Kafka由浅入深(4)生产者主线程工作原理(下)
一、生产者发送流程
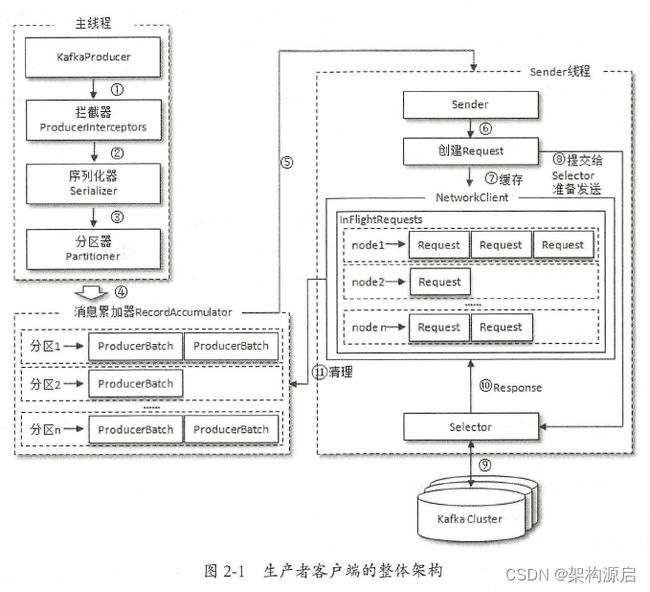
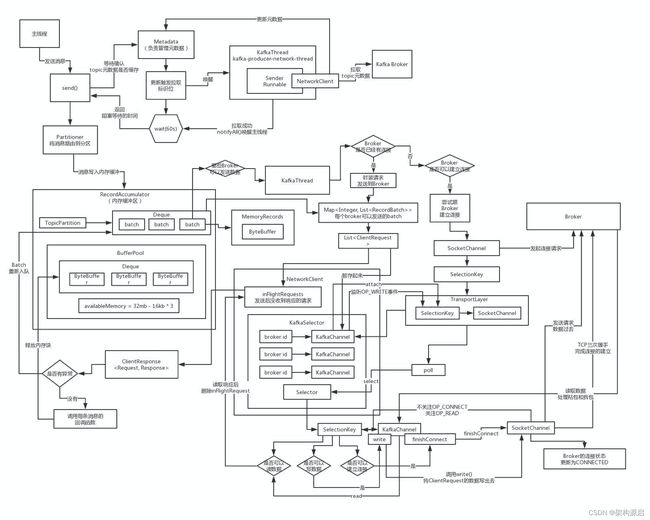
1.1、生产者的流程架构
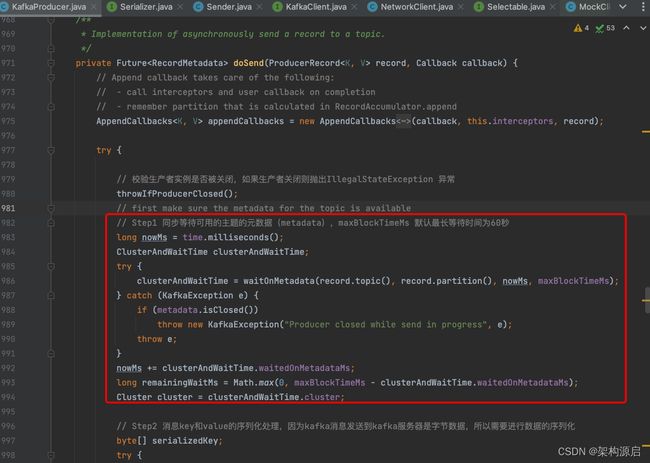
1.2 KafkaProducer doSend() 源码和解析:
public class KafkaProducer implements Producer {
@Override
private Future doSend(ProducerRecord record, Callback callback) {
// Append callback takes care of the following:
// - call interceptors and user callback on completion
// - remember partition that is calculated in RecordAccumulator.append
AppendCallbacks appendCallbacks = new AppendCallbacks(callback, this.interceptors, record);
try {
// 校验生产者实例是否被关闭,如果生产者关闭则抛出IllegalStateException 异常
throwIfProducerClosed();
// first make sure the metadata for the topic is available
// Step1 同步等待可用的主题的元数据(metadata),maxBlockTimeMs 默认最长等待时间为60秒
long nowMs = time.milliseconds();
ClusterAndWaitTime clusterAndWaitTime;
try {
clusterAndWaitTime = waitOnMetadata(record.topic(), record.partition(), nowMs, maxBlockTimeMs);
} catch (KafkaException e) {
if (metadata.isClosed())
throw new KafkaException("Producer closed while send in progress", e);
throw e;
}
nowMs += clusterAndWaitTime.waitedOnMetadataMs;
long remainingWaitMs = Math.max(0, maxBlockTimeMs - clusterAndWaitTime.waitedOnMetadataMs);
Cluster cluster = clusterAndWaitTime.cluster;
