深入理解Linux虚拟内存管理(三)

系列文章目录
Linux 内核设计与实现
深入理解 Linux 内核(一)
深入理解 Linux 内核(二)
Linux 设备驱动程序(一)
Linux 设备驱动程序(二)
Linux 设备驱动程序(三)
Linux设备驱动开发详解
深入理解Linux虚拟内存管理(一)
深入理解Linux虚拟内存管理(二)
深入理解Linux虚拟内存管理(三)
文章目录
- 系列文章目录
- 第12章 共享内存虚拟文件系统
-
- 12.1 初始化虚拟文件系统
- 12.2 使用 shmem 函数
- 12.3 在 tmpfs 中创建文件
- 12.4 虚拟文件中的缺页中断
-
- 12.4.1 定位交换页面
- 12.4.2 向交换区写页面
- 12.5 tmps 中的文件操作
- 12.6 tmpfs 中的索引节点操作
- 12.7 建立共享区
- 12.8 System V IPC
- 12.9 2.6 中有哪些新特性
- 第13章 内存溢出管理
-
- 13.1 检查可用内存
- 13.2 确定 OOM 状态
- 13.3 选择进程
- 13.4 杀死选定的进程
- 13.5 是这样吗?
- 13.6 2.6 中有些新特性
- 第14章 结束语
第12章 共享内存虚拟文件系统
共享一个有后援文件或后援设备的内存区域仅需要调用 mmap() 设置 MAP_SHARED 标志位。但是,进程间共享一片匿名区域时存在两种重要情形:其一是在 mmap() 设置 MAP_SHARED 时没有后援文件,这片区域将在 fork() 执行之后由父、子进程共享;其二是该区域明确地利用 shmget() 设置,并由 shmat() 附加到虚拟地址空间中。
当 VMA 中的页面有磁盘上的后援文件时,所使用的接口很简单。系统在缺页时为了读入一页会调用 vm_area_struct->vm_ops 中的 nopage() 函数。要写一页到后援存储设备时,就使用 inode -> i_mapping -> a_ops 或 page -> mapping→ a_ops 在 address_space_operations 中寻找到相应的 writepage() 函数。当进行普通文件操作如 mmap(),read() 和 write() 时,系统则使用 inode→i_fop 等找到 struct file_operations 及其相应的函数。这些关系如图 4.2 所示。
这是一个相当清晰的接口,概念上也很容易理解。但它却无法处理匿名页的情况,因为匿名页没有后援文件。所以,为了保留这个清晰的接口,Linux 引入了一个基于 RAM 文件系统的人造文件,用于后援匿名页面,其中每个 VMA 都由这个文件系统中的一个文件作为后援。此文件系统的每个索引节点都被放置在 shmem_inodes 链表中,这样就很容易确定每个索引节点。通过引入这个概念,Linux 允许使用相同的基于文件的接口,而不是对匿名页作特殊处理。
这种文件系统有两个变种 :shm 和 tmpfs。它们的核心功能相同,主要不同的地方是用途。内核利用 shm 为匿名页创建后援文件并由 shmget() 生成后援区域。该文件系统由 kern_mount() 加载,所以它在内部加载,并不为用户所见。tmpfs 是一个临时文件系统,它可以有选择地加载到 /tmp/ 以获得一个基于 RAM 的临时文件系统。tmpfs 的另一个用途是被加载到 /dev/shm/ 。这时,在 tmpfs 文件系统中,mmap() 文件的进程之间可以共享信息,这是代替 System V 进程间通信(IPC)机制的一种方法。但是无论哪一种使用情形,tmpfs 必须显式地由系统管理员加载。
本章首先描述如何实现虚拟文件系统。接着讨论如何建立及销毁共享区域,最后说明怎样使用工具实现 System V IPC 机制。
12.1 初始化虚拟文件系统
如图 12.1 所示,在系统启动或载入模块时,由函数 init_tmpfs() 初始化虚拟文件系统。 init_tmpfs() 注册两个文件系统 tmpfs 和 shm,并调用 kern_mount() 加载作为内部文件系统的 shm。然后计算文件系统中块和索引节点的最大数量。作为注册过程的一部分,它还调用 shmem_read_super() 作为一个回调函数来生成 super_block 结构,这个结构中保存有更多关于文件系统的信息,如保证块大小等于页面大小。

文件系统创建的每一个索引节点都附带有 shmem_inode_info 结构,这个结构含有文件系统的私有信息。SHMEM_I() 函数以索引节点为参数,返回指针到此类型的结构中。
