本文主要介绍目前存在的定时任务处理解决方案。业务系统中存在众多的任务需要定时或定期执行,并且针对不同的系统架构也需要提供不同的解决方案。京东内部也提供了众多定时任务中间件来支持,总结当前各种定时任务原理,从定时任务基础原理、单机定时任务(单线程、多线程)、分布式定时任务介绍目前主流的定时任务的基本原理组成、优缺点等。希望能帮助读者深入理解定时任务具体的算法和实现方案。
一、背景概述
定时任务,顾名思义,就是指定时间点进行执行相应的任务。业务场景中包括:
- 每天晚上12点,将当日的销售数据发送给各个VP;
- 订单下单十分钟未付款将自动取消订单;用户下单后发短信;
- 定时的清理系统中失效的数据;
- 心跳检测、session、请求是否timeout。
二、定时任务基础原理
2.1 小顶堆算法
每个节点是对应的定时任务,定时任务的执行顺序通过利用堆化进行排序,循环判断每秒是否堆顶的任务是否应该执行,每次插入任务、删除任务需要重新堆化;
图1 利用小顶堆来获取需要最新执行的任务
为什么用优先队列(小顶堆)而不是有序的数组或者链表?
因为优先队列只需要确保局部有序,它的插入、删除操作的复杂度都是O(log n);而有序数组的插入和删除复杂度为O(n);链表的插入复杂度为O(n),删除复杂度为O(1)。总体而言优先队列性能最好。
2.2 时间轮算法
链表或者数组实现时间轮:
图2 利用链表+数组实现时间轮算法
round时间轮: 时间轮其实就是一种环型的数据结构,可以把它想象成一个时钟,分成了许多格子,每个格子代表一定的时间,在这个格子上用一个链表来保存要执行的超时任务,同时有一个指针一格一格的走,走到那个格子时就执行格子对应的延迟任务。
图3 环形数据结构的round时间轮
2.3 分层时间轮
就是将月、周、天分成不同的时间轮层级,各自的时间轮进行定义:

图4 按时间维度分层的时间轮
三、单机定时任务
3.1 单线程任务调度
3.1.1 无限循环
创建thread,在while中一直执行,通过sleep来达到定时任务的效果。
3.1.2 JDK提供了Timer
Timer位于java.util包下,其内部包含且仅包含一个后台线程(TimeThread)对多个业务任务(TimeTask)进行定时定频率的调度。

图5 JDK中Timer支持的调度方法
每个Timer中包含一个TaskQueue对象,这个队列存储了所有将被调度的task, 该队列是一个根据task下一次运行时间排序形成的最小优先队列,该最小优先队列的是一个二叉堆,所以可以在log(n)的时间内完成增加task,删除task等操作,并且可以在常数时间内获得下次运行时间最小的task对象。
原理: TimerTask是按nextExecutionTime进行堆排序的。每次取堆中nextExecutionTime和当前系统时间进行比较,如果当前时间大于nextExecutionTime则执行,如果是单次任务,会将任务从最小堆,移除。否则,更新nextExecutionTime的值。

图6 TimerTask中按照时间的堆排序
任务追赶特性:
schedule在执行的时候,如果Date过了,也就是Date是小于现在时间,那么会立即执行一次,然后从这个执行时间开始每隔间隔时间执行一次;
scheduleAtFixedRate在执行的时候,如果Date过了。还会执行,然后才是每隔一段时间执行。
Timer问题:
- 任务执行时间长影响其他任务:如果TimerTask抛出未检查的异常,Timer将会产生无法预料的行为。Timer线程并不捕获异常,所以 TimerTask抛出的未检查的异常会终止timer线程。此时,已经被安排但尚未执行的TimerTask永远不会再执行了,新的任务也不能被调度了。
- 任务异常影响其他任务:Timer里面的任务如果执行时间太长,会独占Timer对象,使得后面的任务无法几时的执行 ,ScheduledExecutorService不会出现Timer的问题(除非你只搞一个单线程池的任务区)。
3.1.3 DelayQueue
DelayQueue 是一个支持延时获取元素的无界阻塞队列,DelayQueue 其实就是在每次往优先级队列中添加元素,然后以元素的delay过期值作为排序的因素,以此来达到先过期的元素会拍在队首,每次从队列里取出来都是最先要过期的元素。