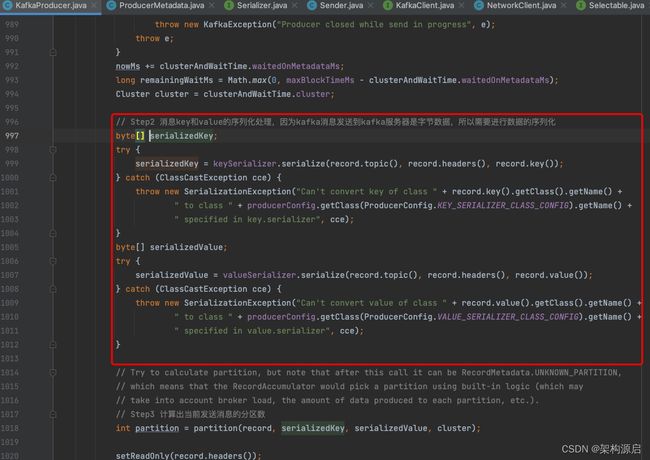
// Step2 消息key和value的序列化处理,因为kafka消息发送到kafka服务器是字节数据,所以需要进行数据的序列化
byte[] serializedKey;
try {
serializedKey = keySerializer.serialize(record.topic(), record.headers(), record.key());
} catch (ClassCastException cce) {
throw new SerializationException("Can't convert key of class " + record.key().getClass().getName() +
" to class " + producerConfig.getClass(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG).getName() +
" specified in key.serializer", cce);
}
byte[] serializedValue;
try {
serializedValue = valueSerializer.serialize(record.topic(), record.headers(), record.value());
} catch (ClassCastException cce) {
throw new SerializationException("Can't convert value of class " + record.value().getClass().getName() +
" to class " + producerConfig.getClass(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG).getName() +
" specified in value.serializer", cce);
}
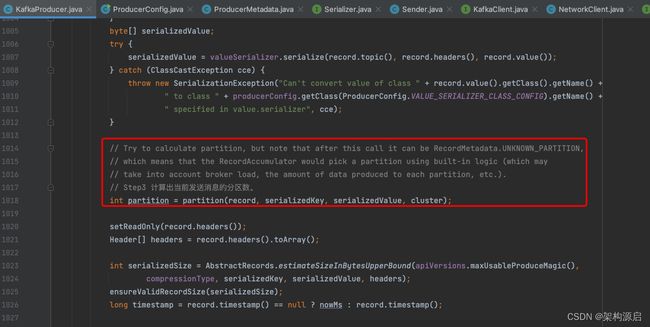
// Try to calculate partition, but note that after this call it can be RecordMetadata.UNKNOWN_PARTITION,
// which means that the RecordAccumulator would pick a partition using built-in logic (which may
// take into account broker load, the amount of data produced to each partition, etc.).
