使用chatglm搭建本地知识库AI_闻达
最近大火的chatgpt,老板说让我看看能不能用自己的数据,回答专业一些,所以做了一些调研,最近用这个倒是成功推理了自己的数据,模型也开源了,之后有机会也训练一下自己的数据。
使用chatglm搭建本地知识库AI_闻达
- 1.本机部署
-
- 1.1环境部署
- 1.2 配置参数
- 1.3. 推理
- 2.云服务器部署
- 3.项目需求
-
- 3.1 修改前端的名字
- 3.2 不同用户用不同的知识库
-
- 3.2.1修改生成不同目录的知识库文件
- 3.2.2 不同用户用不同知识库
- 3.2.3效果
- 3.2.4一个txt或pdf自动生成一个独立的知识库
- 3.2.5返回score值最低的知识库prompt
- 3.3 ptuning微调
1.本机部署
因为电脑配置不行,所以用了rwkv模型。
1.1环境部署
1.1双击打开anconda prompt创建虚拟环境
Conda create –n chatglm python#(创建名叫chatglm的虚拟python环境)
Conda activate chatglm#(激活环境)
1.2下载pytorch(这里要根据自己的电脑版本下载)都在虚拟环境里操作
nvidia-smi#(查看自己cuda版本)
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118#(下载符合自己配置的torch,可以在官网https://pytorch.org/查看命令)

1.3在官网https://download.pytorch.org/whl/torch_stable.html下载对应的cuda版本的torch和torchvision,然后pip install即可
这时gpu版的torch就下载成功:,验证方法如图:

1.4安装依赖库
cd C:\Users\dz\Desktop\AIGC\wenda\wd-git\wenda\requirements#(进入工具包的simple目录下)
pip install –r .\requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install protobuf flatbuffers termcolor#(根据提示下载需要的包和自己的模型requirements.txt文件)
1.2 配置参数
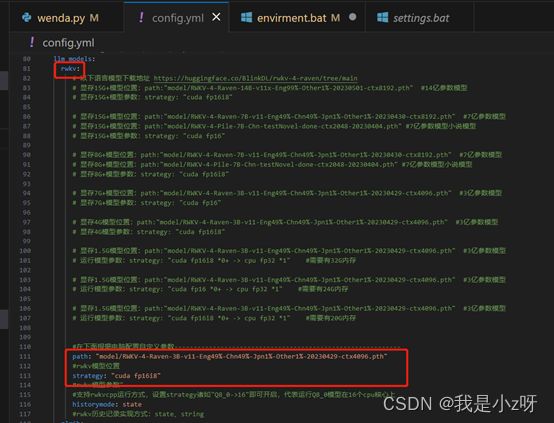
- 配模型:下载对应的模型权重文件,放到model文件夹下面,这里我用的是RWKV:

- 配数据:自己的文本数据放到txt文件夹下面:

3.配环境:在environment里面把环境配成自己刚刚创建的虚拟环境

在config里面把权重文件的地址和配置改成自己的
1.3. 推理
- 双击step.2本地数据库建库.bat建本地数据库

- 双击run_rwkv-点击运行.bat运行这个模型,然后浏览器打开http://127.0.0.1:17860/
首先测试是否检测到本地数据库

问答功能

2.云服务器部署
电脑跑起来不行,所以在云服务器上搞了一个,本来是git源码的,但是源码git下来运行有问题,所以我还是把本地文件放到自己仓库,重新git了一下,云服务器租环境,就租wenda环境,然后
git clone https://github.com/Turing-dz/wenda_zoe_test.git
修改example.config.xml文件里的模型地址,然后就可以推理自己的数据了。
python pluges/gen_data_st.py#运行本地数据库
python wenda.py -t glm6b -p 6006#云上规定用6006映射
然后打开链接,打开知识库按钮,就会推理自己的数据文件了。

3.项目需求
3.1 修改前端的名字
修改views/static/string.js里面的常量值就可以。
3.2 不同用户用不同的知识库
这个其实是一个安全问题,但代码修改起来也很简单,分两步,一个是生成不同的知识库,下一步就是调用不同的知识库。
3.2.1修改生成不同目录的知识库文件
1.修改example.config.yml,当用户没有给-u参数时,默认txt下的文件生成到memory的default1文件夹下。
user_Type: default1