- delayed是一个具有过期时间的元素
- PriorityQueue是一个根据队列里元素某些属性排列先后的顺序队列(核心还是基于小顶堆)
队列中的元素必须实现 Delayed 接口,并重写 getDelay(TimeUnit) 和 compareTo(Delayed) 方法。
- CompareTo(Delayed o):Delayed接口继承了Comparable接口,因此有了这个方法。
- getDelay(TimeUnit unit):这个方法返回到激活日期的剩余时间,时间单位由单位参数指定。
队列入队出队方法:
- offer():入队的逻辑综合了PriorityBlockingQueue的平衡二叉堆冒泡插入以及DelayQueue的消费线程唤醒与leader领导权剥夺
- take():出队的逻辑一样综合了PriorityBlockingQueue的平衡二叉堆向下降级以及DelayQueue的Leader-Follower线程等待唤醒模式
在ScheduledExecutorService中推出了DelayedWorkQueue,DelayQueue队列元素必须是实现了Delayed接口的实例,而DelayedWorkQueue存放的是线程运行时代码RunnableScheduledFuture,该延时队列灵活的加入定时任务特有的方法调用。
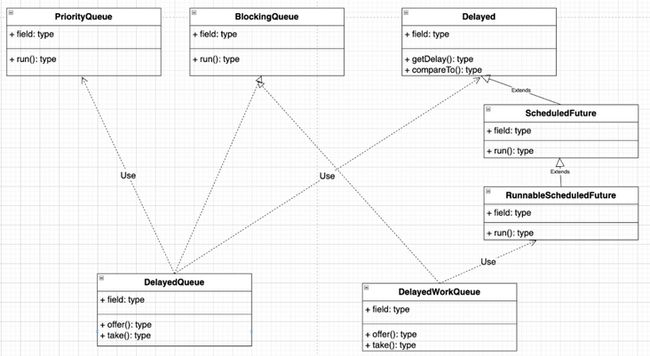
图7 定时任务中的延时队列类图
leader follower模式:
所有线程会有三种身份中的一种:leader和follower,以及一个工作中的状态:proccesser。它的基本原则就是,永远最多只有一个leader。而所有follower都在等待成为leader。线程池启动时会自动产生一个Leader负责等待网络IO事件,当有一个事件产生时,Leader线程首先通知一个Follower线程将其提拔为新的Leader,然后自己就去干活了,去处理这个网络事件,处理完毕后加入Follower线程等待队列,等待下次成为Leader。这种方法可以增强CPU高速缓存相似性,及消除动态内存分配和线程间的数据交换。
3.1.4 Netty 实现延迟任务-HashedWheel
可以使用 Netty 提供的工具类 HashedWheelTimer 来实现延迟任务。
该工具类采用的是时间轮的原理来实现的,HashedWheelTimer是一个基于hash的环形数组。

图8 HashedWheelTimer实现的时间轮
1. 优点: 能高效的处理大批定时任务,适用于对时效性不高的,可快速执行的,大量这样的“小”任务,能够做到高性能,低消耗。把大批量的调度任务全部都绑定到同一个的调度器上面,使用这一个调度器来进行所有任务的管理(manager),触发(trigger)以及运行(runnable)。能够高效的管理各种延时任务,周期任务,通知任务等等。
2. 缺点: 对内存要求较高,占用较高的内存。时间精度要求不高:时间轮调度器的时间精度可能不是很高,对于精度要求特别高的调度任务可能不太适合。因为时间轮算法的精度取决于,时间段“指针”单元的最小粒度大小,比如时间轮的格子是一秒跳一次,那么调度精度小于一秒的任务就无法被时间轮所调度。
3.1.5 MQ 实现延迟任务
- 订单在十分钟之内未支付则自动取消。
- 新创建的店铺,如果在十天内都没有上传过商品,则自动发送消息提醒。
- 账单在一周内未支付,则自动结算。
- 用户注册成功后,如果三天内没有登陆则进行短信提醒。
- 用户发起退款,如果三天内没有得到处理则通知相关运营人员。
- 预定会议后,需要在预定的时间点前十分钟通知各个与会人员参加会议。
以上这些场景都有一个特点,需要在某个事件发生之后或者之前的指定时间点完成某一项任务。
RabbitMQ 实现延迟队列的方式有两种:
- 通过消息过期后进入死信交换器,再由交换器转发到延迟消费队列,实现延迟功能;
- 使用 rabbitmq-delayed-message-exchange 插件实现延迟功能。
同样我们也可以利用京东自研jmq的延时消费来做到以上的场景。
3.2 多线程定时任务
上述方案都是基于单线程的任务调度,如何引入多线程提高延时任务的并发处理能力?
