Linux线程理解
各位大佬大家好,我是猪皮兄弟

文章目录
- 一、线程概念
-
- Linux特有线程方案
- 二、什么是进程?
-
- 资源角度
- 在CPU的视角
- 轻量级进程
- 三、pthread线程库初使用
-
- pthread库的介绍
- pthread_create
- 四、线程如何看待进程内部的资源
- 五、进程vs线程
- 六、线程缺点
一、线程概念
通过一定的技术手段,将当前进程的资源以一定的方式划分给不同的task_struct(CPU只管调度)
但是这种方式的task_struct和之前最大的区别就是不再重新申请地址空间,不再重新申请页表,创建出来伸手要资源就可以了
那么这里面的每一个task_strcut我们就可以叫做一个线程
线程在进程内部执行:线程在进程的地址空间内运行,因为共享一个地址空间
线程是OS调度的基本单位,CPU不关心执行流是线程还是进程,它只关心task_struct

Linux特有线程方案
这种方案是Linux特有的:
不同的操作系统有不同的实现方案,只要满足了调度比进程更轻,创建,维护成本更低,那么它就是线程
只是说,在Linux中,没有专门为线程设计单独的数据结构
在Windows当中,就有真正的线程
系统中存在大量进程,就意味着存在大量的线程
如果创建特定的数据结构,这个结构中的代码,逻辑等等,其中有相当一部分是非常类似的,所以如果想Windows这样单独设计,那么很多工作是重复的
所以Linux决定,没必要在内核层面区分进程和线程,所有进程和线程都通过task_struct来统一表示,只不过进程有独立的地址空间,线程共享地址空间
二、什么是进程?
资源角度
在用户视角:
进程 = 内核数据结构 + 代码和数据
在Linux当中,进程是可以有多个PCB的,因为这时Linux的特有方案,线程也是PCB,没有设计新的数据结构,都是PCB(task_struct)
在内核视角
进程是承担分配系统资源的基本实体
第一个PCB创建的时候,向OS申请PCB,进程地址空间,页表,这些都是在申请系统资源,以进程的身份,而后面线程就是直接像进程要
在没有学习线程的时候,我们写的代码叫做内部只有一个执行流的进程,有了线程,进程就是内部有多个执行流的进程
那么进程就是一大批的执行流(最少一个)+地址空间、页表等数据结构+进程所对应的代码和数据整体以基本单位 的方式向OS申请对应资源(我们可以称task_struct为进程内部的一个执行流)
在CPU的视角
CPU并不关心他是进程还是线程,它只认识task_struct,CPU调度的是这个结构体,它只关心一个执行流(所以线程是操作系统调度的基本单位)
轻量级进程
在Linux下,PCB<=其他OS内的PCB,这叫做量级更轻
当我们一个进程只有一个执行流的时候,PCB==其他OS内的PCB
Linux下的进程,我们统一称之为:轻量级进程
三、pthread线程库初使用
pthread库的介绍
因为Linux并没有真正的线程结构,所以Linux并不能直接给我提供线程相关结构,只能给我们提供轻量级进程的接口
我们不可能说重新去为了这一个Linux独特的设计去重新学习什么是轻量级进程,接口怎么使用,所以反正我用户只知道进程和线程
那么,就有了POSIX标准的pthread线程库
pthread_create
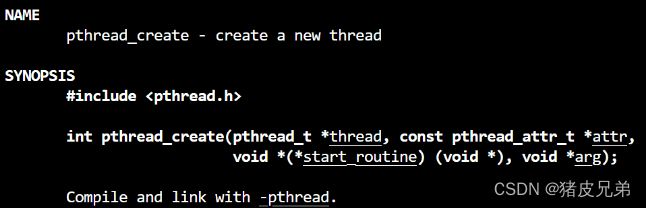
参数一是线程id,但是它其实是一个地址,每个线程都会在pthread共享库维护一块数据,线程id,线程局部存储,线程栈,所以干脆就拿这部分的起始地址做线程id,线程的调度和内核数据结构是OS维护,其他的都是pthread原生线程库在维护
参数二是线程属性,一般我们可以不用管,传nullptr
参数三是函数指针(返回类型void*,参数类型void*)也就是说可以接受任何类型,这个函数就是创建线程之后自动调用的线程函数,也就是回调函数
参数四是给这个函数的参数,线程创建后,会把参数四传给参数三,从而完成回调
创建成功,返回0,失败,返回错误码,线程未定义
#include 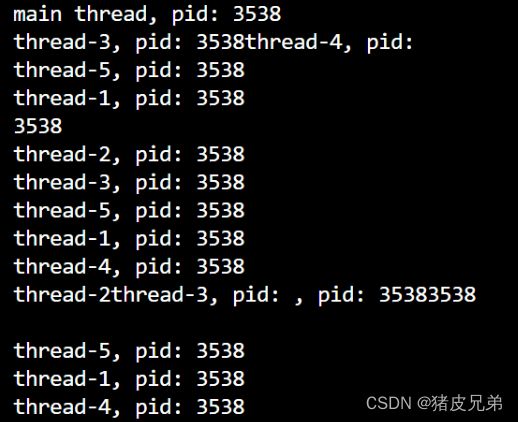
得出结论:这些线程是在一个进程当中运行的(指的是共用进程资源)
ps -aL #查看轻量级进程
-L#表示轻量级进程 light weight process
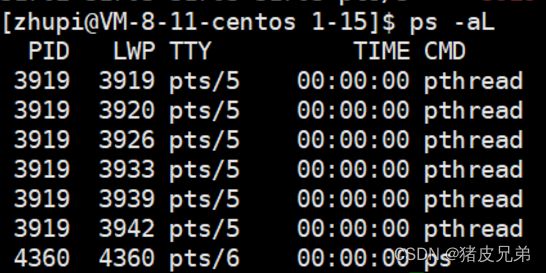
PID相同说明属于同一个进程,但是还有一个字段不同
LWP - light weight process轻量级进程
LWP就是轻量级进程的ID
PID和LWP相同的就是主执行流
当只有一个执行流的时候,我们说看PID,因为单执行流PID==LWP所以无所谓,现在我们需要看 LWP
当我们杀掉一个进程的时候,一个进程内的全部执行流就都停止了,因为线程是依靠进程的,线程的所以资源都是找线程要的,所以进程/主线程挂掉,全部执行流就都挂掉
四、线程如何看待进程内部的资源
大部分资源,线程是共享的
比如:
文件描述符表(进程打开的所有文件)
每种型号的处理方式(SIG_DFL,SIG_IGN或者自定义)
当前工作目录
用户id和组id/谁起的这个线程,用户所属组
代码区(写一个函数,所有线程都能用,只要找到)
全局变量(已初始化,未初始化)
堆区(堆区也是共享的,malloc的空间如果愿意,也可以其他线程使用,但是一般都是在自己线程函数里面申请,所以其他线程不方便拿到地址,但是确实是共享的,基于以上原因,我们一般看做私有)
共享区
栈区(严格来说,可以共享,但是地址不方便拿到,所以我们不这么干,也认为栈是私有的,但是如果想的话也可以)
有些资源是私有的
比如
线程id
一组寄存器(线程上下文)
栈(每个线程需要调用自己的函数完成某种功能,一定涉及到出栈入栈,形成的临时变量需要保存到栈里面,所以需要有自己的私有栈(允许独自占用))
五、进程vs线程
如果调度的是一个进程内的若干个线程
1.地址空间不需要切换,虽然这也就是一个寄存器的值
2.页表不需要切换,也是一个寄存器的值
这些东西成本不高,不是顺手的事吗
但是进程和线程相比,切换成本高的核心原因是CPU内部有缓存的(硬件级别的缓存 三级高速缓存cache),因为是硬件级别的缓存,速度才能和CPU相比
如果一条指令就要访问一次内存,那效率就太低了,所以当CPU读指令的时候,CPU中会有缓存,同时会加载当前指令后面的部分指令进去(预读),以后再执行的时候,有非常大的概率在CPU内部就完成对指令的操作(通过三级高速缓存cache)—>称作局部性原理
正因为CPU有这个特性,从概率上来讲,可以被直接优化,多个线程直接从缓存中就可以读取,提高线程效率
如果是进程间切换,因为进程的独立性,一旦切换,对应的cache就立即失效,只能重新缓存,成本非常高,所以线程切换更轻量化的原因其实是在这里
但是呢,也不是线程越多越好,有些时候,创建太多,实际上CPU还要进行线程切换,虽然成本比进程切换低,但是依旧有成本,那么有可能创建太多这个主要矛盾就不是任务本身了,而是线程的切换成本
计算密集型:比如我要对10个G的文件加密,实行各种算法,这就叫做计算密集型,比如说我把文件拆成1G,创建十个进程,再合并起来,但是呢,如果计算机是单核的,不如只要一个线程去加密,效率反而高
I/O密集型
大多时候都在做I/O,创建的线程可以多一些,但是一般也就是创建线程总数基本上等于CPU的核数
六、线程缺点
1.性能损失
这个其实不算线程的问题,而是线程创建多少的问题
2.健壮性降低
一个线程出了问题,很容易出问题
比如主线程挂掉就都挂了,侧面说明了健壮性太差
3.缺乏访问控制
多进程好歹有一个写时拷贝来防止进程访问时的安全问题
而线程大部分是共享的,访问的时候不知道别人有没有访问,所以同时在访问,容易出问题,但是也有解决方案。但是缺乏访问控制也带来了一定的好处,比如交互数据时成本变低
4.编程难度变高
主要是因为多线程程序难调试,比如说除了一个问题,但是呢并不是这个问题本身,而是线程之间导致的
