AMBA协议AXI-Stream(协议信号、设计实践)
文章目录
- 一、AXI-Stream简介
- 二、AXI-Stream端口信号(Master)
- 三、AXI-Stream数据字节类型和流格式
- 四、数据反压
- 五、实验设计
-
- 5.1 情景描述与分析
- 5.2 硬件架构设计
- 5.3 源码设计
- 5.4 仿真
一、AXI-Stream简介
AXI-Stream(以下简称AXIS)是AMBA协议的AXI协议三个版本中(AXI4-FULL、AXI4-Lite、AXI4-Stream)最简单的一个协议;是AXI4中定义的面向数据流的协议,常用于对数据流的处理,如:
- 摄像头
- 高速AD
- Xilinx的AXI-DMA模块
在进行SOC设计中需要高速数据传输处理的场合,常常使用AXIS协议;
AXIS与AXI-FULL的区别:
-
取消了Address Write/Address Read通道;
-
取消了反馈响应信号Bresp和Rresp;
-
半双工,仅能读或者写;
-
不允许乱序;
-
无最大突发传输长度;
-
包含TID信号指示源,TDEST指示目的地;
-
包括一个用于插入和溢出空字节的TKEEP信号;
二、AXI-Stream端口信号(Master)
以AXIS主机接口的信号为例,AXIS的信号表如下:
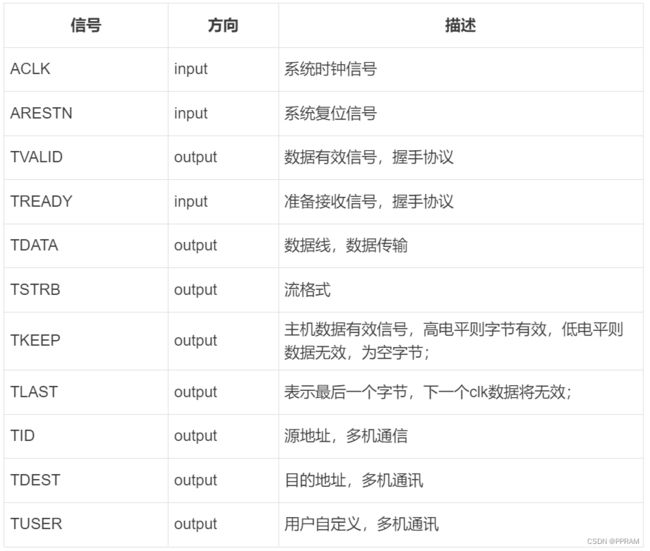 AXIS的所有信号都在ACLK的上升沿被采样;
AXIS的所有信号都在ACLK的上升沿被采样;
这里讲解下几个比较重要的信号:
TVALID:TVALID是数据有效信号,若TVALID为高电平,标志着TDATA数据线上的数据是有效的,能够被取走,TVALID信号与TREADY信号是一组握手信号;;
TREADY:TREADY是指从机是否准备好接收数据,若TREADY为高电平,则标志着从机此时已经准备好接收数据,TREADY信号与TVALID信号是一组握手信号;
TDATA:数据通道,位宽可以是8、16、32;当TVALID与TREADY均为高电平(有效)时,TDATA数据被传递;
TLAST:数据流结束信号,当TLAST为高电平时,说明此时传输的数据为数据流的最后一个数据;在Xilinx的AXI-DMA中,TLAST信号可以控制整个数据流传输的结束(当传输过程中TLAST为高,则结束一次DMA传输);
 我们可以发现,本质上AXIS协议也就是握手协议,只不过增加了一个TLAST信号,和一些其他的附带指示其他信息的信号;如TID、TDEST、TUSER等都是用于多级通讯的,在单一数据流方向的系统中,我们只需要关注上述几个重要的信号即可;
我们可以发现,本质上AXIS协议也就是握手协议,只不过增加了一个TLAST信号,和一些其他的附带指示其他信息的信号;如TID、TDEST、TUSER等都是用于多级通讯的,在单一数据流方向的系统中,我们只需要关注上述几个重要的信号即可;
三、AXI-Stream数据字节类型和流格式
- 数据字节(Data Byte):包含在源和目标之间传输的有效信息的数据字节。
- 占位字节 (Position byte):表示流内部数据字节的相对位置的字节。 这是一个不包含在源和目标之间传输的任何相关数据值的占位符。
- 空字节(Null byte):不包含任何数据信息的字节或关于流内数据字节的相对位置的任何信息。
字节流:
在每次握手之后,可以传输任何数量的数据字节,NULL字节没有含义,可以插入或删除。
 连续对齐流:
连续对齐流:
即数据本身就是对其的,可以直接写入内存
 连续不对齐流:
连续不对齐流:
数据包只有18B,但是对齐需要20B/24B,这个时候就需要引入占位字节:

稀疏流:
允许数据流的中间也有占位符;
 不同字节类型指示:
不同字节类型指示:
 可自定义省略的信号:
可自定义省略的信号:
TID、TDEST、TUSER:自定义,多传输系统中使用
TLAST:常为1或0;
TKEEP和TSTRB:全部为1或0;
TREADY:时刻准备接收,数据反压问题;
四、数据反压
数据流源源不断涌入,但从机处理数据能力有限,导致输入数据量大于输出数据量。
- 发送端:当保留TREADY信号时,从机若处理不了数据时,可以将数据缓存。若去掉TREADY信号,则处理不了的数据只能溢出。
- 接收端:若去除TREADY信号,则说明接收端的处理数据速度大于发送端,数据可以持续输入。
五、实验设计
5.1 情景描述与分析
假设现在需要一个加解密模块对数据流进行加解密处理,其输入为128bit信息,输出为128bit信息;
分析:如果采用地址映射的方式输入和读取信息,则需要CPU介入向IP核写入或读取信息,当需要加密的数据量过大时,则会占用大量的CPU资源来搬运数据;
此时就需要DMA介入了,DMA可以对连续的内存进行访问,并将内存数据以数据流的方式搬运到指定地址的IP核;假设DMA以AXIS的协议将数据搬运到IP核内,假设TDATA位宽为32位,则在模块内部需要进行4个数据的缓冲,直到加解密模块将数据处理完毕,再以AXIS数据流方式写出;
5.2 硬件架构设计
这里我们不探讨DMA的原理,假设我们已经知道了DMA的数据流输出为AXIS协议的,我们对从机进行接口设计;
 数据流以AXIS协议流入IP核的Slave接口,其次由Buffer缓冲4个字的数据(128bits);
数据流以AXIS协议流入IP核的Slave接口,其次由Buffer缓冲4个字的数据(128bits);
当缓冲满4个字数据后,AXIS-Slave Interface将从机TREADY信号拉低,此时来自DMA Master接口的数据流阻塞,并且加解密码模块进入工作状态;
