深入浅出opencv人脸识别,准确率95%,云服务器数据库存储人脸信息,代码全过程讲解以及心得
此文章记录自己从实现人脸识别到把识别到的数据上传到云端的数据库,随时随地只要有网就能登录服务器,查看人员进出的情况。我会把我记得的所有的错误和经验都分享出来,希望能对大家有所帮助也是对自己的一个总结。
视觉部分:采样,训练,识别
1:人脸采集:
首先输入学号和姓名,设定一个变量存储获取到人脸图片的数量,和存储图片的文件夹,然后打开摄像头开始捕捉人脸。(注意:存储路径的时候学号必须是str类型的)。进入while首先判断摄像头是否已经打开,如果没有就break退出while。
继续while里边,先转换为灰度图片,然后加载opencv库中的一个级联分类器文件,用于检测图像中是否存在人脸,是opencv中比较经典的人脸检测算法之一。
接下来是detectMultiScale函数,获取人脸,返回一个矩阵列表(gray是输入图像(灰度图),1.2表示每次图像缩小的比例为1.2,5表示每个矩形至少应该有5个邻居矩形。函数返回的结果保存在faces中,是一个矩形列表,每个矩形表示一个检测到的人脸的位置和大小)。
接着是判断有两人的情况下,如果face>于1就停止录入,每次只录入一个人脸,然后是绘制矩形框,frame是要绘制矩形框的图像。(x, y)是矩形框的左上角坐标。(x + w, y + h)是矩形框的右下角坐标。color=(0, 255, 0)表示矩形框的颜色,(0, 255, 0)表示绿色。thickness=2表示矩形框的线条粗细为2个像素。
锚出框后,写进数据库里面,便于训练
if __name__ == '__main__':
face_id = input('请输入学号:')
face_name = input('请输入姓名:')
print('请看向摄像头,3秒后开始采集300张人脸图片(可按ESC强制退出)...')
count = 0 # 统计照片数量
path = "./Picture_resources/Stu_" + str(face_id) # 人脸图片数据的储存路径
# 读取视频
cap = cv.VideoCapture(0)
time.sleep(3) # 给你3s,管理表情
while True:#捕捉人脸
flag, frame = cap.read()
if not flag:
break
# 将图片灰度
gray = cv.cvtColor(frame, cv.COLOR_BGR2GRAY)
# 加载特征数据
face_detector = cv.CascadeClassifier('haarcascade_frontalface_default.xml')
faces = face_detector.detectMultiScale(gray, 1.2, 5)
if not os.path.exists(path): # 如果没有对应文件夹,自动生成
os.makedirs(path)
if len(faces) > 1: # 一帧出现两张照片丢弃,原因:有人乱入,也有可能人脸识别出现差错
continue
# 框选人脸,for循环保证一个能检测的实时动态视频流
for x, y, w, h in faces:
cv.rectangle(frame, (x, y), (x + w, y + h), color=(0, 255, 0), thickness=2)
count += 1
cv.imwrite(path + '/' + str(count) + '.png', gray[y:y + h, x:x + w])
# 显示图片
cv.imshow('Camera', frame)
print('已采集成功人脸照片数量为:' + str(count))
if 27 == cv.waitKey(1) or count >= 300: # 按ESC可退出 默认采集300张照片
break
# 关闭资源
print('采集照片成功,3秒后退出程序...')
time.sleep(3)
cv.destroyAllWindows()
cap.release()2:人脸训练:
首先找到存放图片的文件夹,getImageAndLabels函数接收文件夹路径,
-----root 表示当前正在访问的文件夹路径
-----dirs 表示该文件夹下的子目录名list
------files 表示该文件夹下的文件list(也就是人脸照片)
imageFiles.append追加所有的的照片,准备训练
imagefile.replace('\\','/'),这行代码将\\替换为/,以便正确表示文件路径
id是来自云服务器数据库存储的id,这个点下面再介绍
下面几行就人脸采样类似,遍历检测到的人脸(在变量faces中),并使用切片操作(img_numpy[y:y+h,x:x+w])从输入图像中提取出对应的人脸区域,然后将其添加到人脸样本列表(facesSamples)中,并将对应的标签(id)添加到标签列表(ids)中。这些样本和标签可以用于训练人脸识别模型。返回框出来的人脸和对应的id
然后勇训练对象调用训练识别器 recognizer.train(faces,np.array(ids该方法会使用这些数据训练识别器,生成一个模型,该模型可以根据输入的人脸图像判断该人脸属于哪个标签或 ID。
具体算法实现过程可以参加这篇博客(27条消息) OpenCV人脸识别之LBPH算法(局部二值模式方法)_dongcidacigogogo的博客-CSDN博客
def getImageAndLabels(path):
facesSamples=[]
imageFiles = []
ids = []
for root, dirs, files in os.walk(path):
# 遍历文件
for file in files:
imageFiles.append(os.path.join(root, file))
#检测人脸
face_detector = cv2.CascadeClassifier('haarcascade_frontalface_default.xml')
#遍历列表中的图片
count = 0
for imagefile in imageFiles: #获得各文件夹名字
imagefile=imagefile.replace('\\','/')
id = int(getIdfromSql(imagefile.split('/')[2].split('_')[1]))
PIL_img=Image.open(imagefile).convert('L') #打开图片并且转为灰度图片
#将图像转换为数组
img_numpy=np.array(PIL_img,'uint8')
faces = face_detector.detectMultiScale(img_numpy)
for x,y,w,h in faces:
facesSamples.append(img_numpy[y:y+h,x:x+w])
ids.append(id)
return facesSamples,ids
if __name__ == '__main__':
path='./Picture_resources'
#获取图像数组和id标签数组
print('开始采集数据...')
