python库streamlit学习笔记
什么是streamlit?
Streamlit是一个免费的开源框架,用于快速构建和共享漂亮的机器学习和数据科学Web应用程序。它是一个基于Python的库,专为机器学习工程师设计。数据科学家或机器学习工程师不是网络开发人员,他们对花几周时间学习使用这些框架来构建网络应用程序不感兴趣。相反,他们需要一个更容易学习和使用的工具,只要它可以显示数据并收集建模所需的参数。Streamlit允许您仅用几行代码创建一个外观惊艳的应用程序。
数据科学家为何要使用Streamlit?
Streamlit最大的好处是,您甚至不需要了解Web开发的基础知识就可以开始或创建您的第一个Web应用程序。因此,如果你是一个对数据科学感兴趣的人,你想轻松、快速地部署你的模型,并且只需要几行代码,Streamlit是一个很好的选择。
使应用程序成功的一个重要方面是提供有效和直观的用户界面。许多现代的数据密集型应用程序都面临着快速构建有效用户界面的挑战,而无需采取复杂的步骤。Streamlit是一个很有前途的开源Python库,它使开发人员能够立即构建有吸引力的用户界面。
Streamlit是最简单的方法,尤其是对于没有前端知识的人来说,可以将他们的代码放到Web应用程序中:
- 没有前端(html,js,css)的经验或知识是必需的。
- 你不需要花费几天或几个月的时间来创建一个Web应用,你可以在几个小时甚至几分钟内创建一个非常漂亮的机器学习或数据科学应用。
- 它兼容大多数Python库(例如panda、matplotlib、seaborn、plotly、Keras、PyTorch、SymPy(latex))。
- 创建令人惊叹的Web应用程序需要更少的代码。
- 数据缓存简化并加速了计算。
如何使用Streamlit
在Windows上:
1.安装Anaconda并创建您的环境
2. 打开终端
在终端中键入以下命令以安装Streamlit:
pip install streamlit
测试安装是否正常:
streamlit hello
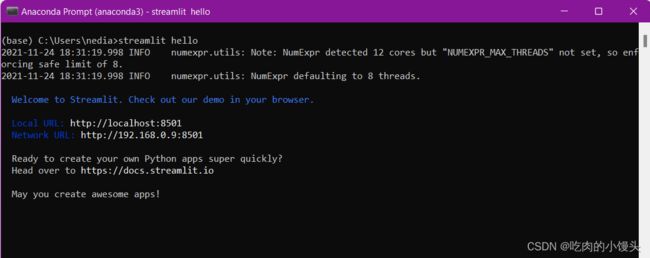
当您在终端中键入此命令时,应自动打开以下页面:

如何运行Streamlit代码
streamlit run file_name.py
精简命令易于编写和理解。只需一个简单的命令,您就可以显示文本、媒体、小部件、图形等。
使用Streamlit显示文本
首先,我们将了解如何向Streamlit应用添加文本,以及添加文本时使用的不同命令。
st.write():该函数用于向Web应用程序添加任何内容,从格式化字符串到matplotlib图中的图表、Altair图、plotly图、数据框、Keras模型等。
import streamlit as st
st.write("Hello ,let's learn how to build a streamlit app together")

st.title():此函数允许您添加应用程序的标题。st.header():此函数用于设置节的标题。st.markdown():该函数用于设置某个部分的降价。st.subheader():该函数用于设置一个小节的子标题。st.caption():该函数用于编写字幕。st.code():该函数用于设置代码。st.latex():该函数用于显示LaTeX格式的数学表达式。
st.title ("this is the app title")
st.header("this is the markdown")
st.markdown("this is the header")
st.subheader("this is the subheader")
st.caption("this is the caption")
st.code("x=2021")
st.latex(r''' a+a r^1+a r^2+a r^3 ''')

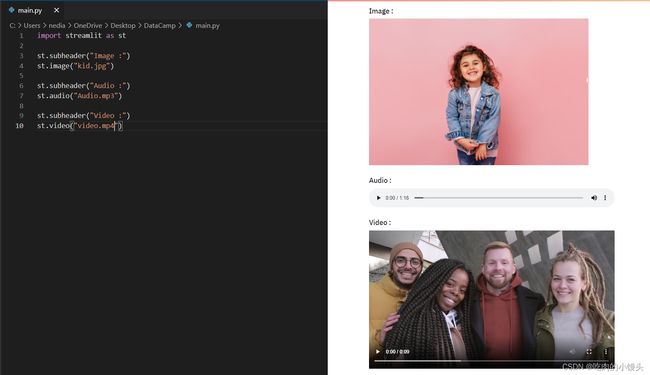
使用Streamlit显示图像、视频或音频文件
您无法找到像Streamlit功能那样简单的功能来显示图像、视频和音频文件。让我们来看看如何显示媒体与Streamlit!