3.2.1 ScheduledExecutorService
JDK1.5之后 推出了线程池(ScheduledExecutorService),现阶段定时任务与 JUC 包中的周期性线程池密不可分。JUC 包中的 Executor 架构带来了线程的创建与执行的分离。Executor 的继承者 ExecutorService 下面衍生出了两个重要的实现类,他们分别是:
- ThreadPoolExecutor 线程池
- ScheduledThreadPoolExecutor 支持周期性任务的线程池

图9 ScheduledExecutorService实现类图
通过 ThreadPoolExecutor 可以实现各式各样的自定义线程池,而 ScheduledThreadPoolExecutor 类则在自定义线程池的基础上增加了周期性执行任务的功能。
- 最大线程数为Integer.MAX\_VALUE;表明线程池内线程数不受限制:即这是因为延迟队列内用数组存放任务,数组初始长度为16,但数组长度会随着任务数的增加而动态扩容,直到数组长度为Integer.MAX\_VALUE;既然队列能存放Integer.MAX\_VALUE个任务,又因为任务是延迟任务,因此保证任务不被抛弃,最多需要Integer.MAX\_VALUE个线程。
- 空闲线程的等待时间都为0纳秒,表明池内不存在空闲线程,除了核心线程:采用leader-follwer,这里等待的线程都为空闲线程,为了避免过多的线程浪费资源,所以ScheduledThreadPool线程池内更多的存活的是核心线程。
- 任务等待队列为DelayedWorkQueue。

图10 ScheduledThreadPoolExecutor中的延时队列DelayedWorkQueue
总结: ScheduledThreadPoolExecutor中定义内部类ScheduledFutureTask、DelayedWorkQueue;ScheduledFutureTask记录任务定时信息,DelayedWorkQueue来排序任务定时执行。ScheduledExecutorService自定义了阻塞队列DelayedWorkQueue给线程池使用,它可以根据ScheduledFutureTask的下次执行时间来阻塞take方法,并且新进来的ScheduledFutureTask会根据这个时间来进行排序,最小的最前面。
- DelayedWorkQueue:其中DelayedWorkQueue是定义的延时队列,可以看做是一个用延时时间长短作为排序的优先级队列,来实现加入任务,DelayedWorkQueue原理见3.1.3;
- ScheduledFutureTask是用作实现Run方法,使得任务能够延迟执行,甚至周期执行,并且记录每个任务进入延时队列的序列号sequenceNumber。任务类ScheduledFutureTask继承FutureTask并扩展了一些属性来记录任务下次执行时间和每次执行间隔。同时重写了run方法重新计算任务下次执行时间,并把任务放到线程池队列中。
run()在处理任务时,会根据任务是否是周期任务走不通的流程:
- 非周期任务,则采用futureTask类的run()方法,不存储优先队列;
- 周期任务,首先确定任务的延迟时间,然后把延迟任务插入优先队列;
ScheduledFutureTask的reExecutePeriodic(outerTask)方法:把周期任务插入优先队列的过程。
3.2.2 实现SchedulingConfigurer接口
Spring Boot 提供了一个 SchedulingConfigurer 配置接口。我们通过 ScheduleConfig 配置文件实现 ScheduleConfiguration 接口,并重写 configureTasks() 方法,向 ScheduledTaskRegistrar 注册一个 ThreadPoolTaskScheduler 任务线程对象即可。
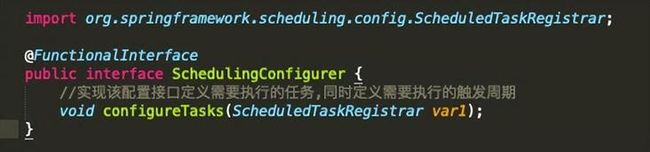
图11 任务调度配置接口
3.2.3 Java任务调度框架Quartz

图12 Quartz任务调度框架
- Job:定义需要执行的任务,该类是一个接口,只定义了一个方法execute(JobExecutionContext context),在实现类的execute方法中编写所需要定时执行的Job(任务),Job运行时的信息保存在JobDataMap实例中。
- Trigger:负责设置调度策略。该类是一个接口,描述触发job执行的时间触发规则。主要有SimpleTrigger和CronTrigger这两个子类。当且仅当需调度一次或者以固定时间间隔周期执行调度,SimpleTrigger 是最适合的选择;而CronTrigger则可以通过Cron表达式定义出各种复杂时间规则的调度方案:如在周一到周五的15:00 ~ 16:00 执行调度等。
- Scheduler:调度器就相当于一个容器,装载着任务和触发器。该类是一个接口。代表一个Quartz的独立运行容器。Trigger和JobDetail可以注册到Scheduler中,两者在Scheduler中拥有各自的组及名称,组及名称是Scheduler查找定位容器中某一对象的依据。
- JobDetail:描述Job的实现类及其它相关的静态信息,如:Job名字、描述、关联监听器等信息。Quartz每次调度Job时,都重新创建一个Job实例,它接受一个Job实现类,以便运行时通过newInstance()的反射机制实例化Job。
- ThreadPool Scheduler使用一个线程池作为任务运行的基础设施,任务通过共享线程池中的线程提高运行效率。
- Listener:Quartz拥有完善的事件和监听体系,大部分组件都拥有事件,如:JobListener监听任务执行前事件、任务执行后事件;TriggerListener监听触发前事件,出发后事件;TriggerListener监听调度开始事件,关闭事件等等,可以注册响应的监听器处理感兴趣的事件。