struct shmem_inode_info {
spinlock_t lock;
unsigned long next_index;
swp_entry_t i_direct[SHMEM_NR_DIRECT]; /* for the first blocks */
void **i_indirect; /* indirect blocks */
unsigned long swapped; /* data pages assigned to swap */
unsigned long flags;
struct list_head list;
struct inode *inode;
};
其中各字段含义如下。
- lock:为了保护索引节点信息不被并发访问的自旋锁。
- next_index:文件最后一页的索引。在文件被截断时它与 inode→i_size 是不同的。
- i_direct:一个直接块,它存放有文件中用到的第一个 SHMEM_NR_DIRECT 交换向量。具体见 12.4.1 小节。
- i_indirect:指向首个间接块的指针。具体见 12.4.1 小节。
- swapped:记录文件当前换出的页面数量的计数。
- flags:目前仅用于记住文件是否属于 shmget() 建立的共享区域。它通过 shmctl() 指定 SHM_LOCK 锁来设置,指定 SHM_UNLOCK 来解锁。
- list:文件系统中所有索引节点的列表。
- inode:父索引节点的指针。
12.2 使用 shmem 函数
包含 shmem 特定函数指针的结构有多种,所有结构中 tmpfs 和 shm 都共享相同的结构。
Linux 中声明了 hmem_aops 和 shmem_vm_ops,它们分别具有 struct address_space_operations 和 struct vm_operations_struct,分别对应于换页中的缺页处理和写页面到后援存储区。
地址空间操作结构 struct shmem_aops 包含有指向一些函数的指针,其中最重要的是 shmem_writepage() ,它在从高速缓存移动页面到交换高速缓存时被调用。shmem_removepage() 在从页面高速缓存中移除页面时被调用,这时系统可以回收存储块。tmpfs 不使用 shmem_readpage() ,但 Linux 还是提供了这个函数,这样 tmpfs 文件上的系统调用 sendfile() 才可能被使用。同样 tmpfs 也没有使用 shmem_prepare_write() 和 shmem_commit_write() ,但 Linux 提供它们从而 tmpfs 可以被用作回环设备。mm/shmem.c 中,shmem_aops 有如下声明:
// mm/shmem.c
static struct address_space_operations shmem_aops = {
removepage: shmem_removepage,
writepage: shmem_writepage,
#ifdef CONFIG_TMPFS
readpage: shmem_readpage,
prepare_write: shmem_prepare_write,
commit_write: shmem_commit_write,
#endif
};
匿名 VMA 使用 shmem_vm_ops 作为 vm_operations_struct,所以在中断陷入时系统调用 shmem_nopage() 。它如下声明:
// mm/shmem.c
static struct vm_operations_struct shmem_vm_ops = {
nopage: shmem_nopage,
};
在文件和索引节点上完成操作时需要有两个结构 : file_operations 和 inode_operations 。file_operations 由 shmem_file_operations 调用,它提供函数实现 mmap(),read(),write() 和 fsync() 。它如下声明:
// mm/shmem.c
static struct file_operations shmem_file_operations = {
mmap: shmem_mmap,
#ifdef CONFIG_TMPFS
read: shmem_file_read,
write: shmem_file_write,
fsync: shmem_sync_file,
#endif
};