st.image():该函数用于显示图像。st.audio ():此函数用于显示音频。st.video ():此函数用于显示视频。
st.image("kid.jpg")
st.audio("Audio.mp3")
st.video("video.mp4")
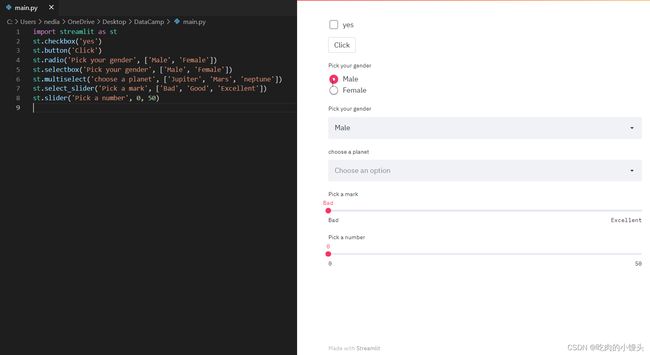
输入部件
小部件是最重要的用户界面组件。Streamlit有各种各样的小部件,可以让你通过按钮、滑块、文本输入等直接将交互性融入到你的应用程序中。
st.checkbox():该函数返回一个布尔值。选中该框时,返回True值,否则返回False值。st.button():该函数用于显示按钮控件。st.radio ():此函数用于显示单选按钮小部件。st.selectbox():该函数用于显示一个选择小部件。st.multiselect():该函数用于显示多选小部件。st.select _slider():此函数用于显示选择滑块小部件。st.slider():该函数用于显示滑块小部件。
st.checkbox('yes')
st.button('Click')
st.radio('Pick your gender',['Male','Female'])
st.selectbox('Pick your gender',['Male','Female'])
st.multiselect('choose a planet',['Jupiter', 'Mars', 'neptune'])
st.select_slider('Pick a mark', ['Bad', 'Good', 'Excellent'])
st.slider('Pick a number', 0,50)
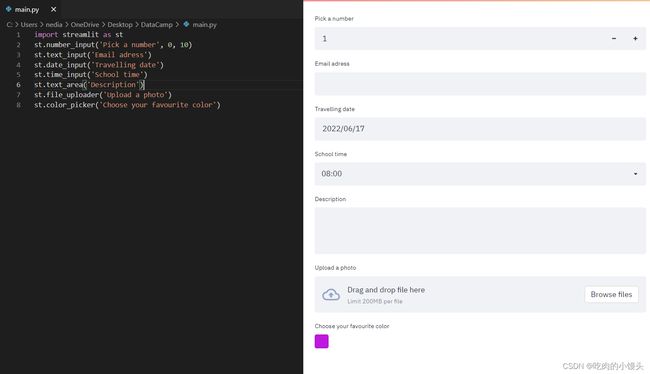
st.number_input():此函数用于显示一个数字输入小部件。st.text_input():这个函数用于显示文本输入小部件。st.date _input():此函数用于显示一个日期输入小部件以选择日期。st.time_input():此函数用于显示时间输入小部件,以选择时间。st.text_area():这个函数用于显示一个文本输入小部件,其中包含多行文本。st.file_uploader():此函数用于显示一个文件上载器小部件。st.color_picker():该函数用于显示颜色选择器小部件以选择颜色。
st.number_input('Pick a number', 0,10)
st.text_input('Email address')
st.date_input('Travelling date')
st.time_input('School time')
st.text_area('Description')
st.file_uploader('Upload a photo')
st.color_picker('Choose your favorite color')
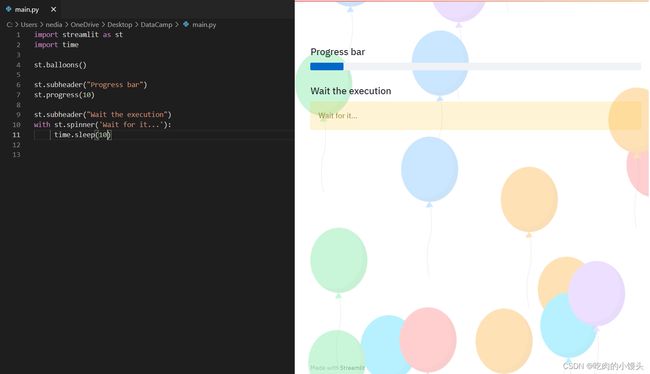
使用Streamlit显示进度和状态
现在,我们将了解如何向应用程序添加进度条和状态消息,例如错误和成功。
st.balloons():此函数用于显示庆祝用的气球。st.progress():该函数用于显示进度条。st.spinner():该函数用于显示执行过程中的临时等待消息。
st.balloons()
st.progress(10)
with st.spinner('Wait for it...'):
time.sleep(10)
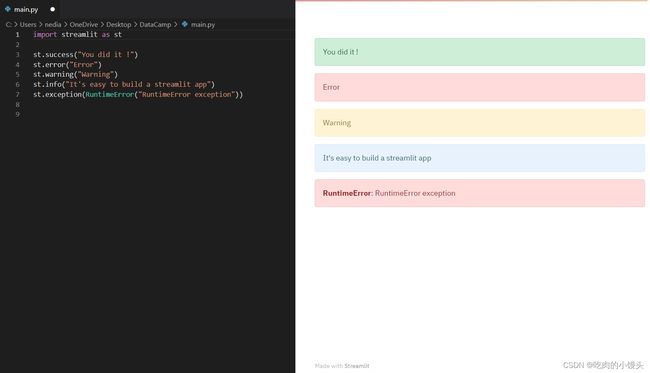
