MPP分析性数据库之Doris
#### Doris介绍
Apache Doris是一个现代化的MPP分析性数据库产品。仅需要亚秒级响应时间即可获得查询结果,有效地支持实时数据分析。Apache Doris可以满足多种数据分析需求,例如固定历史报表,实时数据分析。
#### 分区
Doris支持单分区和复合分区两种建表方式。
在复合分区中:
第一级称为Partition,即分区。用户指定某一维度列做为分区列(当前只支持整型和时间类型的列),并指定每个分区的取值范围。
第二级称为Distribution,即分桶。用户可以指定一个或多个维度列以及桶数进行HASH分布。
以下场景推荐使用复合分区
1. 有时间维或类似带有有序值的维度,可以以这类维度列作为分区列。分区粒度可以根据导入频次、分区数据量等进行评估。
2. 历史数据删除需求:如有删除历史数据的需求(比如仅保留最近N天的数据)。使用复合分区,可以通过删除历史分区来达到目的。也可以通过在指定分区内发送DELETE于禁进行删除。
3. 解决数据倾斜的问题:每个分区可以单独指定分桶数量。如按天分区,当每天的数据量差异很大的时,可以通过指定分区的分桶数,合理规划不同分区的数据,分桶列建议选择区分度大的列。
用户也可以不是用复合分区,仅使用单分区。则数据只做HASH分布。
#### 创建单分区表
建立一张student表。分桶列为id,桶数为10,副本数为1。
```
CREATE TABLE student
(
id INT,
name VARCHAR(50),
age INT,
count BIGINT SUM DEFAULT '0'
)
AGGREGATE KEY (id,name,age)
DISTRIBUTED BY HASH(id) buckets 10
PROPERTIES("replication_num" = "1");
```
#### 创建复合分区表
创建student2表,使用dt字段作为分区列,并且创建3个分区发,分别是:
P202007 范围值是是小于2020-08-01的数据
P202008 范围值是2020-08-01到2020-08-31的数据
P202009 范围值是2020-09-01到2020-09-30的数据
```
CREATE TABLE student2
(
dt DATE,
id INT,
name VARCHAR(50),
age INT,
count BIGINT SUM DEFAULT '0'
)
AGGREGATE KEY (dt,id,name,age)
PARTITION BY RANGE(dt)
(
PARTITION p202007 VALUES LESS THAN ('2020-08-01'),
PARTITION p202008 VALUES LESS THAN ('2020-09-01'),
PARTITION p202009 VALUES LESS THAN ('2020-10-01')
)
DISTRIBUTED BY HASH(id) buckets 10
PROPERTIES("replication_num" = "1");
```
#### 数据模型
Doris数据模型上目前分为三种 AGGREGATE KEY, UNIQUE KEY, DUPLICATE KEY。三种模型都是按KEY进行排序
##### AGGREGATE KEY
AGGREGATE KEY相同时,新旧记录将会进行聚合操作,目前支持SUM,MIN,MAX,REPLACE。
AGGREGATE KEY模型可以提前聚合数据,适合报表和多维度业务。
1. 建表
```
CREATE TABLE site_visit
(
siteid INT,
city SMALLINT,
username VARCHAR(32),
pv BIGINT SUM DEFAULT '0'
)
AGGREGATE KEY(siteid, city, username)
DISTRIBUTED BY HASH(siteid) BUCKETS 10;
```
2. 插入2条数据
```
mysql> insert into site_visit values(1,1,'name1',10);
mysql> insert into site_visit values(1,1,'name1',20);
```
3. 查看结果
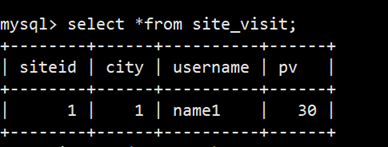
#### UNIQUE KEY
UNIQUE KEY相同时,新记录覆盖旧记录。目前UNIQUE KEY和AGGREGATE KEY的REPLACE聚合方法一致。适用于有更新需求的业务。
1. 建表
```
CREATE TABLE sales_order
(
orderid BIGINT,
status TINYINT,
username VARCHAR(32),
amount BIGINT DEFAULT '0'
)
UNIQUE KEY(orderid)
DISTRIBUTED BY HASH(orderid) BUCKETS 10;
```
2. 插入2条数据
```
mysql> insert into sales_order values(1,1,'name1',100);
mysql> insert into sales_order values(1,1,'name1',200);
```
3. 查询
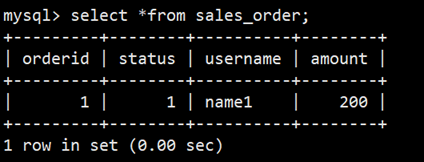
#### DUPLICATE KEY
只指定排序列,相同的行并不会合并。适用于数据无需提前聚合的分析业务。
