Python爬虫之Scrapy框架系列(21)——重写媒体管道类实现保存图片名字自定义及多页爬取
目录:
- 重写框架自带媒体管道类部分方法实现保存图片名字的自定义:
-
- 1.爬虫文件:
- 2.items.py文件中设置特殊的字段名:
- 3.settings.py文件中开启自建管道并设置文件存储路径:
- 4.编写pipelines.py
- 5.观察可发现完美实现:
- 它的工作流是这样的:
- 更改爬虫文件实现多页爬取:
- 拓展:媒体管道的一些设置:
重写框架自带媒体管道类部分方法实现保存图片名字的自定义:
- spider文件中要拿到图片列表并yield item;
- item里需要定义特殊的字段名:image_urls=scrapy.Field();
- settings里设置IMAGES_STORE存储路径,如果路径不存在,系统会帮助我们创建;
- 使用默认管道则在settings.py文件中开启:scrapy.pipelines.images.ImagesPipeline: 60,
自建管道需要继承ImagesPipeline并在settings.py中开启相应的管道; - 可根据官方文档进行重写:
get_media_requests
item_completed
1.爬虫文件:
# -*- coding: utf-8 -*-
import scrapy
import re
from ..items import BaiduimgPipeItem
import os
class BdimgSpider(scrapy.Spider):
name = 'bdimgpipe'
allowed_domains = ['image.baidu.com']
start_urls = ['https://image.baidu.com/search/index?tn=baiduimage&ipn=r&ct=201326592&cl=2&lm=-1&st=-1&sf=1&fmq=&pv=&ic=0&nc=1&z=&se=1&showtab=0&fb=0&width=&height=&face=0&istype=2&ie=utf-8&fm=index&pos=history&word=%E7%8C%AB%E5%92%AA']
def parse(self, response):
text=response.text
image_urls=re.findall('"thumbURL":"(.*?)"',text)
item=BaiduimgPipeItem()
item["image_urls"]=image_urls
yield item
2.items.py文件中设置特殊的字段名:
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class BaiduimgPipeItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
image_urls=scrapy.Field()
3.settings.py文件中开启自建管道并设置文件存储路径:
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
# 'baiduimg.pipelines.BaiduimgPipeline': 300,
'baiduimg.pipelines.BdImagePipeline': 40,
# 'scrapy.pipelines.images.ImagesPipeline': 60,
}
# IMAGES_STORE =r'C:\my\pycharm_work\爬虫\eight_class\baiduimg\baiduimg\dir0'
IMAGES_STORE ='C:/my/pycharm_work/爬虫/eight_class_ImagesPipeline/baiduimg/baiduimg/dir3'
4.编写pipelines.py
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
from scrapy.http import Request
import os
from scrapy.pipelines.images import ImagesPipeline # 导入要使用的媒体管道类
from .settings import IMAGES_STORE
class BdImagePipeline(ImagesPipeline):
image_num = 0
print("spider的媒体管道类")
def get_media_requests(self, item, info): # 可以用来重写
# 将图片的URL变成请求发给引擎
'''
req_list=[]
for x in item.get(self.images_urls_field, []): #本句相当于:item["images_urls"]得到图片URL列表
req_list.append(Request(x))
return req_list
'''
return [Request(x) for x in item.get(self.images_urls_field, [])]
def item_completed(self, results, item, info):
images_path = [x["path"] for ok,x in results if ok]
for image_path in images_path: # 通过os的方法rename实现图片保存名字的自定义!第一个参数为图片原路径;第二个参数为图片自定义路径
os.rename(IMAGES_STORE+"/"+image_path,IMAGES_STORE+"/full/"+str(self.image_num)+".jpg") # IMAGES_STORE+"/"+image_path是图片保存的原绝对路径;第二个参数是自定义的图片保存的新绝对路径(此处也放在IMAGES_STORE路径下)
self.image_num+=1
'''
源码中一个可重写的方法:
def item_completed(self, results, item, info): #此方法也可以重写
if isinstance(item, dict) or self.images_result_field in item.fields:
item[self.images_result_field] = [x for ok, x in results if ok]
return item
results详解:
url-从中下载文件的网址。这是从get_media_requests() 方法返回的请求的URL 。
path- FILES_STORE文件存储的路径(相对于)
checksum- 图片内容的MD5哈希
这是该results参数的典型值:
[(True,
{'checksum': '2b00042f7481c7b056c4b410d28f33cf',
'path': 'full/0a79c461a4062ac383dc4fade7bc09f1384a3910.jpg',
'url': 'http://www.example.com/files/product1.pdf'}),
]
而上面的方法item_completed()就是处理此results的,所以解读源码:
[x for ok, x in results if ok]
可知此列表推导式获取的是results中整个字典的值,然后赋给item再返回!