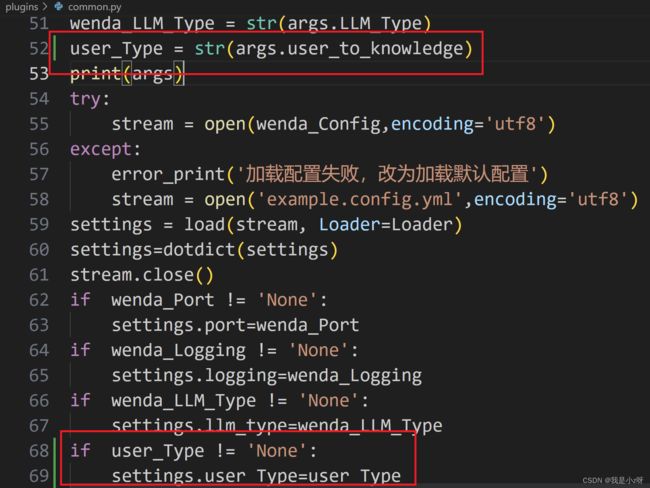
2.修改common.py文件,设置用户输入-u参数,如果没输入就用上面设置的默认default1
parser.add_argument('-u', type=str, dest="user_to_knowledge", help="不同用户的本地知识库")
user_Type = str(args.user_to_knowledge)
if user_Type != 'None':
settings.user_Type=user_Type

3.修改gen_data_st.py文件,这个文件是生成知识库的,所以要修改生成地址
add_knowledge='memory/'+settings.user_Type
try:
vectorstore_old = FAISS.load_local(
add_knowledge, embeddings=embeddings)
success_print("合并至已有索引。如不需合并请删除 add_knowledge 文件夹")
vectorstore_old.merge_from(vectorstore)
vectorstore_old.save_local(add_knowledge)


3.2.2 不同用户用不同知识库
修改zhishiku_rtst.py文件
def find(s,step = 0,memory_name=settings.user_Type):

3.2.3效果
python '/root/autodl-fs/wenda_zoe_test/plugins/gen_data_st.py' -u u2
python '/root/autodl-fs/wenda_zoe_test/wenda.py' -u u2 -t glm6b -p 6006


python '/root/autodl-fs/wenda_zoe_test/plugins/gen_data_st.py' -u u5
python '/root/autodl-fs/wenda_zoe_test/wenda.py' -u u5 -t glm6b -p 6006


3.2.4一个txt或pdf自动生成一个独立的知识库
天哥需要一个文件生成一个知识库。这个就更简单了,修改gen_data_st.py文件,
#add_knowledge='memory/'+settings.user_Type#这个是上次的-u功能,可以先注释
#下面两段代码加到for循环里,并把地下的代码都右移一位,加到for循环里面
add_knowledge='memory/'+file
add_knowledge=add_knowledge.split(".")[0]

但在后面需要返回score最大文章的content时,发现了bug,上面改完之后每次生成下一个文件的知识库时都会把之前的包括了,所以如果数据要独立,还得在all_files的循环开始加上
docs=[]
vectorstore = None
最好把下面的合并索引也删掉。所以改完的gen_data_st .py如下:
import argparse
import sentence_transformers
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores.faiss import FAISS
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.docstore.document import Document
import threading
import pdfplumber
import re
import chardet
import os
import sys
import time
os.chdir(sys.path[0][:-8])
from common import success_print
from common import error_helper
from common import settings
from common import CounterLock
source_folder = 'txt'
source_folder_path = os.path.join(os.getcwd(), source_folder)
#add_knowledge='memory/'+settings.user_Type
import logging
logging.basicConfig()
logger = logging.getLogger()
logger.setLevel(logging.ERROR)
root_path_list = source_folder_path.split(os.sep)
docs = []
vectorstore = None
model_path = settings.librarys.rtst.model_path
try:
embeddings = HuggingFaceEmbeddings(model_name='')
embeddings.client = sentence_transformers.SentenceTransformer(
model_path, device="cuda")
except Exception as e:
error_helper("embedding加载失败,请下载相应模型",
r"https://github.com/l15y/wenda#st%E6%A8%A1%E5%BC%8F")
raise e
success_print("Embedding 加载完成")
embedding_lock=CounterLock()
vectorstore_lock=threading.Lock()
def clac_embedding(texts, embeddings, metadatas):
global vectorstore
with embedding_lock:
vectorstore_new = FAISS.from_texts(texts, embeddings, metadatas=metadatas)
with vectorstore_lock:
if vectorstore is None:
vectorstore = vectorstore_new
else:
vectorstore.merge_from(vectorstore_new)
def make_index():
global docs
if hasattr(settings.librarys.rtst,"size") and hasattr(settings.librarys.rtst,"overlap"):
text_splitter = CharacterTextSplitter(
chunk_size=int(settings.librarys.rtst.size), chunk_overlap=int(settings.librarys.rtst.overlap), separator='\n')
else:
text_splitter = CharacterTextSplitter(
chunk_size=20, chunk_overlap=0, separator='\n')
doc_texts = text_splitter.split_documents(docs)
docs = []
texts = [d.page_content for d in doc_texts]
metadatas = [d.metadata for d in doc_texts]
thread = threading.Thread(target=clac_embedding, args=(texts, embeddings, metadatas))
thread.start()
while embedding_lock.get_waiting_threads()>2:
time.sleep(0.1)
all_files=[]
for root, dirs, files in os.walk(source_folder_path):
for file in files:
all_files.append([root, file])
success_print("文件列表生成完成",len(all_files))
for i in range(len(all_files)):
root, file=all_files[i]
length_of_read=0
docs=[]
vectorstore = None
data = ""
title = ""
try:
if file.endswith(".pdf"):
file_path = os.path.join(root, file)
with pdfplumber.open(file_path) as pdf:
data_list = []
for page in pdf.pages:
print(page.extract_text())
data_list.append(page.extract_text())
data = "\n".join(data_list)
else:
# txt
file_path = os.path.join(root, file)
with open(file_path, 'rb') as f:
b = f.read()
result = chardet.detect(b)
with open(file_path, 'r', encoding=result['encoding']) as f:
data = f.read()
add_knowledge='memory/'+file
add_knowledge=add_knowledge.split(".")[0]
except Exception as e:
print("文件读取失败,当前文件已被跳过:",file,"。错误信息:",e)
data = re.sub(r'!', "!\n", data)
data = re.sub(r':', ":\n", data)
data = re.sub(r'。', "。\n", data)
data = re.sub(r'\r', "\n", data)
data = re.sub(r'\n\n', "\n", data)
data = re.sub(r"\n\s*\n", "\n", data)
length_of_read+=len(data)
docs.append(Document(page_content=data, metadata={"source": file}))
if length_of_read > 1e5:
success_print("处理进度",int(100*i/len(all_files)),f"%\t({i}/{len(all_files)})")
make_index()
# print(embedding_lock.get_waiting_threads())
length_of_read=0
if len(all_files) == 0:
#error_print("txt 目录没有数据")
print("txt 目录没有数据")
sys.exit(0)
if len(docs) > 0:
make_index()
while embedding_lock.get_waiting_threads()>0:
time.sleep(0.1)
with embedding_lock:
time.sleep(0.1)
with vectorstore_lock:
success_print("处理完成")
# try:
# vectorstore_old = FAISS.load_local(
# add_knowledge, embeddings=embeddings)
# success_print("合并至已有索引。如不需合并请删除 add_knowledge 文件夹")
# vectorstore_old.merge_from(vectorstore)
# vectorstore_old.save_local(add_knowledge)
# except:
# print("新建索引")
vectorstore.save_local(add_knowledge)
success_print("保存完成")
3.2.5返回score值最低的知识库prompt
需要遍历生成的知识库,所以在zhishiku_rtst.py里面加上
source_folder = 'memory'
memory_name_list=[]
source_folder_path = os.path.join(os.getcwd(), source_folder)
for root, dirs, files in os.walk(source_folder_path):
for dir in dirs:
memory_name_list.append(dir)
然后在find函数里遍历,并计算score值,score越大距离越远,所以要最小的prompt,所以zhishiku_rtst.py文件如下:
from langchain.vectorstores.faiss import FAISS
from langchain.embeddings import HuggingFaceEmbeddings
import sentence_transformers
import numpy as np
import re,os
from plugins.common import settings,allowCROS
from plugins.common import error_helper
from plugins.common import success_print
divider='\n'
if not os.path.exists('memory'):
os.mkdir('memory')
cunnrent_setting=settings.librarys.rtst
#print(cunnrent_setting.user_to_knowledge)
def get_doc_by_id(id,memory_name):
return vectorstores[memory_name].docstore.search(vectorstores[memory_name].index_to_docstore_id[id])
