【数据结构】【算法】二叉树、二叉排序树、树的相关操作
树结构是以分支关系定义的一种层次结构,应用树结构组织起来的数据,逻辑上都具有明显的层次关系。
操作系统中的文件管理系统、网络系统中的域名管理、数据库系统中的索引管理等都使用了树结构来组织和管理数据。
树的基本概念
树Tree是由n个节点组成的有限集合。在任意一颗非空树中:
- 有且仅有一个根
Root节点。 - 当
n>1时,其余节点分别为m个互不相交的有限集。其余每一个集合都是一棵树,被称为子树。
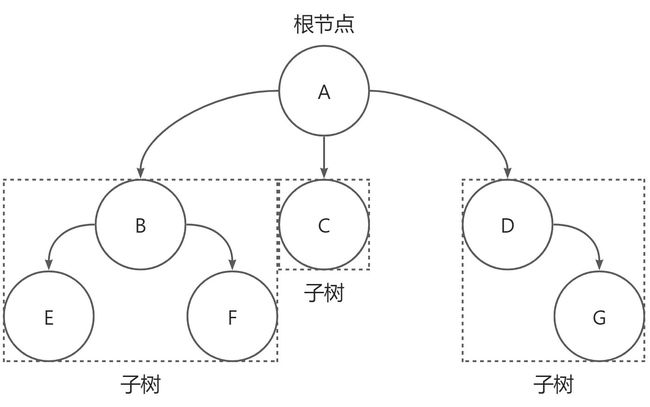
每个圆圈表示树的一个节点,其中节点A被称为树的根节点。
每一棵子树本身也是树。
常见术语
- 节点的度
Degree:节点拥有的子树数量被称为该节点的度。如上图:A的度为3,B的度为2,D的度为1,C的度为0。 - 树的度:树中各节点的度的最大值被称为树的度。如上图:树的度为3。
- 叶子节点
Leaf:度为0的节点被称为树的叶子节点。如上图:E、F、C、G。 - 孩子节点
Child:一个节点的子树的根节点被称为该节点的孩子节点。如上图:A的孩子节点有B、C、D。 - 双亲结点
Parent:双亲节点与孩子节点对应。如上图:A为B、C、D的双亲节点。 - 兄弟节点
Sibling:一个双亲节点的孩子节点互为兄弟节点。如上图:B、C、D互为兄弟节点。 - 节点的层次
Level:从根节点开始,根节点在第1层,根节点的孩子节点为第2层,以此类推。如上图:E、F、G位于树的第3层。 - 树的深度
Depth:书中节点的最大深度被称为树的深度。如上图,树的深度为3。 - 森林
Forest:m棵互不相交的树的集合被称为森林。
树的性质
- 非空树的节点总数,等于树中所有节点的度的和+1。
- 度为
k的非空树的第i层最多有 k i − 1 k^{i-1} ki−1个节点。 - 深度为
h的k叉树最多有 k h − 1 k − 1 \frac{k^h-1}{k-1} k−1kh−1个节点。 - 具有
n个节点的k叉树的最小深度为 log k ( n ( k − 1 ) + 1 ) \log_k(n(k-1)+1) logk(n(k−1)+1)
二叉树
二叉树是一种特殊的树结构,前面所说的树的特性及术语同样适用于二叉树。
二叉树的定义
二叉树Binary Tree或者为空,或者由一个根节点加上根节点的左子树和右子树组成。
要求左子树和右子树互不相交,且同为二叉树。
显然,这个定义式是递归形式的。
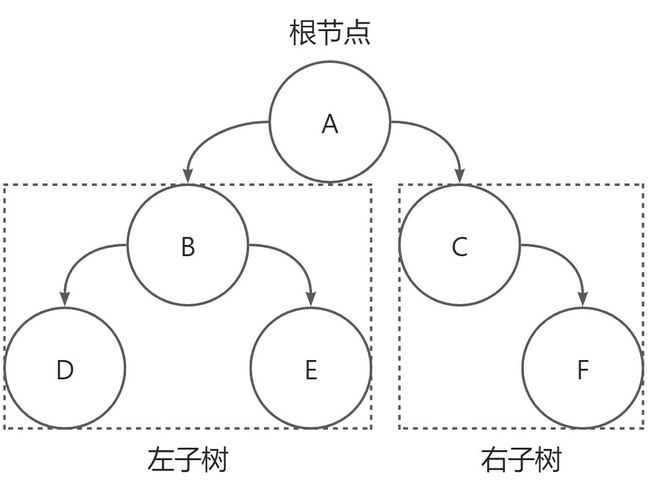
二叉树的每个节点至多有两个孩子节点,其中左边的孩子节点被称为左孩子,右边的孩子节点被称为右孩子。
满二叉树与完全二叉树
如果二叉树内的任意节点都是叶子节点或有两棵树,同时叶子节点都位于二叉树的底层,则其被称为满二叉树。
若二叉树最多只有最下面两层节点的度小于2,并且底层节点(叶子节点)依次排列在该层最左边的位置上,则其被称为完全二叉树。
如图:
二叉树非常特殊,需要我们掌握它的一些性质:
- 在二叉树的第
i层至多有 2 i − 1 2^{i-1} 2i−1个节点。 - 深度为
k的二叉树至多有 2 k − 1 2^k-1 2k−1个节点。 - 对于任何一棵二叉树,如果叶子节点数为
n,度为2的节点数为m,则n=m+1。 - 具有n个节点的完全二叉树的深度为 log 2 n + 1 \log_2n+1 log2n+1
二叉树的存储形式
二叉树一般采用多重链表的形式存储,直观地讲就是将二叉树的各个节点用链表节点的形式连接在一起。
每个节点都包含三个域:
- 一个数据域用来存放节点数据。
- 两个指针域分别指向左右孩子节点。当没有孩子节点时,相应的指针域将被置为
null。
二叉树的节点定义如下:
class BinaryTreeNode {
int data;
BinaryTreeNode leftChild;
