Python多进程
本文主要是B站黑马程序员课程的学习笔记。
多任务的介绍
概念:多任务是指在同一时间内执行多个任务。例如百度下载工具,同时下载多个文件;电脑同时处理文档和聊天。
表现形式:并发和并行。
并发:在一定时间内交替去执行多个任务。通常对于单核处理器处理多任务时,操作系统轮流让各个任务交替去执行。
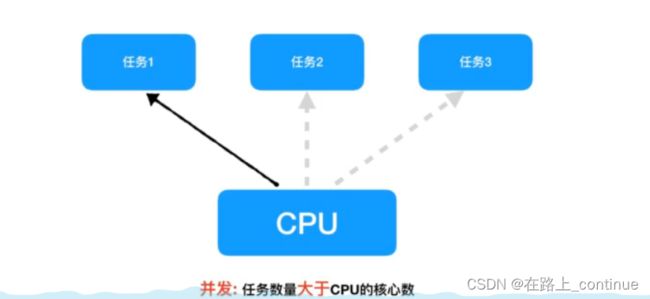
并行:在一段时间内真正的同时一起执行多个任务。例如多核CPU同时执行多个任务。

进程
概念:Process是资源分配的最小单位,是操作系统进行资源分配和调度运行的基本单位。
通俗说就是一个正在运行的程序就是一个进程,例如:正在运行的QQ,微信。
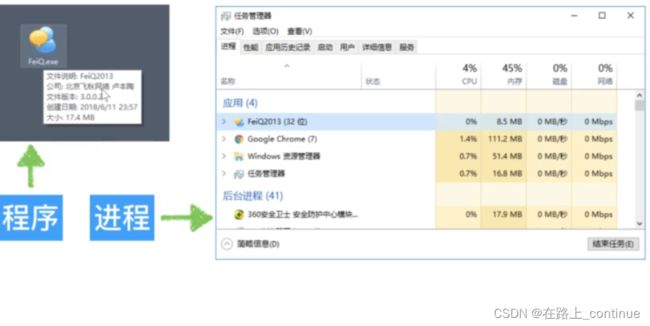
只有运行起来的程序才是进程,否则就是一个程序。
下图左边是未使用多进程,函数执行只能顺序执行,右边是多进成,两个函数可以同步执行,提高了CPU的效率。

多进程完成多任务
1、创建步骤

2、创建进程对象与启动代码
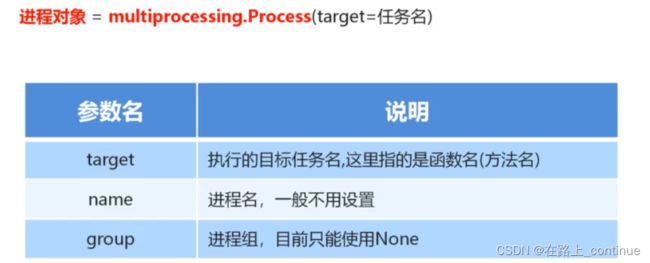
任务名即为函数名,创建对象时候必须指定进程的名字。
# 创建子进程1
sing_process = multiprocessing.Process(target = sing)
# 创建子进程2
dance_process = multiprocessing.Process(target = dance)
# 启动进程,使用对象中的start()函数
sing_process.start()
dance_process.start()
进程执行带有参数的任务
args参数的使用
# target: 进程执行的函数名
# args: 表示以元组的方式给函数传参
# 注意以元祖传参时,如果只有一个参数,不要忘记加 ,
sing_process = multiprocessing.Process(target = sing, args = (3,))
# 有多个参数的时候,参数的顺序为依次传入
sing_process = multiprocessing.Process(target = sing, args = (3, "xiaoming"))
sing_process.start()
kwargs参数的使用
# target: 进程执行的函数名
# kwargs: 以字典的方式给函数传参
sing_process = multiprocessing.Process(target = dance, kwargs = {"num":3})
# 字典的key必须与参数的名字一样才可以传参,多个参数传入时不需要注意参数的顺序
# 启动进程
sing_process.start()
获取进程编号
1、作用
 2、获取方式
2、获取方式