依此得出思路,可通过下面列表推导式获取results中图片存储的路径:
images_path = [x["path"] for ok,x in results if ok]
'''
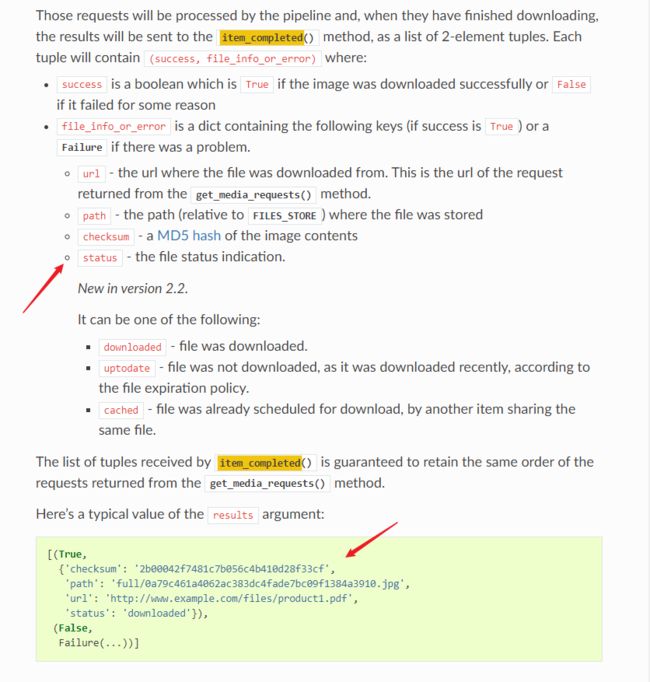
5.观察可发现完美实现:
它的工作流是这样的:
(下面讲的是文件管道类,其实和图片管道类一个道理。因为图片管道类是继承的文件管道类,而它俩都是继承的媒体管道类~)
- 在爬虫中,您可以返回一个item,并将所需的url放入file_urls字段。
- item从爬虫返回并进入item管道。
- 当item到达文件管道时,file_urls字段中的url将使用标准的Scrapy调度器和下载程序(这意味着将重用调度器和下载程序中间件)计划下载, 但是具有更高的优先级,在其他页面被爬取之前处理它们。在文件下载完成(或由于某种原因失败)之前,该项在特定管道阶段保持“锁定”状态。
- 下载文件后,将使用另一个字段(files)填充results。这个字段将包含一个包含有关下载文件信息的dicts列表,例如下载的路径、原始的剪贴url(从file_urls字段中获得)和文件校验和。文件字段列表中的文件将保持原来file_urls字段的顺序。如果某些文件下载失败,将记录一个错误,文件将不会出现在files字段中。
更改爬虫文件实现多页爬取:
- 注意:settings.py文件中设置个下载延迟哦!不然会有被封的危险。
# -*- coding: utf-8 -*-
import scrapy
import re
from ..items import BaiduimgPipeItem
import os
class BdimgSpider(scrapy.Spider):
name = 'bdimgpipe'
allowed_domains = ['image.baidu.com']
start_urls = ['https://image.baidu.com/search/index?tn=baiduimage&ipn=r&ct=201326592&cl=2&lm=-1&st=-1&sf=1&fmq=&pv=&ic=0&nc=1&z=&se=1&showtab=0&fb=0&width=&height=&face=0&istype=2&ie=utf-8&fm=index&pos=history&word=%E7%8C%AB%E5%92%AA']
page_url="https://image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj&ct=201326592&is=&fp=result&queryWord=%E7%8C%AB%E5%92%AA&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=0&hd=&latest=©right=&word=%E7%8C%AB%E5%92%AA&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&fr=&expermode=&force=&pn={}&rn=30&gsm=1e&1588088573059="
num = 0
pagenum=1
def parse(self, response):
text=response.text
image_urls=re.findall('"thumbURL":"(.*?)"',text)
item=BaiduimgPipeItem()
item["image_urls"]=image_urls
yield item
url=self.page_url.format(self.pagenum*30)
self.pagenum+=1
if self.pagenum == 3: #想要多少就设置多少为中断!!!
return
yield scrapy.Request(url, callback=self.parse)
'''
F12观察原网页,每次加载更多图片,找到对应的URL,观察规律,发现其中pn参数的值随着页面的加载逐页增加30!!!
https://image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj&ct=201326592&is=&fp=result&queryWord=%E7%8C%AB%E5%92%AA&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=0&hd=&latest=©right=&word=%E7%8C%AB%E5%92%AA&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&fr=&expermode=&force=&pn=30&rn=30&gsm=1e&1588088573059=
https://image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj&ct=201326592&is=&fp=result&queryWord=%E7%8C%AB%E5%92%AA&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=0&hd=&latest=©right=&word=%E7%8C%AB%E5%92%AA&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&fr=&expermode=&force=&pn=60&rn=30&gsm=3c&1588088573138=
'''
效果非常nice:
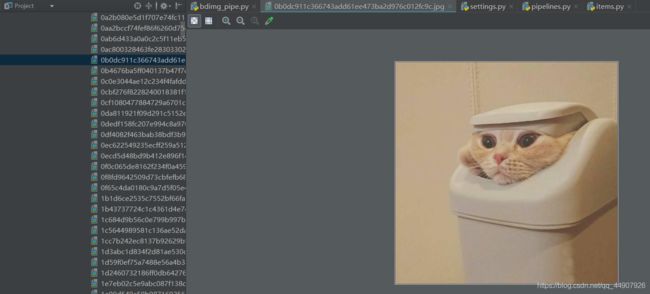
拓展:媒体管道的一些设置:
ITEM_PIPELINES = {'scrapy.pipelines.images.ImagesPipeline': 1} 启用
FILES_STORE = '/path/to/valid/dir' 文件管道存放位置
IMAGES_STORE = '/path/to/valid/dir' 图片管道存放位置
FILES_URLS_FIELD = 'field_name_for_your_files_urls' 自定义文件url字段
FILES_RESULT_FIELD = 'field_name_for_your_processed_files' 自定义结果字段
IMAGES_URLS_FIELD = 'field_name_for_your_images_urls' 自定义图片url字段
IMAGES_RESULT_FIELD = 'field_name_for_your_processed_images' 结果字段
FILES_EXPIRES = 90 文件过期时间 默认90天
IMAGES_EXPIRES = 90 图片过期时间 默认90天
IMAGES_THUMBS = {'small': (50, 50), 'big':(270, 270)} 缩略图尺寸 # !!!直接在settings.py中写入此设置,再运行框架就会生成缩略图!!!十分方便,常用!!!
IMAGES_MIN_HEIGHT = 110 过滤最小高度
IMAGES_MIN_WIDTH = 110 过滤最小宽度
MEDIA_ALLOW_REDIRECTS = True 是否重定向