def process_strings(A, C, B):
# find the longest common suffix of A and prefix of B
common = ""
for i in range(1, min(len(A), len(B)) + 1):
if A[-i:] == B[:i]:
common = A[-i:]
# if there is a common substring, replace one of them with C and concatenate
if common:
return A[:-len(common)] + C + B
# otherwise, just return A + B
else:
return A + B
def get_doc(id,score,step,memory_name):
doc = get_doc_by_id(id,memory_name)
final_content=doc.page_content
print("文段分数:",score,[doc.page_content])
# print(id,score,step,memory_name,doc)
if step > 0:
for i in range(1, step+1):
try:
doc_before=get_doc_by_id(id-i,memory_name)
if doc_before.metadata['source']==doc.metadata['source']:
final_content=process_strings(doc_before.page_content,divider,final_content)
# print("上文分数:",score,doc.page_content)
except:
pass
try:
doc_after=get_doc_by_id(id+i,memory_name)
if doc_after.metadata['source']==doc.metadata['source']:
final_content=process_strings(final_content,divider,doc_after.page_content)
except:
pass
if doc.metadata['source'].endswith(".pdf") or doc.metadata['source'].endswith(".txt"):
title=f"[{doc.metadata['source']}](/api/read_news/{doc.metadata['source']})"
else:
title=doc.metadata['source']
return {'title': title,'content':re.sub(r'\n+', "\n", final_content),"score":int(score)}
source_folder = 'memory'
memory_name_list=[]
source_folder_path = os.path.join(os.getcwd(), source_folder)
for root, dirs, files in os.walk(source_folder_path):
for dir in dirs:
memory_name_list.append(dir)
success_print(memory_name_list)
def find(s,step = 0,memory_name="test2"): #"test2",
try:
scor_min=700
docs_min=[]
for memory_name in memory_name_list:
docs = []
scor=0
n=0
embedding = get_vectorstore(memory_name).embedding_function(s)
scores, indices = vectorstores[memory_name].index.search(np.array([embedding], dtype=np.float32), int(cunnrent_setting.count))
#print("scores, indices:",scores, indices)
for j, i in enumerate(indices[0]):
if i == -1:continue
if scores[0][j]>700:continue
docs.append(get_doc(i,scores[0][j],step,memory_name))
scor+=scores[0][j]
n+=1
if n!=0:
scor=scor/n
if scor_min>scor:
scor_min=scor
docs_min=docs
docs=docs_min
print(scor_min)
print(docs)
return docs
except Exception as e:
print(e)
return []
try:
embeddings = HuggingFaceEmbeddings(model_name='')
embeddings.client = sentence_transformers.SentenceTransformer(cunnrent_setting.model_path, device=cunnrent_setting.device)
except Exception as e:
error_helper("embedding加载失败,请下载相应模型",r"https://github.com/l15y/wenda#st%E6%A8%A1%E5%BC%8F")
raise e
vectorstores={}
def get_vectorstore(memory_name):
try:
return vectorstores[memory_name]
except Exception as e:
try:
vectorstores[memory_name] = FAISS.load_local(
'memory/'+memory_name, embeddings=embeddings)
return vectorstores[memory_name]
except Exception as e:
success_print("没有读取到RTST记忆区%s,将新建。"%memory_name)
return None
from langchain.docstore.document import Document
from langchain.text_splitter import CharacterTextSplitter
from bottle import route, response, request, static_file, hook
import bottle
@route('/api/upload_rtst_zhishiku', method=("POST","OPTIONS"))
def upload_zhishiku():
allowCROS()
try:
data = request.json
title=data.get("title")
memory_name=data.get("memory_name")
data = re.sub(r'!', "!\n", data.get("txt"))
data = re.sub(r'。', "。\n", data)
data = re.sub(r'[\n\r]+', "\n", data)
docs=[Document(page_content=data, metadata={"source":title })]
print(docs)
text_splitter = CharacterTextSplitter(
chunk_size=20, chunk_overlap=0, separator='\n')
doc_texts = text_splitter.split_documents(docs)
texts = [d.page_content for d in doc_texts]
metadatas = [d.metadata for d in doc_texts]
vectorstore_new = FAISS.from_texts(texts, embeddings, metadatas=metadatas)
vectorstore=get_vectorstore(memory_name)
if vectorstore is None:
vectorstores[memory_name]=vectorstore_new
else:
vectorstores[memory_name].merge_from(vectorstore_new)
return '成功'
except Exception as e:
return str(e)
@route('/api/save_rtst_zhishiku', method=("POST","OPTIONS"))
def save_zhishiku():
allowCROS()
try:
data = request.json
memory_name=data.get("memory_name")
vectorstores[memory_name].save_local('memory/'+memory_name)
#print("保存到了"+'memory/'+memory_name)
return "保存成功"
except Exception as e:
return str(e)
import json
@route('/api/find_rtst_in_memory', method=("POST","OPTIONS"))
def api_find():
allowCROS()
data = request.json
prompt = data.get('prompt')
step = data.get('step')
memory_name=data.get("memory_name")
if step is None:
step = int(settings.library.step)
# for i in range
return json.dumps(find(prompt,int(step),memory_name_list))
@route('/api/save_news', method=("POST","OPTIONS"))
def save_news():
allowCROS()
try:
data = request.json
if not data:
return 'no data'
title = data.get('title')
txt = data.get('txt')
cut_file = f"txt/{title}.txt"
with open(cut_file, 'w', encoding='utf-8') as f:
f.write(txt)
f.close()
return 'success'
except Exception as e:
return(e)
@route('/api/read_news/:path', method=("GET","OPTIONS"))
def read_news(path=""):
allowCROS()
return static_file(path, root="txt/")
3.3 ptuning微调
这里首先用官方的工具,生成对话的json数据,然后就修改main文件的参数,训练一下。