st.success():该函数用于显示成功消息。st.error():该函数用于显示错误消息。st.warnig():该函数用于显示警告消息。st.info ():此函数用于显示信息性消息。st.exception():该函数用于显示异常消息。
st.success("You did it !")
st.error("Error")
st.warnig("Warning")
st.info("It's easy to build a streamlit app")
st.exception(RuntimeError("RuntimeError exception"))
边栏和容器
您还可以在页面上创建侧栏或容器来组织应用。应用上页面的层次结构和排列方式会对用户体验产生很大影响。通过组织您的内容,您可以让访问者了解和浏览您的网站,这有助于他们找到他们正在寻找的东西,并增加他们将来返回的可能性。
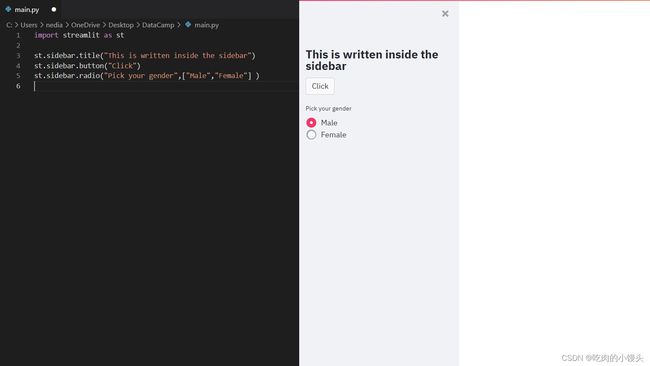
边栏
将元素传递给st.sidebar()会使该元素固定在左侧,从而允许用户关注应用中的内容。
但是 st.spinner()和st.echo()不受st.sidebar支持。
如您所见,您可以在应用界面中创建一个侧边栏,并在其中放置元素,这将使您的应用更有条理、更易于理解。
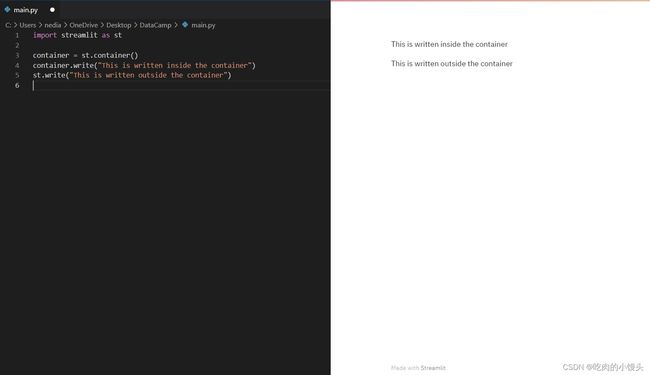
容器
st.container()用于创建一个不可见的容器,您可以在其中放置元素,以便创建有用的排列和层次结构。
Streamlit用于显示图形
数据可视化通过将数据整理成更易于理解的格式、突出显示趋势和异常值来帮助讲述故事。一个好的可视化可以讲述一个故事,消除数据中的噪音并突出有用的信息。然而,这并不像修饰图表使其看起来更好或在信息图表的“信息”部分打个耳光那么简单。有效的数据可视化是形式和功能之间的微妙平衡。最简单的图表可能太过枯燥,无法吸引注意力或传达有力的信息,而最令人惊叹的可视化可能完全无法传达正确的信息。数据和视觉效果需要协同工作,将出色的分析和出色的故事讲述结合起来是一门艺术。
你认为在一个表/数据库文件中给你一百万个点的数据,并要求你仅仅通过查看该表中的数据来提供你的推断是可行的吗?除非你是超人,否则不可能。这就是我们利用数据可视化的时候–它通过地图或图表提供信息的可视环境,让我们清楚地了解信息的含义。这就是Streamlit可视化的强大功能。
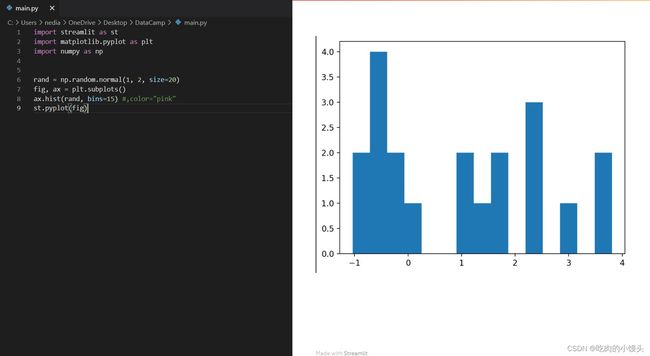
st.pyplot():该函数用于显示matplotlib.pyplot图形。
import streamlit as st
import matplotlib.pyplot as plt
import numpy as np
rand=np.random.normal(1, 2, size=20)
fig, ax = plt.subplots()
ax.hist(rand, bins=15)
st.pyplot(fig)
st.line_chart():该函数用于显示折线图。
import streamlit as st
import pandas as pd
import numpy as np
df= pd.DataFrame(np.random.randn(10, 2),columns=['x', 'y'])
st.line_chart(df)
st.bar _chart():此函数用于显示条形图。
import streamlit as st
import pandas as pd
import numpy as np
df= pd.DataFrame(np.random.randn(10, 2),columns=['x', 'y'])
st.bar_chart(df)