若干时间后,加解密模块完成任务后,将输出数据打入Buffer out,此时AXI-Master Interface将TVALID信号拉高,AXI-Slave Interface将TREADY信号拉高,将输出寄存器中处理后的数据回传回DMA,并将新的数据读入输入缓冲区;
其数据流如下:
DATA(IN)为输入的数据,DATA(OUT)为输出的数据;
Encoder Module为加解密模块所占用的时间;

5.3 源码设计
`timescale 1ns / 1ps
//
// Company:
// Engineer:
//
// Create Date: 2023/03/01 19:34:56
// Design Name:
// Module Name: axi_stream_test
// Project Name:
// Target Devices:
// Tool Versions:
// Description:
//
// Dependencies:
//
// Revision:
// Revision 0.01 - File Created
// Additional Comments:
//
//
module axi_stream_test #
(
parameter integer C_S_AXIS_TDATA_WIDTH = 32,
// parameter integer C_M_AXIS_TDATA_WIDTH = 32,
parameter integer C_M_AXIS_BURST_LEN = 8,
parameter integer COMB_LEN = 4
)
(
//AXI_Stream receiver ports
input wire S_AXIS_ACLK,
input wire S_AXIS_ARESETN,
output wire S_AXIS_TREADY,
input wire [C_S_AXIS_TDATA_WIDTH-1 : 0] S_AXIS_TDATA,
input wire [(C_S_AXIS_TDATA_WIDTH/8)-1 : 0] S_AXIS_TSTRB,
input wire S_AXIS_TLAST,
input wire S_AXIS_TVALID,
//AXI_Stream send ports
// input wire M_AXIS_ACLK,
// input wire M_AXIS_ARESETN,
output wire M_AXIS_TVALID,
output wire [C_S_AXIS_TDATA_WIDTH-1 : 0] M_AXIS_TDATA,
output wire[(C_S_AXIS_TDATA_WIDTH/8)-1 : 0] M_AXIS_TSTRB,
output wire M_AXIS_TLAST,
input wire M_AXIS_TREADY
);
//----------------------------------Slave Logic------------------------------------//
reg [C_S_AXIS_TDATA_WIDTH-1 : 0] axi_s_m2s_data;
(* MARK_DEBUG="true" *)reg [C_S_AXIS_TDATA_WIDTH-1 : 0] axi_s_m2s_data_buffer [0:COMB_LEN-1];
(* MARK_DEBUG="true" *)reg [C_S_AXIS_TDATA_WIDTH-1 : 0] axi_s_data_deal_buffer [0:COMB_LEN-1];
reg [COMB_LEN-1 : 0] tdata_index;
wire s_axis_tready;
(* MARK_DEBUG="true" *) reg done_flg;
wire recv_flg;
assign s_axis_tready = (tdata_index == COMB_LEN) ? 1'b0:1'b1;
assign S_AXIS_TREADY = s_axis_tready;
assign recv_flg = s_axis_tready & S_AXIS_TVALID;
always @(posedge S_AXIS_ACLK) begin : axi_s_recv_proc_
if(~S_AXIS_ARESETN) begin
axi_s_m2s_data <= 0;
end else begin
if(recv_flg)
begin
axi_s_m2s_data <= S_AXIS_TDATA;
end
end
end
always@(posedge S_AXIS_ACLK)begin
if(~S_AXIS_ARESETN) begin
tdata_index <= 'd0;
end
else begin
if((tdata_index != COMB_LEN) & recv_flg)
tdata_index <= tdata_index + 1'd1;
else if((tdata_index == COMB_LEN)&(done_flg == 1'b1))
tdata_index <= 'd0;
end
end
integer index;
always@(posedge S_AXIS_ACLK)begin
if(~S_AXIS_ARESETN) begin
for(index = 0;index < COMB_LEN ; index = index+1)
begin
axi_s_m2s_data_buffer[index] <= 'd0;
axi_s_data_deal_buffer[index] <= 'd0;
end
end
else begin
