《数据库系统原理与设计》万常选著知识点整理
数据库系统原理与设计
1.1数据库系统
数据管理技术经历了人工管理、文件系统和数据库管理系统3个阶段。
1.人工管理的数据是面向应用程序的。
2.文件系统阶段已经有了操作系统,有专门的软件对数据进行统一管理。
3.数据库管理阶段有数据库管理系统(DBMS),数据库管理系统是由一个相互关联的数据的集合(称为数据库)和一组用以访问、管理和控制这些数据的程序组成。DBMS是位于用户与操作系统之间的一层数据管理系统,它提供一个可以方便且高效地存取、管理和控制数据库信息的环境。
DBMS的特点:
1.数据结构化。
2.数据的共享度高,冗余度低
3.数据独立性高。数据独立是指数据的使用(即应用程序)与数据的说明(即数据的组织结构和存储方式)分离,使应用程序只考虑如何使用数据

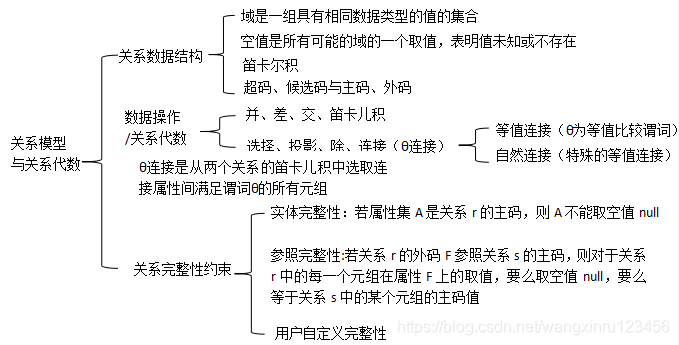
1.2数据模型是一个描述数据结构、数据操作和数据约束的概念及其符号表示系统。

关系数据模型的优缺点:
1.关系模型建立在严格的数学概念的基础之上
2.关系模型的概念单一,数据结构简单。
3.关系模型的存取路径对用户透明,从而具有更高的数据独立性、更好的安全保密性。
缺点:由于存取路径对用户透明,查询效率往往不如非关系数据模型。为了提高性能,DBMS必须对用户的查询请求进行优化,这样就增加了开发DBMS的难度。
1.3数据库三级模式结构及两层映像

1.模式(逻辑模式)对应于逻辑层数据抽象,是数据库中全体数据的逻辑结构和特征的描述。
2.外模式(子模式/用户模式)对应于视图层数据抽象,它是数据库用户(包括应用程序和最终用户)能够看见和使用的局部数据的逻辑结构和特征的描述。
3.内模式(存储模式)对应于物理层数据抽象,它是数据的物理结构和存储方式的描述,是数据在数据库内部的表示方式。
4.外模式/模式映像 保证了数据与应用程序的逻辑独立性(数据的逻辑独立性)。
5.模式/内模式映像:保证了数据与应用程序的物理独立性(数据的物理独立性)。
1.4数据库系统

第一章
数据库系统概论

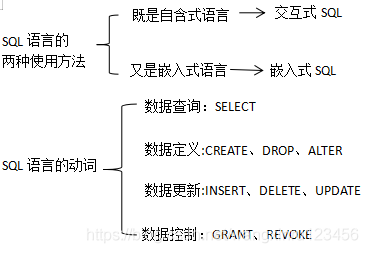
3 SQL语言
组成部分

SQL语言的
两种使用方法
SELECT [ALL|DISTINCT]<目标列表达式>[[AS]<别名>](DISTINT消除重复元组、AS给属性列取别名)
FROM
[WHERE<条件表达式>]
[GROUP BY<列名1>,<列名2>]分组聚合:GROUP BY 对查询结果按某一列或某几列进行分组,值相等的分为一组
[HAVING<条件表达式>]:HAVING分句对分组的结果进行选择,仅输出满足条件的组
[ORDER BY<列名表达式>[ASC|DESC]] 排序运算ASC升序,DESC降序
(WHERE条件表达式使用下列谓词运算符:
比较运算符:>,>=,<,<=,=,<>,!=; WHERE grade=2015
逻辑运算符:AND,OR,NOT; WHERE courseNo=’001’ OR courseNo=’005’ OR courseNo=’003’
范围运算符:[NOT]BETWEEN…AND; WHERE score BETWEEN 80 AND 90
集合运算符:[NOT]IN; WHERE courseNo IN(‘001’,’005’,’003’)
空值运算符:IS[NOT]null; WHERE priorCourse IS null
字符匹配运算符:[NOT]LIKE; WHERE className LIKE ‘%会计%’
存在量词运算符:[NOT]EXISTS;)
聚合查询:聚合函数

7.1数据定义语言

7.1.1数据库的定义
1.数据库的创建 CREATE DATABASE databaseName>
[ON [PRIMARY]
[FILEGROUP] ]
[LOG ON ]
2.数据库的修改 ALTER DATABASE
3.数据库的删除 DROP DATABASE databaseName>
7.1.2基本表的定义
1创建基本表
CREATE TABLE Course(
courseNo char(3) NOT NULL,
courseName varchar(30) UNIQUE NOT NULL,(UNIQUE建立唯一索引)
creditHour numeric(1) DEFAULT 0 NOT NULL,
courseHour tinyint DEFAULT 0 NOT NULL,
priorCourse char(3) NULL,
(建立命名的主码约束和匿名的外码约束)
CONSTRAINT CoursePK PRIMARY KEY (courseNo),(PRIMARY KEY:建立主码)
FOREING KEY (priorCourse) REFERENCES Course(courseNo)(FOREING KEY :建立外码)
)
2基本表的修改
增加列 ALTER TABLE tableName>
ADD columnName> dataType>
增加约束 ALTER TABLE tableName>
ADD CONSTRAINT constraintName>
删除约束 ALTER TABLE tableName>
DROP constraintName>
修改列的数据类型 ALETR TABLE tableName>
ALTER COLUMN columnName>newDataType>
3基本表的删除
DROP TABLE TempTable
7.3视图
7.3.1创建视图
CREATE VIEW viewName>[( columnName1>[, columnName2>…])]
AS subquery>
[WITH CHECK OPTION]
viewName>:新建视图的名称,该名称在一个数据库中必须唯一;
columnName1>[, columnName2>…]:视图中定义的列名。如果列名缺省不写,则视图的列名自动取subquery>语句查询出来的列名。如果存在下列3种情况之一,则必须写视图的列名:
① subquery>查询中的某个目标列是聚合函数或表达式
② subquery>查询中出现了多表连接中名称相同的列名;
③在视图中需要为某列取新的名称更合适。
AS subquery>:子查询,不允许含有ORDER BY子句和DISTINCT短语;
[WITH CHECK OPTION]:表示在对视图进行更新(插入、删除或修改)操作时必须进行合法性检查,只有当更新操作的结果满足创建视图中谓语条件(即 subquery>子查询的条件表达式)时,该更新操作才被允许。
7.3.2查询视图
7.3.3更新视图(插入、删除DELETE、修改UPDATE)
建立视图的作用不是利用视图来更新数据库的数据,而是简化用户的查询,因此尽量不要对视图执行更新操作。
7.3.4删除视图
DROP VIEW viewName>[CASCADE]:级联删除,把该视图和由它导出的所有视图一起删除
7.1.3索引的定义
1.索引的建立
CREATE [UNIQUE][CLUSTERED|NONCLUSTERED]
INDEX indexName>
ON tableName>(columnName1>[ASC|DEAC] )
ONfilegroupName>
UNIQUE:建立唯一索引
CLUSTERED|NONCLUSTERED:表示建立聚集或非聚集索引,默认为非聚集索引
tableName>(columnName1>[ASC|DEAC] ):指出为哪个基本表关于哪些属性建立索引,其中[ASC|DEAC]为按升序还是降序建立索引,默认为升序
ONfilegroupName>:指定索引存放在哪个逻辑设备(组)上
2.索引的删除
DROP INDEX indexName> ON tableName>
7.2SQL数据更新语言

7.2.1插入数据
插入一个元组
INSERT INTO Student VALUS
(‘1500006’,’李相东’,‘男’,‘1998-10-21 00:00’,‘云南’‘撒呢族’,‘CS1502’)
INSERT INTO Student(studentName,birthday,studentNo)
VALUES(‘张东立’,‘1999-12-10 00:00’,‘1500007’)
插入多个元组
INSERT INTO tableName [( columnName1 [,columnName2…])]
subquery
7.2.2删除数据
DELETE FROM tableName [WHERE predicate ]
7.2.3修改数据
UPDATE Score
SET score=88
WHERE courseNo=’002’ AND termNo=’151’ AND studentNo IN
(SELECT studentNo FROM Student WHERE studentName=’王红敏’)
也可以写成
UPDATE Score
SET score=88
FROM Score a,Student b
WHERE a.studentNo=b.studentNo
AND courseNo=’002’ AND termNo=’151’ AND studentName=’王红敏’
7.5游标
一个SQL语句原则上可产生或处理一组记录,而程序语言一次只能处理一个记录,为此必须协调两种处理方式,这是通过使用游标机制来解决的。
7.7触发器
触发器是一种特殊的存储过程,触发器的事件可以是插入INSERT、修改UPDATE或删除DELETE事件,也可以是这几个事件的组合。

第九章数据库安全性与完整性
权限的授予与收回
GRANT和REVOKE有两种权限:目标权限和命令权限
1)命令权限的授予与收回(DDL操作权限)
GRANT{all|command_list}TO{public|username_list}
REVOKE{all|command_list}FROM{public|username_list}
2)目标权限的授予与收回(DML操作权限)
GRANT{all|command_list}ON objectName>[(columnName_list>)]
TO{public|username_list}[WITH GRANT OPTION]
REVOKE{all|command_list}ON objectName>[(columnName_list>)]
FROM{public|username_list}[CASCADE|RESTRICT]
其中
CASCADE:级联收回
RESTRICT:默认值,若转赋了权限,则不能收回。
WITH GRANT OPTION:将指定对象上的目标权限授予其他安全账户的能力,但是不允许循环授权,即不允许将得到的权限授予祖先。
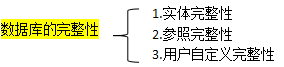
数据库的完整性
第4章数据库建模
数据库设计过程:
1.需求分析
2.概念设计 E-R模型建模方法
3.逻辑设计 将E-R模型转化为关系数据库模式
4.模式求精
5.物理设计 建立索引
6.应用与安全设计
ER模型向关系模型的转换应遵循如下原则:
①每个实体类型转换为一个关系模式。
②一个1:1的联系可转换为一个关系模式,或与任意一端的关系模式合并。若独立转换为一个关系模式,那么,两端关系的码及联系的属性为该关系的属性,且两端关系的码均可作为候选码;若与一端合并,那么将另一端的码及联系的属性合并到该端。
③一个1:n的联系可转换为一个关系模式,或与n端的关系模式合并,若独立转换为一个关系模式,那么,两端关系的码及联系的属性为关系的模式,而n端的码为关系的码。
④一个n:m的联系可转换为一个关系模式,那么,两端关系的码及联系的属性为关系的属性,而关系的码为两端实体的码的组合。
⑤三个或三个以上多对多的联系可转换为一个关系模式,那么,诸关系的码及联系的属性为关系的属性,而关系的码为各实体的码的组合。
⑥具有相同码的关系可以合并。
第5章关系数据理论与模式求精
5.1数据冗余导致的问题:①冗余存储②更新异常③插入异常④删除异常
5.2函数依赖定义1函数依赖

2平凡与非平凡函数依赖
非平凡函数依赖
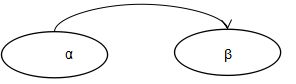
平凡函数依赖

3完全函数依赖和部分函数依赖

4传递函数依赖

5.3范式
第一范式1NF:关系模式r(R)的每个属性对应的域值都是不可再分的。
第二范式2NF:非主属性不允许依赖于部分的候选码属性
第三范式3NF:非主属性不能依赖于另一个(组)非主属性。3NF的放松之处在于允许存在主属性对候选码的传递依赖和部分依赖。3NF存在信息冗余和异常问题。3NF分解即使无损分解,又是保持依赖分解。
BCNF范式:①α->β是平凡函数依赖(即β⊆α)。
②α是r®的一个超码(即α中包含r®的候选码)
BCNF是基于函数依赖理论能够达到的最好关系模式。BCNF分解是无损分解,但不一定是保持依赖分解。
5.4函数依赖理论
左无关属性检测算法
右无关属性检测算法
无损连接分解:给定关系模式r(R),则将关系模式r®分解成r1(R1)和r2(R2)的分解是无损连接分解,当且仅当包含函数依赖R1ՈR2->R1或R1ՈR2->R2。
保持函数依赖:称具有函数依赖集F的关系模式r(R)的分解r1(R1),r2(R2),…rn(Rn)为保持函数分解,当且仅当
求最小函数依赖集:步骤:①用分解的法则,使F中的任何一个函数依赖的右部仅含有一个属性;
②去掉多余的函数依赖:从第一个函数依赖X->Y开始,将其从F中去掉,然后在剩下的函数依赖中求X的闭包,看是否包含Y,若是,则去掉X->Y,否则不能去掉,依次做下去。直到找不到冗余的函数依赖。
5.5模式分解算法
BCNF分解:可将r®分解为r1(R1)和r2(R2),其中R1=αβ,R2=R-(β-α)
3NF分解:1.计算:①合并函数依赖α->β1,α->β2合并为α->β1β2
②去除无关属性:左无关、右无关
2.分解关系r®
第8章数据库存储与查询处理
查询优化:“尽早执行选择操作”
“尽早执行投影操作”
“尽早执行选择运算”的规则优先于“尽早执行投影运算”的规则
第10章事务管理与恢复
10.1事务特性
①原子性:事务的所有操作要么全部都被执行,要么都不被执行
②一致性:将数据库从一个一致性状态转化为另一个一致性状态
③隔离性:并发执行的各个事务不能相互干扰
④永久性:一个事务成功提交后,它对数据库的改变必须是永久的,即使随后系统出现故障也不会受到影响。
事务开始:BEGIN TRANSACTION
事务结束:①事务提交:COMMIT TRANSACTION:将成功完成事务的执行结果(即更新)永久化,并释放事务占有的全部资源。
②事务回滚:ROLLBACK TRANSACTION:终止当前事务、撤销其对数
据库所做的更新,并释放事务占有的全部资源。
事务的并发执行可能出现以下3种不一致性。①读脏数据②不可重复读③丢失更新
10.2并发控制
基于封锁的并发控制方法:
①共享锁(S锁):如果事务T获得了数据对象Q的共享锁,则T可读但不能写Q.
②排它锁(X锁):如果事务T获得了数据对象Q上的排它锁,则T既可读Q又可写Q。
SL(Q)——申请数据对象Q上的共享锁;
XL(Q)——申请数据对象Q上的排他锁;
UL(Q)——释放数据对象Q上的锁。
10.3恢复与备份
事务故障:①输入数据的错误、②运算溢出、③违反某些完整性限制、某些应用程序的错误、并发事务发生死锁。
关于日志的故障恢复策略:数据库中的日志记录有两种类型:①记录数据更新操作的日志记录②记录事务操作的日志记录
1.UNDO操作:对于要UNDO的事务T,日志中记录有
2.对于要REDO的事务T,日志中已经记录了
并发执行事务的基本恢复过程包括3个阶段:
①分析阶段:从日志头开始顺向扫描日志,以确定重做事务集(REDO-set)和撤销事务集(UNDO-set)将既有
②撤销阶段:从日志尾反向扫描日志,对每一条属于UNDO-set中事务的更新操作日志依次执行UNDO操作。
③重做阶段:从日志头顺向扫描日志,对每一条属于REDO-set中事务的更新操作日志依次执行REDO操作。
检查点:
