【Tessent】Scan and ATPG 【ch8 Test Pattern Generation】Timing-Aware ATPG
Timing-Aware ATPG
- 1. Slack Calculation
-
- Path Delay Calculation
- Slack Calculation When Timing Exceptions Are Present
-
- False Paths
- multicycle paths
- 2. Synopsys Design Constraint Derived Clock Timing
- 3. Delay Test Coverage Calculation
- 4. Timing-Aware ATPG Versus Transition ATPG
- 5. Timing-Aware ATPG Limitations
- 6. Inaccuracies in Timing Calculations
- 7. Running Timing-Aware ATPG
-
- 7.1 Prerequisites
- 7.2 Procedure
- 7.3 Examples
- 8. Troubleshooting Topics
-
- Run Time Reduction for Timing-Aware ATPG
- Errors and Warnings While Reading SDF Files
- Warnings During ATPG
- Actual Slack Smaller Than Tms
时序感知ATPG从标准延迟格式(Standard Delay Format ,SDF)文件读取时序信息,并尝试生成使用最长检测路径来检transition fault的向量。
1. Slack Calculation
Slack等于路径延迟和时钟周期之间的裕度(margin)。Small Delay Fault Model 中的 Slack 表示可以检测到的最小延迟故障。
下图所示为slack的计算。假设三条路径R1,R2,R3可以检测到一个故障,其路径延时分别为 8.5ns,7.5ns 和 4.5ns。若时钟周期为10ns,则这三条路径的 slack 依次为 1.5ns,2.5ns 和 0.5ns。
对于最长的路径,从 leading edge 的 launch,到下一个时钟周期的 leading edge 的 capture ,具有 1.5 ns 的 slack,因此该路径能够检测到最小延时缺陷是1.5ns。
对于最短的路径,从 leading edge 的 launch 到当前时钟周期的 falling edge 的 captures,具有0.5ns 的 slack。为了检测故障点(fault site)的小延迟,应该生成能够通过该路径(Shortest)检测故障的测试向量,因为它具有最小的 slack。

=============================================================================
补充:
在每个周期中,第一个出现的边沿就是 leading edge,最后一个出现的边沿就是 trailing edge。

=============================================================================
Path Delay Calculation
当 clock skew 存在时,它会影响到达时间和传播时间。在计算路径延迟时,Tessent 工具使用以下算法来确保考虑到时clock skew 的影响:
- 计算设计中每一个门的到达时间(arrival time)
时序单元到达时间的初始值等于其所有时钟端口之间的最大时钟延迟。这意味着任何gate的到达时间是和时钟输入端口的值合适改变相关,而不是驱动触发器何时改变值相关。
- 计算传播时间(propagation time)
对于直接驱动时序单元(clock cone)时钟端口的门,初始传播延迟设置为零;
对于直接驱动时序单元(data path)数据端口的门,初始传播延迟设置为其时钟延迟的负值(而不是零)。
计算公式如下:

示例:
下图所示的示例电路的时钟周期是8,根据上述算法的延时信息计算结如图上内容所示:

根据计算结果,关键路径应该是 dff2 → g1 → g3 。
Slack Calculation When Timing Exceptions Are Present
False paths 和 multicycle paths 会影响 slack 和 path delay 的计算。
False Paths
multicycle paths
2. Synopsys Design Constraint Derived Clock Timing
timing-aware ATPG 使用来自 SDC(Synopsys Design Constraint)的 derived clocks 的 divided-by ratio 信息,并根据SDC中的定义对其进行调整。
如果图 8-48 示例中的时钟是一个 divided-by-two clock,那么其时钟周期是20ns。
3. Delay Test Coverage Calculation
ATPG计算一个称为延迟测试覆盖率(Delay Test Coverage)的参数(metric),以确定测试向量的质量。当启用timing-aware ATPG时,延迟测试覆盖覆盖率会自动包含在ATPG统计报告中。
每个待测故障的权重根据slack进行修改,slack 最接近最小动态 slack 的路径拥有更高的权重。
延迟测试覆盖率(delay test coverage,DTC)的公式:
![]()
-
max_static_interval —— 通过故障点的所有物理路径中,发射沿和捕获沿之间的时间间隔的最大值。下图的实例中,R1 和 R2 的时间间隔是一个完整的时钟周期,而R3的时间间隔是半个时钟周期,图8-48所给的示例中,通过故障点的最大动态时间间隔是一个时钟周期。
-
dynamic_slack —— 用于检测故障的路径的延时和该路径的发射沿和捕获沿之间的时间间隔的差值。
-
static_slack —— 通过故障点的所有物理路径的slack的最小值
=============================================
结合7.3节的例子,对 DTC 的一些思考:
时钟周期减去 slack 不就是路径延时?
那么 max_static_interval - static_slack 其实就是通过故障点的最大路径延时,
max_static_interval - dynamic_slack 其实就是确定用以检测故障的路径的延时,
简单而言,应该是路径本身的延时越大,能够检测到的延时的范围就越大,所以这里就采用路径延时的比值来作为评估测试向量质量的参数,称之为延时测试覆盖率。
=============================================
在图 8 - 48 给出的示例中,minimum slack 是0.5ns,每条路径的延时测试覆盖率如下:

Undetected faults 的延时测试覆盖率为 0,DI faults 的延时测试覆盖率为100%。
Chip-level 延时测试覆盖率的计算是对所有的故障的延时测试覆盖求平均值。
4. Timing-Aware ATPG Versus Transition ATPG
表 8-4 给出了transition fault ATPG 和 tinming-aware ATPG 的对比。
测试用例 STARC03 的特征如下:
- Design Size: 2.4M sim_gate
- Number of FFs: 69,153
- CPU: 2.2Ghz
- 315 sec to read SDF file that has 10,674,239 lines