针对Quartz 重复调度问题:
在通常的情况下,乐观锁能保证不发生重复调度,但是难免发生ABA问题。
配置文件加上:org.quartz.jobStore.acquireTriggersWithinLock=true
3.2.4 使用 Spring-Task
如果使用的是 Spring 或 Spring Boot 框架,Spring 作为一站式框架,为开发者提供了异步执行和任务调度的抽象接口TaskExecutor 和TaskScheduler。
- Spring TaskExecutor:主要用来创建线程池用来管理异步定时任务开启的线程。(防止建立线程过多导致资源浪费)。
- Spring TaskScheduler:创建定时任务
其中Spring自带的定时任务工具,spring task,可以将它比作一个轻量级的Quartz,而且使用起来很简单,除spring相关的包外不需要额外的包,而且支持注解和配置文件两种:
使用方法:
- 声明开启 Scheduled:通过注解 @EnableScheduling或者配置文件
- 任务方法添加@Scheduled注解
- 将任务的类交结 Spring 管理 (例如使用 @Component)
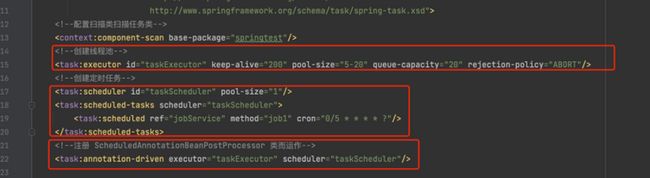
图13 定时任务配置文件和cron表达式

图14 @Scheduled注解拦截类ScheduledAnnotationBeanPostProcessor的实现类图
类图简要介绍:
- 实现感知接口:EmbeddedValueResolverAware, BeanNameAware, BeanFactoryAware, ApplicationContextAware;
- 在spring启动完成单例bean注入,利用接口MergedBeanDefinitionPostProcessor完成扫描,利用BeanPostProcessor接口中的postProcessAfterInitialization扫描被@Scheduled注解表示的方法;
- 利用ScheduledTaskRegistrar作为注册中心,监听到所有bean注入完成之后,然后开始注册全部任务;
- 自定义任务调度器TaskScheduler,默认使用接口ScheduledExecutorService的实现类ScheduledThreadPoolExecutor定义单线程的线程池。
@Scheduler注解源码:
【Java】
@Target({ElementType.METHOD, ElementType.ANNOTATION_TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Repeatable(Schedules.class)
public @interface Scheduled {
//这个变量在ScheduledAnnotationBeanPostProcessor中会用作开启cron的判断条件
String cron() default "";
//用于设置类cron表达式 来描述人物的运行时机
String zone() default "";
//用于设置任务的上一次调用结束后到下一次调用开始前的时间间隔,单位:毫秒
long fixedDelay() default -1L;
//参数 fixedDelay 的字符串参数形式,与fixedDelay只能二选一使用
String fixedDelayString() default "";
//用于设置任务的两次调用之间的固定的时间间隔,单位:毫秒
long fixedRate() default -1L;
//参数 fixedRate 的字符串参数形式,与fixedRate只能二选一使用
String fixedRateString() default "";
//用于设置在首次执行fixedDelay或fixedRate任务之前要延迟的毫秒数
long initialDelay() default -1L;
//参数 initialDelay 的字符串参数形式,与initialDelay只能二选一使用
String initialDelayString() default "";
}
项目启动时,在初始化 bean 后,带 @Scheduled 注解的方法会被拦截,然后依次:构建执行线程,解析参数,加入线程池。其中作为拦截注解的类就是ScheduledAnnotationBeanPostProcessor。
ScheduledAnnotationBeanPostProcessor拦截类中核心注解处理方法:
【Java】
protected void processScheduled(Scheduled scheduled, Method method, Object bean) {
try {
//校验此注解的方法必领是无参的方法
//包装返回一个Runnable线程
Runnable runnable = this.createRunnable(bean, method);
//定义一个校验注册任务最终是否执行的标识
boolean processedSchedule = false;
//裝载任务,定义为4,主要涉及的注解也就3个
String errorMessage = "Exactly one of the 'cron', 'fixedDelay(String)', or 'fixedRate(String)' attributes is required";
Set tasks = new LinkedHashSet(4);
//long和string二者取其一
long initialDelay = scheduled.initialDelay();
String initialDelayString = scheduled.initialDelayString();