1. 建表
```
CREATE TABLE session_data
(
visitorid SMALLINT,
sessionid BIGINT,
city CHAR(20),
ip varchar(32)
)
DUPLICATE KEY(visitorid, sessionid)
DISTRIBUTED BY HASH(sessionid, visitorid) BUCKETS 10;
```
2. 插入数据
```
mysql> insert into session_data values(1,1,'shanghai','www.111.com');
mysql> insert into session_data values(1,1,'shanghai','www.111.com');
mysql> insert into session_data values(3,2,'shanghai','www.111.com');
mysql> insert into session_data values(2,2,'shanghai','www.111.com');
mysql> insert into session_data values(2,1,'shanghai','www.111.com');
```
3. 查询

#### Rollup
Rollup可以理解为表的一个物化索引结构。Rollup可以调整列的顺序以增加前缀索引的命中率,也可以减少key列以增加数据的聚合度。
(1)以session_data为例添加Rollup
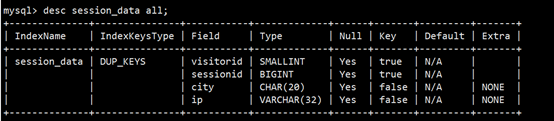
(2)比如我经常需要看某个城市的ip数,那么可以建立一个只有ip和city的rollup
mysql> alter table session_data add rollup rollup_city_ip(city,ip);
(3)创建完毕后,再次查看表结构
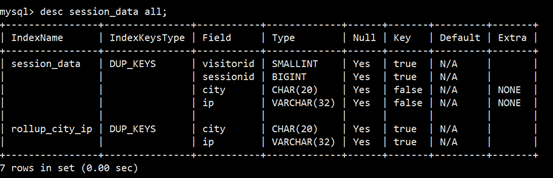
(4)然后可以通过explain查看执行计划,是否使用到了rollup

#### 数据导入
为适配不同的数据导入需求,Doris系统提供5种不同的导入方式。每种导入方式支持不同的数据源,存在不同的方式(异步、同步)
(1)Broker load
通过Broker进程访问并读取外部数据源(HDFS)导入Doris。用户通过MySql协议提交导入作业后,异步执行。通过show load命令查看导入结果。
(2)Stream load
用户通过HTTP协议提交请求并携带原始数据创建导入。主要用于快速将本地文件或数据流中的数据导入到Doris。导入命令同步返回导入结果。
(3)Insert
类似MySql中的insert语句,Doris提供insert into tbl select ...;的方式从Doris的表中读取数据并导入到另一张表。或者通过insert into tbl values(...);的方式插入单条数据
(4)Multi load
用户可以通过HTTP协议提交多个导入作业。Multi Load可以保证多个导入作业的原子生效
(5)Routine load
用户通过MySql协议提交例行导入作业,生成一个常住线程,不间断的从数据源(如Kafka)中读取数据并导入Doris中。
#### Broker Load
Broker load是一个导入的异步方式,支持的数据源取决于Broker进程支持的数据源。
适用场景:(1)源数据在Broker可以访问的存储系统中,如HDFS (2)数据量在几十到百GB级别
基本原理:用户在提交导入任务后,FE(Doris系统的元数据和调度节点)会生成相应的PLAN(导入执行计划,BE会执行导入计划将输入导入Doris中)并根据BE(Doris系统的计算和存储节点)的个数和文件的大小,将Plan分给多个BE执行,每个BE导入一部分数据。BE在执行过程中会从Broker拉取数据,在对数据转换之后导入系统。所有BE均完成导入,由FE最终决定是否导入是否成功。
#### Hive导入Doris
1. 建表
```
create table student_result
(
id int ,
name varchar(50),
age int ,
score decimal(10,4),
dt varchar(20)
)
DUPLICATE KEY(id)
DISTRIBUTED BY HASH(id) BUCKETS 10;
```
2. 编写导入语句,dt是分区列,在数据块读不到所以使用固定值
```
LOAD LABEL test_db.student_result_h_2
(
DATA INFILE("hdfs://mycluster/user/hive/warehouse/student_tmp_h/dt=20200908/*")
INTO TABLE student_result
COLUMNS TERMINATED BY "\t"
(co1,co2,co3,co4)
set(
id=co1,
name=co2,
age=co3,
score=co4,
dt='20200908'
)
)
WITH BROKER "broker_name"
(
"dfs.nameservices"="mycluster",
"dfs.ha.namenodes.mycluster"="nn1,nn2,nn3",
"dfs.namenode.rpc-address.mycluster.nn1"= "hadoop101:8020",
"dfs.namenode.rpc-address.mycluster.nn2"= "hadoop102:8020",
"dfs.namenode.rpc-address.mycluster.nn3"="hadoop103:8020",
"dfs.client.failover.proxy.provider.mycluster"="org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider"
)
```
3. 导入成功后,查询doris数据
#### Stream Load
Stream Load是一个同步的导入方式,用户通过发送HTTP协议将本地文件或数据流导入到Doris中,Stream load同步执行导入并返回结果。用户可以直接通过返回判断导入是否成功。
具体帮助使用HELP STREAM LOAD 查看
#### Routine Load
例行导入功能为用户提供了一种自动从指定数据源进行数据导入的功能。
当前仅支持Kafka系统进行例行导入。
```
CREATE ROUTINE LOAD test_db.kafka_test ON student_kafka
PROPERTIES
(
"desired_concurrent_number"="3",
"strict_mode" = "false"
)
FROM KAFKA
(
"kafka_broker_list"= "doris1:9092,doris2:9092,doris:9092",
"kafka_topic" = "test2",
"property.group.id"="test_group_2",
"property.kafka_default_offsets" = "OFFSET_BEGINNING",
"property.enable.auto.commit"="false"
);
```
#### 动态分区
动态分区是在Doris0.12版本加入的功能。旨在对表级别的分区实现生命周期管理(TTL),减少用户的使用负担。
目前实现了动态添加分区及动态删除分区的功能
原理:
在某些场景下,用户会将表按照天进行分区划分,每天定时执行例行任务,这时需要使用方手动管理分区,否则可能由于使用方没有创建数据导致失败这给使用方带来额外的维护成本。
在实现方式上,FE会启动一个后台子线程,根据fe.conf中dynamic_partition_enable及dynamic_partition_check_interval_seconds参数决定线程是否启动以及该线程的调度频率。每次调度时,会在注册表中读取动态分区表的属性。
| | |
|--|--|
| | |
|dynamic_partition.enable |是否开启动态分区特性,可指定true或false,默认为true|
|dynamic_partition.time_unit |动态分区调度的单位,可指定day,week,month。当指定day时格式为yyyyMMDD。当指定week时格式为yyyy_ww,表示属于这一年的第几周。当指定为month时,格式为yyyyMM|
|dynamic_partition.start |动态分区的开始时间,以当天为准,超过该时间范围的分区将会被删除,如果不填写默认值为Interger.Min_VALUE 即-2147483648|
|dynamic_partition.end| 动态分区的结束时间,以当天为基准,会提前创建N个单位的分区范围|
|dynamic_partition.prefix |动态创建的分区名前缀|
|dynamic_partition.buckets| 动态创建的分区所对应分桶数量|
#### 使用
1)开启动态分区功能,可以在fe.conf中设置dynamic_partition_enable=true,也可以使用命令进行修改。使用命令进行修改,并dynamic_partition_check_interval_seconds调度时间设置为5秒,意思就是每过5秒根据配置刷新分区。我这里做测试设置为5秒,真实场景可以设置为12小时。
```
root@doris1:/opt/module# curl --location-trusted -u root:123456 -XGET http://doris1:8030/api/_set_config?dynamic_partition_enable=true
root@doris1:/opt/module# curl --location-trusted -u root:123456 -XGET http://doris1:8030/api/_set_config?dynamic_partition_check_interval_seconds=5
mysql> ADMIN SET FRONTEND CONFIG ("dynamic_partition_enable" = "true");
mysql> ADMIN SET FRONTEND CONFIG ("dynamic_partition_check_interval_seconds"="5");
```
(2)创建一张调度单位为天,不删除历史分区的动态分区表
```
create table student_dynamic_partition1
(id int,
time date,
name varchar(50),
age int
)
duplicate key(id,time)
PARTITION BY RANGE(time)()
DISTRIBUTED BY HASH(id) buckets 10
PROPERTIES(
"dynamic_partition.enable" = "true",
"dynamic_partition.time_unit" = "DAY",
"dynamic_partition.end" = "3",
"dynamic_partition.prefix" = "p",
"dynamic_partition.buckets" = "10",
"replication_num" = "1"
);
```
(3)查看分区表情况SHOW DYNAMIC PARTITION TABLES,更新最后调度时间

(4)插入测试数据,可以全部成功
```
mysql> insert into student_dynamic_partition1 values(1,'2020-09-10 11:00:00','name1',18);
mysql> insert into student_dynamic_partition1 values(1,'2020-09-11 11:00:00','name1',18);
mysql> insert into student_dynamic_partition1 values(1,'2020-09-12 11:00:00','name1',18);
```
(5)使用命令查看表下的所有分区show partitions from student_dynamic_partition1;

#### 数据导出
数据导出是Doris提供的一种将数据导出的功能。该功能可以将用户指定的表或分区的数据以文本的格式,通过Broker进程导出到远端存储上,如HDFS/BOS等。
(1)启动hadoop集群
(2)执行导出计划
```
export table student_dynamic_partition1
partition(p20200910,p20200911,p20200912,p20200913)
to "hdfs://mycluster/user/atguigu"
WITH BROKER "broker_name"
(
"dfs.nameservices"="mycluster",
"dfs.ha.namenodes.mycluster"="nn1,nn2,nn3",
"dfs.namenode.rpc-address.mycluster.nn1"= "hadoop101:8020",
"dfs.namenode.rpc-address.mycluster.nn2"= "hadoop102:8020",
"dfs.namenode.rpc-address.mycluster.nn3"="hadoop103:8020",
"dfs.client.failover.proxy.provider.mycluster"="org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider"
);
```
(3)导出之后查看hdfs对应路径,会多出许多文件
#### Colocation Join
Colocation Join是在Doris0.9版本引入的功能,旨在为Join查询提供本性优化,来减少数据在节点上的传输耗时,加速查询。
原理
Colocation Join功能,是将一组拥有CGS 的表组成一个CG。保证这些表对应的数据分片会落在同一个be节点上,那么使得两表再进行join的时候,可以通过本地数据进行直接join,减少数据在节点之间的网络传输时间。
使用限制:
(1)建表时两张表的分桶列和数量需要完全一致,并且桶的个数也需要一致。
(2)副本数,两张表的所有分区的副本数需要一致
(1)使用,建两张表,分桶列都为int类型,且桶的个数都是8个。两张表的副本数都为默认副本数。
```
CREATE TABLE `tbl1` (
`k1` date NOT NULL COMMENT "",
`k2` int(11) NOT NULL COMMENT "",
`v1` int(11) SUM NOT NULL COMMENT ""
) ENGINE=OLAP
AGGREGATE KEY(`k1`, `k2`)
PARTITION BY RANGE(`k1`)
(
PARTITION p1 VALUES LESS THAN ('2019-05-31'),
PARTITION p2 VALUES LESS THAN ('2019-06-30')
)
DISTRIBUTED BY HASH(`k2`) BUCKETS 8
PROPERTIES (
"colocate_with" = "group1"
);
```
```
CREATE TABLE `tbl2` (
`k1` datetime NOT NULL COMMENT "",
`k2` int(11) NOT NULL COMMENT "",
`v1` double SUM NOT NULL COMMENT ""
) ENGINE=OLAP
AGGREGATE KEY(`k1`, `k2`)
DISTRIBUTED BY HASH(`k2`) BUCKETS 8
PROPERTIES (
"colocate_with" = "group1"
);
```
(2)编写查询语句,并查看执行计划,HASH JOIN处colocate 显示为true,代表优化成功。
mysql> explain SELECT * FROM tbl1 INNER JOIN tbl2 ON (tbl1.k2 = tbl2.k2);