史上最强!Spring Boot 3.3 高效批量插入万级数据的多种方案
SpringBoot 3.3 多种方式实现高效批量插入万级数据,史上最强!
在大数据处理场景下,如何高效地将大量数据插入数据库是一个重要课题。本文基于SpringBoot 3.3及MyBatis-Plus,介绍几种高效的批量插入数据的方法,包括:
使用JDBC批处理
使用自定义SQL批处理
单条插入(for循环)
拼接SQL语句插入
MyBatis-Plus的saveBatch方法
循环插入 + 开启批处理模式
每种方式都会结合代码示例进行深入讲解,前端将展示每种插入方式的执行时间,帮助你直观了解每种方法的性能表现。
运行效果:
若想获取项目完整代码以及其他文章的项目源码,且在代码编写时遇到问题需要咨询交流,欢迎加入下方的知识星球。
项目依赖配置(pom.xml)
首先,在项目的pom.xml中添加必要的依赖:
4.0.0
org.springframework.boot
spring-boot-starter-parent
3.3.3
com.icoderoad
batch-insert
0.0.1-SNAPSHOT
batch-insert
Demo project for Spring Boot
17
3.5.7
3.0.3
org.springframework.boot
spring-boot-starter-web
com.baomidou
mybatis-plus-boot-starter
${mybatis-plus-boot-starter.version}
org.mybatis
mybatis-spring
${mybatis-spring.version}
com.mysql
mysql-connector-j
runtime
org.springframework.boot
spring-boot-starter-thymeleaf
org.projectlombok
lombok
true
org.springframework.boot
spring-boot-starter-test
test
org.springframework.boot
spring-boot-maven-plugin
配置文件(application.yml)
在application.yml中,配置数据库连接信息:
spring:
datasource:
url: jdbc:mysql://localhost:3306/mydb?useSSL=false&serverTimezone=UTC
username: root
password: password
driver-class-name: com.mysql.cj.jdbc.Driver
thymeleaf:
cache: false
数据库表结构(user 表的DDL)
在开始实现之前,我们需要创建一个用户表user。下面是其DDL语句:
CREATE TABLE user (
id BIGINT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(50) NOT NULL,
age INT NOT NULL
);
后端实现
使用JDBC批处理
原理
JDBC批处理通过PreparedStatement的addBatch和executeBatch方法一次性提交多条SQL插入操作。这种方法直接利用JDBC的批处理机制,可以显著提高插入效率。
优点
-
高性能:JDBC的批处理机制可以提高性能,减少数据库交互的次数。
-
标准化:使用标准的JDBC API,不依赖于特定的ORM框架。
缺点
-
需要手动管理:需要手动管理批处理的大小、事务等,代码复杂度较高。
-
资源管理:需要确保JDBC连接和
PreparedStatement的正确关闭,避免资源泄漏。
适用场景
适用于需要高性能插入操作的场景,特别是当需要直接控制数据库交互的细节时。
@Service
public class UserService {
@Autowired
private DataSource dataSource;
public void insertUsersWithJdbcBatch(List users) {
String sql = "INSERT INTO user (name, age) VALUES (?, ?)";
try (Connection conn = dataSource.getConnection();
PreparedStatement ps = conn.prepareStatement(sql)) {
for (User user : users) {
ps.setString(1, user.getName());
ps.setInt(2, user.getAge());
ps.addBatch();
}
ps.executeBatch();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
使用自定义SQL批处理
原理
自定义SQL批处理通过使用JdbcTemplate的batchUpdate方法,将多个插入操作打包成一个批量操作一次性提交。这种方法结合了Spring的JdbcTemplate和自定义的SQL批处理。
优点
-
灵活性:可以自定义SQL语句并批量处理,提高灵活性。
-
简化操作:
JdbcTemplate简化了JDBC操作,避免了复杂的手动资源管理。
缺点
-
SQL语句复杂性:需要编写和管理复杂的SQL语句,增加了维护成本。
-
性能调优:需要控制批处理的大小和其他性能相关参数。
适用场景
适用于需要复杂插入逻辑和自定义SQL的场景,特别是当数据处理逻辑需要高度自定义时。
@Service
public class UserService {
@Autowired
private JdbcTemplate jdbcTemplate;
public void insertUsersWithCustomBatch(List users) {
List batchArgs = new ArrayList<>();
for (User user : users) {
batchArgs.add(new Object[]{user.getName(), user.getAge()});
}
jdbcTemplate.batchUpdate("INSERT INTO user (name, age) VALUES (?, ?)", batchArgs);
}
}
单条插入(for循环)
原理
单条插入方法通过遍历每个用户对象,逐个调用insert方法将数据插入到数据库中。这种方法通常在MyBatis-Plus中使用baseMapper.insert(user)实现。
优点
-
简单直接:实现起来非常简单,不需要额外的配置或复杂的逻辑。
-
调试方便:在调试阶段容易追踪每条记录的插入过程。
缺点
-
性能较差:每次插入操作都涉及到一次数据库交互,这会导致大量的网络延迟和数据库操作开销。
-
数据库压力大:对数据库的负载较重,可能会导致性能瓶颈,特别是当数据量很大时。
适用场景
适用于数据量较小或者对插入性能要求不高的场景。对于大批量数据插入,不建议使用这种方法。
@Service
public class UserService {
@Autowired
private UserMapper userMapper;
public void insertUsersOneByOne(List users) {
for (User user : users) {
userMapper.insert(user);
}
}
}
拼接SQL语句插入
原理
拼接SQL语句方法通过将所有插入记录拼接成一条长SQL语句,然后一次性提交到数据库。这种方法通过将多个插入操作合并到一个SQL语句中,可以大大减少数据库交互的次数。
优点
-
性能提升:减少了与数据库的交互次数,从而提高了插入性能。
-
数据库负载较轻:由于减少了网络和数据库操作的开销,数据库的负载相对较轻。
缺点
-
SQL长度限制:如果数据量过大,生成的SQL语句可能会超出数据库的长度限制。
-
SQL注入风险:需要确保拼接的SQL语句不会引入SQL注入风险,特别是在处理动态数据时。
适用场景
适用于数据量中等且对性能有一定要求的场景,但需要注意SQL长度和安全问题。
@Service
public class UserService {
@Autowired
private UserMapper userMapper;
public void insertUsersBySql(List users) {
StringBuilder sql = new StringBuilder("INSERT INTO user (name, age) VALUES ");
for (User user : users) {
sql.append(String.format("('%s', %d),", user.getName(), user.getAge()));
}
sql.deleteCharAt(sql.length() - 1);
userMapper.insertBySql(sql.toString());
}
}
MyBatis-Plus的saveBatch方法
原理
saveBatch方法是MyBatis-Plus提供的批量插入方法。它使用批量插入的方式一次性插入多个记录。MyBatis-Plus内部会自动处理批量操作,通常使用JDBC的批处理功能。
优点
-
性能较高:MyBatis-Plus内部优化了批量插入的实现,相比单条插入性能更好。
-
简单易用:只需要调用一个方法,无需手动拼接SQL或处理数据库交互。
缺点
-
批量大小限制:虽然性能较好,但仍然需要控制批量大小以避免过大的数据包造成问题。
-
灵活性较低:如果需要复杂的批处理逻辑,
saveBatch可能无法满足需求。
适用场景
适用于需要高效插入大量数据的场景,特别是当数据量较大且需要优化性能时。
@Service
public class UserService {
@Autowired
private UserMapper userMapper;
public void saveUsersBatch(List users) {
userMapper.saveBatch(users);
}
}
循环插入 + 开启批处理模式
原理
循环插入+批处理模式利用JDBC的批处理功能。通过在循环中将插入操作添加到批处理列表中,然后一次性提交所有操作。这种方法通常使用SqlSession的ExecutorType.BATCH模式。
优点
-
性能提升:使用批处理模式可以显著提高插入性能,因为它减少了数据库交互的次数。
-
灵活性较高:可以在批处理过程中执行更复杂的操作。
缺点
-
内存消耗:需要在内存中维护一个批处理列表,如果数据量过大,可能会导致内存消耗较高。
-
配置复杂:需要配置JDBC批处理的相关参数,并管理事务。
适用场景
适用于需要处理大量数据且对性能要求较高的场景,尤其是当数据量特别大时。
@Service
public class UserService {
@Autowired
private SqlSessionFactory sqlSessionFactory;
public void insertUsersWithBatchProcessing(List users) {
SqlSession session = sqlSessionFactory.openSession(ExecutorType.BATCH, false);
try {
for (User user : users) {
session.insert("com.example.UserMapper.insert", user);
}
session.commit();
} finally {
session.close();
}
}
}
完整项目实现:
MyBatis-Plus 实体类
首先,我们定义一个User实体类,用于映射数据库中的user表。
package com.icoderoad.batchinsert.entity;
import com.baomidou.mybatisplus.annotation.IdType;
import com.baomidou.mybatisplus.annotation.TableId;
import com.baomidou.mybatisplus.annotation.TableName;
import lombok.Data;
@Data
@TableName("user")
public class User {
@TableId(type = IdType.AUTO)
private Long id;
private String name;
private Integer age;
public User(String name, Integer age) {