if (StringUtils.hasText(initialDelayString)) {
Assert.isTrue(initialDelay < 0L, "Specify 'initialDelay' or 'initialDelayString', not both");
if (this.embeddedValueResolver != null) {
initialDelayString = this.embeddedValueResolver.resolveStringValue(initialDelayString);
}
if (StringUtils.hasLength(initialDelayString)) {
try {
initialDelay = parseDelayAsLong(initialDelayString);
} catch (RuntimeException var24) {
throw new IllegalArgumentException("Invalid initialDelayString value "" + initialDelayString + "" - cannot parse into long");
}
}
}
// Check cron expression
// 解析cron
// cron也可以使用占位符。把它配置子啊配置文件里就成
String cron = scheduled.cron();
if (StringUtils.hasText(cron)) {
String zone = scheduled.zone();
if (this.embeddedValueResolver != null) {
cron = this.embeddedValueResolver.resolveStringValue(cron);
zone = this.embeddedValueResolver.resolveStringValue(zone);
}
if (StringUtils.hasLength(cron)) {
Assert.isTrue(initialDelay == -1L, "'initialDelay' not supported for cron triggers");
processedSchedule = true;
if (!"-".equals(cron)) {
TimeZone timeZone;
if (StringUtils.hasText(zone)) {
timeZone = StringUtils.parseTimeZoneString(zone);
} else {
timeZone = TimeZone.getDefault();
}
//如果配置了cron,那么就可以看作是一个task了,就可以把任务注册进registrar里面
tasks.add(this.registrar.scheduleCronTask(new CronTask(runnable, new CronTrigger(cron, timeZone))));
}
}
}
if (initialDelay < 0L) {
initialDelay = 0L;
}
long fixedDelay = scheduled.fixedDelay();
......
......
......
long fixedRate = scheduled.fixedRate();
......
......
......
//校验注册任务最终是否成功
Assert.isTrue(processedSchedule, errorMessage);
//最后把这些任务都放在全局属性里面保存起来
//getScheduledTasks()方法是会把所有的任务都返回出去
synchronized(this.scheduledTasks) {
Set regTasks = (Set)this.scheduledTasks.computeIfAbsent(bean, (key) -> {
return new LinkedHashSet(4);
});
regTasks.addAll(tasks);
}
} catch (IllegalArgumentException var25) {
throw new IllegalStateException("Encountered invalid @Scheduled method '" + method.getName() + "': " + var25.getMessage());
}
返回所有的任务,该注册类实现了ScheduledTaskHolder的方法。
返回所有的实现ScheduledTaskHolder的任务:
【Java】
public Set getScheduledTasks() {
Set result = new LinkedHashSet();
synchronized(this.scheduledTasks) {
Collection> allTasks = this.scheduledTasks.values();
Iterator var4 = allTasks.iterator();
while(true) {
if (!var4.hasNext()) {
break;
}
Set tasks = (Set)var4.next();
result.addAll(tasks);
}
}
result.addAll(this.registrar.getScheduledTasks());
return result;
}
ScheduledTaskRegistrar
ScheduledTask注册中心,ScheduledTaskHolder接口的一个重要的实现类,维护了程序中所有配置的ScheduledTask。指定TaskScheduler或者ScheduledExecutorService都是ok的,ConcurrentTaskScheduler也是一个TaskScheduler的实现类。它是ScheduledAnnotationBeanPostProcessor的一个重要角色。
