[MySQL]不允许你不会SQL语句之查询语句
博客主页:博主链接
本文由 M malloc 原创,首发于 CSDN
学习专栏推荐:LeetCode刷题集!
欢迎点赞 收藏 ⭐留言 如有错误敬请指正!
未来很长,值得我们全力奔赴更美好的生活✨
------------------❤️分割线❤️-------------------------
————————————————

![[MySQL]不允许你不会SQL语句之查询语句_第1张图片](http://img.e-com-net.com/image/info8/5341c15894ce494faaa7a85c1c9fe465.jpg)
文章目录
- 查询语句
-
- 一、sql_server技术介绍
- 二、学习前的准备工作
- 模糊查询
-
- 三、模糊查询的及其语法讲解
- 聚合函数
- 分组查询(group by)
- 总结
大家好呀,今天是我第四次写sql_server,也是最近才学习sql_server,也想着记录一下自己的学习过程,并且分享给大家尼!
查询语句
一、sql_server技术介绍
SQL Server 是由微软公司(Microsoft)开发的关系型数(RDBMS)。RDBMS 是 SQL 以及所有现代数据库系统的基础,比如 MS SQL Server,IBM DB2,Oracle,MySQL 以及微软的 Microsoft Access。
二、学习前的准备工作
编程软件:SQL Server Management Studio 2012
带好你的小板凳,我们一起扬帆起航!

模糊查询
在SQL中有一种查询叫模糊查询,是什么样子的呢?接下来我们就来详细的看几道例题吧!
三、模糊查询的及其语法讲解
如下图所示,正是我们会在查询中遇到的一些语法问题啦!
接下来我们来看几个例子吧!

1.查询出姓刘的员工信息
语法:select * from 表名 where like 条件
select * from People where PeopleName like '刘%'

2.查询出名字字中含有尚的员工信息
select * from People where PeopleName like '%尚%'
![]()
3.查询出名字中含有尚或者史的员工信息
注意看这里是或者,所以我们用到的关键字就得有or这个关键字啦!
select * from People where PeopleName like '%尚%' or PeopleName like '%羽'
![]()
4.查询出姓刘的员工,名字时两个字 _下划线代表有且仅有一个字符
注意看,这个时候我们只想查询刘后面接一个字的名字,例如刘备,假设是刘大汉就不行啦!
select * from People where PeopleName like '刘_'

5.查询名字最后一个字为香,名字一共三个字的员工信息
那么根据上述描写,一个下划线代表着一个字,那么这个时候我们用两个下划线是不是就行啦!
select * from People where PeopleName like '__香'
![]()
6.查询出电话号码开头为138的员工信息
select * from People where PeoplePhone like '138%'

7.查询出电话号码开头为138的,第四位好像是7或者8,最后一个号码是5
此时我们发先题目要求我们呢带有查询的一个范围,这个时候我们就需要用到[]这个语法就行啦!
[]这个代表的是通配符的意思,里面填写的是数的范围
select * from People where PeoplePhone like '138[7,8]%5'

此时我们发现我们建立的表中是没有这样的数据的。
8.查询出电话号码开头为138的,第四位好像是2者5,最后一个号码不是2和3
select * from People where PeoplePhone like '138[2,3,4,5]%[^2,3]'
![]()
聚合函数
下图是聚合函数的几个函数名!
![[MySQL]不允许你不会SQL语句之查询语句_第2张图片](http://img.e-com-net.com/image/info8/8d9ee04d859a47c190693eb17b51ac73.jpg)
接下来我带大家了解几个例子吧!
1.求员工的总数
select count(*) 人数 from People

2.求最大值,求最高的工资
select max(PeopleSalary) 最高工资 from People

3.求最小值,求最小的工资
select min(PeopleSalary) from People

4.求和,求所有员工的工资总和
select sum(PeopleSalary) 总和工资 from People

5.求平均值,求所有员工的平均工资
select avg(PeopleSalary) 平均工资 from People

我们会发现这后面会有很多小数点,这时候我们可以用到一个函数啦!round这个函数
select round(avg(PeopleSalary),2) from People
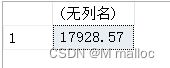
6.求数量,最大值,最小值,总和,平均值,在一行显示
select count(*) 人数,max(PeopleSalary) 最高工资,min(PeopleSalary),sum(PeopleSalary) 总和工资,round(avg(PeopleSalary),2) from People
这一题就是把前面的全部整合到一起啦!

7.查出武汉地区的数量,最大值,最小值,总和,平均值,在一行显示
这里我们发现还多加了一个条件,需要有指定的城市也很简单啦!
select count(*) 人数,max(PeopleSalary) 最高工资,min(PeopleSalary),sum(PeopleSalary) 总和工资,round(avg(PeopleSalary),2) from People where PeopleAddress = '武汉'

8.求出工资比平均工资高的人员信息
select * from People where PeopleSalary >
(select avg(PeopleSalary) from People)

这里运用到了一个子查询,首先我们可以先把工资求出来,然后再通过子查询查询到平均工资,这样在做一个比较就行啦!
9.求数量,年龄最大值,最小值,年龄总和,年龄平均值
在查询年龄的时候,我们可以运用到一个函数,year(),它可以返回对应的年份,在运用一个函数getdate(),这个函数的作用就是求出实时的年月日,再用实时的年月减去出生的年就行啦!
select *,year(getdate()) - year(PeopleBirth) 年龄 from People
select count(*),
max(year(getdate()) - year(PeopleBirth)) 最高年龄,
min(year(getdate()) - year(PeopleBirth)) 最低年龄,
sum(year(getdate()) - year(PeopleBirth)) 年龄总和,
avg(year(getdate()) - year(PeopleBirth)) 平均年龄
from People
![[MySQL]不允许你不会SQL语句之查询语句_第3张图片](http://img.e-com-net.com/image/info8/aa68bc50b0114d278f4bea5dfa66f7a2.jpg)
10.计算出月薪在10000以上的男性,年龄最大值,最小值,年龄总和,年龄平均值
这一道题目就是做了一个条件的限制,我们需要在后面加上限制条件就行啦!
select '月薪在10000以上' 月薪,'男' 性别,
count(*),
max(year(getdate()) - year(PeopleBirth)) 最高年龄,
min(year(getdate()) - year(PeopleBirth)) 最低年龄,
sum(year(getdate()) - year(PeopleBirth)) 年龄总和,
avg(year(getdate()) - year(PeopleBirth)) 平均年龄
from People where PeopleSalary > 10000 and PeopleSex = '男'

11.统计出所在地在武汉或者北京’,年龄最大值,最小值,年龄总和,年龄平均值
select count(*),
max(year(getdate()) - year(PeopleBirth)) 最高年龄,
min(year(getdate()) - year(PeopleBirth)) 最低年龄,
sum(year(getdate()) - year(PeopleBirth)) 年龄总和,
avg(year(getdate()) - year(PeopleBirth)) 平均年龄
from People where PeopleAddress in('武汉','北京') and PeopleSex = '女'
![[MySQL]不允许你不会SQL语句之查询语句_第4张图片](http://img.e-com-net.com/image/info8/be60e51fc7ab478dbaa757ef7fece84d.png)
我们会发现此时我们的表中无值的!
12.求出年龄比平均年龄高的员工信息
这里首先我们可以先通过子查询查出平均年龄的信息,然后再用表中的年龄信息与平均年龄信息进行比较,如果大于平均年龄则输出就行啦!
select * from People where (year(getdate()) - year(PeopleBirth)) > (select avg(year(getdate())- year(PeopleBirth)) from People)

分组查询(group by)
1.根据员工所在地区分组统计员工人数,员工工资总和,平均工资,最高工资,最低工资
首先在分组查询的过程中,我们需要先看题目要求对谁分组,这里是对地区分组,所以我们group by的就是PeopleAddress
select PeopleAddress 地区, count(*),sum(PeopleSalary),avg(PeopleSalary),max(PeopleSalary),min(PeopleSalary) from People
group by PeopleAddress
![[MySQL]不允许你不会SQL语句之查询语句_第5张图片](http://img.e-com-net.com/image/info8/fef983fc69b14006a2177a817cf49147.png)
2.根据员工所在地区分组统计员工人数,员工工资总和,平均工资,最高工资,最低工资,1985年以后出身的员工不参与统计
从这里我们看到,这里还加了一些个条件,此时我们就需要用where来进行限制啦!
select PeopleAddress 地区, count(*),sum(PeopleSalary),avg(PeopleSalary),max(PeopleSalary),min(PeopleSalary) from People
where PeopleBirth < '1985-1-1'
group by PeopleAddress
![[MySQL]不允许你不会SQL语句之查询语句_第6张图片](http://img.e-com-net.com/image/info8/8ef326f926d14de2a78f3c52b36b8eeb.png)
3.根据员工所在地区分组统计员工人数,员工工资总和,平均工资,最高工资,最低工资,要求员工人数至少在两个人及以上的,1985年以后出身的员工不参与统计
select PeopleAddress 地区, count(*),sum(PeopleSalary),avg(PeopleSalary),max(PeopleSalary),min(PeopleSalary) from People
where PeopleBirth < '1985-1-1'
group by PeopleAddress having count(*) >= 2
当我们用了group by时,我们的where里面就不可以用聚合函数了,所以此时我们需要用having这个关键字!

总结
今天的分享就到此为止啦!我们下期再见啦!一定要好好吸收啊!我是爱你们的M malloc
![[MySQL]不允许你不会SQL语句之查询语句_第7张图片](http://img.e-com-net.com/image/info8/7488710a5b334c8c9bc0d45b64e40847.jpg)