# 1、getpid()的使用
import os
pid = os.getpid()
print(pid)
# 2、getppid()的使用
import os
ppid = os.getppid()
print(ppid )
详细例子图解:
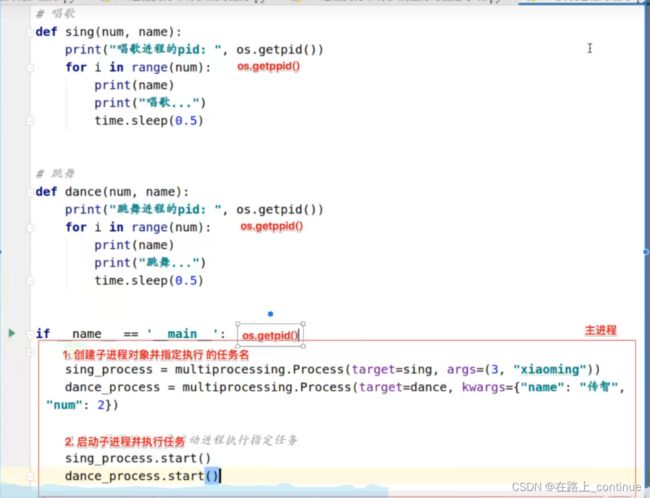
进程注意点
1、主进程会等待所有的子进程执行结束后再结束。
测试代码如下:
import time
import multiprocessing
def work():
# 子进程
# 执行时间为2s
for i in range(10):
print("工作中 ...")
time.sleep(0.2)
if __name__ == "__main__":
work_process = multiprocessing.Process(target = work)
work_process.start()
# 主进程睡眠 1 s
time.sleep(1)
print("主进程执行完成 ...")终端打印效果如下,可知程序会等待子进程运行完成之后才会结束程序。

2、设置守护主进程(目的是主进程结束后程序就自动结束)
import time
import multiprocessing
def work():
# 子进程
# 执行时间为2s
for i in range(10):
print("工作中 ...")
time.sleep(0.2)
if __name__ == "__main__":
work_process = multiprocessing.Process(target = work)
# 设置守护主进程,主进程退出后子进程直接销毁,不再执行子进程中的代码
work_process.daemon = True
work_process.start()
# 主进程睡眠 1 s
time.sleep(1)
print("主进程执行完成啦!")执行效果如下:

3、知识要点

主进程默认会等待所有子进程执行结束后再结束,除非设置子进程守护进程。
案例:多进程高并发copy文件
1、需求

2、 实现步骤
1)定义源文件夹所在的路径,目标文件夹所在的路径

2)创建目标文件夹

3) 获取源文件目录中的文件列表

4) 遍历每一个文件,定义一个函数,专门用来文件拷贝

5) 采用多进程实现多任务,完成高并发的拷贝

每次读到一个文件,就会创建一个进程去copy相应的文件。for循环会依次遍历相应的文件。
6) 示例代码
此代码只能在Ubuntu环境下测试通过,且只有当文件足够大足够多的时候才能体现出多进程高并发的效率优于单进程。
from re import sub
import time
import os
import multiprocessing
from tkinter import Spinbox
def copy_file(file_name, source_dir, dest_dir):
# 拼接路径
source_path = source_dir + "/" + file_name
dest_path = dest_dir + "/" + file_name
print(source_path, "----->", dest_path) # 打印提示信息
# 打开源文件,创建目标文件
with open (source_path, 'rb') as source_file:
with open(dest_path, 'wb') as dest_file:
# 循环进行拷贝,不断读取源文件的内容并写入到目标文件夹中(循环)
while True:
# 循环读数据
file_data = source_file.read(1024)
if file_data:
dest_file.write(file_data)
else:
break
if __name__ == "__main__":
# 1、定义源文件夹河目标文件夹
source_dir = "python教学视频"
dest_dir = "/home/python/"
# 2、创建目标文件夹
try:
os.mkdir(dest_dir)
except:
print("目标文件夹已存在!")
# 3、读取源文件夹的文件列表
flie_list = os.listdir(source_dir) # 得到文件列表
# 4、遍历文件列表实现拷贝
for file_name in flie_list:
# copy_file(file_name, source_dir, dest_dir) # 单进程拷贝,速度慢
# 5、使用多进程实现任务拷贝
sub_process = multiprocessing.Process(target = copy_file,
args = (file_name, source_dir, dest_dir))
sub_process.start() # 启动进程