// Step3 计算出当前发送消息的分区数。
int partition = partition(record, serializedKey, serializedValue, cluster);
// 根据消息记录,设置消息的读写权限
setReadOnly(record.headers());
// 获取到记录请求头
Header[] headers = record.headers().toArray();
// Step4 获取给定字段的记录所需的批次大小的上限预估值
int serializedSize = AbstractRecords.estimateSizeInBytesUpperBound(apiVersions.maxUsableProduceMagic(),
compressionType, serializedKey, serializedValue, headers);
// 校验上限预估值是否过大
ensureValidRecordSize(serializedSize);
long timestamp = record.timestamp() == null ? nowMs : record.timestamp();
// onNewBatch()方法中在3.0.0版本被弃用,但是在自定义分区器中有可能会被使用
boolean abortOnNewBatch = partitioner != null;
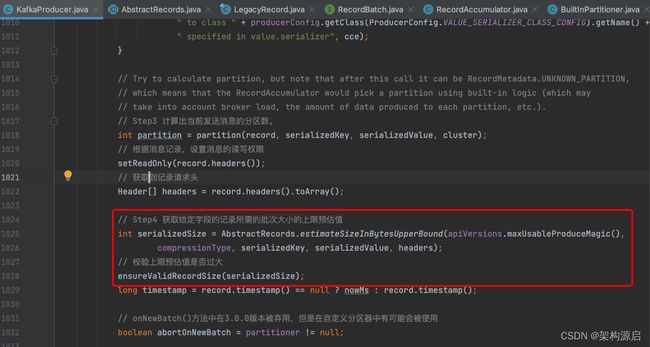
// Append the record to the accumulator. Note, that the actual partition may be
// calculated there and can be accessed via appendCallbacks.topicPartition.
// Step5 第一步添加消息记录到accumulator。最终获取到实际的分区是在这里的逻辑中实现
RecordAccumulator.RecordAppendResult result = accumulator.append(record.topic(), partition, timestamp, serializedKey,
serializedValue, headers, appendCallbacks, remainingWaitMs, abortOnNewBatch, nowMs, cluster);
assert appendCallbacks.getPartition() != RecordMetadata.UNKNOWN_PARTITION;
// 第一步添加accumulator,返回需要创建了一个新的批次,并添加到accumulator里面
if (result.abortForNewBatch) {
int prevPartition = partition;
onNewBatch(record.topic(), cluster, prevPartition);
partition = partition(record, serializedKey, serializedValue, cluster);
if (log.isTraceEnabled()) {
log.trace("Retrying append due to new batch creation for topic {} partition {}. The old partition was {}", record.topic(), partition, prevPartition);
}
result = accumulator.append(record.topic(), partition, timestamp, serializedKey,
serializedValue, headers, appendCallbacks, remainingWaitMs, false, nowMs, cluster);
}
// Add the partition to the transaction (if in progress) after it has been successfully
// appended to the accumulator. We cannot do it before because the partition may be
// unknown or the initially selected partition may be changed when the batch is closed
// (as indicated by `abortForNewBatch`). Note that the `Sender` will refuse to dequeue
// batches from the accumulator until they have been added to the transaction.
if (transactionManager != null) {
transactionManager.maybeAddPartition(appendCallbacks.topicPartition());
}
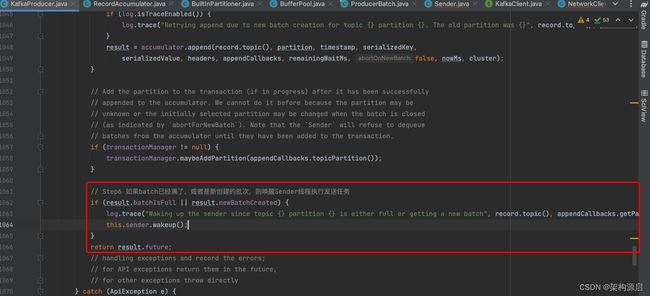
// Step6 如果batch已经满了,或者是新创建的批次,则唤醒Sender线程执行发送任务
if (result.batchIsFull || result.newBatchCreated) {
log.trace("Waking up the sender since topic {} partition {} is either full or getting a new batch", record.topic(), appendCallbacks.getPartition());
this.sender.wakeup();
}
return result.future;
// handling exceptions and record the errors;
// for API exceptions return them in the future,
// for other exceptions throw directly
} catch (ApiException e) {
log.debug("Exception occurred during message send:", e);
if (callback != null) {
TopicPartition tp = appendCallbacks.topicPartition();
RecordMetadata nullMetadata = new RecordMetadata(tp, -1, -1, RecordBatch.NO_TIMESTAMP, -1, -1);
callback.onCompletion(nullMetadata, e);
}
this.errors.record();
this.interceptors.onSendError(record, appendCallbacks.topicPartition(), e);
if (transactionManager != null) {
transactionManager.maybeTransitionToErrorState(e);
}
return new FutureFailure(e);
