2022经典前端面试题大全 h5 +cs +js
一、页面布局
三栏布局
题目:假设高度已知,请写出三栏布局,其中左栏、右栏宽度各为 300px,中间自适应。
解答:可以有很多种布局方式,这里列出五种:float布局,absolute布局,flex布局,table布局,grid布局,代码如下:
面试时至少写出三种哦。
接下来问题可能会有三个延伸方向:
-
每种方案的优缺点?
-
如果高度不固定,实践中一般用哪种?
-
以上几种方案的兼容性如何?
每种布局的优缺点
1. float 布局
优点: 比较简单,兼容性也比较好。只要清除浮动做的好,是没有什么问题的
缺点:浮动元素是脱离文档流,要做清除浮动,这个处理不好的话,会带来很多问题,比如高度塌陷等。
2. 绝对布局
优点:很快捷,设置很方便,而且也不容易出问题
缺点:绝对定位是脱离文档流的,意味着下面的所有子元素也会脱离文档流,这就导致了这种方法的有效性和可使用性是比较差的。
absolute布局
1.我是absolute布局的中间部分 2.我是absolute布局的中间部分
3. flex 布局
优点:简单快捷
缺点:不支持 IE8 及以下
flex布局
1.我是flex布局的中间部分 2.我是flex布局的中间部分
4. table布局
优点:实现简单,代码少
缺点:当其中一个单元格高度超出的时候,两侧的单元格也是会跟着一起变高的,而有时候这种效果不是我们想要的。
table布局
1.我是table布局的中间部分 2.我是table布局的中间部分
5. grid布局
跟 flex 相似。
grid布局
1.我是grid布局的中间部分 2.我是grid布局的中间部分
水平垂直居中
absolute + 负margin
这种方式比较好理解,兼容性也很好,缺点是需要知道子元素的宽高
复制代码12345
absolute + auto margin
这种方法兼容性也很好,缺点是需要知道子元素的宽高
复制代码
absolute + calc
这种方法的兼容性依赖于 calc,且也需要知道宽高
复制代码
absolute + transform
兼容性依赖 translate,不需要知道子元素宽高
复制代码
table
css新增的table属性,可以让我们把普通元素,变为table元素的显示效果,通过这个特性也可以实现水平垂直居中。
这种方法兼容性也不错。
复制代码
flex
flex 实现起来比较简单,三行代码即可搞定。可通过父元素指定子元素的对齐方式,也可通过 子元素自己指定自己的对齐方式来实现。第二种方式见 grid 布局。
复制代码
grid
grid 布局也很强大,大体上属性跟 flex 差不多。
//方法一:父元素指定子元素的对齐方式 //方法二:子元素自己指定自己的对齐方式 复制代码
页面布局小结:
-
语义化掌握到位
-
页面布局理解深刻
-
CSS基础知识扎实
-
思维灵活且积极上进
-
代码书写规范
二、CSS盒模型
CSS盒模型是前端的基石,这个问题由浅入深,由易到难,可以依次问出下面几个问题
-
基本概念:标准模型 + IE模型
-
标准模型 和 IE模型的区别
-
CSS如何设置这两种模型
-
JS如何设置和获取盒模型对应的宽和高
-
实例题(根据盒模型解释边距重叠)
-
BFC(边距重叠解决方案)
1、基本概念
所有HTML元素可以看作盒子,在CSS中,"box model"这一术语是用来设计和布局时使用。
CSS盒模型本质上是一个盒子,封装周围的HTML元素,它包括:边距,边框,填充,和实际内容。
盒模型允许我们在其它元素和周围元素边框之间的空间放置元素。
下面的图片说明了盒子模型(Box Model):

2、标准模型与IE模型的区别
标准模型与 IE 模型的区别在于宽高的计算方式不同。
标准模型计算元素的宽高只算 content 的宽高,IE模型是 content + padding + border 的总尺寸。
假如 content 宽高是 100100px,padding 为 10px,border为 10px,margin为10px,那么在标准模型下,这个元素的宽为 100px,高为 100px。 IE模型下,宽为 100px + 2 10px(左右padding) + 210px(左右border) = 140px; 高为 100px + 2 10px(上下padding) + 2*10px(上下border) = 140px;


3、如何设置这两种模型
//设置标准模型 box-sizing: content-box; //设置IE模型 box-sizing: border-box; 复制代码
box-sizing 的默认值是 content-box,即默认标准模型。
4、JS如何设置盒模型的宽和高
假设已经获取的节点为 dom
//只能获取内联样式设置的宽高 dom.style.width/height //获取渲染后即时运行的宽高,值是准确的。但只支持 IE dom.currentStyle.width/height //获取渲染后即时运行的宽高,值是准确的。兼容性更好 window.getComputedStyle(dom).width/height; //获取渲染后即时运行的宽高,值是准确的。兼容性也很好,一般用来获取元素的绝对位置,getBoundingClientRect()会得到4个值:left, top, width, height dom.getBoundingClientRect().width/height; 复制代码
5、BFC
什么是 BFC?Block Formatting Context(块级格式化上下文)。
在解释什么是BFC之前,我们需要先知道Box、Formatting Context的概念。
Box:css布局的基本单位
Box 是 CSS 布局的对象和基本单位, 直观点来说,就是一个页面是由很多个 Box 组成的。元素的类型和 display 属性,决定了这个 Box 的类型。 不同类型的 Box, 会参与不同的 Formatting Context(一个决定如何渲染文档的容器),因此Box内的元素会以不同的方式渲染。让我们看看有哪些盒子:
-
block-level box: display 属性为 block, list-item, table 的元素,会生成 block-level box。并且参与 block fomatting context;
-
inline-level box: display 属性为 inline, inline-block, inline-table 的元素,会生成 inline-level box。并且参与 inline formatting context;
-
run-in box: css3 中才有, 这儿先不讲了。
Formatting Context
Formatting context 是 W3C CSS2.1 规范中的一个概念。它是页面中的一块渲染区域,并且有一套渲染规则,它决定了其子元素将如何定位,以及和其他元素的关系和相互作用。最常见的 Formatting context 有 Block fomatting context (简称BFC)和 Inline formatting context (简称IFC)。
BFC的布局规则
-
内部的Box会在垂直方向,一个接一个地放置。
-
Box垂直方向的距离由margin决定。属于同一个BFC的两个相邻Box的margin会发生重叠。
-
每个盒子(块盒与行盒)的margin box的左边,与包含块border box的左边相接触(对于从左往右的格式化,否则相反)。即使存在浮动也是如此。
-
BFC的区域不会与float box重叠。
-
BFC就是页面上的一个隔离的独立容器,容器里面的子元素不会影响到外面的元素。反之也如此。
-
计算BFC的高度时,浮动元素也参与计算。
如何创建BFC
-
float的值不是none。
-
position的值不是static或者relative。
-
overflow的值不是visible。
-
display的值是inline-block、table-cell、flex、table-caption或者inline-flex。
BFC的作用
-
利用BFC避免margin重叠
-
自适应两栏布局
-
清除浮动
三、DOM事件
3.1 事件级别
三个事件级别,注意没有 DOM1,因为 DOM1 标准制定的时候没有涉及 DOM事件。DOM3 比 DOM2 只是增加了一些事件类型。
-
DOM0:element.onclick = function(){}
-
DOM2:element.addEventListener('click', function(){}, false)
-
DOM3:element.addEventListener('keyup', function(){}, false)
### 3.2 事件模型和事件流 DOM事件模型包括捕获和冒泡。
事件流即用户与界面交互的过程中,事件的流向过程。
3.3 DOM事件捕获的具体流程
捕获的流程为:window -> document -> html -> body -> ... -> 目标元素。
冒泡的流程为:目标元素 -> ... -> body -> html -> document -> window。
3.4 Event 对象常见应用
-
event. preventDefault()
取消事件的默认动作。
-
event.stopPropagation()
阻止事件冒泡。
-
event.stopImmediatePropagation()
阻止剩下的事件处理程序被执行。如果一个元素上绑定了三个事件,在其中一个事件上调用了这个方法,那其他 的两个事件将不会被执行。
3.5 事件捕获流程和自定义事件示例
dom事件 点我啊点我啊复制代码
控制台打印的结果为:
window capture document capture html capture body capture eve capture 复制代码
证明了事件捕获的流程为:window -> document -> html -> body -> ... -> 目标元素。
自定义事件设定了 3秒后触发,刷新页面,3秒后控制台打印出 自定义事件 test 触发 。
四、HTTP协议
4.1 http协议的主要特点
简单快速、灵活、无连接、无状态
HTTP三点注意事项:
-
HTTP是无连接:无连接的含义是限制每次连接只处理一个请求。服务器处理完客户的请求,并收到客户的应答后,即断开连接。采用这种方式可以节省传输时间。
-
HTTP是媒体独立的:这意味着,只要客户端和服务器知道如何处理的数据内容,任何类型的数据都可以通过HTTP发送。客户端以及服务器指定使用适合的MIME-type内容类型。
-
HTTP是无状态:HTTP协议是无状态协议。无状态是指协议对于事务处理没有记忆能力。缺少状态意味着如果后续处理需要前面的信息,则它必须重传,这样可能导致每次连接传送的数据量增大。另一方面,在服务器不需要先前信息时它的应答就较快。
4.2 请求报文
一个HTTP请求报文由请求行(request line)、请求头(header)、空行和请求数据4个部分组成,下图给出了请求报文的一般格式。
-
请求行 :包括请求方法字段、URL字段和HTTP协议版本,如:GET /index.html HTTP/1.1。
-
请求头
请求头部由关键字/值对组成,每行一对,关键字和值用英文冒号“:”分隔。请求头部通知服务器有关于客户端请求的信息,典型的请求头有:
-
User-Agent:产生请求的浏览器类型。
-
Accept:客户端可识别的内容类型列表。
-
Host:请求的主机名,允许多个域名同处一个IP地址,即虚拟主机。
-
Content-Type:请求体的MIME类型 (用于POST和PUT请求中)。如:Content-Type: application/x-www-form-urlencoded
-
空行
最后一个请求头之后是一个空行,发送回车符和换行符,通知服务器以下不再有请求头。
-
请求数据
请求数据不在GET方法中使用,而是在POST方法中使用。POST方法适用于需要客户填写表单的场合。与请求数据相关的最常使用的请求头是Content-Type和Content-Length。
4.3 响应报文
包括:状态行、响应头、空行、响应正文。
4.4 HTTP 状态码
HTTP状态码的英文为HTTP Status Code。状态代码由三位数字组成,第一个数字定义了响应的类别,且有五种可能取值。
-
1xx:指示信息--表示请求已接收,继续处理。
-
2xx:成功--表示请求已被成功接收、理解、接受。
-
3xx:重定向--要完成请求必须进行更进一步的操作。
-
4xx:客户端错误--请求有语法错误或请求无法实现。
-
5xx:服务器端错误--服务器未能实现合法的请求。
常见状态代码、状态描述的说明如下。
-
200 OK:客户端请求成功。
-
400 Bad Request:客户端请求有语法错误,不能被服务器所理解。
-
401 Unauthorized:请求未经授权,这个状态代码必须和WWW-Authenticate报头域一起使用。
-
403 Forbidden:服务器收到请求,但是拒绝提供服务。
-
404 Not Found:请求资源不存在,举个例子:输入了错误的URL。
-
500 Internal Server Error:服务器发生不可预期的错误。
-
503 Server Unavailable:服务器当前不能处理客户端的请求,一段时间后可能恢复正常,举个例子:HTTP/1.1 200 OK(CRLF)。
4.5 优化
DNS 预解析
复制代码
HTTP预连接
复制代码
4.6 浏览器输入 url 之后发生了什么
网上有很多答案,也没有一个统一的标准答案,多看几个把大概流程说出来即可。
五、原型链
5.1 创建对象的几种方法
原型链 复制代码
然后在控制台查看各对象的值
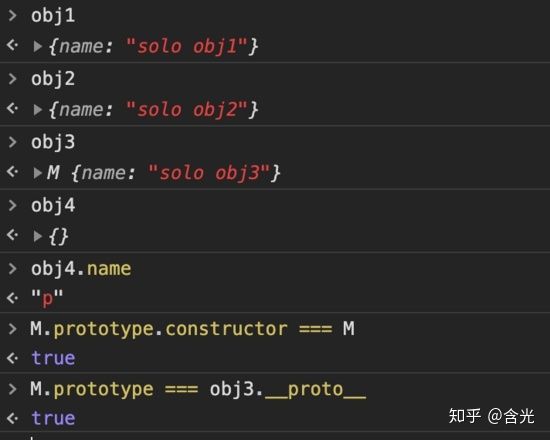
5.2 原型、构造函数、实例、原型链
构造函数、原型对象、实例的关系可以参照下图:

结合上一节控制台的打印值,可以得出结论:
-
构造函数.prototype.constructor === 构造函数
M.prototype.constructor === M 的结果为 true
-
构造函数.prototype === 实例对象. proto
M.prototype === obj3._ proto _ 的结果为 true
5.3 instanceof 的原理
instanceof 用于判断一个引用类型是否属于某构造函数;还可以在继承关系中用来判断一个实例是否属于它的父类型。
instanceof 的原理是判断实例对象的 __proto__ 是否与构造函数的 prototype 指向同一个引用。
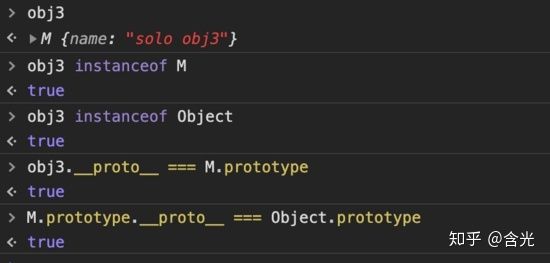
只要在实例对象的原型链上的构造函数,instaceof 都会返回 true。看下图:
obj3 是 M 的实例,所以 obj3 instanceof M = true ;
同时 obj3 instanceof Object
的结果也是 true,因为
obj3.__proto__ === M.prototype true M.prototype.__proto__ === Object.prototype true 复制代码
如果想准确的判断构造函数究竟是哪个,可以用 constructor
obj3.__proto__.constructor === M true obj3.__proto__.constructor === Object false 复制代码
5.4 instanceof 和 typeof 的区别
typeof 对于基本数据类型(null, undefined, string, number, boolean, symbol),除了 null 都会返回正确的类型。null 会返回 object。
typeof 对于对象类型,除了函数会返回 function,其他的都返回 object。
如果我们想获得一个变量的正确类型,可以通过 Object.prototype.toString.call(xx) 。这样我们就可以获得类似 [object Type] 的字符串。
判断是否等于 undefined 的方法:
let a // 我们也可以这样判断 undefined a === undefined // 但是 undefined 不是保留字,能够在低版本浏览器被赋值 let undefined = 1 // 这样判断就会出错 // 所以可以用下面的方式来判断,并且代码量更少 // 因为 void 后面随便跟上一个组成表达式 // 返回就是 undefined a === void 0 复制代码
5.5 new运算符
用代码实现一个 new 方法
模拟new的过程 复制代码
如何理解 [].shift.call(arguments)
因为 shift 内部实现是使用的this代表调用对象。那么当[].shift.call() 传入 arguments对象的时候,通过 call函数改变原来 shift 方法的 this 指向, 使其指向 arguments,并对 arguments 进行复制操作,而后返回一个新数组。至此便是完成了 arguments 类数组转为数组的目的!
其实这可以理解为,让类数组调用数组的方法!
六、面向对象
6.1 类的声明和实例化
声明类有两种方法:
function Animal(name){
this.name = name;
}
class Animal2 {
constructor(name){
this.name = name;
}
}
复制代码
类的实例化只有一种方式
var a1 = new Animal('shape');
var a2 = new Animal2('cat');
复制代码
6.2 继承
继承有多种实现方式
6.2.1 借助构造函数实现继承
先看代码,Parent1 是父类,Child1 是子类。通过 Parent1.call(this, name) 改变了 this 指向,使子类继承了父类的属性,即 Child1 也有了 name 属性。
/*
构造函数实现继承
*/
function Parent1(name){
this.name = name;
}
function Child1(name, age){
Parent1.call(this, name)
this.age = age
}
var c1 = new Child1('bobo', 19)
console.log(c1)
复制代码
运行程序,打印结果

但是, 这种方式不能继承父类原型链上的属性,只能继承在父类显式声明的属性 。
看下面的代码,通过Parent1.prototype.say
给 Parent1 新增一个 say 方法,那么 Child1 能不能也继承呢?
function Parent1(name){
this.name = name;
}
Parent1.prototype.say = function(){
console.log('say hello')
}
function Child1(name, age){
Parent1.call(this, name)
this.age = age
}
var p1 = new Parent1('hehe')
var c1 = new Child1('bobo', 19)
console.log(p1)
console.log(c1)
复制代码
输出结果如下:
Parent1 中有 say 方法,而 Child1 中没有,说明没有继承到。

6.2.2 借助原型链实现继承
实现原理是将 Child.prototype 赋值为一个新的 Parent 对象,即 Child2.prototype = new Parent2('bob')
function Parent2(name){
this.name = name;
this.arr = [1,2,3]
}
function Child2(age){
this.age = age
}
//重点在这句
Child2.prototype = new Parent2('bob')
c2 = new Child2(20)
c3 = new Child2(22)
console.log('c2', c2)
console.log('c3', c3)
复制代码
控制台输出如下:
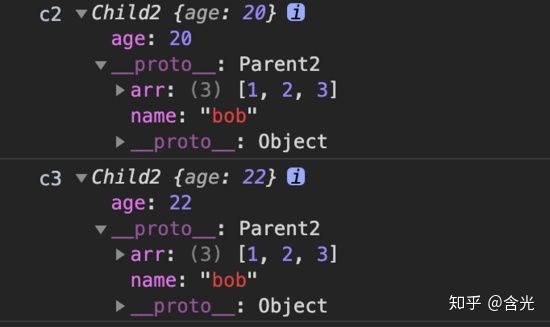
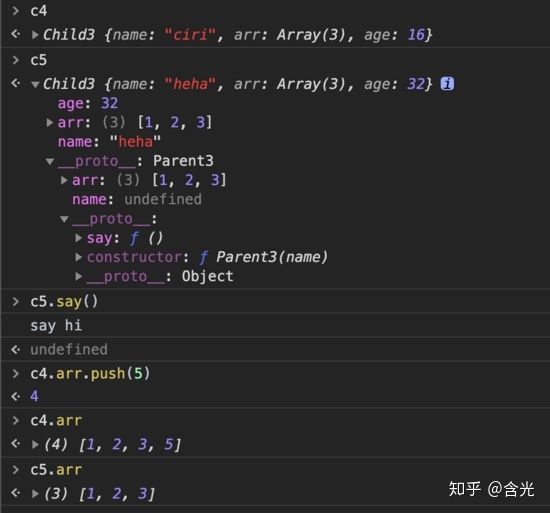
这种方法也有缺点,看 arr 属性是一个数组,如果创建两个实例对象 c2、c3,因为这两个实例对象的 arr 指向同一个引用,所以改变其中一个的值,另一个也会跟着改变。
我们来看下面的实验:c2.arr 和 c3.arr 值都是 [1,2,3],此时通过 c2.arr.push(4) 给 c2.arr 添加一个元素,c2.arr 变成了 [1,2,3,4],这没有问题。但再看 c3.arr ,也是 [1,2,3,4],这就有问题了,不是我们期望的。

6.2.3 组合方式实现继承
以上两种方式单独使用都有一定局限性,把两种方式结合起来是不是完美了呢?
/**
* 组合模式
*/
function Parent3(name){
this.name = name;
this.arr = [1,2,3]
}
function Child3(name, age){
Parent3.call(this, name)
this.age = age
}
Child3.prototype = new Parent3()
Parent4.prototype.say = function(){
console.log('say hi')
}
var c4 = new Child3('ciri', 16)
var c5 = new Child3('heha', 32)
复制代码
再在控制台做实验,通过结果可以看到,子类 Child3 继承了父类原型链上的属性,一个实例改变 arr 的值,不会影响到另一个。解决了前两种的缺陷。
但是, 在实例化 Child3 的时候,父类 Parent3 的构造函数被执行了两遍,这是没必要的。
为什么执行了两遍父类构造函数?因为 new Child3('ciri', 16) 的时候,子类构造函数中 Parent3.call(this, name) 执行了一次父类构造函数,然后 Child3.prototype = new Parent3() 又有一个 new Parent() ,第二次执行了父类构造函数。
所以还可以再优化。
6.2.4 组合方式优化1
上面说到了执行了两次父类构造函数,其中第二次是 Child3.prototype = new Parent3() ,那么把 new Parent3() 换掉不就可以了?是的!根据上一章原型链的知识,可以替换为 Child3.prototype = Parent3.prototype
//组合方式优化1
function Parent4(name){
this.name = name;
this.arr = [1,2,3]
}
function Child4(name, age){
//重点1
Parent4.call(this, name)
this.age = age
}
//重点2
Child4.prototype = Parent4.prototype
Parent4.prototype.say = function(){
console.log('say hi')
}
var c6 = new Child4('ciri', 16)
var c7 = new Child4('heha', 32)
console.log(c6 instanceof Child4, c6 instanceof Parent4)
console.log(c6.constructor)
复制代码
以上就是组合方式优化1,解决了执行两遍父类构造函数的问题。
这种方式就完美了吗?NO!
看最后打印的两行, c6 instanceof Child4 和 c6 instanceof Parent4 都为 true,这没问题。
但是 c6.constructor 是谁呢?正常来说应该是 Child4,那么看一下打印结果却是 Parent4。
**

为什么有这种现象呢?再看一下这张图
Parent4.prototype.constructor 其实是指向了 Parent4 自己,因为 Child4.prototype = Parent4.prototype ,共用了一个原型对象,所以 Child4.prototype.constructor 当然也是 Parent4 了。
那用 6.2.3 中 Child3.prototype = new Parent3() 这种方式有没有这个问题呢?一样的,因为 Child3 没有 constructor,它的 constructor 是从 new Parent3() 继承的,所以也是 Parent3。
6.2.5 组合方式优化2
直接看最完美的继承写法:
//组合方式优化2
function Parent5(name){
this.name = name
}
function Child5(name, age){
Parent5.call(this, name)
this.age = age
}
Child5.prototype = Object.create(Parent5.prototype)
Child5.prototype.constructor = Child5
var c8 = new Child5()
console.log(c8 instanceof Child5, c8 instanceof Parent5)
console.log(c8.constructor)
复制代码
与上一种方法的区别是:
Child5.prototype = Object.create(Parent5.prototype) Child5.prototype.constructor = Child5 复制代码
** Object.create() **方法创建一个新对象,使用现有的对象来提供新创建的对象的proto。即返回一个带着指定的原型对象和属性的新对象。
Child5.prototype 和 Parent5.prototype 不再使用同一个引用,中间用一个新的对象隔离开了。
此时 Child5 还没有 constructor,所以要手动指定一个: Child5.prototype.constructor = Child5
至此,继承的完美解决方案诞生了。
那么可不可以在 6.2.4 中 Child4.prototype = Parent4.prototype 下面直接写个 Child4.prototype.constructor = Child4 呢?不可以,因为它们指向的是同一个对象,改变了 Child4 的 constructor,Parent4 的 constructor 也变成了 Child4。
七、通信类
7.1 同源策略及限制
同源策略限制了从同一个源加载的文档或脚本如何与来自另一个源的资源进行交互。这是一个用于隔离潜在恶意文件的重要安全机制。
协议、域名、端口只要有一个不一样,就是不同的源。
不同源的限制
-
Cookie、LocalStorage、IndexDB 无法获取
-
DOM 无法获取
-
Ajax 请求不能发送(Ajax 只限于同源使用,不能跨域使用)
7.2 前后端如何通信
-
Ajax
-
WebSocket
-
CORS
7.3 跨域通信的几种方式
-
JSONP(利用 script 标签的异步加载实现的)
-
Hash(window.location.hash + iframe)
-
postMessage (H5中新增的)
-
WebSocket
-
CORS
参考文章: *segmentfault.com/a/119000001…*
八、安全类
前端安全分两类:CSRF、XSS
常考点:基本概念和缩写、攻击原理、防御措施
8.1 CSRF
CSRF(Cross-site request forgery)跨站请求伪造。
攻击原理
-
用户C打开浏览器,访问受信任网站A,输入用户名和密码请求登录网站A;
-
在用户信息通过验证后,网站A产生Cookie信息并返回给浏览器,此时用户登录网站A成功,可以正常发送请求到网站A;
-
用户未退出网站A之前,在同一浏览器中,打开一个TAB页访问网站B;
-
网站B接收到用户请求后,返回一些攻击性代码,并发出一个请求要求访问第三方站点A;
-
浏览器在接收到这些攻击性代码后,根据网站B的请求,在用户不知情的情况下携带Cookie信息,向网站A发出请求。网站A并不知道该请求其实是由B发起的,所以会根据用户C的Cookie信息以C的权限处理该请求,导致来自网站B的恶意代码被执行。
防御措施
-
Token验证
-
Referer 验证(简单易行,但 referer 可能被改变)
-
隐藏令牌(跟 Token验证差不多,把令牌存到 header 中)
8.2 XSS
XSS(cross-site scripting)跨域脚本攻击
攻击原理
往 Web 页面里插入恶意Script代码
防御措施
-
HTML:对以下这些字符进行转义:
&:& <:&alt; >:> ':' ":" /:/ 复制代码
-
Javascript:把所有非字母、数字的字符都转义成小于256的ASCII字符;
-
URL:使用Javascript的encodeURIComponent()方法对用户的输入进行编码,该方法会编码如下字符:, / ? : @ & = + $ #
九、算法
算法前端问的不太多,建议先复习其他的,有精力了再复习算法。
排序
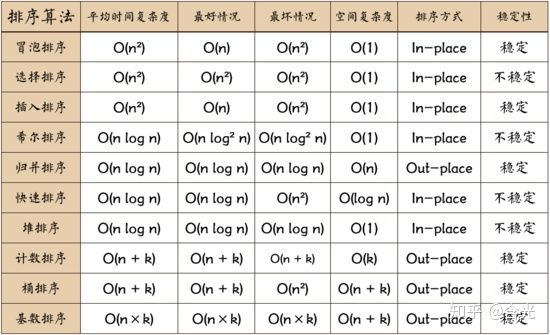
排序算法比较多,重点掌握:快速排序、选择排序、希尔排序、冒泡排序这四种即可。
术语:
稳定 :如果a原本在b前面,而a=b,排序之后a仍然在b的前面; 不稳定 :如果a原本在b的前面,而a=b,排序之后a可能会出现在b的后面; 内排序 :所有排序操作都在内存中完成; 外排序 :由于数据太大,因此把数据放在磁盘中,而排序通过磁盘和内存的数据传输才能进行; 时间复杂度 : 一个算法执行所耗费的时间。 空间复杂度 :运行完一个程序所需内存的大小。
各种算法的时间复杂度:
冒泡排序
冒泡排序 是一种简单的排序算法。它重复地走访过要排序的数列,一次比较两个元素,如果它们的顺序错误就把它们交换过来。走访数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成。这个算法的名字由来是因为越小的元素会经由交换慢慢“浮”到数列的顶端。
时间复杂度:
-
最佳情况:T(n) = O(n)
-
最差情况:T(n) = O(n^2)
-
平均情况:T(n) = O(n^2)
//冒泡排序
function bubbleSort(arr){
if(!arr || arr.length === 0){
return;
}
for(let i=0; i
选择排序
选择排序(Selection-sort) 是一种简单直观的排序算法。它的工作原理:首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置,然后,再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。以此类推,直到所有元素均排序完毕。
时间复杂度:
-
最佳情况:T(n) = O(n^2)
-
最差情况:T(n) = O(n^2)
-
平均情况:T(n) = O(n^2)
function selectSort(arr){
if(!arr || arr.length === 0){
return arr;
}
for(let i=0; i
堆栈、队列、列表
待完善…
递归
待完善…
波兰式和逆波兰式
待完善…
十、渲染机制
10.1 DOCTYPE 及其作用
DTD (Document type definition,文档类型定义) 是一系列的语法规则,用来定义 XML 或 HTML 的文件类型。浏览器会使用它来判断文档类型,决定使用何种协议来解析,以及切换浏览器模式。
DOCTYPE 是用来声明文档类型和 DTD 规范的,一个主要的用途便是文件的合法性验证。如果文件代码不合法,那么浏览器解析时便会出一些差错。
注意: 声明不区分大小写。
HTML5
复制代码
HTML 4.01 Strict
这个 DTD 包含所有 HTML 元素和属性,但不包括表象或过时的元素(如 font )。框架集是不允许的。
复制代码
HTML 4.01 Transitional
这个 DTD 包含所有 HTML 元素和属性,包括表象或过时的元素(如 font )。框架集是不允许的。
复制代码
HTML 4.01 Frameset
这个 DTD 与 HTML 4.01 Transitional 相同,但是允许使用框架集内容。
复制代码
10.2 浏览器渲染过程
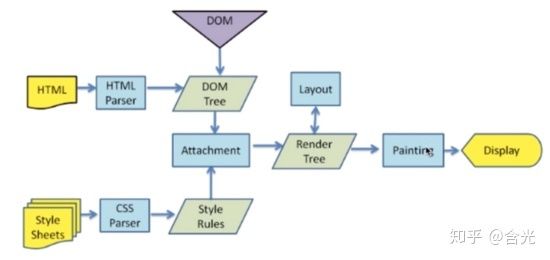
这个问题照着这张图讲清楚就好。
浏览器拿到 HTML 和 CSS 之后,通过 HTML Parser 把 HTML 解析成 DOM Tree , 通过 CSS Parser 把 CSS 解析成 Style Rules 即 CSS 规则,然后 DOM Tree 和 CSS规则 结合起来形成 Render Tree 。
然后进行布局 Layout 和绘制 Painting,最终 Display 显示在页面上。
10.3 重排 Reflow
定义
DOM 结构中各个元素都有自己的盒子(模型),这些都需要浏览器根据各种样式来计算并根据计算结果将元素放到它该出现的位置,这个过程称为 reflow。
触发 Reflow
什么情况会触发 Reflow 呢?(记住两三个就可以)
-
增加、删除、修改 DOM 节点时,会导致 Reflow 或 Repaint
-
移动 DOM 位置,或搞个动画时
-
修改 CSS 样式时
-
Resize 窗口(移动端没这个问题)或滚动的时候
-
修改网页默认字体时
10.4 重绘 Repaint
定义
当各种盒子的位置、大小以及其他属性,例如颜色、字体大小等都确定之后,浏览器把这些元素按照各自的特性绘制了一遍,于是页面内容出现了,这个过程称之为 repaint。
触发 Repaint
-
DOM 改动
-
CSS 改动
如何最小程度的 Repaint
比如要添加多个 DOM 节点,一次性添加,而不要一个个添加。
10.5 dispaly:none 和 visibility:hidden
dispaly:none 设置该属性后,该元素下的元素都会隐藏,占据的空间消失。
visibility:hidden 设置该元素后,元素虽然不可见了,但是依然占据空间的位置。
display:none和visibility:hidden的区别?
1.visibility具有继承性,其子元素也会继承此属性,若设置visibility:visible,则子元素会显示
2.visibility不会影响计数器的计算,虽然隐藏掉了,但是计数器依然继续运行着。
3.在css3的transition中支持visibility属性,但是不支持display,因为transition可以延迟执行,因此配合visibility使用纯css实现hover延时显示效果可以提高用户体验
\4. display:none会引起回流(重排)和重绘 visibility:hidden会引起重绘
十一、JS运行机制
掌握下面几个要点:
-
理解 JS 的单线程概念
-
理解任务队列
-
理解 EventLoop
-
理解哪些语句会放入异步任务队列
-
理解语句放入异步任务队列的时机
11.1 为什么 JavaScript 是单线程
JavaScript语言的一大特点就是单线程,也就是说,同一个时间只能做一件事。那么,为什么JavaScript不能有多个线程呢?这样能提高效率啊。
JavaScript的单线程,与它的用途有关。作为浏览器脚本语言,JavaScript的主要用途是与用户互动,以及操作DOM。这决定了它只能是单线程,否则会带来很复杂的同步问题。比如,假定JavaScript同时有两个线程,一个线程在某个DOM节点上添加内容,另一个线程删除了这个节点,这时浏览器应该以哪个线程为准?
所以,为了避免复杂性,从一诞生,JavaScript就是单线程,这已经成了这门语言的核心特征,将来也不会改变。
为了利用多核CPU的计算能力,HTML5提出Web Worker标准,允许JavaScript脚本创建多个线程,但是子线程完全受主线程控制,且不得操作DOM。所以,这个新标准并没有改变JavaScript单线程的本质。
11.2 任务队列
单线程就意味着,所有任务需要排队,前一个任务结束,才会执行后一个任务。如果前一个任务耗时很长,后一个任务就不得不一直等着。
所有任务可以分成两种,一种是 同步任务 (synchronous),另一种是 异步任务 (asynchronous)。同步任务指的是,在主线程上排队执行的任务,只有前一个任务执行完毕,才能执行后一个任务;异步任务指的是,不进入主线程、而进入"任务队列"(task queue)的任务,只有"任务队列"通知主线程,某个异步任务可以执行了,该任务才会进入主线程执行。
具体来说,异步执行的运行机制如下:(同步执行也是如此,因为它可以被视为没有异步任务的异步执行。)
(1)所有同步任务都在主线程上执行,形成一个执行栈(execution context stack)。
(2)主线程之外,还存在一个"任务队列"(task queue)。只要异步任务有了运行结果,就在"任务队列"之中放置一个事件。
(3)一旦"执行栈"中的所有同步任务执行完毕,系统就会读取"任务队列",看看里面有哪些事件。那些对应的异步任务,于是结束等待状态,进入执行栈,开始执行。
(4)主线程不断重复上面的第三步。
复制代码
只要主线程空了,就会去读取"任务队列",这就是JavaScript的运行机制。这个过程会不断重复。
11.3 宏任务 & 微任务
这里需要注意的是new Promise是会进入到主线程中立刻执行,而promise.then则属于微任务
-
宏任务(macro-task):整体代码script、setTimeOut、setInterval
-
微任务(mincro-task):promise.then、promise.nextTick(node)
11.4 EventLoop 事件循环
主线程从"任务队列"中读取事件,这个过程是循环不断的,所以整个的这种运行机制又称为Event Loop(事件循环)。

-
整体的script(作为第一个宏任务)开始执行的时候,会把所有代码分为两部分:“同步任务”、“异步任务”;
-
同步任务会直接进入主线程依次执行;
-
异步任务会再分为宏任务和微任务;
-
宏任务进入到Event Table中,并在里面注册回调函数,每当指定的事件完成时,Event Table会将这个函数移到Event Queue中;
-
微任务也会进入到另一个Event Table中,并在里面注册回调函数,每当指定的事件完成时,Event Table会将这个函数移到Event Queue中;
-
当主线程内的任务执行完毕,主线程为空时,会检查微任务的Event Queue,如果有任务,就全部执行,如果没有就执行下一个宏任务;
-
上述过程会不断重复,这就是Event Loop事件循环;
11.5 定时器
除了放置异步任务的事件,"任务队列"还可以放置定时事件,即指定某些代码在多少时间之后执行。这叫做"定时器"(timer)功能,也就是定时执行的代码。
定时器功能主要由setTimeout()和setInterval()这两个函数来完成,它们的内部运行机制完全一样,区别在于前者指定的代码是一次性执行,后者则为反复执行。以下主要讨论setTimeout()。
setTimeout()接受两个参数,第一个是回调函数,第二个是推迟执行的毫秒数。
console.log(1);
setTimeout(function(){console.log(2);},1000);
console.log(3);
复制代码
上面代码的执行结果是1,3,2,因为setTimeout()将第二行推迟到1000毫秒之后执行。
如果将setTimeout()的第二个参数设为0,就表示当前代码执行完(执行栈清空)以后,立即执行(0毫秒间隔)指定的回调函数。
setTimeout(function(){console.log(1);}, 0);
console.log(2);
复制代码
上面代码的执行结果总是2,1,因为只有在执行完第二行以后,系统才会去执行"任务队列"中的回调函数。
总之,setTimeout(fn,0)的含义是,指定某个任务在主线程最早可得的空闲时间执行,也就是说,尽可能早得执行。它在"任务队列"的尾部添加一个事件,因此要等到同步任务和"任务队列"现有的事件都处理完,才会得到执行。
HTML5标准规定了setTimeout()的第二个参数的最小值(最短间隔),不得低于 4毫秒 ,如果低于这个值,就会自动增加。在此之前,老版本的浏览器都将最短间隔设为10毫秒。另外,对于那些DOM的变动(尤其是涉及页面重新渲染的部分),通常不会立即执行,而是 每16毫秒执行一次 。这时使用requestAnimationFrame()的效果要好于setTimeout()。
需要注意的是,setTimeout()只是将事件插入了"任务队列",必须等到当前代码(执行栈)执行完,主线程才会去执行它指定的回调函数。要是当前代码耗时很长,有可能要等很久,所以并没有办法保证,回调函数一定会在setTimeout()指定的时间执行。
11.6 哪些是异步任务
-
setTimeout 和 setInterval
-
DOM 事件
-
Promise
-
网络请求
-
I/O
11.7 常考题
1) 第一题
下面代码的输出结果是什么?
console.log(1);
setTimeout(function(){
console.log(2)
}, 0);
console.log(3)
复制代码
答案:1,3,2
解析: console.log() 是同步任务, setTimeout 是异步任务。异步任务会等同步任务执行完再执行。虽然 setTimeout 设置的延迟是 0,但浏览器规定延迟最小为 4ms,所以 console.log(2) 在 4ms 后被放入任务队列。当同步任务执行完,即打印完 1,3 之后,主线程再从任务队列中取任务,打印 2。
2) 第二题
下面的代码输出结果是什么
console.log('A')
while(true){}
console.log('B')
复制代码
答案:A
解析:代码从上往下执行,先打印 A,然后 while 循环,因为条件一直是 true,所以会进入死循环。while 不执行完就不会执行到第三行。
这个题目还有个变种:
console.log('A');
setTimeout(function(){
console.log('B')
}, 0);
while(1){}
复制代码
同样只会输出 A。因为异步任务需要等同步任务执行完之后才执行,while 进入了死循环,所以不会打印 B。
3) 第三题
下面代码输出结果
for(var i=0; i<4; i++){
setTimeout(function(){
console.log(i)
}, 0)
}
复制代码
结果:4个4。
解析:这题主要考察异步任务放入任务队列的时机。当执行到 setTimeout 即定时器时,并不会马上把这个异步任务放入任务队列,而是等时间到了之后才放入。然后等执行栈中的同步任务执行完毕后,再从任务队列中依次取出任务执行。
for 循环是同步任务,会先执行完循环,此时 i 的值是 4。4ms后 console.log(i) 被依次放入任务队列,此时如果执行栈中没有同步任务了,就从任务队列中依次取出任务,所以打印出 4 个 4。
那么如何才能按照期望打印出 0, 1,2,3 呢?有三个方法:
//方法1:把 var 换成 let
for(let i=0; i<4; i++){
setTimeout(function(){
console.log(i)
}, 0)
}
//方法2:使用立即执行函数
for(let i=0; i<4; i++){
(function(i){
setTimeout(function(){
console.log(i)
}, 0)
})(i)
}
//方法3:加闭包
for(let i=0; i<4; i++){
var a = function(){
var j = i;
setTimeout(function(){
console.log(j)
}, 0)
}
a();
}
复制代码
4) 第四题
setTimeout(function(){
console.log(1)
});
new Promise(function(resolve){
console.log(2);
for(var i = 0; i < 10000; i++){
i == 9999 && resolve();
}
}).then(function(){
console.log(3)
});
console.log(4);
执行结果:
// 2, 4, 3, 1
复制代码
分析:
1.setTimeout是异步,且是宏函数,放到宏函数队列中;
2.new Promise是同步任务,直接执行,打印2,并执行for循环;
3.promise.then是微任务,放到微任务队列中;
4.console.log(4)同步任务,直接执行,打印4;
5.此时主线程任务执行完毕,检查微任务队列中,有promise.then,执行微任务,打印3;
6.微任务执行完毕,第一次循环结束;从宏任务队列中取出第一个宏任务到主线程执行,打印1;
7.结果:2,4,3,1
5) 第五题
console.log(1);
setTimeout(function() {
console.log(2);
}, 0);
Promise.resolve().then(function() {
console.log(3);
}).then(function() {
console.log('4.我是新增的微任务');
});
console.log(5);
执行结果:
// 1,5,3,4.我是新增的微任务,2
复制代码
分析:
1.console.log(1)是同步任务,直接执行,打印1;
2.setTimeout是异步,且是宏函数,放到宏函数队列中;
3.Promise.resolve().then是微任务,放到微任务队列中;
4.console.log(5)是同步任务,直接执行,打印5;
5.此时主线程任务执行完毕,检查微任务队列中,有Promise.resolve().then,执行微任务,打印3;
6.此时发现第二个.then任务,属于微任务,添加到微任务队列,并执行,打印4.我是新增的微任务;
7.这里强调一下,微任务执行过程中,发现新的微任务,会把这个新的微任务添加到队列中,微任务队列依次执行完毕后,才会执行下一个循环;
8.微任务执行完毕,第一次循环结束;取出宏任务队列中的第一个宏任务setTimeout到主线程执行,打印2;
9.结果:1,5,3,4.我是新增的微任务,2
6) 第六题
function add(x, y) {
console.log(1)
setTimeout(function() { // timer1
console.log(2)
}, 1000)
}
add();
setTimeout(function() { // timer2
console.log(3)
})
new Promise(function(resolve) {
console.log(4)
setTimeout(function() { // timer3
console.log(5)
}, 100)
for(var i = 0; i < 100; i++) {
i == 99 && resolve()
}
}).then(function() {
setTimeout(function() { // timer4
console.log(6)
}, 0)
console.log(7)
})
console.log(8)
执行结果
//1,4,8,7,3,6,5,2
复制代码
分析:
1.add()是同步任务,直接执行,打印1;
2.add()里面的setTimeout是异步任务且宏函数,记做timer1放到宏函数队列;
3.add()下面的setTimeout是异步任务且宏函数,记做timer2放到宏函数队列;
4.new Promise是同步任务,直接执行,打印4;
5.Promise里面的setTimeout是异步任务且宏函数,记做timer3放到宏函数队列;
6.Promise里面的for循环,同步任务,执行代码;
7.Promise.then是微任务,放到微任务队列;
8.console.log(8)是同步任务,直接执行,打印8;
9.此时主线程任务执行完毕,检查微任务队列中,有Promise.then,执行微任务,发现有setTimeout是异步任务且宏函数,记做timer4放到宏函数队列;
10.微任务队列中的console.log(7)是同步任务,直接执行,打印7;
11.微任务执行完毕,第一次循环结束;
12.检查宏任务Event Table,里面有timer1、timer2、timer3、timer4,四个定时器宏任务,按照定时器延迟时间得到可以执行的顺序,即Event Queue:timer2、timer4、timer3、timer1,取出排在第一个的timer2;
13.取出timer2执行,console.log(3)同步任务,直接执行,打印3;
14.没有微任务,第二次Event Loop结束;
15.取出timer4执行,console.log(6)同步任务,直接执行,打印6;
16.没有微任务,第三次Event Loop结束;
17.取出timer3执行,console.log(5)同步任务,直接执行,打印5;
18.没有微任务,第四次Event Loop结束;
19.取出timer1执行,console.log(2)同步任务,直接执行,打印2;
20.没有微任务,也没有宏任务,第五次Event Loop结束;
21.结果:1,4,8,7,3,6,5,2
7) 第七题
setTimeout(function() { // timer1
console.log(1);
setTimeout(function() { // timer3
console.log(2);
})
}, 0);
setTimeout(function() { // timer2
console.log(3);
}, 0);
执行结果
//1,3,2
复制代码
分析:
1.第一个setTimeout是异步任务且宏函数,记做timer1放到宏函数队列;
2.第三个setTimeout是异步任务且宏函数,记做timer2放到宏函数队列;
3.没有微任务,第一次Event Loop结束;
4.取出timer1,console.log(1)同步任务,直接执行,打印1;
5.timer1里面的setTimeout是异步任务且宏函数,记做timer3放到宏函数队列;
6.没有微任务,第二次Event Loop结束;
7.取出timer2,console.log(3)同步任务,直接执行,打印3;
8.没有微任务,第三次Event Loop结束;
9.取出timer3,console.log(2)同步任务,直接执行,打印2;
10.没有微任务,也没有宏任务,第四次Event Loop结束;
11.结果:1,3,2
十二、页面性能
面试必考,这五个最好都能记住。异步加载和浏览器缓存都会延伸了问,其他三个只要说出来即可。
提升页面性能的方法有哪些?
-
资源压缩合并,减少 HTTP 请求
-
非核心代码异步加载(异步加载的方式,异步加载的区别)
-
利用浏览器缓存(缓存的分类,缓存原理)
-
使用 CDN
-
预解析 DNS
//强制打开 标签的 dns 解析
//DNS预解析
复制代码
12.1 异步加载
异步加载的方式
-
动态脚本加载
-
defer
-
async
异步加载的区别
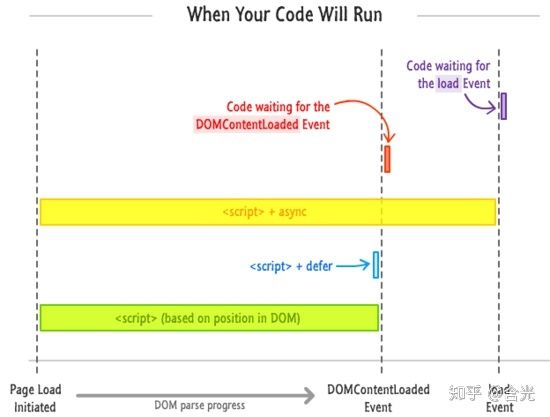
-
defer 是在 HTML 解析完之后才会执行,如果是多个,按照加载的顺序依次执行。 defer 脚本会在 DOMContentLoaded 和 load 事件之前执行。
-
async 是在脚本加载完之后立即执行,如果是多个,执行顺序和加载顺序无关。 async 会在 load 事件之前执行,但并不能确保与 DOMContentLoaded 的执行先后顺序。
下面两张图可以更清楚地阐述 defer 和 async 的执行以及和 DOMContentLoaded 、 load 事件的关系:

12.2 浏览器缓存
缓存策略的分类:
-
强缓存
-
协商缓存
缓存策略都是通过设置 HTTP Header 来实现的。
浏览器每次发起请求,都会先在浏览器缓存中查找该请求的结果以及缓存标识。
浏览器每次拿到返回的请求结果都会将该结果和缓存标识存入浏览器缓存中。
12.2.1 强缓存
强缓存:不会向服务器发送请求,直接从缓存中读取资源,在chrome控制台的Network选项中可以看到该请求返回200的状态码,并且Size显示from disk cache或from memory cache。强缓存可以通过设置两种 HTTP Header 实现:Expires 和 Cache-Control。
1. Expires
缓存过期时间,用来指定资源到期的时间,是服务器端的具体的时间点。也就是说,Expires=max-age + 请求时间,需要和Last-modified结合使用。Expires是Web服务器响应消息头字段,在响应http请求时告诉浏览器在过期时间前浏览器可以直接从浏览器缓存取数据,而无需再次请求。
Expires 是 HTTP/1 的产物,受限于本地时间,如果修改了本地时间,可能会造成缓存失效。 Expires: Wed, 22 Oct 2018 08:41:00 GMT 表示资源会在 Wed, 22 Oct 2018 08:41:00 GMT 后过期,需要再次请求。
2. Cache-Control
在HTTP/1.1中,Cache-Control是最重要的规则,主要用于控制网页缓存。比如当 Cache-Control:max-age=300 时,则代表在这个请求正确返回时间(浏览器也会记录下来)的5分钟内再次加载资源,就会命中强缓存。
Cache-Control 可以在请求头或者响应头中设置,并且可以组合使用多种指令:
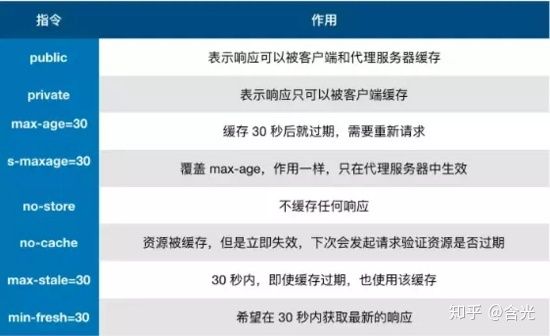
3. Expires和Cache-Control两者对比
其实这两者差别不大,区别就在于 Expires 是http1.0的产物,Cache-Control是http1.1的产物,两者同时存在的话,Cache-Control优先级高于Expires ;在某些不支持HTTP1.1的环境下,Expires就会发挥用处。所以Expires其实是过时的产物,现阶段它的存在只是一种兼容性的写法。
强缓存判断是否缓存的依据来自于是否超出某个时间或者某个时间段,而不关心服务器端文件是否已经更新,这可能会导致加载文件不是服务器端最新的内容,那我们如何获知服务器端内容是否已经发生了更新呢?此时我们需要用到协商缓存策略。
12.2.2 协商缓存
协商缓存就是强制缓存失效后,浏览器携带缓存标识向服务器发起请求,由服务器根据缓存标识决定是否使用缓存的过程,主要有以下两种情况:
-
协商缓存生效,返回304和Not Modified
-
协商缓存失效,返回200和请求结果
协商缓存可以通过设置两种 HTTP Header 实现:Last-Modified 和 ETag 。
1. Last-Modified 和 If-Modified-Since
浏览器在第一次访问资源时,服务器返回资源的同时,在response header中添加 Last-Modified 的header,值是这个资源在服务器上的最后修改时间,浏览器接收后缓存文件和 header;
Last-Modified: Fri, 22 Jul 2016 01:47:00 GMT
复制代码
浏览器下一次请求这个资源,浏览器检测到有 Last-Modified这个header,于是添加If-Modified-Since这个header,值就是Last-Modified中的值;服务器再次收到这个资源请求,会根据 If-Modified-Since 中的值与服务器中这个资源的最后修改时间对比,如果没有变化,返回304和空的响应体,直接从缓存读取,如果If-Modified-Since的时间小于服务器中这个资源的最后修改时间,说明文件有更新,于是返回新的资源文件和200。
但是 Last-Modified 存在一些弊端:
-
如果本地打开缓存文件,即使没有对文件进行修改,但还是会造成 Last-Modified 被修改,服务端不能命中缓存导致发送相同的资源
-
因为 Last-Modified 只能以秒计时,如果在不可感知的时间内修改完成文件,那么服务端会认为资源还是命中了,不会返回正确的资源
既然根据文件修改时间来决定是否缓存尚有不足,能否可以直接根据文件内容是否修改来决定缓存策略?所以在 HTTP / 1.1 出现了 ETag 和 If-None-Match
2. ETag 和 If-None-Match
Etag 是服务器响应请求时,返回当前资源文件的一个唯一标识(由服务器生成),只要资源有变化,Etag就会重新生成。浏览器在下一次加载资源向服务器发送请求时,会将上一次返回的Etag值放到request header里的If-None-Match里,服务器只需要比较客户端传来的If-None-Match跟自己服务器上该资源的ETag是否一致,就能很好地判断资源相对客户端而言是否被修改过了。如果服务器发现ETag匹配不上,那么直接以常规GET 200回包形式将新的资源(当然也包括了新的ETag)发给客户端;如果ETag是一致的,则直接返回304知会客户端直接使用本地缓存即可。
3. 两者之间对比:
-
首先在精确度上,Etag要优于Last-Modified。
Last-Modified的时间单位是秒,如果某个文件在1秒内改变了多次,那么他们的Last-Modified其实并没有体 现出来修改,但是Etag每次都会改变确保了精度;如果是负载均衡的服务器,各个服务器生成的Last- Modified也有可能不一致。
-
第二在性能上,Etag要逊于Last-Modified,毕竟Last-Modified只需要记录时间,而Etag需要服务器通过算法来计算出一个hash值。
-
第三在优先级上,服务器校验优先考虑Etag
12.2.3 缓存机制
强制缓存优先于协商缓存进行,若强制缓存(Expires和Cache-Control)生效则直接使用缓存,若不生效则进行协商缓存(Last-Modified / If-Modified-Since和Etag / If-None-Match),协商缓存由服务器决定是否使用缓存,若协商缓存失效,那么代表该请求的缓存失效,返回200,重新返回资源和缓存标识,再存入浏览器缓存中;生效则返回304,继续使用缓存。
12.2.4 强缓存与协商缓存的区别
强缓存与协商缓存的区别可以用下表来表示:
缓存类型获取资源形式状态码发送请求到服务器强缓存从缓存取200(from cache)否,直接从缓存取协商缓存从缓存取304(Not Modified)是,通过服务器来告知缓存是否可用
用户行为对缓存的影响
用户操作Expires/Cache-ControlLast-Modied/Etag地址栏回车有效有效页面链接跳转有效有效新开窗口有效有效前进回退有效有效F5刷新无效有效Ctrl+F5强制刷新无效无效
12.2.5 from memory cache 与 from disk cache对比
在chrome浏览器中的控制台Network中size栏通常会有三种状态
1.from memory cache
2.from disk cache
3.资源本身的大小(如:1.5k)
三种的区别:
-
from memory cache :字面理解是从内存中,其实也是字面的含义,这个资源是直接从内存中拿到的,不会请求服务器一般已经加载过该资源且缓存在了内存当中,当关闭该页面时,此资源就被内存释放掉了,再次重新打开相同页面时不会出现from memory cache的情况。
-
from disk cache :同上类似,此资源是从磁盘当中取出的,也是在已经在之前的某个时间加载过该资源,不会请求服务器但是此资源不会随着该页面的关闭而释放掉,因为是存在硬盘当中的,下次打开仍会from disk cache
-
资源本身大小数值 :当http状态为200是实实在在从浏览器获取的资源,当http状态为304时该数字是与服务端通信报文的大小,并不是该资源本身的大小,该资源是从本地获取的
状态类型说明200form memory cache不请求网络资源,资源在内存当中,一般脚本、字体、图片会存在内存当中。200form disk ceche不请求网络资源,在磁盘当中,一般非脚本会存在内存当中,如css等。200资源大小数值资源大小数值 从服务器下载最新资源。304报文大小请求服务端发现资源没有更新,使用本地资源,即命中协商缓存。
十三、错误监控
13.1 前端错误分类
前端错误分为两大类:
-
即时运行错误(代码错误)
-
资源加载错误
13.2 错误的捕获方式
即时运行错误的捕获方式
-
try...catch
-
window.onerror
资源加载错误捕获:
-
object.onerror
-
performance.getEntries()
-
Error 事件捕获
window.onerror 只能捕获即时运行错误,不能捕获资源加载错误,因为资源加载错误不会冒泡。
资源加载错误可以通过捕获 Error 来拿到,代码演示:
错误监控
复制代码
#### 跨域的 js 运行错误可以捕获到吗?错误提示是什么,应该怎么处理 可以捕获到,错误如下:
如何处理?
-
在 script 标签上增加 crossorigin 属性(客户端做)
-
设置 js 资源响应头 Access-Control-Allow-Origin:*(服务端做)
### 13.3 上报错误的基本原理
-
采用 Ajax 通信的方式上报(基本没用)
-
利用 Image 对象上报(基本都用这种方式)
复制代码
十四、this,call,apply,bind
14.1 call 和 apply 共同点
-
都能够改变函数执行时的上下文,将一个对象的方法交给另一个对象来执行,并且是立即执行的。
-
调用 call 和 apply 的对象,必须是一个函数 Function
14.2 call 和 apply 的区别
区别主要体现在参数上。
call 的写法:
Function.call(obj,[param1[,param2[,…[,paramN]]]])
复制代码
-
调用 call 的对象,必须是个函数 Function。
-
call 的第一个参数,是一个对象。 Function 的调用者,将会指向这个对象。如果不传,则默认为全局对象 window。
-
第二个参数开始,可以接收任意个参数。每个参数会映射到相应位置的 Function 的参数上。但是如果将所有的参数作为数组传入,它们会作为一个整体映射到 Function 对应的第一个参数上,之后参数都为空。
function func (a,b,c) {}
func.call(obj, 1,2,3)
// func 接收到的参数实际上是 1,2,3
func.call(obj, [1,2,3])
// func 接收到的参数实际上是 [1,2,3],undefined,undefined
复制代码
apply 的写法
Function.apply(obj[,argArray])
复制代码
-
它的调用者必须是函数 Function,并且只接收两个参数,第一个参数的规则与 call 一致。
-
第二个参数,必须是数组或者类数组,它们会被转换成类数组,传入 Function 中,并且会被映射到 Function 对应的参数上。这也是 call 和 apply 之间,很重要的一个区别。
func.apply(obj, [1,2,3])
// func 接收到的参数实际上是 1,2,3
func.apply(obj, {
0: 1,
1: 2,
2: 3,
length: 3
})
// func 接收到的参数实际上是 1,2,3
复制代码
14.3 call 和 apply 的用途
下面会分别列举 call 和 apply 的一些使用场景。声明:例子中没有哪个场景是必须用 call 或者必须用 apply 的,只是个人习惯这么用而已。
call 的使用场景
1、对象的继承。如下面这个例子:
function superClass () {
this.a = 1;
this.print = function () {
console.log(this.a);
}
}
function subClass () {
superClass.call(this);
this.print();
}
subClass();
// 1
复制代码
subClass 通过 call 方法,继承了 superClass 的 print 方法和 a 变量。此外,subClass 还可以扩展自己的其他方法。
2、借用方法。还记得刚才的类数组么?如果它想使用 Array 原型链上的方法,可以这样:
let domNodes = Array.prototype.slice.call(document.getElementsByTagName("*"));
复制代码
这样,domNodes 就可以应用 Array 下的所有方法了。
apply 的一些妙用
1、Math.max。用它来获取数组中最大的一项。
let max = Math.max.apply(null, array);
复制代码
同理,要获取数组中最小的一项,可以这样:
let min = Math.min.apply(null, array);
复制代码
2、实现两个数组合并。在 ES6 的扩展运算符出现之前,我们可以用 Array.prototype.push来实现。
let arr1 = [1, 2, 3];
let arr2 = [4, 5, 6];
Array.prototype.push.apply(arr1, arr2);
console.log(arr1); // [1, 2, 3, 4, 5, 6]
复制代码
14.4 bind 的使用
最后来说说 bind。在 MDN 上的解释是:bind() 方法创建一个新的函数,在调用时设置 this 关键字为提供的值。并在调用新函数时,将给定参数列表作为原函数的参数序列的前若干项。
它的语法如下:
Function.bind(thisArg[, arg1[, arg2[, ...]]])
复制代码
bind 方法 与 apply 和 call 比较类似,也能改变函数体内的 this 指向。不同的是, bind 方法的返回值是函数,并且需要稍后调用,才会执行 。而 apply 和 call 则是立即调用。
来看下面这个例子:
function add (a, b) {
return a + b;
}
function sub (a, b) {
return a - b;
}
add.bind(sub, 5, 3); // 这时,并不会返回 8
add.bind(sub, 5, 3)(); // 调用后,返回 8
复制代码
如果 bind 的第一个参数是 null 或者 undefined,this 就指向全局对象 window。
总结
call 和 apply 的主要作用,是改变对象的执行上下文,并且是立即执行的。它们在参数上的写法略有区别。
bind 也能改变对象的执行上下文,它与 call 和 apply 不同的是,返回值是一个函数,并且需要稍后再调用一下,才会执行。
十五、防抖节流
防抖:触发高频函数事件后,n秒内函数只能执行一次,如果在n秒内这个事件再次被触发的话,那么会重新计算时间。
节流:所谓节流,就是指连续触发事件但是在 n 秒中只执行一次函数。节流会稀释函数的执行频率
防抖节流2
复制代码