faces,ids=getImageAndLabels(path)
print('采集数据结束,开始训练数据...')
#获取训练对象
recognizer=cv2.face.LBPHFaceRecognizer_create()
recognizer.train(faces,np.array(ids))
#保存文件
recognizer.write('./Trainer/trainer.yml')
print('训练数据成功!3秒后程序自动关闭...')
time.sleep(3)3:人脸识别:
其中get(propId)函数可以用来获取视频的属性,propId=3表示获取帧宽度,propId=4表示获取帧高度,所以video.get(3)返回视频帧的宽度,video.get(4)返回视频帧的高度。
首先读取他们训练好的特征recogizer.read('trainer.yml')
然后打开摄像头获取到人脸,之后调用recogizer.predict(gray[y:y+h, x:x+w])
预测函数,返回了id和置信度,置信度的意思就是可信度,通常情况下,认为小于50 的值是可以接受的,如果该值大于80 则认为差别较大。之后就是用cv的画图函数将预测结果展示出来
好了,整个人脸识别项目就写好了,是不是很简单?主要是我们有了已经封装好的train和predict进行运用,然后用摄像头获取到人脸这个函数去计算人脸的特征加预测即可。虽然这个算法比较简单和久远,但我们还是有必讲这些算法去了解一下,也有便于我们后续理解更多不同的算法。
视频演示在文章最后有链接,感兴趣的可以点击观看。
二:云端数据库
1:人脸采集部分的云端:
首先调用connect连接你的数据库,我这里用的是mysql,
cur.execute(sql1),execute就是执行的意思,把东西传进去让他帮你执行,
con.commit() 是 Python 对 MySQL 数据库的操作中提交事务的方法。当你执行 INSERT、UPDATE 或 DELETE 等语句时,数据不会直接写入数据库,而是先写到缓冲区,等待 commit() 方法被调用后,才会将数据真正写入数据库。这种方式可以保证数据的一致性和完整性。
然后调用cur.fetchall(),它可以一次性获取所有查询结果,返回一个包含所有结果的列表。
然后开始查询数据,首先如果插入的数据信息是已经存在的,判断它的文件夹,进而判断里面是否有图片,如果没有的话就重新录入。如果都存在的,则说明用户已经存在,提醒用户重新输入信息。代码如下:
if student:
con.close()
flag = 2
return flagresult = PutDatatoSql(face_name, face_id)
if result == 1:
break
elif result == 2:
# 可能存在数据库有记录 但是图像资源被删掉了,这种情况重新录入
if not os.path.exists('./Picture_resources/Stu_' + str(face_id)): # 文件夹是否存在
break
elif not os.listdir("./Picture_resources/Stu_" + str(face_id)): # 文件夹里面是否有文件
break
else:
print('该用户已存在!')但是如果你传入的数据是很多小数点的,varchar无法处理,则抛出异常,print('插入数据失败')
con.rollback() 是 Python 中 MySQL 数据库模块 mysql-connector-python 中的一个方法,用于撤销自上次提交以来所做的所有更改。
except Exception as e:
print(e)
print('插入数据失败')
flag = 0
return flag2:人脸训练部分的云端:
主要是索引学号,首先什么人脸训练部分代码中,把文件夹的路径的切分结果(也就是学号)传给getIdfromSql(sno),去获取这个学号的图片信息(注意:在人脸采集的时候输入了学号和姓名,学号用来获取图像去训练,姓名是在预测的时候用到的用来显示预测结果的)
cur.fetchone() 看函数名应该看得出来,大概意思就是fetch(获取)one(一)个什么东西。功能是:返回结果集中的第一行数据(也就是自增长的id),因为是通过学号(sno)查询学生ID,所以查询结果只有一行数据,因此使用fetchone() 从结果集中获取该行数据,并将其赋值给 student 变量。
def getIdfromSql(sno):
con = pymysql.connect(host='localhost', database='test', user='root', password='123456', port=3306)
# 创建游标对象
cur = con.cursor()
# 编写查询的sql
sql = 'select id from t_stu where sno='+sno
# 执行sql
try:
cur.execute(sql)
# 处理结果集
student = cur.fetchone()
id = student[0]
return id
except Exception as e:
print(e)
print('查询所有数据失败')
finally:
con.close()3:人脸识别部分的云端:
识别部分就只有获取学生信息了。重点是students = cur.fetchall()这一行代码,获取到所有数据库的结果后,获取到id号对应的名字,用于结果显示
def getDataFromSql():
names = {}
# 创建连接
con = pymysql.connect(host='49.234.44.69', password='498666', user='fc', port=3306, db='fc')
# 创建游标对象
cur = con.cursor()
# 编写查询的sql
sql = 'select * from t_stu'
# 执行sql
try:
cur.execute(sql)
# 处理结果集
students = cur.fetchall()
for student in students:
id = student[0]
sname = student[1]
sno = student[2]
names[int(id)] = sname
except Exception as e:
print(e)
print('查询所有数据失败')
finally:
# 关闭连接
con.close()
return names这一部分是将训练好模型进行预测,返回是一个id和置信度,然后将id传给names,输出正确的name,即是预测的结果
for (x, y, w, h) in faces:
cv2.rectangle(img, (x, y), (x+w, y+h), (0, 255, 0), 2)
idnum, confidence = recogizer.predict(gray[y:y+h, x:x+w])
if confidence < 60:
idname = names[idnum]
confidence = "{0}%".format(round(100 - confidence))
else:
idname = 'unknown'
confidence = "{0}%".format(round(100 - confidence))另外,在云数据库中,刚开始连不上navicat,因为在图形界面操作数据库简单点。但是刚开始我是连不上的,因为端口号问题,这里面我刚开始是用宝塔来操作服务器的,后来发现宝塔那边放行的端口号,服务器上面没有更新整个端口号(还有字符也要慎重选择)。
当你连上navicat后,你又发现数据库是无法操作的,这里全都在终端敲命令解决的,刚开始想在navicat设置权限的,但是一直说拒绝访问,这一点我花了很多时间找了各种资料,最后弄好了,但是这过程也会帮助你学到很多的东西。
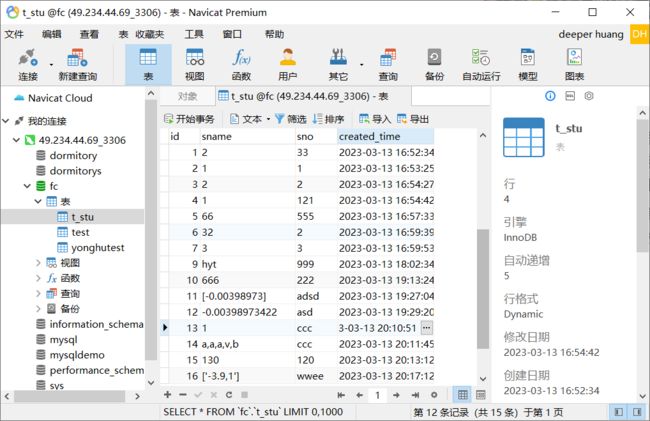
这个是数据库的人脸信息
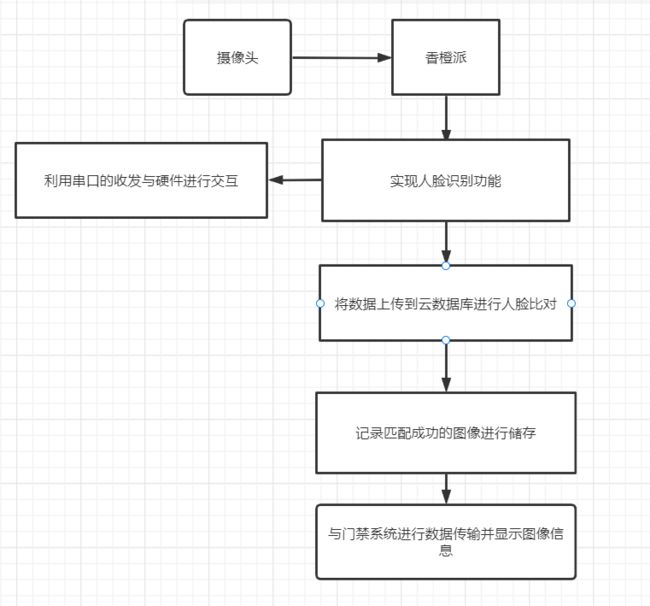
下面是一个简单的流程图:总体的代码在上面详细的介绍了
录制人脸加训练点击此查看视频演示
识别视频演示点击这里