vfio概述(vfio/iommu/device passthrough)
文章目录
1.IOMMU
1.1 IOMMU功能简介
1.2 IOMMU作用
1.3 IOMMU工作原理
1.4 Source Identifier
2.VFIO
2.1 概念介绍
2.2 使用示例
3.设备透传分析
3.1 虚机地址映射
3.2 设备透传实现
1.IOMMU
1.1 IOMMU功能简介
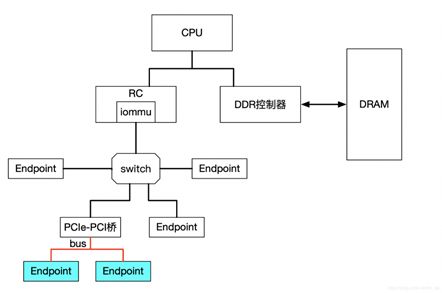
IOMMU主要功能包括DMA Remapping和Interrupt Remapping,这里主要讲解DMA Remapping,Interrupt Remapping会独立讲解。对于DMA Remapping,IOMMU与MMU类似。IOMMU可以将一个设备访问地址转换为存储器地址,下图针对有无IOMMU情况说明IOMMU作用。
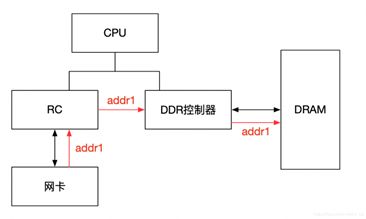
在没有IOMMU的情况下,网卡接收数据时地址转换流程,RC会将网卡请求写入地址addr1直接发送到DDR控制器,然后访问DRAM上的addr1地址,这里的RC对网卡请求地址不做任何转换,网卡访问的地址必须是物理地址。

对于有IOMMU的情况,网卡请求写入地址addr1会被IOMMU转换为addr2,然后发送到DDR控制器,最终访问的是DRAM上addr2地址,网卡访问的地址addr1会被IOMMU转换成真正的物理地址addr2,这里可以将addr1理解为虚机地址。
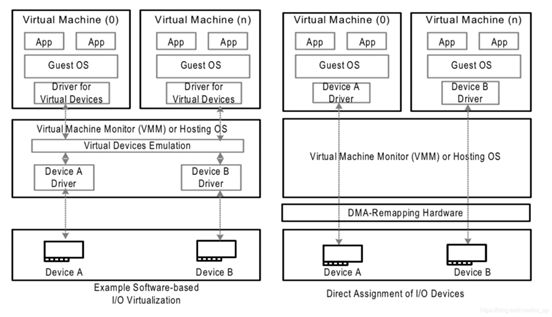
左图是没有IOMMU的情况,对于虚机无法实现设备的透传,原因主要有两个:
一是因为在没有IOMMU的情况下,设备必须访问真实的物理地址HPA,而虚机可见的是GPA;
二是如果让虚机填入真正的HPA,那样的话相当于虚机可以直接访问物理地址,会有安全隐患。
所以针对没有IOMMU的情况,不能用透传的方式,对于设备的直接访问都会有VMM接管,这样就不会对虚机暴露HPA。
右图是有IOMMU的情况,虚机可以将GPA直接写入到设备,当设备进行DMA传输时,设备请求地址GPA由IOMMU转换为HPA(硬件自动完成),进而DMA操作真实的物理空间。IOMMU的映射关系是由VMM维护的,HPA对虚机不可见,保障了安全问题,利用IOMMU可实现设备的透传。这里先留一个问题,既然IOMMU可以将设备访问地址映射成真实的物理地址,那么对于右图中的Device A和Device B,IOMMU必须保证两个设备映射后的物理空间不能存在交集,否则两个虚机可以相互干扰,这和IOMMU的映射原理有关,后面会详细介绍。
1.2 IOMMU作用
根据上一节内容,总结IOMMU主要作用如下:
屏蔽物理地址,起到保护作用。典型应用包括两个:一是实现用户态驱动,由于IOMMU的映射功能,使HPA对用户空间不可见,在vfio部分还会举例。二是将设备透传给虚机,使HPA对虚机不可见,并将GPA映射为HPA.
IOMMU可以将连续的虚拟地址映射到不连续的多个物理内存片段,这部分功能于MMU类似,对于没有IOMMU的情况,设备访问的物理空间必须是连续的,IOMMU可有效的解决这个问题
1.3 IOMMU工作原理
前面简单介绍了IOMMU的映射功能,下面讲述IOMMU到底如何实现映射的,为便于分析,这里先不考虑虚拟化的场景,以下图为例,阐述工作原理。
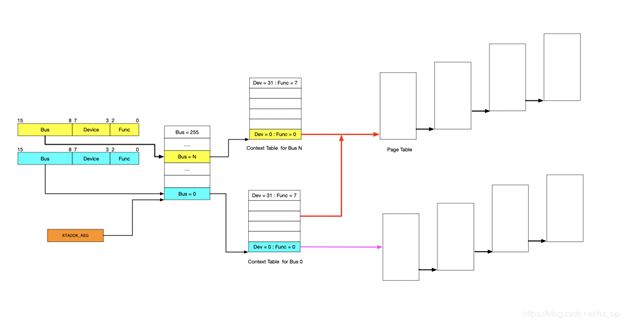
IOMMU的主要功能就是完成映射,类比MMU利用页表实现VA->PA的映射,IOMMU也需要用到页表,那么下一个问题就是如何找到页表。在设备发起DMA请求时,会将自己的Source Identifier(包含Bus、Device、Func)包含在请求中,IOMMU根据这个标识,以RTADDR_REG指向空间为基地址,然后利用Bus、Device、Func在Context Table中找到对应的Context Entry,即页表首地址,然后利用页表即可将设备请求的虚拟地址翻译成物理地址。这里做以下说明:
图中红线的部门,是两个Context Entry指向了同一个页表。这种情况在虚拟化场景中的典型用法就是这两个Context Entry对应的不同PCIe设备属于同一个虚机,那样IOMMU在将GPA->HPA过程中要遵循同一规则 ?????
由图中可知,每个具有Source Identifier(包含Bus、Device、Func)的设备都会具有一个Context Entry。如果不这样做,所有设备共用同一个页表,隶属于不同虚机的不同GPA就会翻译成相同HPA,会产生问题,
有了页表之后,就可以按照MMU那样进行地址映射工作了,这里也支持不同页大小的映射,包括4KB、2MB、1GB,不同页大小对应的级数也不同,下图以4KB页大小为例说明,映射过程和MMU类似,不再详细阐述。

1.4 Source Identifier
在讲述IOMMU的工作原理时,讲到了设备利用自己的Source Identifier(包含Bus、Device、Func)来找到页表项来完成地址映射,不过存在下面几个特殊情况需要考虑。
对于由PCIe switch扩展出的PCI桥及桥下设备,在发送DMA请求时,Source Identifier是PCIe switch的,这样的话该PCI桥及桥下所有设备都会使用PCIe switch的Source Identifier去定位Context Entry,找到的页表也是同一个,如果将这个PCI桥下的不同设备分给不同虚机,由于会使用同一份页表,这样会产生问题,针对这种情况,当前PCI桥及桥下的所有设备必须分配给同一个虚机,这就是VFIO中组的概念,下面会再讲到。
对于SRIO-V,之前介绍过VF的Bus及devfn的计算方法,所以不同VF会有不同的Source Identifier,映射到不同虚机也是没有问题的
2.VFIO
#########
Virtual Function I/O (VFIO) 是一种现代化的设备直通方案,它充分利用了VT-d/AMD-Vi技术提供的DMA Remapping和Interrupt Remapping特性, 在保证直通设备的DMA安全性同时可以达到接近物理设备的I/O的性能。 用户态进程可以直接使用VFIO驱动直接访问硬件,并且由于整个过程是在IOMMU的保护下进行因此十分安全, 而且非特权用户也是可以直接使用。 换句话说,VFIO是一套完整的用户态驱动(userspace driver)方案,因为它可以安全地把设备I/O、中断、DMA等能力呈现给用户空间。
为了达到最高的IO性能,虚拟机就需要VFIO这种设备直通方式,因为它具有低延时、高带宽的特点,并且guest也能够直接使用设备的原生驱动。 这些优异的特点得益于VFIO对VT-d/AMD-Vi所提供的DMA Remapping和Interrupt Remapping机制的应用。 VFIO使用DMA Remapping为每个Domain建立独立的IOMMU Page Table将直通设备的DMA访问限制在Domain的地址空间之内保证了用户态DMA的安全性, 使用Interrupt Remapping来完成中断重映射和Interrupt Posting来达到中断隔离和中断直接投递的目的。
2.1. VFIO 框架简介
整个VFIO框架设计十分简洁清晰,可以用下面的一幅图描述:
+--------------------------------------------------------------+
| VFIO interface |
+--------------------------------------------------------------+
| vfio_iommu | vfio_pci |
+--------------------------------------------------------------+
| iommu driver | pci_bus driver |
+--------------------------------------------------------------+
最上层VFIO Interface Layer,它负责向用户态提供统一访问的接口,用户态通过约定的ioctl设置和调用VFIO的各种能力。
中间层分别是vfio_iommu和vfio_pci:
vfio_iommu是VFIO对iommu层的统一封装主要用来实现DMA Remapping的功能,即管理IOMMU页表的能力。
vfio_pci是VFIO对pci设备驱动的统一封装,它和用户态进程一起配合完成设备访问直接访问,具体包括PCI配置空间模拟、PCI Bar空间重定向,Interrupt Remapping等。
最下面的一层则是硬件驱动调用层:
iommu driver是与硬件平台相关的实现,例如它可能是intel iommu driver或amd iommu driver或者ppc iommu driver或者arm SMMU driver;
pci_bus driver: 而同时vfio_pci会调用到host上的pci_bus driver来实现设备的注册和反注册等操作。
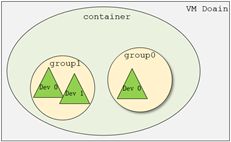
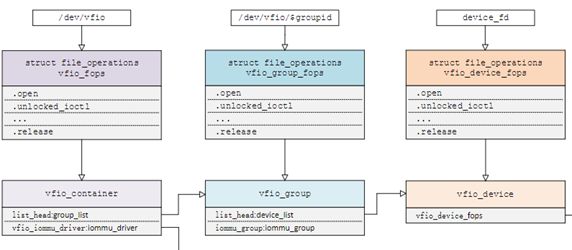
在了解VFIO之前需要了解3个基本概念:device, group, container,它们在逻辑上的关系如上图所示。
Group 是IOMMU能够进行DMA隔离的最小硬件单元,一个group内可能只有一个device,也可能有多个device,这取决于物理平台上硬件的IOMMU拓扑结构。 设备直通的时候一个group里面的设备必须都直通给一个虚拟机。 不能够让一个group里的多个device分别从属于2个不同的VM,也不允许部分device在host上而另一部分被分配到guest里, 因为就这样一个guest中的device可以利用DMA攻击获取另外一个guest里的数据,就无法做到物理上的DMA隔离。 另外,VFIO中的group和iommu group可以认为是同一个概念。
Device 指的是我们要操作的硬件设备,不过这里的“设备”需要从IOMMU拓扑的角度去理解。如果该设备是一个硬件拓扑上独立的设备,那么它自己就构成一个iommu group。 如果这里是一个multi-function设备,那么它和其他的function一起组成一个iommu group,因为多个function设备在物理硬件上就是互联的, 他们可以互相访问对方的数据,所以必须放到一个group里隔离起来。值得一提的是,对于支持PCIe ACS特性的硬件设备,我们可以认为他们在物理上是互相隔离的。
Container 是一个和地址空间相关联的概念,这里可以简单把它理解为一个VM Domain的物理内存空间。对于用户态驱动,Container可以是多个Group的集合。
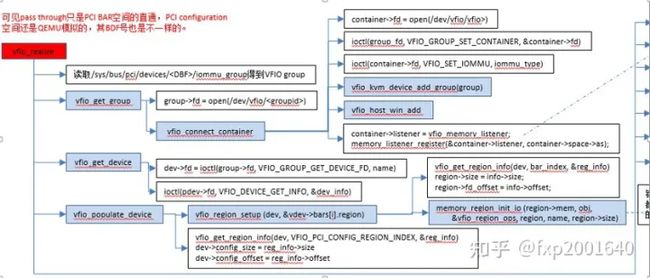
从上图可以看出,一个或多个device从属于某个group,而一个或多个group又从属于一个container。 如果要将一个device直通给VM,那么先要找到这个设备从属的iommu group,然后将整个group加入到container中即可。关于如何使用VFIO可以参考内核文档:vfio.txt
上图中PCIe-PCI桥下的两个设备,在发送DMA请求时,PCIe-PCI桥会为下面两个设备生成Source Identifier,其中Bus域为红色总线号bus,device和func域为0。这样的话,PCIe-PCI桥下的两个设备会找到同一个Context Entry和同一份页表,所以这两个设备不能分别给两个虚机使用,这两个设备就属于一个Group。
2.2 VFIO 数据结构关系
Linux内核设备驱动充分利用了“一切皆文件”的思想,VFIO驱动也不例外,VFIO中为了方便操作device, group, container等对象将它们和对应的设备文件进行绑定。 VFIO驱动在加载的时候会创建一个名为/dev/vfio/vfio的文件,而这个文件的句柄关联到了vfio_container上,用户态进程打开这个文件就可以初始化和访问vfio_container。 当我们把一个设备直通给虚拟机时,首先要做的就是将这个设备从host上进行解绑,即解除host上此设备的驱动,然后将设备驱动绑定为“vfio-pci”, 在完成绑定后会新增一个/dev/vfio/$groupid的文件,其中$groupid为此PCI设备的iommu group id, 这个id号是在操作系统加载iommu driver遍历扫描host上的PCI设备的时候就已经分配好的,可以使用readlink -f /sys/bus/pci/devices/$bdf/iommu_group来查询。 类似的,/dev/vfio/$groupid这个文件的句柄被关联到vfio_group上,用户态进程打开这个文件就可以管理这个iommu group里的设备。 然而VFIO中并没有为每个device单独创建一个文件,而是通过VFIO_GROUP_GET_DEVICE_FD这个ioctl来获取device的句柄,然后再通过这个句柄来管理设备。
VFIO框架中很重要的一部分是要完成DMA Remapping,即为Domain创建对应的IOMMU页表,这个部分是由vfio_iommu_driver来完成的。 vfio_container包含一个指针记录vfio_iommu_driver的信息,在x86上vfio_iommu_driver的具体实现是由vfio_iommu_type1来完成的。 其中包含了vfio_iommu, vfio_domain, vfio_group, vfio_dma等关键数据结构(注意这里是iommu里面的),
vfio_iommu可以认为是和container概念相对应的iommu数据结构,在虚拟化场景下每个虚拟机的物理地址空间映射到一个vfio_iommu上。
vfio_group可以认为是和group概念对应的iommu数据结构,它指向一个iommu_group对象,记录了着iommu_group的信息。
vfio_domain这个概念尤其需要注意,这里绝不能把它理解成一个虚拟机domain,它是一个与DRHD(即IOMMU硬件)相关的概念, 它的出现就是为了应对多IOMMU硬件的场景,我们知道在大规格服务器上可能会有多个IOMMU硬件,不同的IOMMU硬件有可能存在差异, 例如IOMMU 0支持IOMMU_CACHE而IOMMU 1不支持IOMMU_CACHE(当然这种情况少见,大部分平台上硬件功能是具备一致性的),这时候我们不能直接将分别属于不同IOMMU硬件管理的设备直接加入到一个container中, 因为它们的IOMMU页表SNP bit是不一致的。 因此,一种合理的解决办法就是把一个container划分多个vfio_domain,当然在大多数情况下我们只需要一个vfio_domain就足够了。 处在同一个vfio_domain中的设备共享IOMMU页表区域,不同的vfio_domain的页表属性又可以不一致,这样我们就可以支持跨IOMMU硬件的设备直通的混合场景。
经过上面的介绍和分析,我们可以把VFIO各个组件直接的关系用下图表示(点击看完整图片),读者可以按照图中的关系去阅读相关代码实现。
########
VFIO就是内核针对IOMMU提供的软件框架,支持DMA Remapping和Interrupt Remapping,这里只讲DMA Remapping。VFIO利用IOMMU这个特性,可以屏蔽物理地址对上层的可见性,可以用来开发用户态驱动,也可以实现设备透传。
2.3 使用示例
这里先以简单的用户态驱动为例,在设备透传小节中,在分析如何利用vfio实现透传。
对于dev下Group就是按照上一节介绍的Group划分规则产生的,上述代码描述了如何使用VFIO实现映射,对于Group和Container的相关操作这里不做过多解释,主要关注如何完成映射,下图解释具体工作流程。
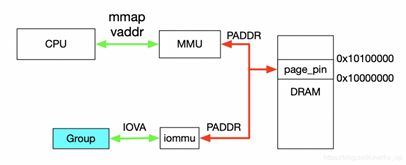
首先,利用mmap映射出1MB字节的虚拟空间,因为物理地址对于用户态不可见,只能通过虚拟地址访问物理空间。然后执行ioctl的VFIO_IOMMU_MAP_DMA命令,传入参数主要包含vaddr及iova,其中iova代表的是设备发起DMA请求时要访问的地址,也就是IOMMU映射前的地址,vaddr就是mmap的地址。VFIO_IOMMU_MAP_DMA命令会为虚拟地址vaddr找到物理页并pin住(因为设备DMA是异步的,随时可能发生,物理页面不能交换出去),然后找到Group对应的Contex Entry,建立页表项,页表项能够将iova地址映射成上面pin住的物理页对应的物理地址上去,这样对用户态程序完全屏蔽了物理地址,实现了用户空间驱动。IOVA地址的00x100000对应DRAM地址0x100000000x10100000,size为1024 * 1024。一句话概述,VFIO_IOMMU_MAP_DMA这个命令就是将iova通过IOMMU映射到vaddr对应的物理地址上去。
3.设备透传分析
设备透传就是由虚机直接接管设备,虚机可以直接访问MMIO空间,VMM配置好IOMMU之后,设备DMA读写请求也无需VMM借入,需要注意的是设备的配置空间没有透传,因为VMM已经配置好了BAR空间,如果将这部分空间也透传给虚机,虚机会对BAR空间再次配置,会导致设备无法正常工作。
3.1 虚机地址映射
在介绍透传之前,先看下虚机的GPA与HVA和HPA的关系,以及虚机是如何访问到真实的物理地址的,过程如下图。
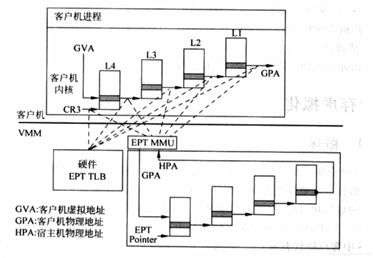
一旦页表建立好后,整个映射过程都是硬件自动完成的,对于上图有如下几点说明:
对于虚机内的页表,完成GVA到GPA的映射,虽然整个过程都是硬件自动完成,但有一点要注意下,在虚机的中各级页表也是存储在HPA中的,而CR3及各级页表中装的地址都是GPA,所以在访问页表时也需要借助EPT(extension page table?),上图中以虚线表示这个过程
利用虚机页表完成GVA到GPA的映射后,此时借助EPT实现GPA到HPA的映射,这里没有什么特殊的,就是一层层页表映射
看完上图,有没有发现少了点啥,是不是没有HVA。单从上图整个虚机寻址的映射过程来看,是不需要HVA借助的,硬件会自动完成GVA->GPA->HPA映射,那么HVA有什么用呢?这里从下面两方面来分析:
1)Qemu利用iotcl控制KVM实现EPT的映射,映射的过程中必然要申请物理页面。Qemu是应用程序,唯一可见的只是HVA,这时候又需要借助mmap了,Qemu会根据虚机的ram大小,即GPA大小范围,然后mmap出与之对应的大小,即HVA。通过KVM_SET_USER_MEMORY_REGION命令控制KVM,与这个命令一起传入的参数主要包括两个值,guest_phys_addr代表虚机GPA地址起始,userspace_addr代表上面mmap得到的首地址(HVA)。传入进去后,KVM就会为当前虚机GPA建立EPT映射表实现GPA->HPA,同时会为VMM建立HVA->HPA映射。
2)当vm_exit发生时,VMM需要对异常进行处理,异常发生时VMM能够获取到GPA,有时VMM需要访问虚机GPA对应的HPA,VMM的映射和虚机的映射方式不同,是通过VMM完成HVA->HPA,且只能通过HVA才能访问HPA,这就需要VMM将GPA及HVA的对应关系维护起来,这个关系是Qemu维护的,这里先不管Qemu的具体实现(后面会有专门文档介绍),当前只需要知道给定一个虚机的GPA,虚机就能获取到GPA对应的HVA。下图描述VMM与VM的地址映射关系。
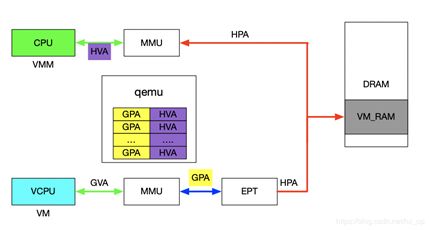
3.2 设备透传实现
在前面介绍VFIO的使用实例时,核心思想就是IOVA经过IOMMU映射出的物理地址与HVA经过MMU映射出的物理地址是同一个。对于设备透传的情况,先上图,然后看图说话。

先来分析一下设备的DMA透传的工作流程,一旦设备透传给了虚机,虚机在配置设备DMA时直接使用GPA。此时GPA经由EPT会映射成HPA1,GPA经由IOMMU映射的地址为HPA2,此时的HPA1和HPA2必须相等,设备的透传才有意义。下面介绍在配置IOMMU时如何保证HPA1和HPA2相等,在VFIO章节讲到了VFIO_IOMMU_MAP_DMA这个命令就是将iova通过IOMMU映射到vaddr对应的物理地址上去。对于IOMMU来讲,此时的GPA就是iova,我们知道GPA经由EPT会映射为HPA1,对于VMM来讲,这个HPA1对应的虚机地址为HVA,那样的话在传入VFIO_IOMMU_MAP_DMA命令时讲hva作为vaddr,IOMMU就会将GPA映射为HVA对应的物理地址及HPA1,即HPA1和HPA2相等。上述流程帮助理清整个映射关系,实际映射IOMMU的操作很简单,前面提到了qemu维护了GPA和HVA的关系,在映射IOMMU的时候也可以派上用场。注:IOMMU的映射在虚机启动时就已经建立好了,映射要涵盖整个GPA地址范围,同时虚机的HPA对应的物理页都不会交换出去(设备DMA交换是异步的)。
本文链接http://element-ui.cn/news/show-44900.aspx
1, 将硬件设备寄存器映射至用户态VA空间
1.1 在系统中使能vfio和iommu
1.1.1 在Bios开启iommu:
ARM : Advance -> MISC config -> Support SMMU
X86: Advance -> Intel @ Vt-d
1.1.2 在Kernel 启用iommu:
在/boot/grub2/grub.cfg中的linux kernel启动参数中添加:iommu.passthrough=1, 系统重启后执行:
linux~xp: /home # cat /proc/cmdline 以确定上述启动参数添加成功
1.1.3 加载vfio-pci内核模块
linux~xp: /home # modprobe vfio-pci上述命令将加载vfio_pci.ko, vfio_virqfd.ko, vfio_iommu_type1.ko, vfio.ko这4个内核模块。
1.2 用vfio-pci来驱动设备
1.2.1 通过lspci找到需要驱动的设备,比如0000:7b:00.0,并获取vendor id和device id:
Linux~: /home # lspci -n -s 0000:7b:00.0
7b:00.0 0880: 19e5:a122 (rev 21) (vendor id = 19e5 device id = a1222)1.2.2 解绑定原有驱动
Linux~xp: /home # echo 0000:7b:00.0 >>/sys/bus/pci/devices/0000\:7b\:00.0/driver/unbind1.2.3 绑定到vfio-pci
linux~xp: /home # echo 19e5 a122 > /sys/bus/pci/drivers/vfio-pci/new_id1.2.4 获取设备所在的iommu group
Linux~xp: /home # readlink /sys/bus/pci/devices/0000\:7b\:00.0/iommu_group
../../../kernel/iommu_groups/200 (/sys/kernel/iommu_groups/200/devices/0000\:7b\:00.0)可见设备所在iommu group是200
1.3 获取vfio接管下的device fd
container_fd = open("/dev/vfio/vfio", O_RDWR)
group_fd = open("/dev/vfio/200", O_RDWR)
ioctl(group_fd, VFIO_GROUP_SET_CONTAINER, &container_fd)
ioctl(container_fd, VFIO_SET_IOMMU, VFIO_TYPE1_IOMMU)
device_fd = ioctl(group_fd, VFIO_GROUP_GET_DEVICE_FD, “0000:7b:00.0”)把device_fd看成一个文件,这个文件的内容包含了设备的所有可访问资源,这包括中断,pci配置空间,扩展配置空间,6个bar空间。这些不同的资源可以看做是文件不同偏移基址处的一段文件内容(region),可以像读写普通文件一样读写这些资源。6个bar空间对应的region属于可映射区域,可以使用mmap将其映射进用户态空间进行读写,而其他资源则不可映射,只能通过read/write系统调用经内核进行间接的读写。设备的pci配置空间属于不可映射区域,只能read/write系统调用经内核进行间接的读写。
1.4 访问PCI配置空间
设备的pci配置空间属于不可映射区域,只能read/write系统调用经内核进行间接的读写。
1.4.1 获取设备的region数
struct vfio_device_info dev_info;
dev_info.argsz = sizeof(dev_info);
ioctl(device_fd, VFIO_DEVICE_GET_INFO, &dev_info)dev_info.num_regions即regions数量,其中标号为VFIO_PCI_CONFIG_REGION_INDEX(=7)的region固定为pci配置空间
1.4.2 获取pci配置空间的大小及其在device_fd文件中的偏移
struct vfio_region_info reg;
reg.argsz = sizeof(reg);
reg.index = idx;
ioctl(device_fd, VFIO_DEVICE_GET_REGION_INFO, ®);此时reg.size即pci配置空间的大小,reg.offset即pci配置空间在整个device_fd设备资源文件中的偏移
1.4.3 读写pci配置空间
pread64(device_fd, buf, len, reg->offset+ target_offset);
pwrite64(device_fd, buf, len, reg->offset+ target_offset);注意各种扩展capability结构也需通过此方式读取。
1.5 在用户态VA空间访问设备的BAR空间
设备的bar空间属于可映射区域,可以使用mmap将其映射进用户态空间进行读写。如下获取的0-5号regions为bar空间。
struct vfio_region_info reg;
reg.argsz = sizeof(reg);
reg.index = idx;
ioctl(device_fd, VFIO_DEVICE_GET_REGION_INFO, ®);
register_base = mmap(NULL, reg->size, PROT_READ | PROT_WRITE, MAP_SHARED, device_fd, reg.offset);
register_value = *((uint64_t *)(register_base + register_offset));此时register_base就是设备寄存器空间的基地址,再加上各个寄存器的偏移即可访问各个寄存器。
2, 在IOMMU中为硬件设备建立DMA映射
2.1 为什么要使用iommu
当DMA使用物理地址时可以访问任意内存,这会造成不同程序间的干扰。DMA只能访问连续物理内存。某些设备通过物理地址访存时无法访问高端内存。设备passthrough给guest os时,guest os中的驱动写入设备的地址是GPA,此时需要通过Iommu翻译为HPA。Host os的用户态驱动写入设备的地址是HVA ,此时需要通过Iommu翻译为HPA。
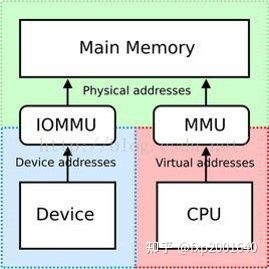
2.2 VFIO中iommu概念
Container :一种逻辑分类,一个container代表一个页表实例。
Group:一种物理分类,在同一个pci bridge后的设备属于同一个group。
Iommu:IOMMU本身亦是一种设备,它可以有多个,可以是不同类型,也有不同的驱动。
2.3 选择iommu驱动
container_fd = open(“/dev/vfio/vfio”, O_RDWR) # 每次open “/dev/vfio/vfio”都会
ioctl(container_fd, VFIO_SET_IOMMU, VFIO_TYPE1_IOMMU) # 创建新的页表实例container。2.4 为device选择页表实例
group_fd = open("/dev/vfio/200", O_RDWR)
ioctl(group_fd, VFIO_GROUP_SET_CONTAINER, &container_fd) 将device所在的group加入container,相当于为设备选择一个页表实例,即此设备的访存地址将用此页表进行映射。
2.5 建立映射
addr = malloc(size);
struct vfio_iommu_type1_dma_map map;
map.argsz = sizeof(map);
map.vaddr = (uint64_t)addr;
map.iova = (uint64_t)addr;
map.flags = VFIO_DMA_MAP_FLAG_READ | VFIO_DMA_MAP_FLAG_WRITE;
map.size = size;
ioctl(container_fd, VFIO_IOMMU_MAP_DMA, &map);这将在container对应的页表实例中新加一项映射:DMA使用map.iova访存时将访问map.vaddr虚拟地址对应的物理内存,map.iova是站在DMA的角度,map.vaddr是站在CPU的角度。可以添加多段映射。
3, 在用户态处理中断
中断处理函数必须放在内核中,用户态驱动创建一个eventfd,并在vfio中将中断绑定此eventfd,这样一旦vfio内核中的中断处理函数收到中断就会触发eventfd变为可读。用户态驱动epoll此eventfd,即可收到中断通知。
3.1 获取中断数量
struct vfio_device_info dev_info;
dev_info.argsz = sizeof(dev_info);
ioctl(device_fd, VFIO_DEVICE_GET_INFO, &dev_info)dev_info.num_irqs即中断数量
3.2 为每一个中断创建一个eventfd
int irqfd = eventfd(0, EFD_NONBLOCK | EFD_CLOEXEC);3.3 在vfio中绑定中断和eventfd
struct vfio_irq_set *irq_set = malloc(sizeof(*irq_set) + sizeof(irqfd));
irq_set->argsz = sizeof(*irq_set) + sizeof(irqfd);