Linux 提供了 3 种 inode_operations:第 1 种是 shmem_inode_operations,它在文件索引
节点中使用;第 2 种是 shmem_dir_inode_operations,它针对目录;第 3 种是 shmem_symlink_inline_operations 和 shmem_symlink_inode_operations 的组合,它针对符号链接。
在名为 shmem_inode_operations 的 inode_operations 结构中存放有 Linux 支持的两种文件操作,即 truncate() 和 setattr() 。shmem_truncate() 用于截断文件。shmem_notify_change() 在文件属性改变时被调用,从而使文件中的其他部分通过 truncate() 得以增长并使用全局零页面作为数据页面。shmem_inode_operations 如下声明:
// mm/shmem.c
static struct inode_operations shmem_inode_operations = {
truncate: shmem_truncate,
setattr: shmem_notify_change,
};
目录 inode_operations 提供了诸如 create(),link() 和 mkdir() 的函数,它们如下声明:
// mm/shmem.c
static struct inode_operations shmem_dir_inode_operations = {
#ifdef CONFIG_TMPFS
create: shmem_create,
lookup: shmem_lookup,
link: shmem_link,
unlink: shmem_unlink,
symlink: shmem_symlink,
mkdir: shmem_mkdir,
rmdir: shmem_rmdir,
mknod: shmem_mknod,
rename: shmem_rename,
#endif
};
最后一对操作用于符号链接。它们如下声明:
// mm/shmem.c 1354
static struct inode_operations shmem_symlink_inline_operations = {
readlink: shmem_readlink_inline,
follow_link: shmem_follow_link_inline,
};
static struct inode_operations shmem_symlink_inode_operations = {
truncate: shmem_truncate,
readlink: shmem_readlink,
follow_link: shmem_follow_link,
};
函数 readlink() 和 follow_link() 之间的差异与链接信息存放的位置有关。符号链接索引节点不需要私有索引节点信息结构 shmem_inode_information。如果符号链接名的长度小于这个结构,则索引节点中的空间用于存放名字,而 shmem_symlink_inline_operations 会变成索引节点操作结构。否则,shmem_getpage() 开辟一个页面,把符号链接复制到页面中,索引节点操作结构定义为 shmem_symlink_inode_operations 。第 2 个结构中包括 truncate() 函数,可以在删除文件时回收页面。
这些不同的结构保证了与索引节点相关操作等价的 shmem 会在共享区域有后援虚拟文件时被用到。当用到它们时,VM 的主要部分中不会出现由实际文件作后援的页面和由虚拟文件作后援的页面之间的差异。
12.3 在 tmpfs 中创建文件
由于 tmpfs 作为一种用户可见的文件系统加载,因此它必须支持目录索引节点操作,如 open(),mkdir() 和 link() 。实现 tmpfs 的函数指针由 shmem_dir_inode_operations 提供 ,详见 12.2 节。
这些函数中大部分的实现都不完全,在某种层次上,它们之间的交互如图 12.2 所示。它们实现虚拟文件系统中的索引节点相关操作的基本原理都是相同的,并且大部分索引节点字段都由 shmem_get_inode() 填充。

