基于Python的网络爬虫爬取天气数据可视化分析
目录
摘 要 1
一、 设计目的 2
二、 设计任务内容 3
三、 常用爬虫框架比较 3
四、网络爬虫程序总体设计 3
四、 网络爬虫程序详细设计 4
4.1设计环境和目标分析 4
4.2爬虫运行流程分析 5
爬虫基本流程 5
发起请求 5
获取响应内容 5
解析数据 5
保存数据 5
Request和Response 5
Request 5
Response 5
请求方式 5
GET 5
POST 5
URL 6
请求体 6
4.3控制模块详细设计 6
v = [] 8
v = [] 9
六、调试与测试 11
七、心得体会 12
参考文献 13
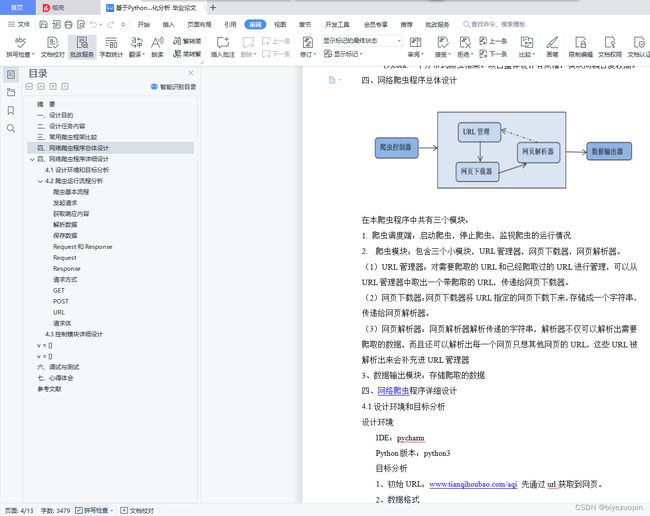
在本爬虫程序中共有三个模块:
1.爬虫调度端:启动爬虫,停止爬虫,监视爬虫的运行情况
2.爬虫模块:包含三个小模块,URL管理器,网页下载器,网页解析器。
(1)URL管理器:对需要爬取的URL和已经爬取过的URL进行管理,可以从URL管理器中取出一个带爬取的URL,传递给网页下载器。
(2)网页下载器:网页下载器将URL指定的网页下载下来,存储成一个字符串,传递给网页解析器。
(3)网页解析器:网页解析器解析传递的字符串,解析器不仅可以解析出需要爬取的数据,而且还可以解析出每一个网页只想其他网页的URL,这些URL被解析出来会补充进URL管理器
3、数据输出模块:存储爬取的数据
四、网络爬虫程序详细设计
4.1设计环境和目标分析
设计环境
IDE:pycharm
Python版本:python3
目标分析
1、初始URL:www.tianqihoubao.com/aqi 先通过url获取到网页。
2、数据格式
3、页面编码:UTF—8
4.2爬虫运行流程分析
爬虫基本流程
发起请求
通过HTTP库向目标服务器发送Request,Request内可以包含额外的headers信息。
获取响应内容
如果服务器正常响应,会返回Response, 里面包含的就是该页面的内容。
解析数据
内容或许是HTML,可以用正则表达式、网页解析库进行解析。
或许是Json,可以直接转换为Json对象解析。
保存数据
可以存储为文本,也可以保存至数据库,或其他特定类型文件。
Request和Response
Request
主机向服务器发送数据请求时的过程叫做HTTP Request
Response
服务器向主机返回数据的过程叫做HTTP Response
Request中包含的内容
请求方式
常用的有GET,POST两种类型。
GET
这种请求方式的参数都包含在网址里面。
POST
这种请求方式的参数包含在请求体中的form data中。相对安全。
URL
请求的网络链接。
请求头
包含请求时的头部信息。如:User-Agent、Host、Cookies等。
User-Agent
指定浏览器。
请求体
GET请求下一般情况请求体中不会包含重要信息。
POST请求中包含重要信息。
Response中包含的内容
响应状态
Status Code:200
即状态码,一般200表示响应成功。
响应头
Response Headers
内容类型,内容长度,服务器信息,设置Cookie等。
响应体
请求资源的内容,如网页源代码,二进制数据等。
4.3控制模块详细设计
爬取代码
import time
import requests
from bs4 import BeautifulSoup
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'
}
citys = ['beijing', 'shanghai', 'guangzhou', 'shenzhen']
for i in range(len(citys)):
time.sleep(5)
for j in range(1, 13):
time.sleep(5)
# 请求2018年各月份的数据页面
url = 'http://www.tianqihoubao.com/aqi/' + citys[i] + '-2018' + str("%02d" % j) + '.html'
# 有请求头(键值对形式表示请求头)
response = requests.get(url=url, headers=headers)
# html字符串创建BeautifulSoup对象
soup = BeautifulSoup(response.text, 'html.parser')
tr = soup.find_all('tr')
for k in tr[1:]:
td = k.find_all('td')
# 日期
Date = td[0].get_text().strip()
# 质量等级
Quality_grade = td[1].get_text().strip()
# AQI指数
AQI = td[2].get_text().strip()
# 当天AQI排名
AQI_rank = td[3].get_text().strip()
# PM2.5
PM = td[4].get_text()
# 数据存储
filename = 'air_' + citys[i] + '_2018.csv'
with open(filename, 'a+', encoding='utf-8-sig') as f:
f.write(Date + ',' + Quality_grade + ',' + AQI + ',' + AQI_rank + ',' + PM + '\n')
分析代码
import numpy as np
import pandas as pd
from pyecharts import Line
citys = ['beijing', 'shanghai', 'guangzhou', 'shenzhen']
v = []
for i in range(4):
filename = 'air_' + citys[i] + '_2018.csv'
df = pd.read_csv(filename, header=None, names=["Date", "Quality_grade", "AQI", "AQI_rank", "PM"])
dom = df[['Date', 'AQI']]
list1 = []
for j in dom['Date']:
time = j.split('-')[1]
list1.append(time)
df['month'] = list1
month_message = df.groupby(['month'])
month_com = month_message['AQI'].agg(['mean'])
month_com.reset_index(inplace=True)
month_com_last = month_com.sort_index()
v1 = np.array(month_com_last['mean'])
v1 = ["{}".format(int(i)) for i in v1]
v.append(v1)
attr = ["{}".format(str(i) + '月') for i in range(1, 12)]
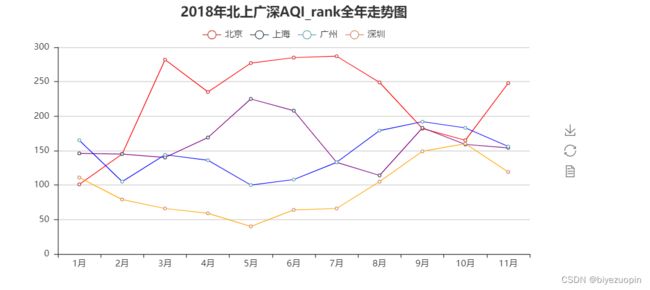
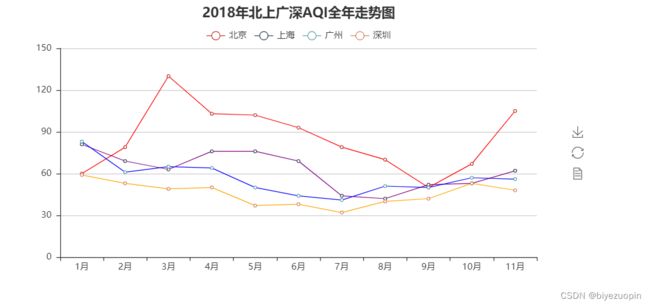
line = Line("2018年北上广深AQI全年走势图", title_pos='center', title_top='0', width=800, height=400)
line.add("北京", attr, v[0], line_color='red', legend_top='8%')
line.add("上海", attr, v[1], line_color='purple', legend_top='8%')
line.add("广州", attr, v[2], line_color='blue', legend_top='8%')
line.add("深圳", attr, v[3], line_color='orange', legend_top='8%')
line.render("2018年北上广深AQI全年走势图.html")
import numpy as np
import pandas as pd
from pyecharts import Pie, Grid
citys = ['beijing', 'shanghai', 'guangzhou', 'shenzhen']
v = []
attrs = []
for i in range(4):
filename = 'air_' + citys[i] + '_2018.csv'
df = pd.read_csv(filename, header=None, names=["Date", "Quality_grade", "AQI", "AQI_rank", "PM"])
rank_message = df.groupby(['Quality_grade'])
rank_com = rank_message['Quality_grade'].agg(['count'])
rank_com.reset_index(inplace=True)
rank_com_last = rank_com.sort_values('count', ascending=False)
attr = rank_com_last['Quality_grade']
attr = np.array(rank_com_last['Quality_grade'])
attrs.append(attr)
v1 = rank_com_last['count']
v1 = np.array(rank_com_last['count'])
v.append(v1)
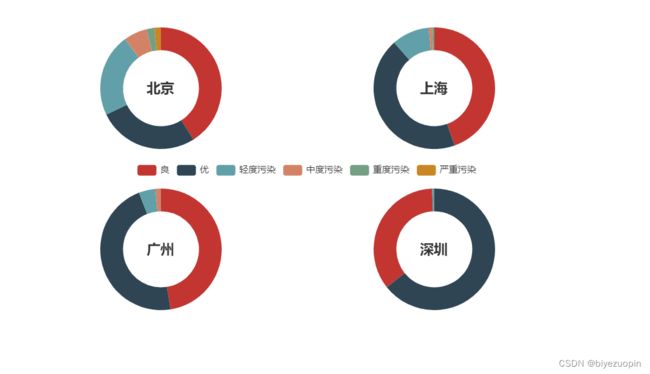
pie1 = Pie("北京", title_pos="28%", title_top="24%")
pie1.add("", attrs[0], v[0], radius=[25, 40], center=[30, 27], legend_pos="27%", legend_top="51%", legend_orient="horizontal",)
pie2 = Pie("上海", title_pos="58%", title_top="24%")
pie2.add("", attrs[1], v[1], radius=[25, 40], center=[60, 27], is_label_show=False, is_legend_show=False)
pie3 = Pie("广州", title_pos='28%', title_top='77%')
pie3.add("", attrs[2], v[2], radius=[25, 40], center=[30, 80], is_label_show=False, is_legend_show=False)
pie4 = Pie("深圳", title_pos='58%', title_top='77%')
pie4.add("", attrs[3], v[3], radius=[25, 40], center=[60, 80], is_label_show=False, is_legend_show=False)
grid = Grid("2018年北上广深全年空气质量情况", width=1200)
grid.add(pie1)
grid.add(pie2)
grid.add(pie3)
grid.add(pie4)
grid.render('2018年北上广深全年空气质量情况.html')