st.area_chart():该函数用于显示面积图。
import streamlit as st
import pandas as pd
import numpy as np
df= pd.DataFrame(np.random.randn(10, 2),columns=['x', 'y'])
st.area_chart(df)
st.altair_chart():该函数用于显示一个牛郎星图表。
import streamlit as st
import numpy as np
import pandas as pd
import altair as alt
df = pd.DataFrame(np.random.randn(500, 3), columns=['x','y','z'])
c = alt.Chart(df).mark_circle().encode(x='x', 'y'=y , size='z', color='z', tooltip=['x', 'y', 'z'])
st.altair_chart(c, use_container_width=True)
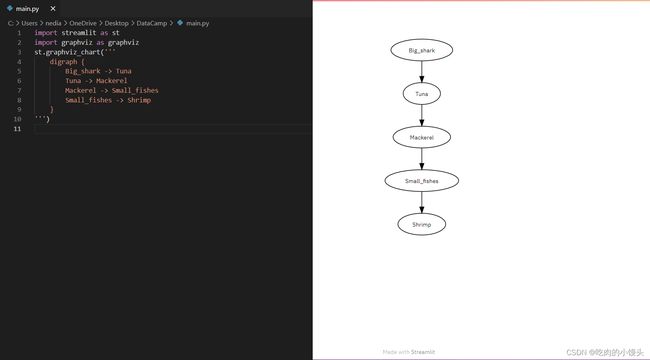
st.graphviz_chart():该函数用于显示图形对象,可以使用不同的节点和边来完成。
import streamlit as st
import graphviz as graphviz
st.graphviz_chart('''digraph {
Big_shark -> Tuna
Tuna -> Mackerel
Mackerel -> Small_fishes
Small_fishes -> Shrimp
}'''
)
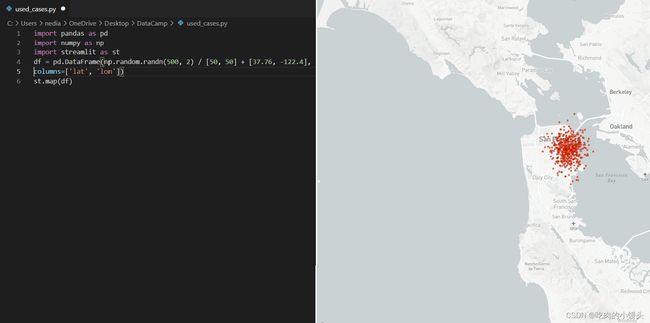
使用Streamlit显示地图
st.map ():此函数用于在应用中显示地图,但需要纬度和经度的值,这些值不应为null/NA。
import pandas as pd
import numpy as np
import streamlit as st
df = pd.DataFrame(np.random.randn(500, 2) / [50, 50] + [37.76, -122.4],columns=['lat', 'lon'])
st.map(df)
构建机器学习应用程序
在本节中,我将带你完成一个关于贷款预测的项目。
贷款的主要利润直接来自贷款利息。贷款公司在经过密集的核实和确认程序后发放贷款。然而,他们仍然没有保证,如果申请人能够偿还贷款没有困难。在本教程中,我们将构建一个预测模型(随机森林分类器)来预测申请人的贷款状态。我们的使命是准备一个Web应用程序,使其在生产中可用。
从导入应用所需的库开始:
import streamlit as st
import pandas as pd
import numpy as np
import pickle #to load a saved modelimport base64 #to open .gif files in streamlit app
在此应用程序中,我们将使用多个小部件作为滑块:侧边栏菜单中的selectbox和radio,我们将为此准备一些Python函数。这个例子将是一个简单的演示,有两页。在主页上,它将显示我们选择的数据,而Exploration页面将允许您在图中可视化变量,Prediction页面将包含带有一个名为Predict的按钮的变量,该按钮将允许您估计贷款状态。下面的代码在侧边栏中提供了一个selectbox,允许您选择页面。数据被缓存,因此不需要不断地重新加载。
@st.cache是一种缓存机制,可让您的应用在从Web加载数据、操作大型数据集或执行高成本计算时保持高性能。