在创建一个新文件时,调用的顶层函数是 shmem_create() ,它调用 shmem_mknod(),设置 S_IFREG 标志位,从而创建一个普通文件。shmem_mknod() 仅是 shmem_get_inode() 的一个包装器,可以确定,它创建一个新的索引节点并填充结构字段。主要要填充的 3 个字段是 inode -> i_mapping -> a_ops,inode -> i_op 和 inode→i_fop 字段。在创建索引节点之后,shmem_mknod() 会更新目录索引节点大小并统计参数 mtime,然后实例化这个新的索引节点。
即使各文件系统的功能本质上相同,shm 中文件的创建也各不相同。如何创建这些文件将在 12.7 中详细讨论。
12.4 虚拟文件中的缺页中断
发生缺页中断时,如果 vma -> vm_ops->nopage 操作存在,do_no_page() 将会调用该操作。在虚拟文件系统的情形下,这意味着函数 shmem_nopage() 以及它的调用图中函数(如图 12.3 所示)将在缺页时被调用。
在这种情形下的核心函数是 shmem_getpage(),它负责分配新页或者在交换区中找到该页。这种对错误类型的重载是不寻常的,因为 do_swap_page() 一般负责使用 PTE 中的编址信息来定位那些已经移到交换高速缓存或后援存储区的页面。在这种情况下,有后援虚拟文件的页面在被移到交换高速缓存中时其 PTE 是被设为 0 的,而索引节点的私有文件系统数据储存了直接或间接的关于块的信息,这些信息将被用来定位页面。这个操作在很多方面都与普通缺页中断处理类似。

12.4.1 定位交换页面
当一个页面被换出后,swp_entry_t 就会包含再次定位该页面所需的信息。这些信息存放在索引节点中作为文件系统特定的私有信息,而不是使用 PTE 来完成这个工作。
在发生缺页时,系统会调用 shmem_alloc_entry() 来定位交换项。它的基本任务是进行基本的检查并保证 shmem_inode_info -> next_index 始终指向虚拟文件末端的页面索引。它的主要任务是调用 shmem_swp_entry() 得到索引节点信息,然后查找索引节点信息中的交换向量,并且在需要时分配新页来存放交换向量。
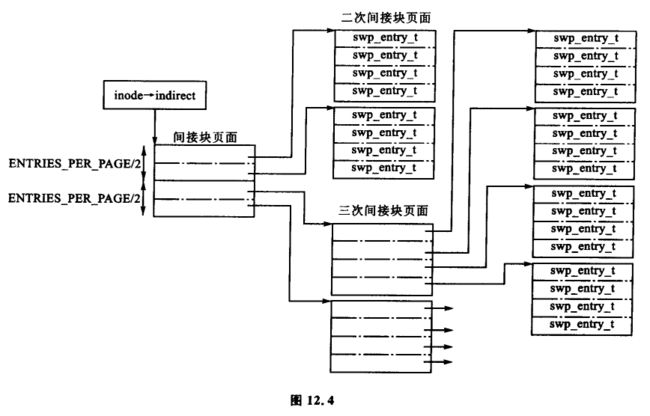
第一个 SHMEM_NR_DIRECT 项存放在 inode→i_direct 中。这意味着对 x86 而言,小于 64 KB(SHMEM_NR_DIRECT * PAGE_SIZE)的文件将不需要使用间接块。更大的文件则必须使用从 inode→i_indirect 指向位置开始的间接块。
刚开始间接块(inode→i_indirect)分为两半。一半包含指向二次间接块的指针,另一半则包含指向三次间接块的指针。二次间接块由包含交换向量(swp_entry_t)的页面组成。三次间接块包含由交换向量填充的页面指针。图 12.4 中显示了间接块不同层次之间的关系。这种关系意味着在一个虚拟文件(SHMEM_MAX_INDEX)中页面的最大数量(在 mm/shmem.c 中定义)为:
#define SHMEM_MAX_INDEX (SHMEM_NR_DIRECT + (ENTRIES_PER_PAGEPAGE/2) * (ENTRIES_PER_PAGE+1))
12.4.2 向交换区写页面
在虚拟文件系统中,由 address_space_operations 的注册函数 shmem_writepage() 向交换区写页面。这个函数负责把页面从页面高速缓存移到交换高速缓存。过程包括以下几步:
- 记录当前 page→mapping 和索引节点相关的信息。
- 调用 get_swap_page() 在后援存储区中分配一空闲槽。
- 调用函数 shmem_swp_entry() 分配 swp_entry_t。
- 从页面高速缓存中移除该页。
- 将该页加入到交换高速缓存中。如果有失败,则释放交换槽,将页面加入到页面高速缓存中并再次进行这步操作。
12.5 tmps 中的文件操作
虚拟文件支持四种操作,mmap(),read(),write() 和 fsync() 。这些函数的指针都存放在 shmem_file_operations 中,在 12.2 节中已有叙述。
这些操作的实现都很普通,在代码注释部分也会有详细阐述。mmap() 操作由 shmem_mmap() 实现,它仅是更新负责那片映射区域的 VMA。read() 操作由 shmem_read() 实现,它从虚拟文件中读数据到用户空间的缓冲区中,并在需要时产生缺页中断。write() 由 shmem_write() 实现,本质上与 read() 类似。fsync() 操作由 shmem_file_sync() 实现,但它实际上是一个 NULL 操作,因为它不做任何事,仅返回 0 表示成功。由于这些文件只存在于 RAM 中,所以它们不需要与磁盘同步。