ATPG运行时的相关参数通过set_atpg_timing命令设置。
5. Timing-Aware ATPG Limitations
执行 timing-aware ATPG的一些限制:
- SDF文件的读取有一定的限制,
read_sdf命令中有具体的描述 - 不支持 Launch-off shift
- timing-aware ATPG 的运行速度要比常规的 transition fault ATPG 慢8倍。Targeting critical faults may help
- 大规模的组合回路可能会减慢计算静态松弛(static slack)的分析速度。这也使得实际的延迟分析不那么准确。
- timing-aware ATPG 的 transition 测试覆盖率可能会低于常规的transition fault ATPG,因为timing-aware ATPG试图通过更长的路径来检测故障,因此更有可能达到中止限制。可以使用
creat_patterns命令的-coverage_effort high选项来提高transition测试覆盖率,但是同时,改选项也会增加运行时间。 - NCP(Named Capture Procedure)中的时序信息不包括在静态松弛计算中。
- 保存检查点(check point)时,不会存储SDF数据库。使用 flattened model 时,必须使用
read_SDF命令重新加载SDF数据 - 当指定
-Slack_margin_for_fault_dropping时,不能使用Static Compression(compress_patterns命令)和 pattern ordering(order_patterns指令)。 - SDF文件不会影响good machine simulation的值。SDF文件主要用于引导 timing-aware ATPG 检测 long path 上的故障以及计算延迟测试覆盖范围。也就是说,工具不会从SDF文件中的延迟提取(或推断)false path 和 multicycle paths 。您须通过SDC文件或
add_false_paths命令来提供该信息。
6. Inaccuracies in Timing Calculations
基于SDF文件执行timing-aware ATPG时,导致时序计算不准确的部分原因如下:
- 不支持 Device Delay
- 不支持 Conditional delay。对于给定的 IOPATH 或 INTERCONNECT 引脚对,工具在计算静态和实际延迟时,使用的是为该引脚对定义的所有条件延迟中的最大值。
- 支持Negative delay。但是,如果路径延迟是负数,则在计算延迟覆盖率、路径延迟和松弛等参数时,工具会强制延迟值为0
7. Running Timing-Aware ATPG
使用ATPG工具执行Timing-Aware ATPG的基本步骤
7.1 Prerequisites
-
因为 timing-aware ATPG是建立在 transition ATPG 技术之上的,所以在开始此过程之前,必须先设置transition ATPG。
-
STA(static timing analysis)得到的 SDF 文件
7.2 Procedure
- 使用
read_sdf命令从SDF文件中加载时序信息
ANALYSIS> read_sdf top_worst.sdf
- 使用
set_atpg_timing命令定义时钟信息。您必须为设计中的所有时钟定义时钟信息,即使是那些未用于ATPG(未用于NCP过程)的时钟。
ANALYSIS> set_atpg_timing -clock clk_in 36000 18000 18000
ANALYSIS> set_atpg_timing -clock default 36000 18000 18000
- 使用
set_ATPG_timing命令启用 timing-aware ATPG。
ANALYSIS> set_atpg_timing on -slack_margin_for_fault_dropping 50%
如果为故障排除 (fault dropping) 指定了裕度 (slack margin),则故障仿真会保留故障以生成向量,直到达到阈值为止。在正常的 transition fault 仿真过程中,一旦检测到故障,故障就会被丢弃(drop)。
- 使用
set_atpg_timing命令选择时序关键的故障
ANALYSIS> set_atpg_timing -timing_critical 90%
- 运行ATPG
ANALYSIS> create_patterns -coverage_effort high
- 使用
report_statistics命令报告 delay_fault 的测试覆盖率
ANALYSIS> report_statistics
7.3 Examples
图8-52显示了一个测试用例,其中有17个扫描触发器和10个组合门。
每个门具有1ns的延迟,并且扫描触发器上没有延迟。G5/Y 处插入了一个 slow-to-rise fault。测试周期为12ns。最后一个扫描触发器(U17)具有 OX 单元约束,因此它不能用作观察点。
最长的路径从U1开始,经过 G1 到 G10,并在U17结束。总路径延迟为10ns。因为U17不能用作观测点,所以timing-aware ATPG 使用从U1开始、经过 G1 到 G9 并在 U16 结束的路径。总路径延迟为9ns。
因此,
静态最小松弛度(static minimum slack)为 12ns-10ns = 2ns;
最佳实际松弛度(the best actual slack) 为 12ns-9ns = 3ns。

图 8-53 显示了本例中使用的dofile。如注释所述,dofile将执行 7.2 小节中描述的过程。

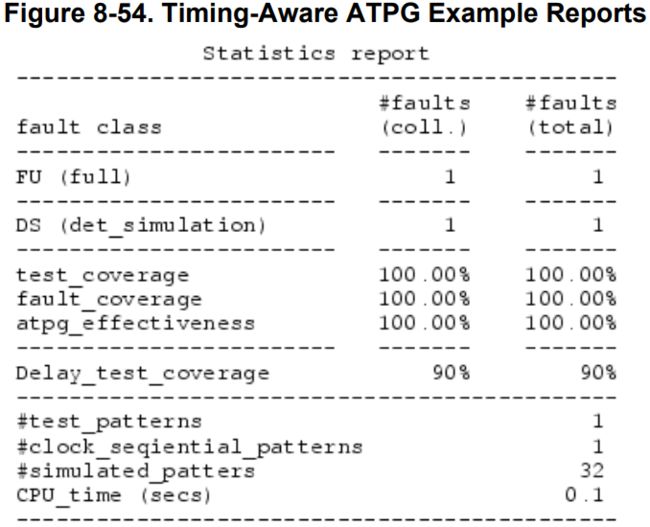
图8-54显示了故障统计报告。timing-aware ATPG使用了最长的可能路径,即延时为9ns的路径。静态最长路径(Static longest path)延时为10ns。延迟测试覆盖率为 9ns / 10ns = 90%。
8. Troubleshooting Topics
该部分描述了与 timing-aware ATPG 相关的常见问题。(troubleshoot,疑难解答)