指定任务调度taskScheduler:
【Java】
//这里,如果你指定的是一个TaskScheduler、ScheduledExecutorService皆可
//ConcurrentTaskScheduler也是一个TaskScheduler的实现类
public void setScheduler(@Nullable Object scheduler) {
if (scheduler == null) {
this.taskScheduler = null;
} else if (scheduler instanceof TaskScheduler) {
this.taskScheduler = (TaskScheduler)scheduler;
} else {
if (!(scheduler instanceof ScheduledExecutorService)) {
throw new IllegalArgumentException("Unsupported scheduler type: " + scheduler.getClass());
}
this.taskScheduler = new ConcurrentTaskScheduler((ScheduledExecutorService)scheduler);
}
}
重要的一步:如果没有指定taskScheduler ,这里面会new一个newSingleThreadScheduledExecutor,但它并不是一个合理的线程池,所以所有的任务还需要One by One顺序执行,其中默认为:Executors.newSingleThreadScheduledExecutor(),所以肯定单线程串行执行。
触发执行定时任务:
【Java】
protected void scheduleTasks() {
//这一步非常重要:如果我们没有指定taskScheduler,这里会new一个newSingleThreadScheduledExecutor
//显然他并不是一个真的线程池,所以他所有的任务还是得一个一个的执行
//默认是Executors.newSingleThreadScheduledExecutor(),所以必定是串行执行
if (this.taskScheduler == null) {
this.localExecutor = Executors.newSingleThreadScheduledExecutor();
this.taskScheduler = new ConcurrentTaskScheduler(this.localExecutor);
}
//下面就是借助TaskScheduler来启动每一个任务
//并且把启动了的任务最终保存到scheduleTasks中
Iterator var1;
if (this.triggerTasks != null) {
var1 = this.triggerTasks.iterator();
while(var1.hasNext()) {
TriggerTask task = (TriggerTask)var1.next();
this.addScheduledTask(this.scheduleTriggerTask(task));
}
}
......
......
......
}
四、分布式定时任务
上面的方法都是关于单机定时任务的实现,如果是分布式环境可以使用 Redis 来实现定时任务。
使用 Redis 实现延迟任务的方法大体可分为两类:通过 ZSet 的方式和键空间通知的方式。
4.1 通过 ZSet 的方式、Redis 的键空间通知
上述方案都是基于单线程的任务调度,如何引入多线程提高延时任务的并发处理能力?
- 通过 ZSet 实现定时任务的思路是,将定时任务存放到 ZSet 集合中,并且将过期时间存储到 ZSet 的 Score 字段中,然后通过一个无线循环来判断当前时间内是否有需要执行的定时任务,如果有则进行执行。
- 可以通过 Redis 的键空间通知来实现定时任务,它的实现思路是给所有的定时任务设置一个过期时间,等到过期之后通过订阅过期消息就能感知到定时任务需要被执行了,此时执行定时任务即可。
- 默认情况下 Redis 是不开启键空间通知的,需要通过 config set notify-keyspace-events Ex 的命令手动开启。
4.2 Elastic-job、xxl-job
- elastic-job:是由当当网基于quartz 二次开发之后的分布式调度解决方案 , 由两个相对独立的子项目Elastic-Job-Lite和Elastic-Job-Cloud组成 。elastic-job主要的设计理念是无中心化的分布式定时调度框架,思路来源于Quartz的基于数据库的高可用方案。但数据库没有分布式协调功能,所以在高可用方案的基础上增加了弹性扩容和数据分片的思路,以便于更大限度的利用分布式服务器的资源。
- XXL-JOB:是一个轻量级分布式任务调度框架,它的核心设计理念是把任务调度分为两个核心部分:调度中心(xxl-admin),和执行器。隔离成两个部分。这是一种中心化的设计,由调度中心来统一管理和调度各个接入的业务模块(也叫执行器),接入的业务模块(执行器)只需要接收调度信号,然后去执行具体的业务逻辑,两者可以各自的进行扩容。
五、总结
定时任务作为业务场景中不可或缺的一种通用能力,运用适合的定时任务能够快速解决业务问题,同时又能避免过度设计带来的资源浪费。本文旨在梳理目前定时任务的主流方案设计和原理,希望在读者在技术选型和方案重构时有所帮助,唯有落地推动业务的技术才有价值。技术永远不停变革,思考不能止步不前。
作者:京东物流 肖明睿
来源:京东云开发者社区