12.6 tmpfs 中的索引节点操作
支持索引节点的最复杂的操作是截断,它涉及 4 个不同的阶段。第 1 个阶段是在 shmem_truncate() 中,它会截断文件末尾的部分页面,并不停地调用 shmem_truncate_indirect(),直到文件被截断到合适大小。每一次调用 shmem_truncate_indirect() 只能对一个间接块进行处理,这也是它可能需要多次调用的原因。
第 2 个阶段,是在 shmem_truncate_indirect() 中,处理二次和三次间接块。它找到下一个需要被截断的间接块。这个将被传到第 3 个阶段的直接块将包含含有交换向量的页面指针。
第 3 个阶段,是在 shmem_truncate_direct() 中处理包含交换量的页面。它选出一个需要截断的范围并且将这个范围传到最后一个阶段 shmem_swp_free() 。最后一个阶段调用 free_swap_and_cache() 来释放表项,包括释放交换区表项以及包含数据的页面。
文件的链接和断开操作很简单,因为大部分的工作由文件系统层完成。要链接一个文件,需要增大目录索引节点的大小,更新相应索引节点的 ctime 和 mtime 参数,以及增加将要链接的索引节点的链接节点数量。然后调用 dget() 指向新表项,接着调用 d_instantiate() 来实例化新表项。断开操作同样会更新相应索引节点的参数,再减少将要链接的索引节点的链接节点数量,然后调用 dput() 来减少引用。dput() 也会调用 iput() 在引用计数到 0 时清除该索引节点。
创建目录的操作将通过调用 shmem_mkdir() 来完成。它调用 shmem_mknod() 设置 S_IFDIR 标志位,然 后增加父目录索引节点的 i_nlink 计数。函数 shmem_rmdir() 在调用 shmem_empty() 清空目录之后再删除此目录。如果目录是空的,shmem_rmdir() 会将父目录索引节点的 i_nlink 计数减 1,然后调用 shmem_unlink() 来移除目录。
12.7 建立共享区
共享区由 shm 创建的文件作后援。存在创建文件的两种情形:一种是在 shmget() 建立共享区时,另一种是在 mmap() 设立 MAP_SHARED 标志位来启动匿名共享区时。这两个函数都使用核心函数 shmem_file_setup() 创建文件。
由于文件系统是在内部的,所以所要创建的文件的名字不需要惟一(文件总是以索引节点来定位的,不是名字)。因此,shmem_zero_setup() (如图 12.5 所示)据说总是创建一个名为 dev/zero 的文件,在文件 /proc/pid/maps 中它就是这样出现的。shmget() 创建的文件叫做 SYSVNN,其中 NN 是传递给 shmget() 的一个参数。
核心函数 shmem_file_setup() 仅创建一个目录项和索引节点,然后填充相关的字段并实例化。
12.8 System V IPC
IPC 实现的内部机制超出了本书的范围。这一节仅集中讨论 shmget() 和 shmat() 的实现以及它们如何受到 VM 的影响。如图 12.6 所示,系统调用 shmget() 由 sys_shmget() 实现。
它进行基本的参数检查,然后建立 IPC 相关的数据结构。为了创建段,它调用 newset() ,就是由这个函数在 shmfs 中调用前面节中讨论过的 shmem_file_setup() 来创建文件。
系统调用 shmat() 由 sys_shmat() 实现。对这个函数没有什么要注意的地方。它获得适当的描述符,并且保证所有的参数都有效,然后调用 do_mmap() 把共享区映射到进程地址空间。这个函数中仅有两点需要注意。
首先,如果调用者指明了地址,必须保证 VMA 不会被覆盖。其次 shp→shm_nattch 计数由一个类型为 shm_vm_ops 的 vm_operations_struct() 来维护,它分别注册了 open() 和 close() 的回调函数 shm_open() 和 shm_close() 。回调函数 shm_close() 还负责在指明 SHM_DEST 标志位且 shm_nattch 计数到 0 时销毁共享区。


12.9 2.6 中有哪些新特性
在 2.6 中,文件系统的核心概念和功能保持不变,改变的部分仅是优化或者对文件系统功能的扩展。如果读者能够很好地理解 2.4 中的实现,那么对 2.6 中的实现的理解就不会构成很大的障碍。