} catch (InterruptedException e) {
this.errors.record();
this.interceptors.onSendError(record, appendCallbacks.topicPartition(), e);
throw new InterruptException(e);
} catch (KafkaException e) {
this.errors.record();
this.interceptors.onSendError(record, appendCallbacks.topicPartition(), e);
throw e;
} catch (Exception e) {
// we notify interceptor about all exceptions, since onSend is called before anything else in this method
this.interceptors.onSendError(record, appendCallbacks.topicPartition(), e);
throw e;
}
}
1.3 doSend() 发送主体逻辑拆解
doSend() 的主体处理逻辑可以拆成这几步
Step1同步等待可用的主题的元数据(metadata),maxBlockTimeMs 默认最长等待时间为60秒Step2 消息key和value的序列化处理,因为kafka消息发送到kafka服务器是字节数据,所以需要进行数据的序列化Step3 计算出当前发送消息的分区号Step4 获取给定字段的记录所需的批次大小的上限预估值Step5 添加消息记录到accumulatorStep6 如果batch已经满了,或者是新创建的批次,则唤醒Sender线程执行发送任务
二、doSend() 发送主体逻辑拆解
2.1 同步等待可用的主题的元数据(metadata)
获取可用的主题元数据,具体的逻辑在waitOnMetadata()中实现
// ClusterAndWaitTime主要是主题集群Cluster和元数据等待时间
private static class ClusterAndWaitTime {
final Cluster cluster;
final long waitedOnMetadataMs;
ClusterAndWaitTime(Cluster cluster, long waitedOnMetadataMs) {
this.cluster = cluster;
this.waitedOnMetadataMs = waitedOnMetadataMs;
}
}
/**
* 等待集群元数据包括给定主题分区可用
* @param topic 主题
* @param partition 分区号
* @param nowMs 当前时间
* @param maxWaitMs 最大等待时间,默认为60秒
*/
private ClusterAndWaitTime waitOnMetadata(String topic, Integer partition, long nowMs, long maxWaitMs) throws InterruptedException {
// add topic to metadata topic list if it is not there already and reset expiry
// 从元数据缓存(MetadataCache)非阻塞的获取当前集群信息
Cluster cluster = metadata.fetch();
// 如果集群不可用的主题中
if (cluster.invalidTopics().contains(topic))
throw new InvalidTopicException(topic);
// 加入当前主题和当前时间到元数据中
metadata.add(topic, nowMs);
// 获取到当前主题的分区数
Integer partitionsCount = cluster.partitionCountForTopic(topic);
// Return cached metadata if we have it, and if the record's partition is either undefined
// or within the known partition range
// 如果分区号还没有分配,或者分区号在当前分区号范围之内,则 直接创建ClusterAndWaitTime 并返回当前集群元数据
if (partitionsCount != null && (partition == null || partition < partitionsCount))
return new ClusterAndWaitTime(cluster, 0);
// 如果partitionsCount 为空,或者指定分区号已经有了,或者指定分区号超出当前主题分区号
// 剩余等待时间 = 配置的最长等待时间
long remainingWaitMs = maxWaitMs;
// 已耗时多长
long elapsed = 0;
long nowNanos = time.nanoseconds();
// do while 不断在尝试等待获取元数据,直至获取到集群元数据或超过maxWaitTimeMs;如果有了集群的元数据之后,partitionsCount不为null,就表示有了集群元数据,然后退出循环
do {
if (partition != null) {
log.trace("Requesting metadata update for partition {} of topic {}.", partition, topic);
} else {
log.trace("Requesting metadata update for topic {}.", topic);
}
metadata.add(topic, nowMs + elapsed);
// 获取当前元数据的版本号 。 在Producer管理元数据时候,每一个元数据都有版本号,更新元数据的时候版本号也会随之更新
int version = metadata.requestUpdateForTopic(topic);
// 唤醒客户端Sender线程,并执行拉取元数据操作,拉取元数据的操作是由Sender线程完成的
sender.wakeup();
try {
// 同步的等待sender线程拉取元数据
metadata.awaitUpdate(version, remainingWaitMs);
} catch (TimeoutException ex) {
// Rethrow with original maxWaitMs to prevent logging exception with remainingWaitMs
throw new TimeoutException(
String.format("Topic %s not present in metadata after %d ms.",
topic, maxWaitMs));
}
cluster = metadata.fetch();
elapsed = time.milliseconds() - nowMs;
if (elapsed >= maxWaitMs) {
throw new TimeoutException(partitionsCount == null ?
