Linux系统实现MySQL的主从复制及读写分离
介绍
MySQL主从复制是一个异步的复制过程,底层是基于Mysql数据库自带的二进制日志功能。就是一台或多台MysQL数据库(slave,即从库),从另一台MysQL数据库(master,即主库)进行日志的复制然后再解析日志并应用到自身,最终实现从库的数据和主库的数据保持一致。MySQL主从复制是MysQL数据库自带功能,无需借助第三方工具。
MySQL复制过程分成三步:
-
master将改变记录到二进制日志(binary log)
-
slave将master的binary log拷贝到它的中继日志 (relay log)
-
slave重做中继日志中的事件,将改变应用到自己的数据库中

配置-前置条件
提前准备好两台服务器,分别安装Mysql并启动服务成功
-
主库Master 192.168.91.130
-
从库Slave 192.168.91.5
配置-主库 Master
第一步:修改Mysql数据库的配置文件/etc/my.cnf
#进入my.cng修改配置
vim /etc/my.cng[mysqld]
log-bin=mysql-bin #[必须]启用二进制日志
server-id=100 #[必须]服务器唯一ID第二步:重启Mysql服务
systemctl restart mysqld第三步:登录Mysql数据库,执行下面SQL
grant replication slave on *.* to 'xiaoming'@'%' identified by '123456';注:上面SQL的作用是创建一个用户xiaoming,密码为123456,并且给xiaoming用户授予REPLICATION SLAVE权限。常用于建立复制时所需要用到的用户权限,也就是slave必须被master授权具有该权限的用户,才能通过该用户复制。
第四步:登录Mysql数据库,执行下面SQL,记录下结果中File和Position的值
show master status;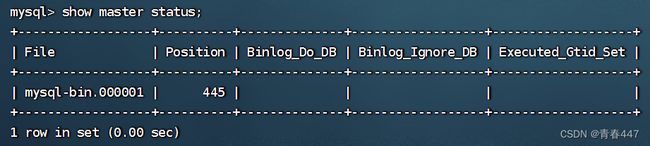
注:上面SQL的作用是查看Master的状态,执行完此SQL后不要再执行任何操作。
配置-从库 Slave
第一步:修改Mysql数据库的配置文件/etc/my.cnf
vi /etc/my.cnf
[mysqld]
server-id=101 #[必须]服务器唯一ID第二步:重启Mysql服务
systemctl restart mysqld第三步:登录Mysql数据库,执行下面SQL。(master_user,master_password为主机分配复制的账号,上图所示。)
change master to
master_host='192.168.91.130',master_user='xiaoming',master_password='123456',
master_log_file='mysql-bin.000001',master_log_pos=154;开启从机
start slave;查看slave状态
show slave status \G #如意下图,必须均为yes才算配置成功
总结:
出现无法同步状况,可按下边步骤反复尝试:
方法一:
1.先show slave status \G;查看错误信息
2.使用命令尝试,可以多尝试几遍:
mysql> stop slave;
mysql> SET GLOBAL SQL_SLAVE_SKIP_COUNTER=1; START SLAVE;
mysql> start slave;
mysql> show slave status\G
方法二:
1..进行手动同步
mysql> stop slave;
mysql> change master to
-> master_host='192.168.203.132',
-> master_user='xiaoming',
-> master_password='123456',
-> master_log_file='master-a-bin.000001',
-> master_log_pos=120;
Query OK, 0 rows affected, 2 warnings (0.02 sec)
mysql> start slave;
mysql> show slave status \G;Mysql读写分离
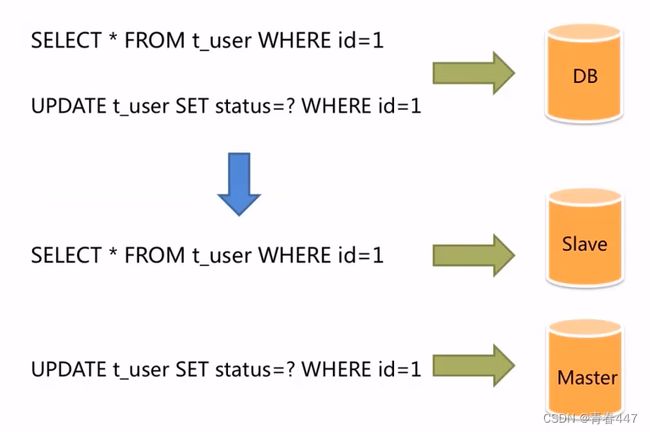
面对日益增加的系统访问量,数据库的吞吐量面临着巨大瓶颈。对于同一时刻有大量并发读操作和较少写操作类型的应用系统来说,将数据库拆分为主库和从库,主库负责处理事务性的增删改操作,从库负责处理查询操作,能够有效的避免由数据更新导致的行锁,使得整个系统的查询性能得到极大的改善。
Sharding-JDBC介绍
Sharding-JDBC定位为轻量级Java框架,在Java的JDBC层提供的额外服务。它使用客户端直连数据库,以jar包形式提供服务,无需额外部署和依赖,可理解为增强版的JDBC驱动,完全兼容JDBC和各种ORM框架。 使用Sharding-JDBC可以在程序中轻松的实现数据库读写分离。
-
适用于任何基于JDBC的ORM框架,如:JPA, Hibernate,Mybatis, Spring JDBC Template或直接使用JDBC。
-
支持任何第三方的数据库连接池,如:DBCP,C3PO,BoneCP, Druid, HikariCP等。
-
支持任意实现JDBC规范的数据库。目前支持MySQL,Oracle,SQLServer,PostgreSQL以及任何遵循SQL92标准的数据库。
使用Sharding-JDBC实现读写分离步骤:
1.导入maven坐标
org.apache.shardingsphere
sharding-jdbc-spring-boot-starter
4.0.0-RC1
2.在配置文件中配置读写分离规则
3.在配置文件中配置允许bean定义覆盖配置项
spring:
shardingsphere:
datasource:
names:
master,slave
#主数据源
master:
username: root
password: root
url: jdbc:mysql://192.168.91.130:3306/reggie?useSSL=false&useUnicode=true&characterEncoding=utf8&serverTimezone=GMT
driver-class-name: com.mysql.cj.jdbc.Driver
type: com.alibaba.druid.pool.DruidDataSource
#从数据源
slave:
username: root
password: dong1028..
url: jdbc:mysql://192.168.91.5:3306/reggie?useSSL=false&useUnicode=true&characterEncoding=utf8&serverTimezone=GMT
driver-class-name: com.mysql.cj.jdbc.Driver
type: com.alibaba.druid.pool.DruidDataSource
masterslave:
#读写分离配置(负载均衡的策略:轮询)
load-balance-algorithm-type: round_robin
#最终的名字
name: dataSource
#主库数据源名称
master-data-source-name: master
#从库数据源名称列表,多个逗号分隔
slave-data-source-names: slave
props:
sql:
show: true #开启SQL显示,默认为false
main:
#允许bean定义覆盖配置项
allow-bean-definition-overriding: true