@st.cache(suppress_st_warning=True)
def get_fvalue(val):
feature_dict = {"No":1,"Yes":2}
for key,value in feature_dict.items():
if val == key:
return value
def get_value(val,my_dict):
for key,value in my_dict.items():
if val == key:
return value
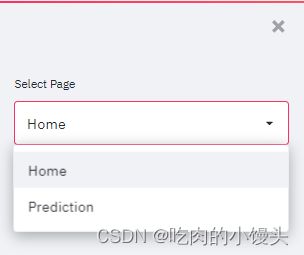
app_mode = st.sidebar.selectbox('Select Page',['Home','Prediction']) #two pages
在主页中,我们将可视化:申请人收入和贷款金额的展示图片/数据集/直方图。
注意:我们将使用if/elif/else在页面之间切换。
我们将以变量数据的形式加载loan_dataset.csv,这样我们就可以在主页中显示其中的几行。
if app_mode=='Home':
st.title('LOAN PREDICTION :')
st.image('loan_image.jpg')
st.markdown('Dataset :')
data=pd.read_csv('loan_dataset.csv')
st.write(data.head())
st.markdown('Applicant Income VS Loan Amount ')
st.bar_chart(data[['ApplicantIncome','LoanAmount']].head(20))

然后在“预测”页中:
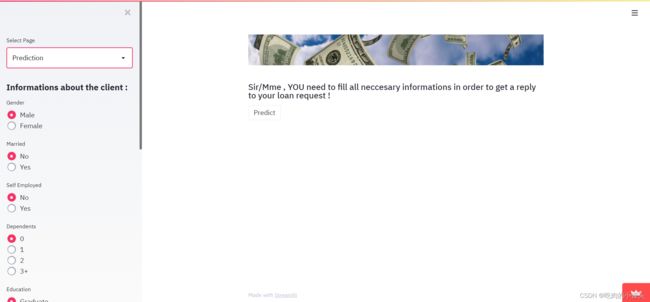
elif app_mode == 'Prediction':
st.image('slider-short-3.jpg')
st.subheader('Sir/Mme , YOU need to fill all necessary informations in order to get a reply to your loan request !')
st.sidebar.header("Informations about the client :")
gender_dict = {"Male":1,"Female":2}
feature_dict = {"No":1,"Yes":2}
edu={'Graduate':1,'Not Graduate':2}
prop={'Rural':1,'Urban':2,'Semiurban':3}
ApplicantIncome=st.sidebar.slider('ApplicantIncome',0,10000,0,)
CoapplicantIncome=st.sidebar.slider('CoapplicantIncome',0,10000,0,)
LoanAmount=st.sidebar.slider('LoanAmount in K$',9.0,700.0,200.0)
Loan_Amount_Term=st.sidebar.selectbox('Loan_Amount_Term',(12.0,36.0,60.0,84.0,120.0,180.0,240.0,300.0,360.0))
Credit_History=st.sidebar.radio('Credit_History',(0.0,1.0))
Gender=st.sidebar.radio('Gender',tuple(gender_dict.keys()))