this.name = name;
this.age = age;
}
}
MyBatis-Plus Mapper 接口
定义一个UserMapper接口,继承自BaseMapper。
@Mapper
public interface UserMapper extends BaseMapper {
@Insert("${sql}")
void insertBySql(@Param("sql") String sql);
}
Service 接口
定义一个UserService接口,包含多个插入方法。
package com.icoderoad.batchinsert.service;
import java.util.List;
import com.baomidou.mybatisplus.extension.service.IService;
import com.icoderoad.batchinsert.entity.User;
public interface UserService extends IService {
long insertUsersOneByOne(List users);
long insertUsersBySql(List users);
long saveUsersBatch(List users);
long insertUsersWithBatchProcessing(List users);
long insertUsersWithJdbcBatch(List users);
long insertUsersWithCustomBatch(List users);
}
ServiceImpl 实现类
UserServiceImpl类实现UserService接口中的方法,每个方法返回执行时间。
package com.icoderoad.batchinsert.service.impl;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.SQLException;
import java.util.ArrayList;
import java.util.List;
import javax.sql.DataSource;
import org.apache.ibatis.session.ExecutorType;
import org.apache.ibatis.session.SqlSession;
import org.apache.ibatis.session.SqlSessionFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.jdbc.core.JdbcTemplate;
import org.springframework.stereotype.Service;
import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl;
import com.icoderoad.batchinsert.entity.User;
import com.icoderoad.batchinsert.mapper.UserMapper;
import com.icoderoad.batchinsert.service.UserService;
@Service
public class UserServiceImpl extends ServiceImpl implements UserService {
@Autowired
private UserMapper userMapper;
@Autowired
private SqlSessionFactory sqlSessionFactory;
@Autowired
private DataSource dataSource;
@Autowired
private JdbcTemplate jdbcTemplate;
@Override
public long insertUsersOneByOne(List users) {
long startTime = System.currentTimeMillis();
for (User user : users) {
userMapper.insert(user);
}
return System.currentTimeMillis() - startTime;
}
@Override
public long insertUsersBySql(List users) {
long startTime = System.currentTimeMillis();
StringBuilder sql = new StringBuilder("INSERT INTO user (name, age) VALUES ");
for (User user : users) {
sql.append(String.format("('%s', %d),", user.getName(), user.getAge()));
}
sql.deleteCharAt(sql.length() - 1);
userMapper.insertBySql(sql.toString());
return System.currentTimeMillis() - startTime;
}
@Override
public long saveUsersBatch(List users) {
long startTime = System.currentTimeMillis();
saveBatch(users); // MyBatis-Plus 提供的批量插入方法
return System.currentTimeMillis() - startTime;
}
@Override
public long insertUsersWithBatchProcessing(List users) {
long startTime = System.currentTimeMillis();
SqlSession session = sqlSessionFactory.openSession(ExecutorType.BATCH, false);
try {
for (User user : users) {
session.insert("com.example.UserMapper.insert", user);
}
session.commit();
} finally {
session.close();
}
return System.currentTimeMillis() - startTime;
}
@Override
public long insertUsersWithJdbcBatch(List users) {
long startTime = System.currentTimeMillis();
String sql = "INSERT INTO user (name, age) VALUES (?, ?)";
try (Connection conn = dataSource.getConnection();
PreparedStatement ps = conn.prepareStatement(sql)) {
for (User user : users) {
ps.setString(1, user.getName());
ps.setInt(2, user.getAge());
ps.addBatch();
}
ps.executeBatch();
} catch (SQLException e) {
e.printStackTrace();
}
return System.currentTimeMillis() - startTime;
}
@Override
public long insertUsersWithCustomBatch(List users) {
long startTime = System.currentTimeMillis();
List batchArgs = new ArrayList<>();
for (User user : users) {
batchArgs.add(new Object[]{user.getName(), user.getAge()});
}
jdbcTemplate.batchUpdate("INSERT INTO user (name, age) VALUES (?, ?)", batchArgs);
return System.currentTimeMillis() - startTime;
}
}
InsertController 类
在InsertController类中,每个方法调用UserService中的方法,并返回执行时间。
@RestController
@RequestMapping("/insert")
public class InsertController {
@Autowired
private UserService userService;
@PostMapping("/single")
public long insertSingle() {
return userService.insertUsersOneByOne(getSampleUsers());
}
@PostMapping("/sql")
public long insertSql() {
return userService.insertUsersBySql(getSampleUsers());
}
@PostMapping("/saveBatch")
public long saveBatch() {
return userService.saveUsersBatch(getSampleUsers());
}
@PostMapping("/batchProcessing")
public long batchProcessing() {
return userService.insertUsersWithBatchProcessing(getSampleUsers());
}
@PostMapping("/jdbcBatch")
public long jdbcBatch() {
return userService.insertUsersWithJdbcBatch(getSampleUsers());
}
@PostMapping("/customBatch")
public long customBatch() {
return userService.insertUsersWithCustomBatch(getSampleUsers());
}
private List getSampleUsers() {
List users = new ArrayList<>();
for (int i = 0; i < 10000; i++) {
users.add(new User("user" + i, i));
}
return users;
}
}
前端实现
在前端,我们通过Thymeleaf模板引擎和Bootstrap来展示各种插入方法,并显示其执行时间。
在src/main/resources/templates目录下创建index.html文件:
批量插入数据演示
批量插入数据演示
启动项目并测试
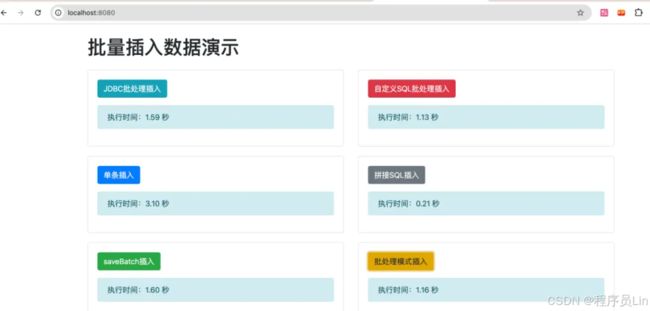
启动Spring Boot应用,访问http://localhost:8080/,点击不同类型的插入按钮,大家将看到插入的执行时间展示在页面上。在实际应用中,我们对不同的批量插入方式进行了性能测试。以下是测试结果:
-
JDBC批处理插入:执行时间:1.59 秒
-
自定义SQL批处理插入:执行时间:1.13 秒
-
单条插入:执行时间:3.10 秒
-
拼接SQL插入:执行时间:0.21 秒
-
saveBatch插入:执行时间:1.60 秒
-
批处理模式插入:执行时间:1.16 秒
从测试结果可以看出,各种插入方式在性能上有明显差异。拼接SQL插入方式在这次测试中表现最好,执行时间最短,而单条插入方式执行时间最长。其他方式的执行时间也有所不同,但都比单条插入要优越。
总结
在这篇文章中,我们深入探讨了几种在SpringBoot 3.3中实现高效批量插入数据的方法,包括JDBC批处理、自定义SQL批处理、单条插入、拼接SQL、MyBatis-Plus的`saveBatch和循环插入+批处理。每种方法都具有独特的优点和适用场景,在实际开发中可以根据需求选择最合适的方法。
通过前端页面的演示,用户可以方便地比较每种方法的执行时间,直观地了解各自的性能表现。这种全栈式的实现方式,结合了后端高效数据处理和前端直观展示,能够帮助开发者快速构建高性能的数据处理应用。