String.format("Topic %s not present in metadata after %d ms.",
topic, maxWaitMs) :
String.format("Partition %d of topic %s with partition count %d is not present in metadata after %d ms.",
partition, topic, partitionsCount, maxWaitMs));
}
metadata.maybeThrowExceptionForTopic(topic);
remainingWaitMs = maxWaitMs - elapsed;
partitionsCount = cluster.partitionCountForTopic(topic);
} while (partitionsCount == null || (partition != null && partition >= partitionsCount));
producerMetrics.recordMetadataWait(time.nanoseconds() - nowNanos);
// 创建ClusterAndWaitTime 并返回当前集群元数据
return new ClusterAndWaitTime(cluster, elapsed);
}
waitOnMetadata()方法处理逻辑
1、 从元数据缓存(MetadataCache)非阻塞的获取当前集群信息 2、 将当前主题和当前时间到元数据中 3、 获取到当前主题的分区数 4、 Case1 如果分区号还没有分配,或者分区号在当前分区号范围之内,则 直接创建ClusterAndWaitTime 并返回当前集群元数据 5、 Case2 如果partitionsCount 为空,或者指定分区号已经有了,或者指定分区号超出当前主题分区号 do {} while (partitionsCount == null || (partition != null && partition >= partitionsCount)); do while 不断在尝试等待获取元数据,如果有了集群的元数据之后,partitionsCount不为null,就表示有了集群元数据,然后退出循环
2.2、消息key/value的序列化处理
序列化的原因:Kafka服务端接收的数据格式是字节数组(byte[]), 所以生产者需要用序列化器(Serializer)把对象转换成字节数组才能通过网络发送给Kafka, 消费者从Kafak中获取字节数组数据,再通过反序列化器(Deserializer)成相应的对象。因此,生产者和消费者的序列化规则需要保持一致。
**常见的序列化方式:**org.apache.kafka.common.serialization.Serializer接口是Kafka的父接口,客户端自带的String的序列化器StringSerializer(org.apache.kafka.common.serialization.StringSerializer),以及ByteArray、ByteBuffer、Double、Integer、Long 等类型,都是实现与 Serializer 接口。
详细的介绍可以查看之前的介绍:Kafka由浅入深(2) 生产者主线程工作原理_架构源启的博客-CSDN博客
2.3 计算出当前发送消息的分区号
private int partition(ProducerRecord record, byte[] serializedKey, byte[] serializedValue, Cluster cluster) {
// Case1 如果消息中指定了分区,则使用指定的分区
if (record.partition() != null)
return record.partition();
// Case2 如果生产者客户端设置了自定义分区逻辑,则通过自定义分区逻辑进行分区处理
if (partitioner != null) {
int customPartition = partitioner.partition(
record.topic(), record.key(), serializedKey, record.value(), serializedValue, cluster);
if (customPartition < 0) {
throw new IllegalArgumentException(String.format(
"The partitioner generated an invalid partition number: %d. Partition number should always be non-negative.", customPartition));
}
return customPartition;
}
if (serializedKey != null && !partitionerIgnoreKeys) {
// Case3 如果未指定分区但存在key并且配置partitioner.ignore.keys=false,则根据序列化key使用murmur2哈希算法对分区数取模
return BuiltInPartitioner.partitionForKey(serializedKey, cluster.partitionsForTopic(record.topic()).size());
} else {
// Case4 如果未指定分区或key或配置partitioner.ignore.keys=true,则返回RecordMetadata.UNKNOWN_PARTITION,在RecordAccumulator基于服务器压力进行动态负载分配分区
return RecordMetadata.UNKNOWN_PARTITION;
}
}
public class BuiltInPartitioner {
private final Logger log;
private final String topic;
private final int stickyBatchSize;
private volatile PartitionLoadStats partitionLoadStats = null;
private final AtomicReference stickyPartitionInfo = new AtomicReference<>();
...
