Python的界面神器Streamlit初使用,一个漂亮的界面有多简单,超乎想象
Python的界面神器Streamlit初使用,一个漂亮的界面有多简单,超乎想象
废话不多说,直接上干货
- 首先安装好所需要的库
pip install streamlit
- 新建一个 Python 文件(test.py),导入所需要的库,
import streamlit as st
import pandas as pd
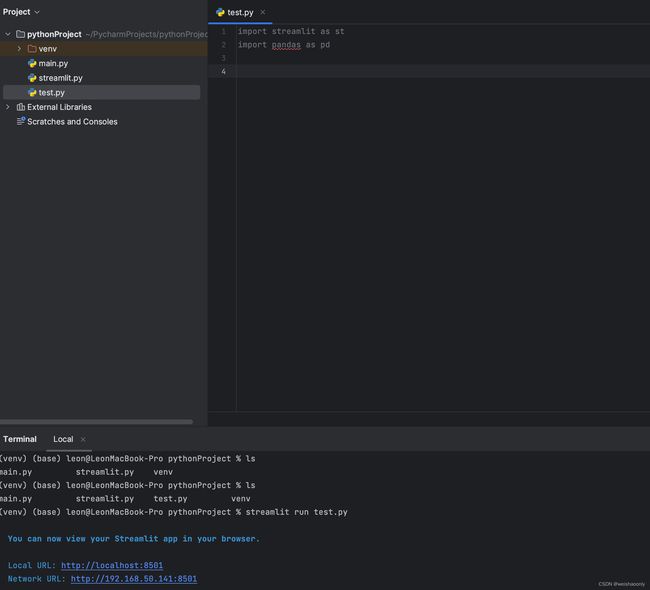
- 打开命令,行输入命令,
streamlit run test.py
-
启动服务,可以看到输出信息证明已经成功启动了一个服务,浏览器会自动打开这个地址。
-
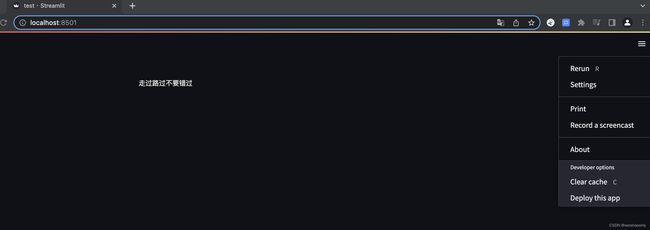
现在页面什么东西都没有,加一句代码,打印一些文字
import streamlit as st
import pandas as pd
st.text("走过路过不要错过")
保存文件,此时页面右上角出现了一些选项按钮,选择总是返回,回到代码修改内容,现在页面可以自动刷新了。
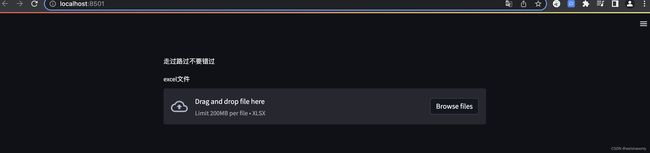
接下来添加一个文件上传的组件参数type,指定接受的文件后缀名可以指定多种文件类型,所以是一个列表函数返回的是一个文件对象。我们可以直接使用 Pandas 读取数据,然后试试输出到界面上,这里有一个快捷方式,直接把变量 df写在这里,就会在界面上显示成一个表格。不过保存文件后发现页面出现报错信息。
uploaded_file = st.file_uploader('excel文件',type=['xlsx'])
df = pd.read_excel(uploaded_file)
st.dataframe(df)

streamlit每次页面更新都会执行一遍代码,我们还没有选择任何文件,所以文件上传组件的函数返回了一个None,到了 Pandas 加载数据就会报错。

这里要划重点了。 streamlit与其他框架非常不一样的地方就在于,我们写的代码就像一个描述了整个界面的文档, streamlit 每次都要从头到尾执行一次,才能知道画面上应该描绘出哪些内容。因此每当调用一个组件函数,就要注意判断空的情况。这里在上传组件函数之后,判断返回的文件对象是否有东西。这里有一个技巧,逻辑,尽可能描述空的情况下,然后跳出执行有专门的函数 stop 做这个事情,这样可以避免我们的代码出现大量的判断嵌套。
uploaded_file= st.file_uploader('excel文件',type=['xlsx'])
if uploaded_file is None:
st.stop()
选择一个文件看看效果,可以正常显示。接着我们让 Pandas 一次性加载所有的工作表,不需要直接显示数据,而是做一个下拉列表框,让用户选择工作表名字,看看页面效果。