在 shmem_inode_info 中增加了一个叫做 alloced 的字段。它存储了分配给这个文件的页数,在 2.4 中这是需要通过 inode→i_blocks 的值在运行时计算的。同时它保存了一些共同操作的时钟周期,从而使代码更具可读性。
2.4 中的 flags 字段现在使用 VM_ACCOUNT 标志位以及 VM_LOCKED 标志位。系统总是要设置 VM_ACCOUNT,表明 VM 将仔细地计算所需的内存从而确保分配不会失败。
对文件操作的扩展能通过系统调用 _llseek() 来定位内容,_llseek 由 generic_file_llseek() 实现。还有虚拟文件上调用 sendfile(),它由 shmem_file_sendfile() 实现。还有 2.6 中允许非线性映射的对 VMA 操作的扩展,它由 shmem_populate() 实现。
最后一个主要的改变是文件系统负责分配和回收它自己的索引节点,这涉及到在结构 super_operations 中的两个回调函数。 它们通过调用 shmem_inode_cache 来创建一个 slab 高速缓存实现。在这个 slab 分配器上注册一个 init_once() 构造函数来初始化每个新索引节点。
第13章 内存溢出管理
现在要讨论的有关 VM 的最后一部分是内存溢出(OOM,Out Of Memory)管理。这一章写得比较短,因为检查系统是否有足够的内存、是否真的溢出以及在内在溢出时杀死一个进程等都是比较简单的任务。这部分内容在 VM 中颇具争议,所以很多场合中都会删除这部分。但我认为无论它在以后的内核中是否会出现,它都是一个需要考虑的重要子系统,因为它涉及到一系列其他的子系统。
13.1 检查可用内存
对于某些操作,如扩展堆的 brk() 和重映射地址空间的 mremap(),系统都会检查是否有足够的空间来满足请求。注意这与下一节中的 out_of_memory() 路径是有差异的。 out_of_memory() 路径用于在可能的时候避免系统处于 OOM 状态。
在进行可用内存检查时,系统将所请求的页面数作为参数传递给 vm_enough_memory(),然后检查是否可以满足该请求。除非系统管理员指定了系统可以多用内存,否则系统都将进行可用内存的检查。为了确定系统所有可用的页面数量,Linux 把以下数据相加。
- 页面高速缓存容量:因为页面高速缓存很容易就可以回收。
- 空闲页面数:因为它们已经处于可用状态。
- 空闲交换页面数:因为可以换出用户空间页面。
- swapper_space 管理的页面数量:其对空闲交换页面双倍计数。但由于槽要保留起来,而且不曾用到,因此该方式是比较妥当的。
- dentry 高速缓存使用的页面数:因为很容易回收它们。
- inode 高速缓存使用的页面数:因为也很容易回收它们。
如果加起来的页面数对请求页面数来说已经足够,则 vm_enough_memory() 会返回 true 给调用者。如果调用者获得了 false 的返回值,则它知道系统当前空闲页面不足,这时它就会决定是否向用户空间返回 -ENOMEM 错误。
13.2 确定 OOM 状态
在机器内存不足时,系统就会回收旧的页面帧(见第 10 章),但是在这个过程中可能会发现,系统即使是以最高优先级扫描都无法释放足够的页面来满足请求。如果系统不能够释放页面,就会调用 out_of_memory(),告知系统发生内存溢出,这时需要杀死某个进程。函数调用图如图 13.1 所示。

不幸的是,系统可能并没有发生内存溢出,而只是等待 I/O 操作完成,或者将页面换出到后援存储器。这很糟糕,不是因为系统没有内存,而是因为函数被不必要地调用,它将导致进程可能会被不必要地杀掉。所以在决定杀死某个进程之前,系统会做如下检查:
-
有足够的换出空间留下吗 (nr_swap_pages > 0) ? 如果是,不是 OOM;
-
自从上次失败已经大于 5 s 了? 如果是,不是 OOM;
-
在上一秒中失败过? 如果不是,不是 OOM;
-
如果在至少上 5 s 中没有 10 个错误,不是 OOM;
-
在上 5 s 中有进程被杀死? 如果是,不是 OOM。
仅当上面的检查都通过时,系统才会调用 oom_kill() 选择一个进程杀死。
13.3 选择进程
函数 select_bad_process() 负责选择一个进程杀死。它逐个检查各个正在运行的进程,并调用函数 badness() 计算各个进程是否合适被杀死。badness() 的计算方法如下,注意方根是使用 int_sqrt() 计算出来的整型估计数值。