Married=st.sidebar.radio('Married',tuple(feature_dict.keys()))
Self_Employed=st.sidebar.radio('Self Employed',tuple(feature_dict.keys()))
Dependents=st.sidebar.radio('Dependents',options=['0','1' , '2' , '3+'])
Education=st.sidebar.radio('Education',tuple(edu.keys()))
Property_Area=st.sidebar.radio('Property_Area',tuple(prop.keys()))
class_0 , class_3 , class_1,class_2 = 0,0,0,0
if Dependents == '0':
class_0 = 1
elif Dependents == '1':
class_1 = 1
elif Dependents == '2' :
class_2 = 1
else:
class_3= 1
Rural,Urban,Semiurban=0,0,0
if Property_Area == 'Urban' :
Urban = 1
elif Property_Area == 'Semiurban' :
Semiurban = 1
else :
Rural=1
我们编写了两个函数 获取值(val,my_dict) 以及 获取f值(val) 和字典 特征_字典 操纵 st.sidebar.radio ()带有非数值变量。这是可选的,你可以很容易地做这样的事情:
注意:机器学习算法无法处理分类变量。在数据集中,我做了一些特征工程。例如,Married列有两个变量“Yes”和“No”,我做了一个标签编码(看一看就能更好地理解),所以“NO”将等于1,“Yes”将等于2。函数get_fvalue(val)将根据客户端的选择轻松返回值(1/2)。函数get_value(val,my_dict)也是如此。这两个函数之间的区别在于,第一个函数适用于yes/no特征,而第二个函数适用于具有多个变量的一般情况(例如:性别)。
正如我们所看到的,变量Dependents有四个类别’0’,’ 1’,‘2’和’3+’,我们不能将这样的东西转换为一个数值变量,我们有’+3’,这意味着Dependents可以采取3,4,5 …我们做了一个One Hot Enconding(看一下就能更好地理解)因此,我们创建了一个包含四个元素的侧边栏单选框,每个元素都有一个二进制变量,如果客户端选择’0’,则class_0将等于1,其他元素将等于0。

我们还为Property_Area做了一个热编码,这就是为什么我们创建了3个变量(农村、城市、半城市),当农村取1时,其他变量将等于0。

所以我们已经看到了这两个-当我们标签或一个热编码我们的功能,以及如何处理它,以成功地创建一个工作的Streamlit应用程序。
data1={'Gender':Gender,'Married':Married,'Dependents':[class_0,class_1,class_2,class_3],'Education':Education,'ApplicantIncome':ApplicantIncome,'CoapplicantIncome':CoapplicantIncome,'Self Employed':Self_Employed,'LoanAmount':LoanAmount,'Loan_Amount_Term':Loan_Amount_Term,'Credit_History':Credit_History,'Property_Area':[Rural,Urban,Semiurban],}