BinaryTreeNode rightChild;
public BinaryTreeNode(int data) {
this.data = data;
leftChild = null;
rightChild = null;
}
}
对于一棵二叉树而言,只要得到了它的根节点指针(引用),就可以通过链表结构访问到二叉树中的每一个节点。
所以在定义二叉树类时,通常只需要保存二叉树的根节点,而不需要记录二叉树中每一个节点的信息。
二叉树的遍历
二叉树的遍历Traversing Binary Tree就是通过某种方法将二叉树中的每个节点都访问一次,并且只访问一次。
在实际应用中,经常需要按照一定的顺序逐一访问二叉树中的节点,并对其中的某些节点进行处理。
二叉树的遍历操作是二叉树应用的基础。
二叉树的队列分为两种:
- 一种是基于深度优先搜索的遍历。它是利用二叉树结构的递归特性设计的,包括:先序遍历、中序遍历、后序遍历。
- 一种是按照层次遍历二叉树,它是利用二叉树的层次结构,并借助队列实现的。
基于深度优先搜索的遍历
访问根节点的函数visit()可依据实际情况自行定义,它可以是读取节点中数据的操作,也可以是其他复杂的操作。
基于深度优先搜索的遍历算法一般有三种:先序遍历DLR、中序遍历LDR和后序遍历LRD。
其中D表示根节点,L表示左子树,R表示右子树。
因为二叉树本身就是递归结构,所以这3种遍历算法也都是以递归形式定义的。
先序遍历DLR:
- 访问根节点
- 先序遍历根节点的左子树
- 先序遍历根节点的右子树
public void PreOrderTraverse() { // 先序遍历
PreOrderTraverse(root);
}
public void PreOrderTraverse(BinaryTreeNode root) {
if (root != null) {
visit(root); // 访问根结点
PreOrderTraverse(root.leftChild); // 先序遍历根结点的左子树
PreOrderTraverse(root.rightChild); // 先序遍历根结点的右子树
}
}
中序遍历LDR:
- 中序遍历根节点的左子树
- 访问根节点
- 中序遍历根节点的右子树
public void InOrderTraverse() { // 中序遍历
InOrderTraverse(root);
}
public void InOrderTraverse(BinaryTreeNode root) {
if (root != null) {
InOrderTraverse(root.leftChild);
visit(root);
InOrderTraverse(root.rightChild);
}
}
后序遍历LRD:
- 后序遍历根节点的左子树
- 后序遍历根节点的右子树
- 访问根节点
public void PostOrderTraverse() { // 后序遍历
PostOrderTraverse(root);
}
public void PostOrderTraverse(BinaryTreeNode root) {
if (root != null) {
PostOrderTraverse(root.leftChild);
PostOrderTraverse(root.rightChild);
visit(root);
}
}
按层次遍历
按层次遍历二叉树是一种基于广度优先搜索思想的二叉树遍历算法。按层次遍历二叉树针对二叉树的每一层进行。
若二叉树非空,则先访问二叉树的第1层节点,再依次访问第2层、第3层节点,直到遍历完二叉树底层节点。
对二叉树中每一层节点的访问都按照从左到右的顺序进行。
在遍历时,需要一个队列作为辅助工具,具体步骤如下:
- 将二叉树的根结点指针入队列。
- 将队首的指针元素出队列并利用这个指针访问该节点。依次将该节点的左孩子和右孩子的指针入队列。
- 重复2操作,直到队列为空。
public void LayerOrderTraverse() // 按层次遍历
{
Queue<BinaryTreeNode> queue = new LinkedList<BinaryTreeNode>();
queue.offer(root); // 将根结点入队列
while (!queue.isEmpty()) {
BinaryTreeNode node = queue.poll(); // 取出队头结点
visit(node); // 访问该结点
if (node.leftChild != null) {
queue.offer(node.leftChild); // 将左孩子入队列
}
if (node.rightChild != null) {
queue.offer(node.rightChild); // 将右孩子入队列
}
}
}
方便起见,该队列是用Java容器类LinkedList的泛型实现,这样可以指定队列中的每个数据元素都是BinaryTreeNode类型的。当然也可以使用之前创建的MyQueue类实现这个辅助队列,但在使用之前需要对Myqueue类加以改造,使其每个队列节点的数据域都是BinaryTreeNode类型的。
创建二叉树
前面介绍了二叉树的遍历方法。但这需要存在一棵二叉树为基础。
最常见的创建二叉树的方式就是利用二叉树遍历的思想,在遍历过程中生成二叉树的节点,进而建立起整棵二叉树。
public void CreateBinaryTree(LinkedList<Integer> nodeList) {
root = CreateBiTree(nodeList); // 创建二叉树,将根结点赋值给root
}
public BinaryTreeNode CreateBiTree(LinkedList<Integer> nodeList) {
BinaryTreeNode node = null;
if (nodeList == null || nodeList.isEmpty()) {
return null;
}
Integer data = nodeList.removeFirst(); // 创建根结点
if (data != null) {
node = new BinaryTreeNode(data);
node.leftChild = CreateBiTree(nodeList); // 创建左子树
node.rightChild = CreateBiTree(nodeList); // 创建右子树
}
return node;
}
函数CreateBiTree()可以按照先序序列创建一棵二叉树。该函数的参数是一个LinkedList类型的对象nodeList。保存了每个节点的元素,用来初始化二叉树节点。
这些元素在nodeList中以先序序列的方式排列并指定了该二叉树双亲结点与孩子节点之间的关系。
函数CreateBiTree()先从nodeList中取出第一个元素,如果该元素不为null,则创建一个BinaryTreeNode类型的节点node,并将取出的元素作为node中的数据元素。
再递归地创建以node节点为根节点的二叉树的左子树和右子树。
如果从**nodelist**中取出的第1个元素为**null**,则说明本层递归调用中要创建的二叉树(或二叉树的某棵子树)为空,直接返回**null**即可。
在上面的代码中,将创建二叉树的函数CreateBiTree()以及二叉树遍历函数PreOrderTraverse()、InOrderTraverse()、PostOrderTraverse()都进行了封装,使得它们对外提供的接口可以不以二叉树的根节点作为返回值或参数。这样二叉树根节点作为私有成员被隐藏起来,代码结构也更加符合面向对象的程序设计思想。
二叉排序树和AVL树
二叉排序树也称二叉查找树,是一种特殊形式的二叉树:
- 若它的左子树不为空,则左子树上所有节点的值均小于根节点的值。
- 若它的右子树不为空,则右子树上所有节点的值均大于根节点的值。
- 二叉排序树的左右子树都是二叉排序树。
查找与插入节点
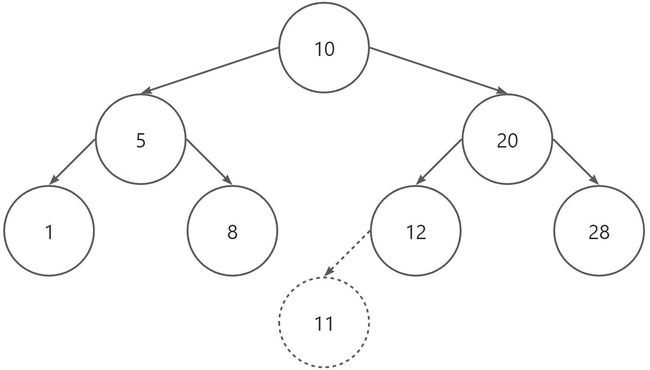
在二叉排序树中查找元素时,首先将给定的关键字与根节点的关键字比较,若相等则查找成功,否则将根据给定的关键字与根节点的关键字之间的大小关系,在左子树或右子树中继续查找。
在二叉树中搜索key=11,搜索步骤如下:
- 将
key与根节点关键字10比较,因为11>10,所以在该节点的右子树中继续搜索。 - 将
key与关键字20比较,因为11<20,所以在该节点的左子树中继续搜索。 - 将
key与关键字12比较,因为11<12,所以在该节点的左子树中继续搜索。 - 因为节点12的左子树为
null,所以查找失败,返回null。
因为二叉树主要用作动态查找表,也就是表结构本身可在查找过程中动态生成,所以插入节点的操作通常在查找不成功时进行,而且新插入的节点一定是查找路径上最后一个节点的左孩子或右孩子,插入新的节点后该二叉树仍为二叉排序树。
在上一步的搜索中,查找key=11会失败,此时就需要向该二叉排序树中插入节点11(见上图)。
删除节点
因为删除节点后仍要保持二叉排序树的结构,所以删除节点的操作比其他操作要复杂一些,需要分以下3种情况讨论。
- 删除的节点为二叉树的叶子节点。删除叶子节点后不会破坏整棵二叉排序树的结构,直接删除即可。
- 要删除的节点只有一个左子树或右子树。将子树的根节点取代要删除的节点即可。
- 要删除的节点既有左子树,又有右子树,这类情况处理起来比较复杂。
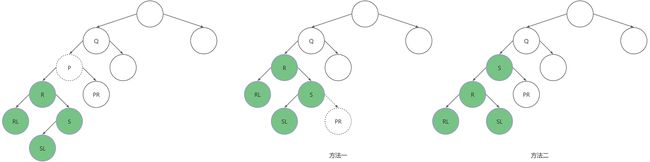
删除节点P需要理解中序遍历。中序遍历二叉树,可以得到:{RL,R,SL,S,P,PR,Q}。该序列从小到大排列。
删除节点P有两种方法:
- 第1种方法是将P的右子树PR变为S的右子树,然后将P的左子树PL变为Q的左子树。
- 第2种方法是用P点在中序遍历序列中的直接前驱S,代替P节点。S的左子树SL直接作为R节点的右子树。
中序遍历这两种方法,得到的序列都是{RL,R,SL,S,PR,Q},与删除之前的中序遍历序列只差了一个P节点。该二叉树仍是一棵二叉排序树,节点仍然按值有序。
AVL树
在一棵具有n个节点的二叉排序树种随即查找一个节点的时间复杂度为 O ( log 2 n ) O(\log_2n) O(log2n)。
二叉排序树的查找效率与二叉排序树的形态密切相关。
如果在创建二排序树时插入的关键字时按值有序的,则该二叉排序树就会退化为单枝树。
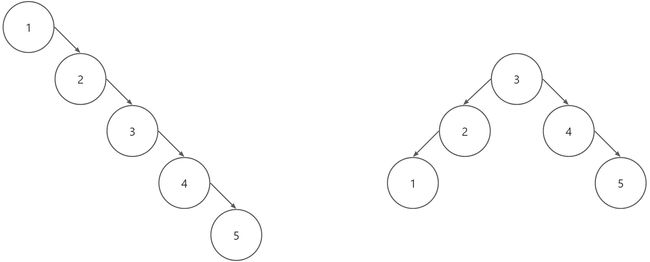
在左图中的二叉排序树种查找元素相当于在一个线性序列种顺序查找,时间复杂度为 O ( n ) O(n) O(n),体现不出二叉排序树的优势。
最好的情况就是二叉排序树完全处于平衡状态.此时二叉排序树的形态与折半查找的判定树相同,平均查找长度与 log 2 n \log_2n log2n成正比。
为了使二叉排序树始终处于尽可能平衡的状态,人们发明了AVL树。
AVL树也称平衡二叉树,它是一种具有自平衡功能的二叉排序树。
AVL树或者是一棵空树,或者是具有下列性质的二叉树:它的左子树和右子树都是AVL树;左子树和右子树的深度差的绝对值不超过1.
如果将二叉树上节点的平衡因子Balance Factor定义为该节点的左子树的深度减去右子树的深度,则AVL树的平衡因子只可能是-1,0或1。
在AVL树种插入或删除节点后,它可能处于一种不平衡的状态(BF的绝对值大于1),此时会通过一次或多次AVL旋转来重新实现平衡。
因为AVL树可通过旋转实现自平衡,所以AVL树上任何节点的左右子树深度之差都不会超过1,AVL树的深度和 log 2 n \log_2n log2n是相同数量级的。因此从AVL树查找一个节点的时间复杂度为 O ( log 2 n ) O(\log_2n) O(log2n)。
来两道算法题
计算二叉树的深度
编写一个程序,计算二叉树的深度。
在二叉树中,除根节点外,左子树和右子树也必须是二叉树,所以二叉树具有递归特性。
在计算二叉树深度时,可以利用这种递归特性。先计算根节点左子树的深度,再计算根节点右子树的深度,然后比较两值将其中的较大值加1,也就是加上当前根节点这一层。
再计算左子树和右子树深度时,使用的方法与计算整棵二叉树深度的方法完全相同,只是计算规模缩小了。
public int getBinaryTreeDepth() {
return getBinaryTreeDepth(root);
}
public int getBinaryTreeDepth(BinaryTreeNode root) {
int leftHeight, rightHeight, maxHeight;
if (root != null) {
leftHeight = getBinaryTreeDepth(root.leftChild); // 计算根结点左子树的深度并赋值给leftHeight
rightHeight = getBinaryTreeDepth(root.rightChild); // 计算根结点右子树的深度并赋值给rightHeight
maxHeight = leftHeight > rightHeight ? leftHeight : rightHeight; // 比较左右子树的深度
return maxHeight + 1; // 返回二叉树的深度
} else {
return 0; // 如果二叉树为NULL,返回0
}
}
getBinaryTreeDepth()函数会直接调用getBinaryTreeDepth(BinaryTreeNode root)计算以root为根节点的二叉树深度。这里为了更加符合面向对象的设计思想,将getBinaryTreeDepth(BinaryTreeNode root)函数做了一层封装。
计算二叉树中叶子节点的数量
编写一个算法,计算二叉树中叶子节点的数量。
本题可以参照上一题的解法,利用二叉树本身的递归特性来求解。
计算二叉树叶子节点的数量,其实就是计算二叉树根节点左子树和右子树的叶子节点的数量之和。
而根节点的左子树和右子树本身也是二叉树,所以计算它们的叶子节点数量的方法与上题中的方法相同,这样就找到了该问题的递归结构。
- 如果二叉树为
null,则叶子节点的数量为0。 - 如果该二叉树只包含一个根节点,则它的根节点就是叶子节点,因此叶子节点的数量为
1。
这两个条件构成了递归的出口,即递归的结束条件。
public int getBinaryTreeLeavesNumber() {
return getBinaryTreeLeavesNumber(root);
}
public int getBinaryTreeLeavesNumber(BinaryTreeNode root) {
if (root == null) {
return 0; // root为null,返回0
} else if (root.leftChild == null && root.rightChild == null) {
return 1; // 该结点是叶子结点,返回1
} else {
// 返回左子树和右子树叶子结点数之和
return getBinaryTreeLeavesNumber(root.leftChild) + getBinaryTreeLeavesNumber(root.rightChild);
}
}
上面的代码中,将getBinaryTreeLeavesNumber(BinaryTreeNode root)函数进行了一层封装。
在getBinaryTreeLeavesNumber()函数中直接调用带参数的getBinaryTreeLeavesNumber(BinaryTreeNode root)函数。
root是一个private访问权限的成员变量,该变量对外不可被访问。这样更加符合面向对象的程序设计思想。
遍历二叉树计算叶子节点数量
本题还可以通过遍历二叉树来计算叶子节点的数量。
在遍历二叉树时可以访问到二叉树的每一个节点,所以可以判断当前访问的节点是否为叶子节点。
如果该节点是叶子节点,就将累加器变量count的值加1。
当遍历完整棵二叉树之后,count记录的值即为该二叉树中叶子节点的数量。
private int count = 0;
public int countBinaryTreeLeavesNumberByTraversing() {
countBinaryTreeLeavesNumberByTraversing(root);
return count;
}
public void countBinaryTreeLeavesNumberByTraversing(BinaryTreeNode root) {
if (root != null && root.leftChild == null && root.rightChild == null) {
count = count + 1; // root结点即为叶子结点,count++
}
if (root != null) {
// 继续遍历root结点的左子树和右子树
countBinaryTreeLeavesNumberByTraversing(root.leftChild);
countBinaryTreeLeavesNumberByTraversing(root.rightChild);
}
}
在上面的代码中,累加器变量count是一个整型的成员变量,在递归地调用成员函数countBinaryTreeLeavesNumberByTraversing(BinaryTreeNode root)遍历二叉树时,都可以直接修改累加器count的值。
因为count是一个private访问权限的成员变量,所以这里将函数countBinaryTreeLeavesNumberByTraversing(BinaryTreeNode root)进行了一次封装,在函数countBinaryTreeLeavesNumberByTraversing()中传递的参数root,以及返回的叶子节点数量count都是private成员变量,这样更加符合面向对象的程序设计思想。
这个代码与之前的先序遍历非常类似。相当于重写了先序遍历中的visit()函数。
二叉排序树的最低公共祖先
已知存在一棵二叉排序树,其中保存的节点值均为正整数。实现一个函数:
int findLowestCommonAncestor(BinaryTreeNode root, int value1,int value2)
该函数的功能是在这棵二叉排序树中寻找节点值value1和节点值value2的最低公共祖先。
该函数的返回值是最低公共祖先节点的值。
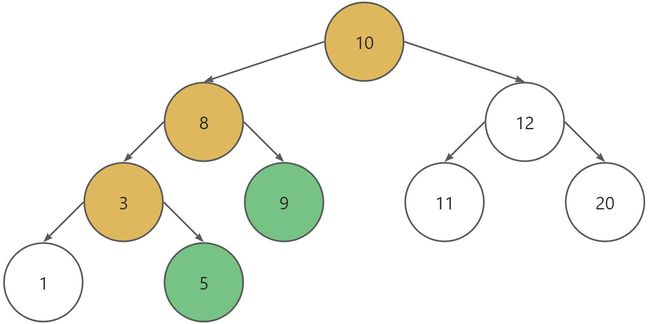
上图中,若value1=5,value2=9,那么它们的最低公共祖先是节点8。
当给定的两个节点分别位于二叉排序树中某个根节点的左右子树上时:
在二叉排序树中,value1和value2的最低公共祖先的值介于value1和value2之间。
这个规律是由二叉排序树的基本特性决定的。
在二叉排序树中,如果两个节点分别位于根节点的左子树和右子树,那么这个根节点必然是它们的最低公共祖先。而其他的公共祖先的值要么同时大于这两个节点的值,要么同时小于这两个节点的值。
如上图,5和9的最低公共祖先为8。
如果给定的两个节点存在祖先和子孙的关系,那么它们的最低公共祖先就不能按照上面的算法求得了。
假设给定的两个节点分别为A和B,并且A是B的祖先。那么节点A和B的最低公共祖先就是A的父节点。
因为A的父节点一定是B的祖先,同时该节点必然是A和B的最低公共祖先。
如上图,3和8的最低公共祖先为10。
另外,如果value1和value2中的一个是根节点,那么不存在最低公共祖先,因为根节点没有祖先,所以也应把这种情况考虑进去。
public int findLowestCommonAncestor(int value1, int value2) {
return findLowestCommonAncestor(root, value1, value2);
}
public int findLowestCommonAncestor(BinaryTreeNode root, int value1, int value2) {
BinaryTreeNode curNode = root; // curNode为当前访问结点,初始化为root
if (root.data == value1 || root.data == value2) {
return -1; // value1和value2有一个为根结点,因此没有公共祖先,返回-1
}
while (curNode != null) {
if (curNode.data > value1 &&
curNode.data > value2 && curNode.leftChild.data != value1 &&
curNode.leftChild.data != value2) {
// 当前结点的值同时大于value1和value2,
// 且不是value1和value2的父结点
curNode = curNode.leftChild;
} else if (curNode.data < value1 &&
curNode.data < value2 && curNode.rightChild.data != value1 &&
curNode.rightChild.data != value2) {
// 当前结点的值同时小于value1和value2,
// 且不是value1和value2的父结点*/
curNode = curNode.rightChild;
} else {
return curNode.data; // 找到最低公共祖先
}
}
return -1;
}
上面的代码中,并没有使用递归,而是通过不断修正while循环,来获取符合条件的最低公共祖先。
while中第一个if的判断条件为curNode.data > value1 && curNode.data > value2 && curNode.leftChild.data != value1 && curNode.leftChild.data != value2
curNode.data > value1 && curNode.data > value2urNode.leftChild.data != value1 && curNode.leftChild.data != value2
对于第一点,也就是前两句if条件。执行的语句是修改curNode指向的对象,也就是修改while循环中下一轮循环的方向。如果判断节点介于value1和value2之间,则直接返回。
对于第二点,也就是后两句if条件。最低公共祖先一定是value1和value2节点的祖先。当判断节点为其中一个节点的双亲节点时,可以直接返回该节点。
该算法适用的前提是
value1和value2在二叉排序树中真实存在。
该算法的核心思想是在二叉排序树中寻找value1和value2之间的值,如果value1或value2在二叉排序树中不存在,那么得到的结果是没有意义的。
更加完善的做法是预先判断value1和value2是否在二叉排序树中。