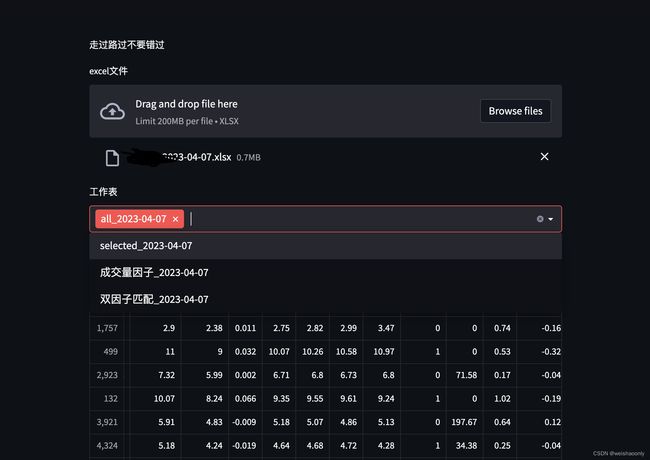
为了让大家更好理解其过程,我们再次分解其显示过程。第一次执行时,上传文件组件函数由于没有选择任何文件,所以返回了none,从而在下面的判断中执行了stop。因此这次执行只收集到上传文件组件的描绘,页面只显示这个组件。在页面上点击组件,选择了一个文件,页面上的上传文件组件数据有了变化,于是页面通知后台重新执行一遍代码,同时页面把上传文件组件的文件数据返回给后台,代码开始重新执行第一句代码时,函数返回了页面给的文件数据,因此函数有了返回值,不再是None。后续的创建,下拉选择框的代码也顺利被执行。本次执行结果收集到两个组件的创建信息,所以页面上创建了下拉框。接下来使用多选下拉框函数返回的列表创建页签,每个页签内创建表格即可。千万别忘了,如果没有选择任何工作表,要提前跳出执行看看,效果,很不错。
dfs=pd.read_excel(uploaded_file,None)
names = list(dfs.keys())
sheet_selected = st.multiselect('工作表',names,[])
if len(sheet_selected) == 0:
st.stop()
tabs = st.tabs(sheet_selected)
for tab,name in zip(tabs,sheet_selected):
with tab:
df = dfs[name]
st.dataframe(df)
根据streamlit的更新规则,不管页面上的任何组件有变化,整个代码都会被重新执行,那就意味着意味着 Pandas 加载数据的代码会被重复执行很多次。实际上数据文件根本没有变化,有没有什么办法可以让它只在我们重新选择其他文件的时候才执行?加载数据?方法很简单,独定义一个函数,接收文件对象,函数里面就是 Pandas 加载数据的代码,然后在函数上方打上装饰器,表明这是一个缓存函数,为了证明其缓存函数生效,我们在函数里面打印内容,到控制台。
@st.cache_data
def load_data(file):
print("正在执行加载数据......")
return pd.read_excel(file,None)
dfs=pd.read_excel(uploaded_file,None)
names = list(dfs.keys())
sheet_selected = st.multiselect('工作表',names,[])
if len(sheet_selected) == 0:
st.stop()
tabs = st.tabs(sheet_selected)
for tab,name in zip(tabs,sheet_selected):
with tab:
df = dfs[name]
st.dataframe(df)