feature_list=[ApplicantIncome,CoapplicantIncome,LoanAmount,Loan_Amount_Term,Credit_History,get_value(Gender,gender_dict),get_fvalue(Married),data1['Dependents'][0],data1['Dependents'][1],data1['Dependents'][2],data1['Dependents'][3],get_value(Education,edu),get_fvalue(Self_Employed),data1['Property_Area'][0],data1['Property_Area'][1],data1['Property_Area'][2]]
single_sample = np.array(feature_list).reshape(1,-1)
现在我们将变量存储在字典中,因为我们写了 获取值(val,my_dict) 以及 获取f值(val)来对付字典。之后,输入(客户端将在Streamlit应用程序中选择作为输入的内容)将排列在名为 特征列表 然后传递给一个名为 单样本。
注:要素的输入必须按照与数据集列相同的顺序排列(例如 已婚 不能接受…的输入 性别问题).
if st.button("Predict"):
file_ = open("6m-rain.gif", "rb")
contents = file_.read()
data_url = base64.b64encode(contents).decode("utf-8")
file_.close()
file = open("green-cola-no.gif", "rb")
contents = file.read()
data_url_no = base64.b64encode(contents).decode("utf-8")
file.close()
loaded_model = pickle.load(open('Random_Forest.sav', 'rb'))
prediction = loaded_model.predict(single_sample)
if prediction[0] == 0 :
st.error('According to our Calculations, you will not get the loan from Bank')
st.markdown(f' {data_url_no}" alt="cat gif">',unsafe_allow_html=True,)
elif prediction[0] == 1 :
st.success('Congratulations!! you will get the loan from Bank')
st.markdown(f'{data_url}" alt="cat gif">',unsafe_allow_html=True,)
{data_url_no}" alt="cat gif">',unsafe_allow_html=True,)
elif prediction[0] == 1 :
st.success('Congratulations!! you will get the loan from Bank')
st.markdown(f'{data_url}" alt="cat gif">',unsafe_allow_html=True,)
最后,我们将在中加载保存的RandomForestClassifier模型 加载_模型 和它的预测,它是0或1(分类问题)在 预测。.gif文件将存储在 锉 以及 文件–。取决于的值 预测,我们将有两种情况,“成功”或“失败”,从银行获得贷款。
这是我们的预测页面: