【数据库】Apache Doris : 一个开源 MPP 数据库的架构与实践
文章目录
- Doris 背景介绍
-
- 一、Doris
- 二、Doris 定位
- 适用场景 & 案例介绍
-
- 一、适用场景
- 二、具体案例
- Doris 整体架构
-
- 一、Doris 整体架构
- 二、Doris 数据分布
- 三、Doris 的使用方式
- Doris 关键技术
-
- 一、数据可靠性
- 二、易运维
- 三、MySQL 兼容性
- 四、支持 MPP
- Doris 数据模型
-
- 一、Doris 数据模型特点
- 二、聚合计算说明:
- 三、按列存储
- 四、物化视图
- 五、两层分区与分级存储
- 六、Doris 在 Elasticsearch 的应用
- 七、Kafka 消息队列加载
- 八、Doris 其他特性
Doris 背景介绍
介绍 Doris,读音:[ˈdɔrɪs],的整体架构,以及 Doris 的一些特性。
一、Doris
Doris 是分布式、面向交互式查询的分布式数据库,主要部分是 SQL,内部用到 MPP 技术。
什么是 MPP?
MPP ( Massively Parallel Processing ),即大规模并行处理,在数据库非共享集群中,每个节点都有独立的磁盘存储系统和内存系统,业务数据根据数据库模型和应用特点划分到各个节点上,每台数据节点通过专用网络或者商业通用网络互相连接,彼此协同计算,作为整体提供数据库服务。非共享数据库集群有完全的可伸缩性、高可用、高性能、优秀的性价比、资源共享等优势。简单来说,MPP 是将任务并行的分散到多个服务器和节点上,在每个节点上计算完成后,将各自部分的结果汇总在一起得到最终的结果 ( 与 Hadoop 相似 )。
Doris 主要解决 PB 级别的数据量(如果高于 PB 级别,不推荐使用 Doris 解决,可以考虑用 Hive 等工具),解决结构化数据,查询时间一般在秒级或毫秒级。
Doris 由百度大数据部研发 ( 之前叫百度 Palo,2018年贡献到 Apache 社区后,更名为 Doris ),在百度内部,有超过200个产品线在使用,部署机器超过1000台,单一业务最大可达到上百 TB。
百度将 Doris 贡献给 Apache 社区之后,许多外部用户也成为了 Doris 的使用者,例如新浪微博,美团,小米等著名企业。
二、Doris 定位
在数据分析处理框架中,Doris 主要做的是 Online 层面的数据服务,主要处理的是数据分析方面的服务。

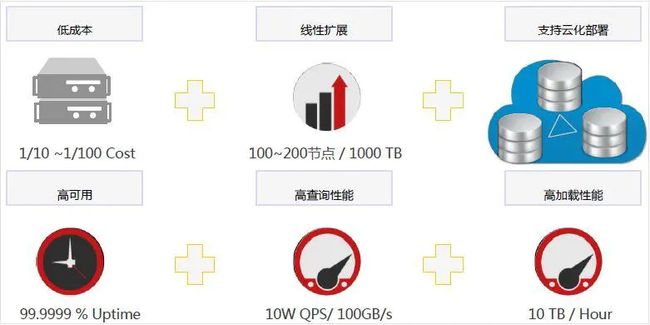
Doris 的目标是:实现低成本(主要针对商业产品),可线性扩展,支持云化部署,高可用,高查询性能,高加载性能。
简要介绍两个百度内部业务中 Doris 的应用案例:
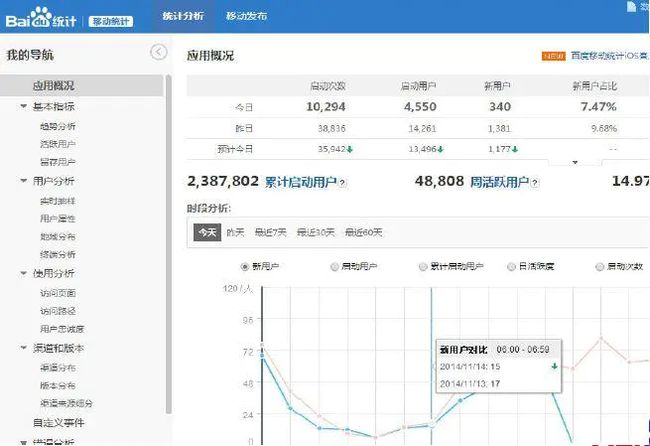
A. 百度统计在线报表
B. 百度另一内部业务的多维分析
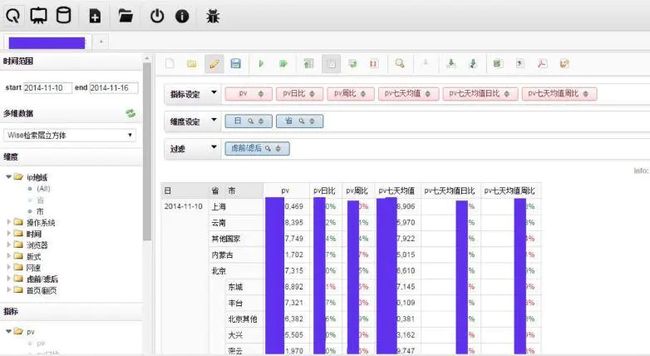
可以手动拖拽维度、指标等,进行查询。
适用场景 & 案例介绍
一、适用场景
1、对数据分析、统计
数据分析大体上可以分为两大类场景:一种偏向于报表类的,另一种偏向于多维分析的。
2、报表
报表类数据分析,数据分析以及查询的模式相对比较固定,而且后台 SQL 的模式往往都是确定的。针对此类应用场景,选择使用 MySQL 存结果数据,用户可从界面选择执行批处理以及发送邮件。在 Doris 平台中,报表类查询时延一般在秒级以下。
3、多维分析
这里提到的多维分析,同样要求数据是结构化的,适用于查询相对灵活的场景,例如数据分析条件以及聚合维度等方面不是很确定,一般将此类数据分析定义为多维分析。相对于报表类分析,多维分析的查询时延会稍慢,大约在会在 10s 的级别。
二、具体案例
案例分析 1:百度统计
百度统计,为网站站长提供流量分析,网站分析,受众分析等多种分析服务。服务网站数量超过 450W,每天查询量达到 1500W,QPS ( Queries Per Second,每秒查询率 ) 峰值超过1400,每日新增数据量超过 2TB;数据导入频次为5分钟,平均查询时延 30ms。
案例分析 2:百度云系统
1、百度云交易系统
百度云交易系统,主要提供订单、账单、扣费、交易流水等 TB 级别量数据的存储和实时查询服务,数据量约 12TB,每5分钟导入。
2、百度云数据中心
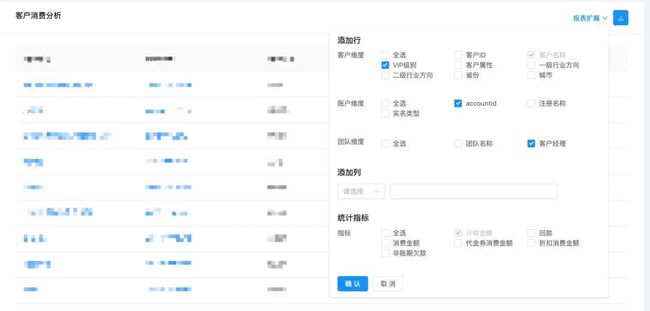
百度云数据中心,主要提供百度云经营分析,产品分析,用户分析等多种分析服务;提供多维度(100+)分析,具备高性能 ( 秒级 ) BI 能力;百度云数据中心的日处理数据量约 1T ( 略少于百度统计,因此查询效率略高于百度统计 ),分钟级导入。以下是百度云数据中心页面的一个截图:
Doris 整体架构
一、Doris 整体架构
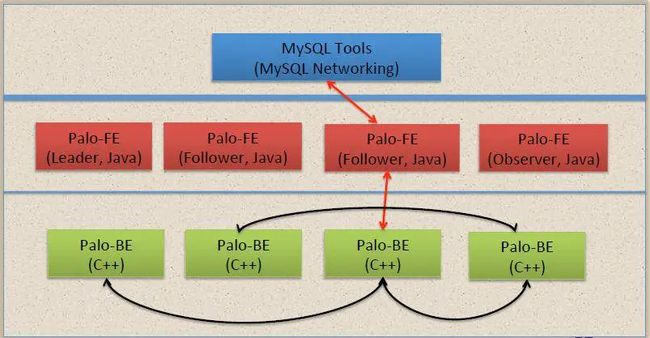
Doris 的整体架构和 TiDB 类似,借助 MySQL 协议,用户使用任意 MySQL 的 ODBC/JDBC以及MySQL 的客户端,都可以直接访问 Doris。Doris 中的模块包括 FE 和 BE 两类:FE 主要负责元数据的管理、存储,以及查询的解析等;一个用户请求经过 FE 解析、规划后,具体的执行计划会发送给 BE,BE 则会完成查询的具体执行。BE 节点主要负责数据的存储、以及查询计划的执行。目前平台的 FE 部分主要使用 Java,BE 部分主要使用 C++。
二、Doris 数据分布
如果从表的角度来看数据结构,用户的一张 Table 会拆成多个 Tablet,Tablet 会存成多副本,存储在不同的 BE 中,从而保证数据的高可用和高可靠。

三、Doris 的使用方式
Doris 的使用方式和 MySQL 类似,创建 database,创建 table,导入数据、执行查询等。具体详见下图:

Doris 关键技术
一、数据可靠性
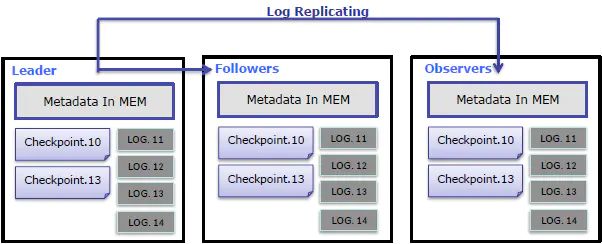
1、元数据使用 Memory+Checkpoint+Journal ( 分别是什么?),使用 BTBJE ( 类似于 Raft ) 协议实现高可用性和高可靠性。
2、Doris 内部自行管理数据的多副本和自动修复。保证数据的高可用、高可靠。在服务器宕机的情况下,服务依然可用,数据也不会丢失。
二、易运维
无外部依赖:
Doris 部署无外部依赖,只需要部署 BE 和 IBE 即可搭建起一个集群。
支持 Online Schema Change
支持在线更改表模式 ( 加减列,创建 Rollup ),不会影响当前服务,不会阻塞读、写等操作;这种执行是异步的 ( 用户不需要一直盯在那里 )
数据库同步操作和异步操作:
同步,是所有的操作都做完,才返回给用户结果;即写完数据库之后,再响应用户,用户体验不好;
异步,不用等所有操作等做完,就相应用户请求;即先相应用户请求,然后慢慢去写数据库,用户体验较好。缓存机制(也就是消息队列),就是异步操作的一个典型应用。
1、副本自动均衡
传统数据库的扩(缩)容比较麻烦,有时甚至需要重做数据;而 Doris 数据库只需要一条 SQL ( 无须额外操作 ) 即可实现扩(缩)容。
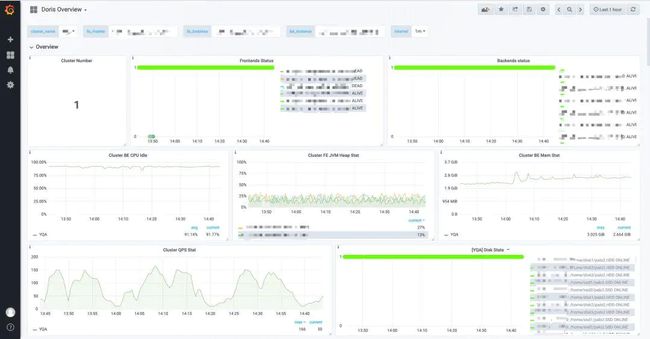
2、内置监控
使用 Prometheus、Grafana 将监控项指标列出。
下图为 Doris 默认配置面板:
三、MySQL 兼容性
MySQL 的兼容性从两方面体现:
1、兼容 MySQL 的网络协议 ( MySQL Network Protocol )
2、兼容 MySQL 语法,使用 MySQL 语法可对 Doris 数据库进行查询
关于 MySQL 语法的兼容性,前文已经描述过,这里不再赘述;
关于 MySQL 的网络协议的兼容性,举个简单的例子:MySQL 的调度服务器 Proxy,可以直接用作 Doris 的 Proxy。
Doris 的前端展示,可以使用 MySQL 专属展示器 Tableu。下图就是使用 Tableu 将 Doris 数据可视化的一个范例。

Doris 与 R 语言可以实现无缝对接,用 R 语言可直接操作 Doris 数据库,进行数据分析、数据挖掘等工作。
四、支持 MPP
MPP 即 Massively Parallel Processing,大规模并行处理,即海量数据并发查询。以下图为例:
执行
SELECT k1,SUM(v1) FROM A,B WHERE A.k2=B.k2 GROUP BY k1 ORDER BY SUM(v1)
语句,该语句包含了合并、聚合计算、排序等多种操作;在执行计划的时候,MPP 将其拆分成多份,分布到每台机器执行,最后再将结果汇总。假如有10台机器,在大数据量下,这种查询执行方式可以使得查询性能达到10倍的提升。

Doris 数据模型
一、Doris 数据模型特点
1、键值对存储形式:
类似于字典搜索查询的键值对格式,Doris 中所有数据分成两列:Key 列和 Value 列。如下图所示,Time、Id、Country 列共同组成 Key 列,Clicks、Cost 列为 Value 列。Key 列有序可进行快速查找,Value 列可以按照具体聚合类型内部完成数据聚合。
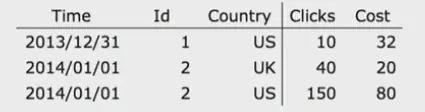
2、Key 列全局有序排列,查询时方便快速定位查找。
Doris 数据模型的一个显著特点是 Key 列全局唯一,因此存在相同 Key 值的不同 Value,则后面的数据与前面的数据自动做 ( SUM,MIN,MAX,REPLACE ) 等聚合处理。例如,下图中绿色方框中的两行,相同的 Key 值对应不同的 Value;因此,新的 Value 到达后,与前数据作 SUM 处理,得到最新的数据,不仅提升效率,还可提高数据处理的准确性。

二、聚合计算说明:
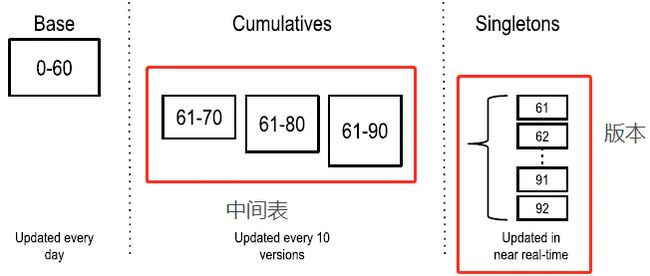
本部分具体描述相同 Key 值下 Value 值的聚合。
数据的导入是分版本的(例如下图右侧91,92版本),每一个版本之间 Key 相同的数据汇总到中间表中,通过聚合处理最终输出为左侧的 base。
三、按列存储
1、Doris 的数据是按列存储的,每一列单独存放。
2、查询时,只访问查询涉及的列,大量降低 I/O。
3、数据类型一致,方便压缩。
4、数据包建索引,数据即索引。
5、利用原始过滤条件以及 min、max 和 sum 等智能索引技术,将数据集查询范围尽可能地缩小,大大减少 I/O,提升查询效率。
四、物化视图
物化视图是提取某些维度的组合建立对用户透明的却有真实数据的视图表格。Doris 的物化视图可以保证用户在更新时,直接更新原始表,Doris 会保证原表、物化视图原子生效。在查询的时候用户也只需指定原始表,Doris 会根据查询的具体条件,选择适合的物化视图完成查询。
通常用户可以通过物化视图功能完成以下两种功能。
1、更换索引列进行重排列
2、针对指定列做聚合查询

五、两层分区与分级存储
两层分区:
1、方便新旧数据分离,使用不同的存储介质(例如新数据使用 SSD,历史数据 SATA)
2、分区减少了大量历史数据不必要的重复 BE/CE,节省了大量的 IO 和 CPU 开销
3、两层分区的方法简化了表的扩容,便于 shard 调整(例如,前期不必建立过多 shard,后期随着业务增长客随时调整 shard 数)
分级存储
用户可以指定数据放到 SSD 上或者 SATA 盘上,也支持根据 TTL 将冷数据从 SSD 迁移到 SATA 上,高效利用 SSD 提高查询性能。

六、Doris 在 Elasticsearch 的应用
简介:
1、ES 的优点是索引,可支持多列索引,甚至可支持全文语义索引(如 term,match,fuzzy 等);然而其缺点是没有分布式计算引擎,不支持 join 等操作
2、与 ES 相反,Palo 具备丰富的 SQL 计算能力,以及分布式查询能力;然而其索引性能较低,不支持全文索引。
3、Doris 在 ES 开发的过程中,分别借鉴 ES 和 Palo 的长处,支持了 Elasticsearch 多表 Join 操作,同时引入 Elasticsearch 的语义搜索功能,扩充了 Doris 的查询能力。
使用方式:
第一步:建立一张 ES 的外部表。

第二步:在 ES 外部表中导入一些数据:

第三步:使用和 ES 一样的搜索语句,进行全文检索查询:

类似于上图这样的搜索语句,在 SQL 中比较难以表达,但是在 ES 中较容易实现。
七、Kafka 消息队列加载
1、Doris 内部支持订阅 Kafka 数据流,实现直接对接 Kafka:

2、用户数据源经 Kafka 消息队列收集后,可以依次进入到 Doris 中,通过 Doris 做报表展示和决策分析等工作。

3、优点
无需额外组件,用户可直接通过命令实现 Kafka 消息订阅。
精确传输,秒级延迟。
Doris 可自动感知 Kafka 中 partition 变化,合理调度并发导入。
在数据导入这一过程中,支持对 Kafka 原始数据做二次处理(如转换,过滤等)。
八、Doris 其他特性
原子性——即一批数据要么都生效,要么都不生效。
支持单机多盘
向量化执行
UDF ( User Defined Function 用户自定义函数 )
内置 HLL 类型,快速计算 UV
doris官方文档(中文版)链接