irq_set->flags = VFIO_IRQ_SET_DATA_EVENTFD | VFIO_IRQ_SET_ACTION_TRIGGER;
irq_set->index = irq_index;
irq_set->start = 0;
irq_set->count = 1;
irq_set->data = irqfd;
ioctl(device, VFIO_DEVICE_SET_IRQS, irq_set);3.4 在用户态驱动中epoll中断对应的eventfd
struct epoll_event ev = {EPOLLIN, irqfd};
epoll_ctl(epollfd, EPOLL_CTL_ADD, &ev);
epoll_wait(epollfd, events, MAX_EVENTS, -1);
unsigned long long cnt;
read(irqfd, &cnt, sizeof(cnt));一旦irqfd可读表示其绑定的中断已经触发,读取回的值表示中断次数。如果基于DPDK编程,则dpdk有一个专门的eal-intr-thread中断处理线程用于上述的epoll。用户只需调用rte_intr_callback_register()将中断绑定的irqfd和对应的处理函数注册至eal-intr-thread即可。
4,QEMU VFIO 实现
4.1,数据结构

4.2,初始化流程
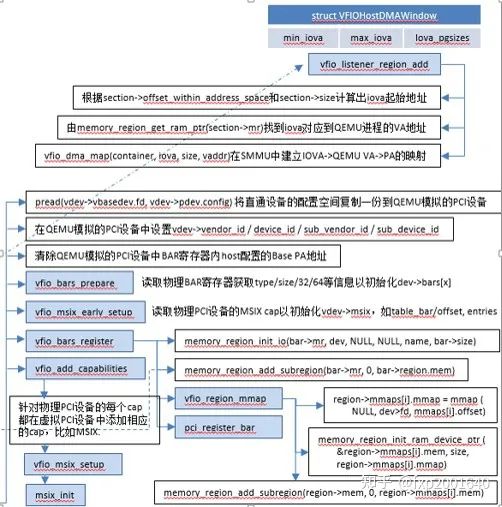
5,参考文档
VFIO简介
PCI和PCIE:PCI设备配置空间
PCI设备的配置空间如下图所示:
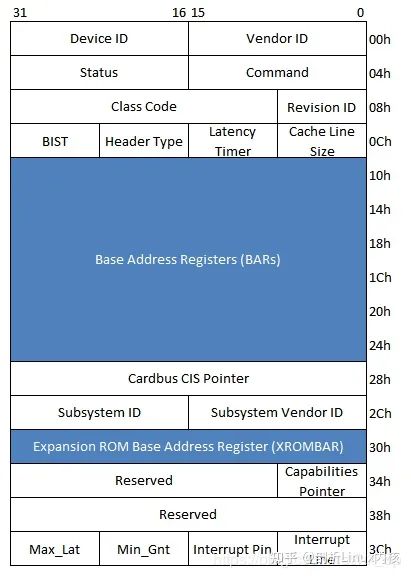
(1)Device ID和Vendor ID寄存器
这两个寄存器只读,Vendor ID代表PCI设备的生产厂商,而Device ID代表这个厂商所生产的具体设备。如Intel公司的82571EB芯片网卡,其中Vendor ID为0x8086,Device为0x105E。
(2)Revision ID和Class Code寄存器
这两个寄存器只读。其中Revision ID寄存器记载PCI设备的版本号。该寄存器可以被认为是Device ID的寄存器的扩展。Class Code寄存器记载PCI设备的分类,该寄存器由三个字段组成,分别是Base Class Code、Sub Class Code和Interface。其中Base Class Code讲PCI设备分类为显卡、网卡、PCI桥等设备;Sub Class Code对这些设备进一步细分。Interface定义编程接口。除此之外硬件逻辑设计也需要使用寄存器识别不同的设备。当Base Class Code寄存器为0x06,Sub Class Code寄存器为0x04时,表示当前PCI设备为一个标准的PCI桥。
(3)Header Type寄存器
该寄存器只读,由8位组成。
第7位为1表示当前PCI设备是多功能设备,为0表示为单功能设备
第0~6位表示当前配置空间的类型,为0表示该设备使用PCI Agent设备的配置空间,普通PCI设备都是用这种配置头;为1表示使用PCI桥的配置空间,PCI桥使用这种配置头。系统软件需要使用该寄存器区分不同类型的PCI配置空间。
(4)Cache Line Size寄存器
该寄存器记录处理器使用的Cache行长度。在PCI总线中和cache相关的总线事务,如存储器写无效等需要使用这个寄存器。该寄存器由系统软件设置,硬件逻辑使用。
(5)Expansion ROM base address寄存器
有些PCI设备在处理器还没有运行操作系统前,就需要完成基本的初始化。为了实现这个"预先执行"功能,PCI设备需要提供一段ROM程序,而处理器在初始化过程中将运行这段ROM程序,初始化这些PCI设备。Expansion ROM base address寄存器记载这段ROM程序的基地址。
(6)Capabilities Pointer寄存器
在PCI设备中,该寄存器是可选的,但是在PCIe设备中必须支持这个寄存器,Capabilities Pointer寄存器存放Capabilitise寄存器组的基地址,利用Capabilities寄存器组存放一些与PCI设备相关的扩展配置信息。
(7)Base Address Register 0~5寄存器
该组寄存器简称为BAR寄存器,BAR寄存器保存PCI设备使用的地址空间的基地址,该基地址保存的是该设备在PCI总线域中的地址。在PCI设备复位之后,该寄存器存放PCI设备需要使用的基址空间大小,这段空间是I/O空间还是存储器空间。系统软件可以使用该寄存器,获取PCI设备使用的BAR空间的长度,其方法是向BAR寄存器写入0xFFFFFFFF,之后在读取该寄存器。
PCIe扩展了配置空间大小,最大支持到4K。其中:
1) 0 - 3Fh 是基本配置空间,PCI和PCIe都支持
2) PCI Express Capability Structure ,PCI可选支持,PCIe支持
3) PCI Express Extended Capability Structure,PCI不支持,PCIe支持
利用IO的访问方式只能访问256Byte空间,所以为了访问4K Byte,支持通过mmio的方式访问配置空间,但是为了兼容性,保留了I/O访问方式。
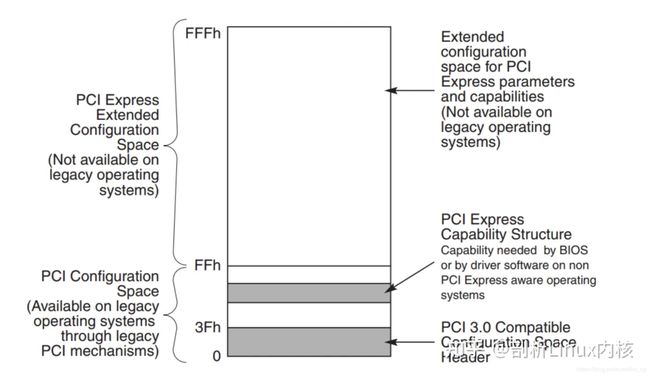

PCI和PCIe区别
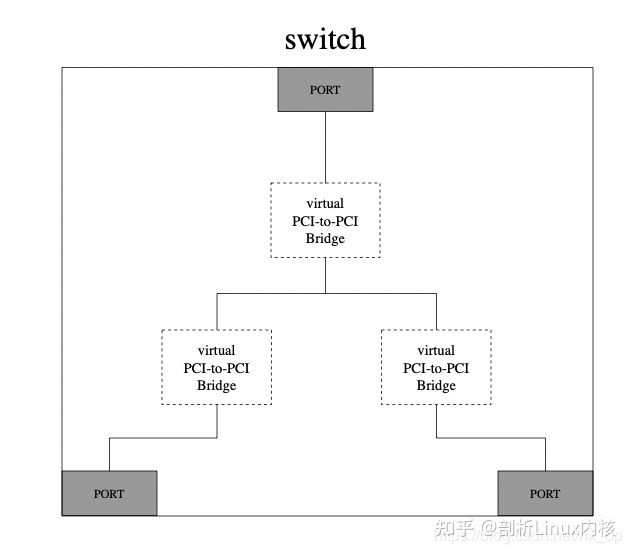
先分别看下基于pci总线和pcie总线的拓扑图:
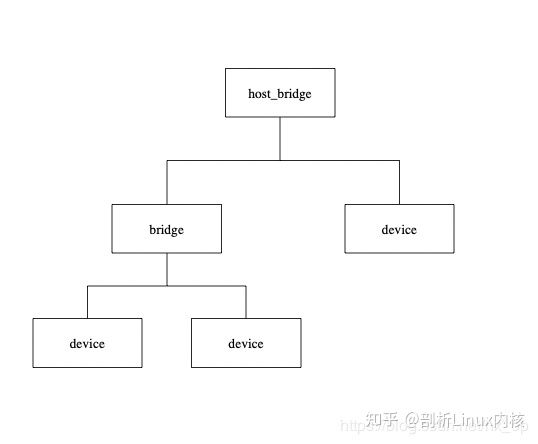
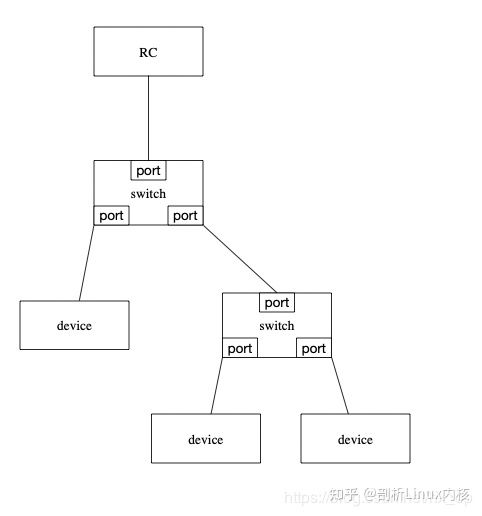
PCIe与PCI两者在电器特性上差别很大,这里不做主要阐述。两类总线拓扑结构上的主要变化就是PCIe支持端到端的连接,无法像PCI一样,在一条总线上挂接多个设备或桥。PCIe在软件上是兼容PCI总线的,对于这两种总线的拓扑结构是有一定的转换关系的:
对于PCIe的RC等价于PCI中的Host Bridge
device都是相同的
对于Bridge和switch的转换关系如下图
一、IOMMU
1、IOMMU功能简介
IOMMU主要功能包括DMA Remapping和Interrupt Remapping,这里主要讲解DMA Remapping,Interrupt Remapping会独立讲解。对于DMA Remapping,IOMMU与MMU类似。IOMMU可以将一个设备访问地址转换为存储器地址,下图针对有无IOMMU情况说明IOMMU作用。
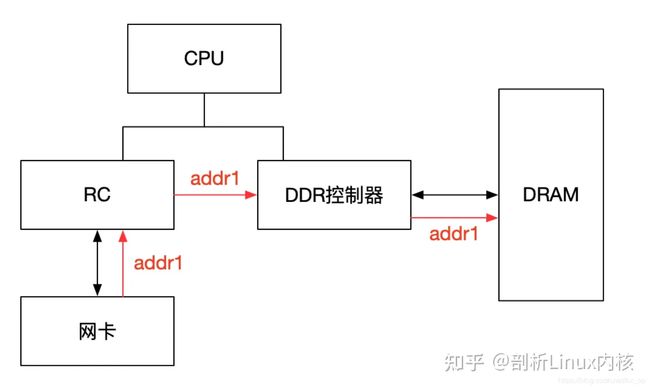
在没有IOMMU的情况下,网卡接收数据时地址转换流程,RC会将网卡请求写入地址addr1直接发送到DDR控制器,然后访问DRAM上的addr1地址,这里的RC对网卡请求地址不做任何转换,网卡访问的地址必须是物理地址。

对于有IOMMU的情况,网卡请求写入地址addr1会被IOMMU转换为addr2,然后发送到DDR控制器,最终访问的是DRAM上addr2地址,网卡访问的地址addr1会被IOMMU转换成真正的物理地址addr2,这里可以将addr1理解为虚机地址。
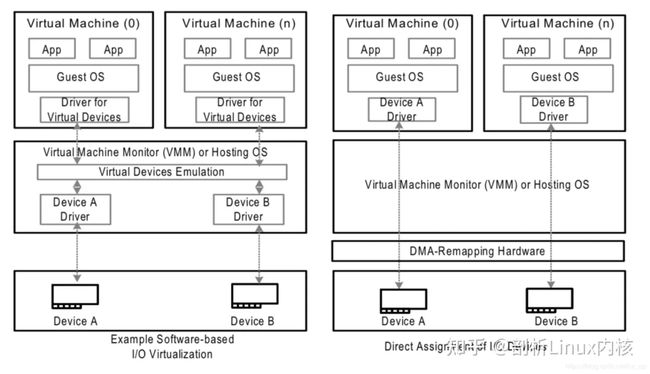
左图是没有IOMMU的情况,对于此种情况虚机无法实现设备的透传,原因主要有两个:一是因为在没有IOMMU的情况下,设备必须访问真实的物理地址HPA,而虚机可见的是GPA;二是如果让虚机填入真正的HPA,那样的话相当于虚机可以直接访问物理地址,会有安全隐患。所以针对没有IOMMU的情况,不能用透传的方式,对于设备的直接访问都会有VMM接管,这样就不会对虚机暴露HPA。
右图是有IOMMU的情况,虚机可以将GPA直接写入到设备,当设备进行DMA传输时,设备请求地址GPA由IOMMU转换为HPA(硬件自动完成),进而DMA操作真实的物理空间。IOMMU的映射关系是由VMM维护的,HPA对虚机不可见,保障了安全问题,利用IOMMU可实现设备的透传。这里先留一个问题,既然IOMMU可以将设备访问地址映射成真实的物理地址,那么对于右图中的Device A和Device B,IOMMU必须保证两个设备映射后的物理空间不能存在交集,否则两个虚机可以相互干扰,这和IOMMU的映射原理有关,后面会详细介绍。
2、IOMMU作用
根据上一节内容,总结IOMMU主要作用如下:
l 屏蔽物理地址,起到保护作用。典型应用包括两个:一是实现用户态驱动,由于IOMMU的映射功能,使HPA对用户空间不可见,在vfio部分还会举例。二是将设备透传给虚机,使HPA对虚机不可见,并将GPA映射为HPA。
l IOMMU可以将连续的虚拟地址映射到不连续的多个物理内存片段,这部分功能于MMU类似,对于没有IOMMU的情况,设备访问的物理空间必须是连续的,IOMMU可有效的解决这个问题。
3、IOMMU工作原理
前面简单介绍了IOMMU的映射功能,下面讲述IOMMU到底如何实现映射的,为便于分析,这里先不考虑虚拟化的场景,以下图为例,阐述工作原理。

IOMMU的主要功能就是完成映射,类比MMU利用页表实现VA->PA的映射,IOMMU也需要用到页表,那么下一个问题就是如何找到页表。在设备发起DMA请求时,会将自己的Source Identifier(包含Bus、Device、Func)包含在请求中,IOMMU根据这个标识,以RTADDR_REG指向空间为基地址,然后利用Bus、Device、Func在Context Table中找到对应的Context Entry,即页表首地址,然后利用页表即可将设备请求的虚拟地址翻译成物理地址。这里做以下说明:
图中红线的部门,是两个Context Entry指向了同一个页表。这种情况在虚拟化场景中的典型用法就是这两个Context Entry对应的不同PCIe设备属于同一个虚机,那样IOMMU在将GPA->HPA过程中要遵循同一规则;
由图中可知,每个具有Source Identifier(包含Bus、Device、Func)的设备都会具有一个Context Entry。如果不这样做,所有设备共用同一个页表,隶属于不同虚机的不同GPA就会翻译成相同HPA,会产生问题。
有了页表之后,就可以按照MMU那样进行地址映射工作了,这里也支持不同页大小的映射,包括4KB、2MB、1GB,不同页大小对应的级数也不同,下图以4KB页大小为例说明,映射过程和MMU类似,不再详细阐述。
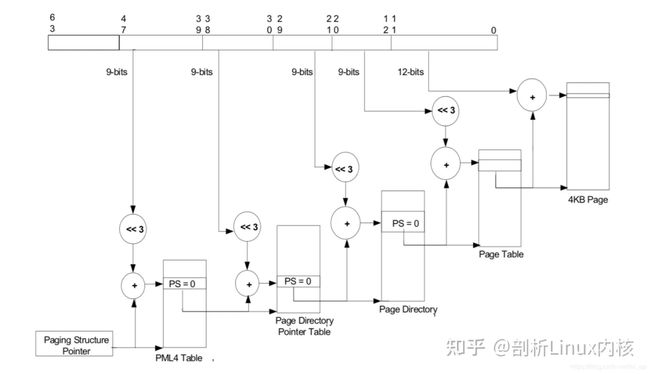
4、Source Identifier
在讲述IOMMU的工作原理时,讲到了设备利用自己的Source Identifier(包含Bus、Device、Func)来找到页表项来完成地址映射,不过存在下面几个特殊情况需要考虑。
l 对于由PCIe switch扩展出的PCI桥及桥下设备,在发送DMA请求时,Source Identifier是PCIe switch的,这样的话该PCI桥及桥下所有设备都会使用PCIe switch的Source Identifier去定位Context Entry,找到的页表也是同一个,如果将这个PCI桥下的不同设备分给不同虚机,由于会使用同一份页表,这样会产生问题,针对这种情况,当前PCI桥及桥下的所有设备必须分配给同一个虚机,这就是VFIO中组的概念,下面会再讲到。
l 对于SRIO-V,之前介绍过VF的Bus及devfn的计算方法,所以不同VF会有不同的Source Identifier,映射到不同虚机也是没有问题的。
二、VFIO
VFIO就是内核针对IOMMU提供的软件框架,支持DMA Remapping和Interrupt Remapping,这里只讲DMA Remapping。VFIO利用IOMMU这个特性,可以屏蔽物理地址对上层的可见性,可以用来开发用户态驱动,也可以实现设备透传。
1、概念介绍
先介绍VFIO中的几个重要概念,主要包括Group和Container。
1) Group:group 是IOMMU能够进行DMA隔离的最小硬件单元,一个group内可能只有一个device,也可能有多个device,这取决于物理平台上硬件的IOMMU拓扑结构。 设备直通的时候一个group里面的设备必须都直通给一个虚拟机。 不能够让一个group里的多个device分别从属于2个不同的VM,也不允许部分device在host上而另一部分被分配到guest里, 因为就这样一个guest中的device可以利用DMA攻击获取另外一个guest里的数据,就无法做到物理上的DMA隔离。
2) Container:对于虚机,Container 这里可以简单理解为一个VM Domain的物理内存空间。对于用户态驱动,Container可以是多个Group的集合。
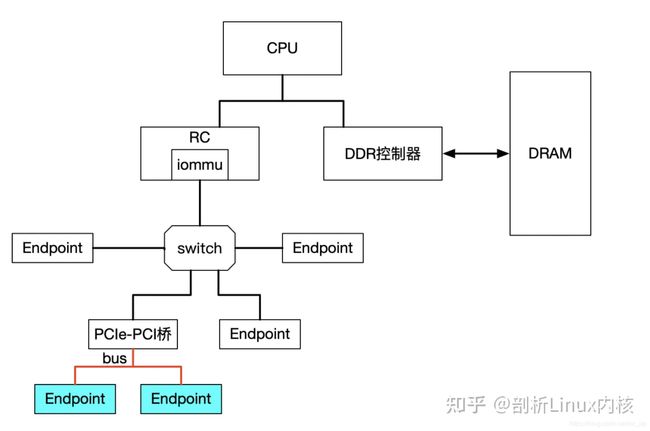
上图中PCIe-PCI桥下的两个设备,在发送DMA请求时,PCIe-PCI桥会为下面两个设备生成Source Identifier,其中Bus域为红色总线号bus,device和func域为0。这样的话,PCIe-PCI桥下的两个设备会找到同一个Context Entry和同一份页表,所以这两个设备不能分别给两个虚机使用,这两个设备就属于一个Group。
2、使用示例
这里先以简单的用户态驱动为例,在设备透传小节中,在分析如何利用vfio实现透传。
int container, group, device, i;
struct vfio_group_status group_status =
{ .argsz = sizeof(group_status) };
struct vfio_iommu_type1_info iommu_info = { .argsz = sizeof(iommu_info) };
struct vfio_iommu_type1_dma_map dma_map = { .argsz = sizeof(dma_map) };
struct vfio_device_info device_info = { .argsz = sizeof(device_info) };
/* Create a new container */
container = open("/dev/vfio/vfio", O_RDWR);
if (ioctl(container, VFIO_GET_API_VERSION) != VFIO_API_VERSION)
/* Unknown API version */
if (!ioctl(container, VFIO_CHECK_EXTENSION, VFIO_TYPE1_IOMMU))
/* Doesn't support the IOMMU driver we want. */
/* Open the group */
group = open("/dev/vfio/26", O_RDWR);
/* Test the group is viable and available */
ioctl(group, VFIO_GROUP_GET_STATUS, &group_status);
if (!(group_status.flags & VFIO_GROUP_FLAGS_VIABLE))
/* Group is not viable (ie, not all devices bound for vfio) */
/* Add the group to the container */
ioctl(group, VFIO_GROUP_SET_CONTAINER, &container);