// 获取到当前粘性分区信息
StickyPartitionInfo peekCurrentPartitionInfo(Cluster cluster) {
StickyPartitionInfo partitionInfo = stickyPartitionInfo.get();
if (partitionInfo != null)
return partitionInfo;
// 第一次创建partitionInfo
partitionInfo = new StickyPartitionInfo(nextPartition(cluster));
// 基于CAS 更新partitionInfo
if (stickyPartitionInfo.compareAndSet(null, partitionInfo))
return partitionInfo;
// 没有争抢到锁的时候,通过竞争获取
return stickyPartitionInfo.get();
}
/**
* 基于分区负载,计算下一个主题的分区
*/
private int nextPartition(Cluster cluster) {
// 随机一个数,用于后续随机分区计算
int random = mockRandom != null ? mockRandom.get() : Utils.toPositive(ThreadLocalRandom.current().nextInt());
// 分区负载的状态
PartitionLoadStats partitionLoadStats = this.partitionLoadStats;
// 分区号
int partition;
if (partitionLoadStats == null) {
// 如果分区负载状态为空,则获取到所有可用状态的分区
List availablePartitions = cluster.availablePartitionsForTopic(topic);
if (availablePartitions.size() > 0) {
// 如果存在可用状态的分区,则随机一个可用状态分区并返回
partition = availablePartitions.get(random % availablePartitions.size()).partition();
} else {
// 如果不存在可用状态的分区,则随机一个主题下得分区并返回
List partitions = cluster.partitionsForTopic(topic);
partition = random % partitions.size();
}
} else {
// 如果当前处于分区负载状态
assert partitionLoadStats.length > 0;
// 分区负载的负载量
int[] cumulativeFrequencyTable = partitionLoadStats.cumulativeFrequencyTable;
// 随机负载的权重
int weightedRandom = random % cumulativeFrequencyTable[partitionLoadStats.length - 1];
// 通过二分查找找到预期的分区并返回
int searchResult = Arrays.binarySearch(cumulativeFrequencyTable, 0, partitionLoadStats.length, weightedRandom);
int partitionIndex = Math.abs(searchResult + 1);
assert partitionIndex < partitionLoadStats.length;
partition = partitionLoadStats.partitionIds[partitionIndex];
}
log.trace("Switching to partition {} in topic {}", partition, topic);
return partition;
}
}
Kafka 3.0.0版本之前使用默认分区器DefaultPartitioner
默认分区全路径类名:org.apache.kafka.clients.producer.internals.DefaultPartitioner
1、如果消息中指定了分区,则使用指定的分区
2、如果未指定分区但存在key,则根据序列化key使用murmur2哈希算法对分区数取模。
3、如果不存在分区或key,则会使用粘性分区策略(2.4.0版本开始),关于粘性分区请参阅 KIP-480。
Kafka 3.0.0版本之后弃用默认分区器DefaultPartitioner,分区逻辑在KafkaProducer 的partition()方法实现
改动之后的变化
1、如果消息中指定了分区,则使用指定的分区。这个跟之前一样
2、如果生产者客户端设置了自定义分区逻辑,则通过自定义分区逻辑进行分区处理
3、如果未指定分区但存在key并且配置partitioner.ignore.keys=false,则根据序列化key使用murmur2哈希算法对分区数取模。
4、如果未指定分区或key或配置partitioner.ignore.keys=true,则返回RecordMetadata.UNKNOWN_PARTITION,在RecordAccumulator基于服务器压力进行动态负载分配分区
对于Kafka 3.0.0 之后弃用默认分区器DefaultPartitioner和统一粘性分区的原因和详细的分区方案,可以参考上一篇文章 Kafka由浅入深(3)一文读懂弃用默认分区器DefaultPartitioner KIP-794_架构源启的博客-CSDN博客
2.4、获取给定字段的记录所需的批次大小的上限预估值
public abstract class AbstractRecords implements Records {
...