b a d n e s s _ f o r _ t a s k = t o t a l _ v m _ f o r _ t a s k c p u _ t i m e _ i n _ s e c o n d s ∗ c p u _ t i m e _ i n _ m i n u t e s 4 badness\_for\_task = \frac {total\_vm\_for\_task} { \sqrt[]{cpu\_time\_in\_seconds} * \sqrt[4]{cpu\_time\_in\_minutes} } badness_for_task=cpu_time_in_seconds∗4cpu_time_in_minutestotal_vm_for_task
它所选择的是那个使用了最大量的内存空间而没有生存很久的进程,因为那些已经生存了很久的进程不像是导致内存不足的原因,所以这个计算选择一个使用了大量的内存而没有生存很久的进程。如果该进程是一个根进程或者具有 CAP_SYS_ADMIN 能力,数值就会除以 4,因为具有根特权的进程被认为是表现良好的。类似地,如果该进程具有 CAP_SYS_RAWIO(访问源设备的能力),数值会再除以 4,因为杀死一个可以访问硬件的进程是不值得的。
13.4 杀死选定的进程
一旦选定一个进程,系统会再一次遍历该列表,发信号给所有与该进程共享相同的 mm_struct 的进程(或它们都是线程)。如果该进程具有 CAP_SYS_RAWIO 能力,系统将会发出一个 SIGTERM 信号,给它一个完全结束的机会,否则就会发出一个 SIGKILL 信号。
13.5 是这样吗?
是这样的。OOM 管理涉及到很多其他的子系统,但是又没有那么多。
13.6 2.6 中有些新特性
除引入了 VM 占用对象以外,2.6 内核中的 OOM 管理几乎保持不变。在 4.8 节中曾经提到过 VM_ACCOUNT,在这里用许多 VMA 表示。系统在这些标识空间中对 VMA 进行操作时,就进行额外的检查以确保有足够的内存。这种复杂操作背后的动机是要争取避免 OOM 终止进程。
含有 VM_ACCOUNT 标志位的区域有:进程,进程堆,mmap() 使用 MAP_SHARED 映射的区域,可写的私有区域,以及建立 shmget() 的区域,或者说,大部分用户空间区域都含有 VM_ACCOUNT 标志位。
Linux 所占内存中的 VMA 数量由 vm_acct_memory() 确定,vm_acct_memory() 会增加变量 committed_space 的大小。 释放 VMA 时, vm_unacct_memory() 会减少 committed_space 的大小。 这是一个相当简单的机制,不过这个机制要求在决定是否分配用户空间时 Linux 必须记住多少内存已经用于用户空间。
系统通过调用 security_vm_enough_memory() 实现这项检查, security_vm_enough_memory() 引入了另外的新特性。2.6 中用到的一个新特性是与安全相关的内核模块重载某些内核函数。类型为 security_opt 的结构体 security_operations 就存放有可用的钩子函数的列表。security/dummy.c 中存放了可能用到的大量的哑元和缺省函数,但大部分只是返回。如果没有载入安全模块,则使用 dummy_security_ops,它是一个使用所有缺省函数的 security_operations 结构。
缺省情况下,security_vm_enough_memory() 调用 sectrity/dummy.c 中声明的 dummy_vm_enough_memory(),它与 2.4 中的 vm_enough_memory() 函数非常相似。新的版本中加入下列的信息在一起来决定可用的内存。
- 页面高速缓存的大小:因为页面高速缓存很容易就可以回收。
- 空闲页面的总数:因为它们已经处于可用状态。
- 空闲交换页面的总数:因为用户空间的页面可能会被换出。
- 设置了 SLAB_RECLAIM_ACCOUNT 的 slab 页面:因为可以很容易回收它们。
这些页面中除减去 3% 保留给 ROOT 进程的那部分外就是当前请求的可用内存总数。如果有足够的内存,系统就检查一次以保证分配的内存不会超过允许的阀值 TotalRam * (OverCommitRatio/100)+TotalSwapPage,其中 OverCommitRatio 由系统管理员设定。如果分配的空间总量不是太大,就会返回 1 从而开始分配。
第14章 结束语

123