/* Enable the IOMMU model we want */ // type 1 open | attatch
ioctl(container, VFIO_SET_IOMMU, VFIO_TYPE1_IOMMU);
/* Get addition IOMMU info */
ioctl(container, VFIO_IOMMU_GET_INFO, &iommu_info);
/* Allocate some space and setup a DMA mapping */
dma_map.vaddr = mmap(0, 1024 * 1024, PROT_READ | PROT_WRITE,
MAP_PRIVATE | MAP_ANONYMOUS, 0, 0);
dma_map.size = 1024 * 1024;
dma_map.iova = 0; /* 1MB starting at 0x0 from device view */
dma_map.flags = VFIO_DMA_MAP_FLAG_READ | VFIO_DMA_MAP_FLAG_WRITE;
ioctl(container, VFIO_IOMMU_MAP_DMA, &dma_map);
/* Get a file descriptor for the device */
device = ioctl(group, VFIO_GROUP_GET_DEVICE_FD, "0000:06:0d.0");
/* Test and setup the device */
ioctl(device, VFIO_DEVICE_GET_INFO, &device_info);
对于dev下Group就是按照上一节介绍的Group划分规则产生的,上述代码描述了如何使用VFIO实现映射,对于Group和Container的相关操作这里不做过多解释,主要关注如何完成映射,下图解释具体工作流程。
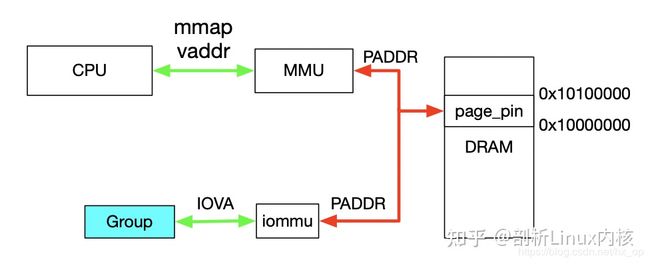
首先,利用mmap映射出1MB字节的虚拟空间,因为物理地址对于用户态不可见,只能通过虚拟地址访问物理空间。然后执行ioctl的VFIO_IOMMU_MAP_DMA命令,传入参数主要包含vaddr及iova,其中iova代表的是设备发起DMA请求时要访问的地址,也就是IOMMU映射前的地址,vaddr就是mmap的地址。VFIO_IOMMU_MAP_DMA命令会为虚拟地址vaddr找到物理页并pin住(因为设备DMA是异步的,随时可能发生,物理页面不能交换出去),然后找到Group对应的Contex Entry,建立页表项,页表项能够将iova地址映射成上面pin住的物理页对应的物理地址上去,这样对用户态程序完全屏蔽了物理地址,实现了用户空间驱动。IOVA地址的0 - 0x100000对应DRAM地址0x10000000 - 0x10100000,size为1024 * 1024。一句话概述,VFIO_IOMMU_MAP_DMA这个命令就是将iova通过IOMMU映射到vaddr对应的物理地址上去。
3、设备透传分析
设备透传就是由虚机直接接管设备,虚机可以直接访问MMIO空间,VMM配置好IOMMU之后,设备DMA读写请求也无需VMM借入,需要注意的是设备的配置空间没有透传,因为VMM已经配置好了BAR空间,如果将这部分空间也透传给虚机,虚机会对BAR空间再次配置,会导致设备无法正常工作。
4、虚机地址映射
在介绍透传之前,先看下虚机的GPA与HVA和HPA的关系,以及虚机是如何访问到真实的物理地址的,过程如下图。
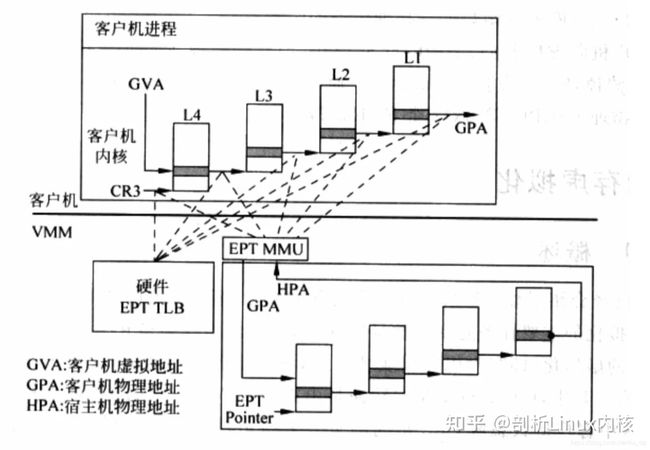
一旦页表建立好后,整个映射过程都是硬件自动完成的,对于上图有如下几点说明:
1) 对于虚机内的页表,完成GVA到GPA的映射,虽然整个过程都是硬件自动完成,但有一点要注意下,在虚机的中各级页表也是存储在HPA中的,而CR3及各级页表中装的地址都是GPA,所以在访问页表时也需要借助EPT,上图中以虚线表示这个过程;
2) 利用虚机页表完成GVA到GPA的映射后,此时借助EPT实现GPA到HPA的映射,这里没有什么特殊的,就是一层层页表映射;
3) 看完上图,有没有发现少了点啥,是不是没有HVA。单从上图整个虚机寻址的映射过程来看,是不需要HVA借助的,硬件会自动完成GVA->GPA->HPA映射,那么HVA有什么用呢?这里从下面两方面来分析:1)Qemu利用iotcl控制KVM实现EPT的映射,映射的过程中必然要申请物理页面。Qemu是应用程序,唯一可见的只是HVA,这时候又需要借助mmap了,Qemu会根据虚机的ram大小,即GPA大小范围,然后mmap出与之对应的大小,即HVA。通过KVM_SET_USER_MEMORY_REGION命令控制KVM,与这个命令一起传入的参数主要包括两个值,guest_phys_addr代表虚机GPA地址起始,userspace_addr代表上面mmap得到的首地址(HVA)。传入进去后,KVM就会为当前虚机GPA建立EPT映射表实现GPA->HPA,同时会为VMM建立HVA->HPA映射。2)当vm_exit发生时,VMM需要对异常进行处理,异常发生时VMM能够获取到GPA,有时VMM需要访问虚机GPA对应的HPA,VMM的映射和虚机的映射方式不同,是通过VMM完成HVA->HPA,且只能通过HVA才能访问HPA,这就需要VMM将GPA及HVA的对应关系维护起来,这个关系是Qemu维护的,这里先不管Qemu的具体实现(后面会有专门文档介绍),当前只需要知道给定一个虚机的GPA,虚机就能获取到GPA对应的HVA。下图描述VMM与VM的地址映射关系。

5、设备透传实现
在前面介绍VFIO的使用实例时,核心思想就是IOVA经过IOMMU映射出的物理地址与HVA经过MMU映射出的物理地址是同一个。对于设备透传的情况,先上图,然后看图说话。
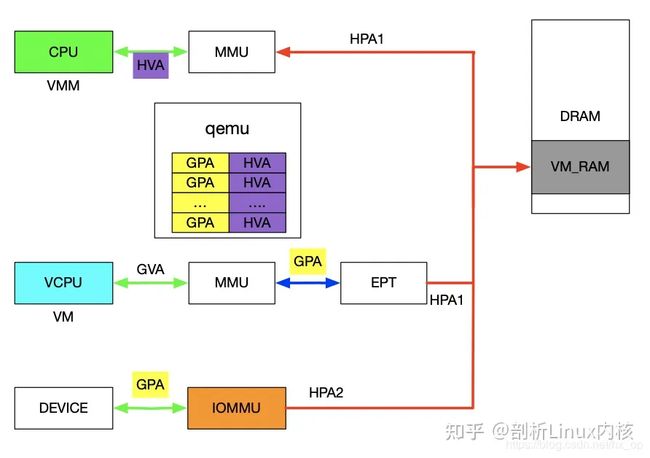
先来分析一下设备的DMA透传的工作流程,一旦设备透传给了虚机,虚机在配置设备DMA时直接使用GPA。此时GPA经由EPT会映射成HPA1,GPA经由IOMMU映射的地址为HPA2,此时的HPA1和HPA2必须相等,设备的透传才有意义。下面介绍在配置IOMMU时如何保证HPA1和HPA2相等,在VFIO章节讲到了VFIO_IOMMU_MAP_DMA这个命令就是将iova通过IOMMU映射到vaddr对应的物理地址上去。对于IOMMU来讲,此时的GPA就是iova,我们知道GPA经由EPT会映射为HPA1,对于VMM来讲,这个HPA1对应的虚机地址为HVA,那样的话在传入VFIO_IOMMU_MAP_DMA命令时讲hva作为vaddr,IOMMU就会将GPA映射为HVA对应的物理地址及HPA1,即HPA1和HPA2相等。上述流程帮助理清整个映射关系,实际映射IOMMU的操作很简单,前面提到了qemu维护了GPA和HVA的关系,在映射IOMMU的时候也可以派上用场。注:IOMMU的映射在虚机启动时就已经建立好了,映射要涵盖整个GPA地址范围,同时虚机的HPA对应的物理页都不会交换出去(设备DMA交换是异步的)。
6、VFIO PassThrough
这里以PCI设备为例讲述VFIO PassThrough具体实现(VFIO不仅仅支持PCI设备)。对于一个透传给虚机的PCI设备,主要处理config空间透传、BAR空间透传和中断三方面,下面分别讲述如何实现这两方面的透传。
6、config空间透传实现
对于config空间,或者是模拟,或者是透传,具体行为由qemu和vfio两个模块共同决定。qemu中可以有选择的进行模拟,在qemu不模拟的情况下调用vfio提供的io操作对设备进行读写,然后再由vfio决定是否模拟。整体软件实现框图如下:
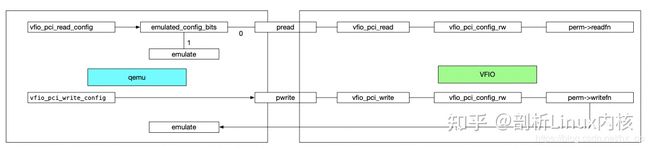
7、qemu实现
当虚机访问透传设备的config空间时,触发vm_exit,然后qemu会调用被访问设备的vfio_pci_read_config或vfio_pci_write_config操作。对于读操作,会查看当前读取的config空间是否被qemu模拟,如果模拟,则直接读取qemu中保存的config值,否则调用vfio提供的read接口进行读取。对于写操作,会直接调用vfio提供的write接口,对于不可写的操作在vfio中会有屏蔽。然后在回到qemu中,更新qemu模拟位状态。qemu处在用户态,必须经由vfio完成与物理设备的交互。目前qemu中模拟的比较重要的就是msi相关的。
8、vfio实现
对于vfio的读写最终会调用perm->readfn或perm->writefn,对于这两个操作的实质就是或者模拟config空间,或者透传config空间。对于每一个cap都定了一个perm选项,其中说明了哪些属性需要模拟,是否可写等。如果可写,且不模拟,则直接透传到物理pci设备上去,否则进行模拟。以cap_perms[PCI_CAP_ID_EXP]为例,对于PCI_EXP_DEVCTL_BCR_FLR、PCI_EXP_DEVCTL_PAYLOAD、PCI_EXP_DEVCTL_READRQ是需要模拟的,这里又分为两种情况,对于PCI_EXP_DEVCTL_BCR_FLR和PCI_EXP_DEVCTL_READRQ这种,软件进行了模拟,但是确没有满足虚机的需求,所以在vfio_exp_config_write中会执行对物理设备的操作(这里对物理设备进行了操作,但是却没有直接将config透传,是因为对物理设备操作前还需要进行检查)。对于PCI_EXP_DEVCTL_PAYLOAD,因为这个属性和物理机的pci拓扑相关,如果按照虚机拓扑对物理设备修改了就会出现问题,所以这个字段需要模拟,并且不需要物理设备有任何响应。
9、BAR空间透传
在qemu中,vfio_map_bars函数会调用vfio提供的vfio_pci_mmap,进而将透传pci设备的bar地址空间(HPA)映射出的HVA返回给qemu,在虚机内部,也会对pci设备枚举并初始化bar空间,这个初始化的值就是GPA,将这个GPA与上面的HPA建立EPT映射,即可完成BAR空间的透传,不过这里需要注意下:对于支持MSI-X的设备,由于MSI-X的table表会存在于bar地址空间中,而MSI-X的配置不能直接给虚机,否则虚机可以通过配置这个中断影响物理机,所以在对bar空间做透传时要除掉MSI-X table占用的bar空间。
Q:HVA与GPA啥时建立关系的
A:虚机写入pci设备bar空间时,这个写入地址为GPA,此时将这个GPA与真实物理设备的BAR地址建立映射关系。
10、vfio中断实现
目前内核使用的是Posted Interrupt方式,对于Posted Interrupt具体实现见Posted Interrupt。以MSI中断为例,当虚机内部为透传设备配置中断时,会触发vm_exit,这时会调用qemu中vfio_pci_write_config->vfio_msi_enable,在vfio_msi_enable中,主要做了两件事:
vfio_add_kvm_msi_virq向KVM中注入监听事件,当虚机写入MSI配置空间时,可以获取到MSI message(包括addredd和data,data中包含了设备在虚机内部使用的中断号),在向KVM注入事件时需要传入虚机内部使用的中断号,这个中断号在Posted Interrupt时会使用。
vfio_enable_vectors利用vfio提供的VFIO_DEVICE_SET_IRQS命令为透传设备申请真正的中断,因为中断相关的配置都不允许虚机直接访问,必须借助VFIO提供的IO接口实现。此时,会在物理机内申请中断,中断服务程序在VFIO内实现,服务程序主要激活步骤1中的监听事件,然后再调用Posted Interrupt。
整个中断初始化和触发流程如下:
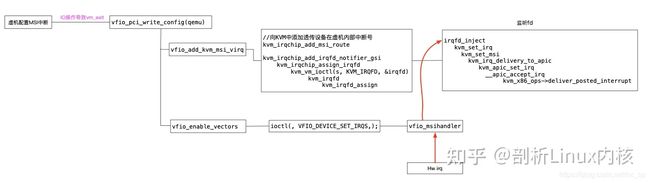
当透传设备产生中断时,vfio_msihandler ISR执行,该函数不做实际的服务程序处理,仅仅通过eventfd_signal激活irqfd_inject,然后最终调用deliver_posted_interrupt向虚机注入中断,中断号即为虚机配置透传设备时的中断号。
11、透传设备具体实现
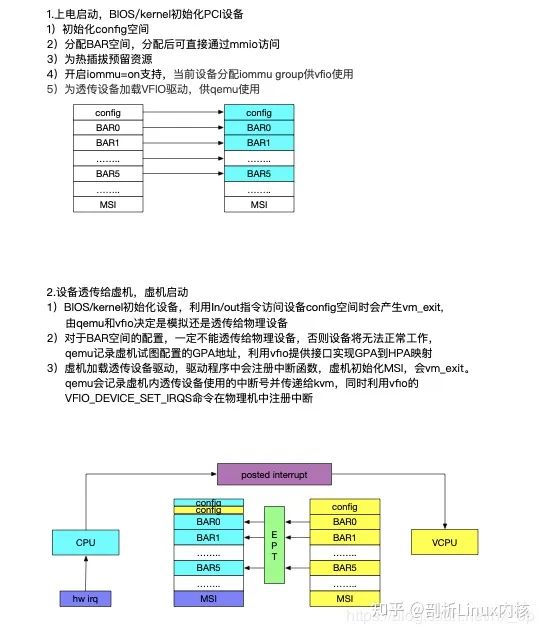
下面从一个物理机启动->虚机启动整个过程描述设备如何透传到虚机,并正常工作的,以昆仑MPW卡为例。
step 1,物理机启动,BIOS完成PCI设备的配置,包括初始化config空间,分配BAR地址空间
step 2,由于内核开启IOMMU支持,会为当前设备分配iommu group
step 3,加载vfio驱动,并与mpw卡关联
step 4,qemu启动虚机,并将mpw卡设备透传给虚机
step 5,前面4个步骤中不涉及虚机,纯粹的物理机操作。当虚机启动后(假设虚机运行linux内核),会根据qemu构建的虚机PCI拓扑为pci设备初始化,包括配置config空间、分配BAR地址空间,这里过程与step1类似,但是行为差别很大。这里说明一下,对于透传设备、virtio设备等,不同的设备实现也不同,这里仅讲述对于透传设备的实现
step 6,当虚机配置mpw卡的config空间时,会用到in、out系列IO指令,这样会造成虚机的vm_exit,qemu中可以截获这个行为,并选择是采取模拟的方式还是利用vfio提供的io接口实现,详细过程见第1节。这里有两个特殊处理,一个是BAR空间的配置,一个是中断的配置
Step 7, 首先透传的优势是高效,在虚机使用设备时,触发vm_exit的情况越少越好,但是又不能放给虚机过大权限,否则会影响到物理机,比如一些特殊的config寄存器,如Max Payload,中断等。在虚机利用in、out指令时会vm_exit,这个影响不大,目前大部分PCI设备的BAR空间都是采用MMIO的方式访问,当设备正常工作时,大部分采用的是mmio的方式。所以要尽可能的保证在mmio访问时,不会vm_exit。也就是将BAR空间透传给虚机,根据EPT映射关系,如果物理机建立好了GPA到HPA的映射,就不会vm_exit,以此来提供效率。先来说HPA,HPA即为物理机在step1中为mpw卡分配的bar地址。GPA为step5-6中,虚机为透传设备分配的BAR空间,在step6中,已经记录了虚机对BAR空间的配置,所以也可以获取到GPA,有了HPA和GPA,建立EPT映射就可以实现BAR地址空间的透传。不过有一种情况需要特殊考虑,就是MSI-X。因为MSI-X的table会放在BAR空间上,而虚机是不允许直接访问中断相关配置的,所以对于MSI-X table的相关BAR空间是不允许直接透传给虚机的
step 8,以使用MSI中断的情况为例,当虚拟配置透传设备的MSI相关寄存器时,会vm_exit。qemu会记录虚机内透传设备使用的中断号并传递给kvm,同时利用vfio的VFIO_DEVICE_SET_IRQS命令在物理机中注册中断,当硬件设备产生中断时,首先物理机会执行服务程序,服务程序主要工作是发送eventfd_signal,激活kvm中的irqfd_inject,最终调用deliver_posted_interrupt向虚机注入中断,祥见第3节。
通过以上步骤,虚机可以访问设备的config空间(模拟或直接访问物理设备),可以访问BAR空间(除MSI-X table外都可透传),中断(利用vfio VFIO_DEVICE_SET_IRQS、kvm协同实现)。
https://zhuanlan.zhihu.com/p/550698319