/**
* 获取给定字段的记录所需的批次大小的上限预估值。为什么是上限预估,因为它没有考虑到压缩算法的开销。
*/
public static int estimateSizeInBytesUpperBound(byte magic, CompressionType compressionType, byte[] key, byte[] value, Header[] headers) {
return estimateSizeInBytesUpperBound(magic, compressionType, Utils.wrapNullable(key), Utils.wrapNullable(value), headers);
}
// 获取消息批次的字节数
public static int estimateSizeInBytesUpperBound(byte magic, CompressionType compressionType, ByteBuffer key,
ByteBuffer value, Header[] headers) {
if (magic >= RecordBatch.MAGIC_VALUE_V2)
return DefaultRecordBatch.estimateBatchSizeUpperBound(key, value, headers);
else if (compressionType != CompressionType.NONE)
return Records.LOG_OVERHEAD + LegacyRecord.recordOverhead(magic) + LegacyRecord.recordSize(magic, key, value);
else
return Records.LOG_OVERHEAD + LegacyRecord.recordSize(magic, key, value);
}
}
2.5、添加消息到记录收集器RecordAccumulator
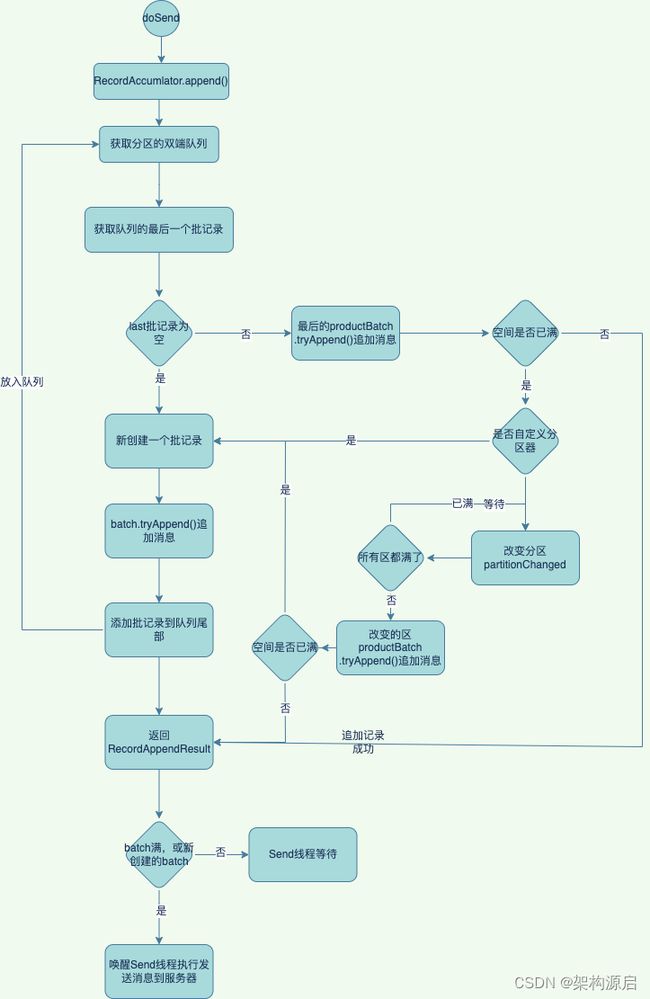
生产者发送的消息先在客户端缓存到记录收集器RecordAccumulator中。如果批记录已满,或者是新创建的配词记录,则唤醒Sender线程执行发送到Kafka集群服务器的消息任务。
如下图为记录收集器RecordAccumlator内存结构图
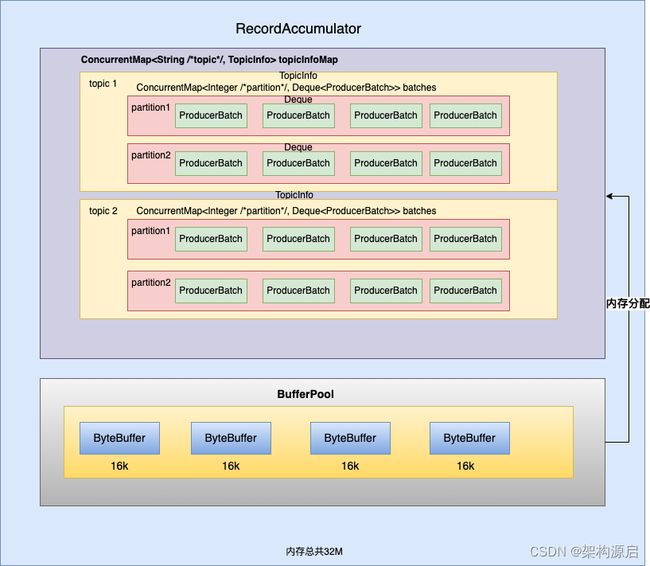
RecordAccumlator主要功能作用是缓存消息以便Sender线程可以批量发送,从而减少网络传输的资源消耗,提升性能。RecordAccumlator缓存大小可以通过生产者客户端参数“buffer.memroy”配置,默认值为32M。RecordAccumlator的内部还有一个BytePool缓冲池,主要实现对ByteBuffer的复用,但只是针对特定大小的ByteBuffer进行管理。ByteBuffer的特定大小,是通过参数“batch.size”指定,默认值为16K。
RecordAccumlator详细原理解析可以看 Kafka由浅入深(5)RecordAccumulator的工作原理_架构源启的博客-CSDN博客
6、唤醒Sender线程执行发送集群消息任务
如果batch已经满了,或者是新创建的批次,则唤醒Sender线程执行发送任务
说明:
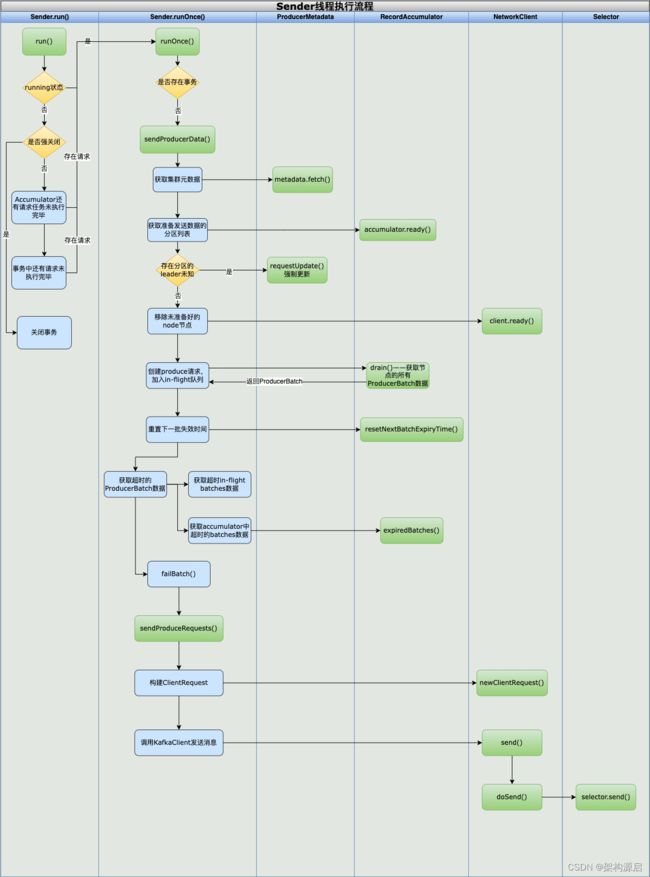
对于后面两期Kafak,将着重对Sender线程的实现原理和源码解析,敬请期待!