if((tdata_index != COMB_LEN) & recv_flg)
axi_s_m2s_data_buffer[tdata_index] <= S_AXIS_TDATA;
else if(tdata_index == COMB_LEN)
for(index = 0;index < COMB_LEN ; index = index+1)
begin
axi_s_data_deal_buffer[index] <= axi_s_m2s_data_buffer[index];
end
end
end
//----------------------------------Master Logic------------------------------------//
reg [C_S_AXIS_TDATA_WIDTH-1 : 0] axi_s_s2m_data_buffer [0:COMB_LEN-1];
reg [COMB_LEN-1:0] m_tdata_index;
reg [$clog2(C_M_AXIS_BURST_LEN)-1:0] burst_len_cnt;
wire m_axis_tlast;
wire batch_last;
reg txd_flg;
assign batch_last = (m_tdata_index == COMB_LEN-1) ? 1'b1:1'b0;
assign m_axis_tlast = (burst_len_cnt == C_M_AXIS_BURST_LEN-1) ? 1'b1:1'b0;
assign M_AXIS_TVALID = txd_flg;//(m_tdata_index == COMB_LEN) ? 1'b0:1'b1;
assign M_AXIS_TSTRB = {(C_S_AXIS_TDATA_WIDTH/8){1'b1}};
assign M_AXIS_TLAST = m_axis_tlast;
assign M_AXIS_TDATA = axi_s_s2m_data_buffer[m_tdata_index];
integer s_index;
always@(*)
begin
for(s_index = 0;s_index < COMB_LEN ; s_index = s_index+1)
begin
axi_s_s2m_data_buffer[s_index] <= axi_s_data_deal_buffer[s_index];
end
end
always@(posedge S_AXIS_ACLK)
begin
if(~S_AXIS_ARESETN)
begin
txd_flg <= 1'b0;
end
else
begin
if((txd_flg == 1'b0) & (done_flg == 1'b1))
txd_flg <= 1'b1;
else if((txd_flg==1'b1) & batch_last)
txd_flg <= 1'b0;
end
end
always@(posedge S_AXIS_ACLK)
begin
if(~S_AXIS_ARESETN)
begin
m_tdata_index <= 'b0;
end
else
begin
if((txd_flg == 1'b1) & (m_tdata_index != COMB_LEN) & (M_AXIS_TREADY == 1'b1))
m_tdata_index <= m_tdata_index+1'b1;
else if((m_tdata_index == COMB_LEN))
m_tdata_index <= 'b0;
end
end
always@(posedge S_AXIS_ACLK)
begin
if(~S_AXIS_ARESETN)
begin
burst_len_cnt <= 'b0;
end
else
begin
if((txd_flg == 1'b1) & (burst_len_cnt != C_M_AXIS_BURST_LEN) & (M_AXIS_TREADY == 1'b1))
burst_len_cnt <= burst_len_cnt+1'b1;
else if((burst_len_cnt == C_M_AXIS_BURST_LEN))
burst_len_cnt <= 'b0;
end
end
/--------------------application--------------------------/
reg [15:0] deal_cnt;
always@(posedge S_AXIS_ACLK)begin
if(~S_AXIS_ARESETN) begin
for(index = 0;index < COMB_LEN ; index = index+1)
begin
deal_cnt <= 'd0;
done_flg <= 1'b0;
end
end
else begin
if((done_flg == 1'b0) & (s_axis_tready == 1'b0))
begin
if(deal_cnt!=32)
begin
deal_cnt <= deal_cnt+'d1;
done_flg <= 1'b0;
end
else
begin
deal_cnt <= 'd0;
done_flg <= 1'b1;
end
end
else if(done_flg == 1'b1)
begin
done_flg <= 1'b0;
end
end
end
endmodule
参数说明:
C_M_AXIS_BURST_LEN:最大传输长度,默认为8,与TLAST信号的产生有关,当传输数据个数达到C_M_AXIS_BURST_LEN后,TLAST拉高;
COMB_LEN:缓冲的长度,表示缓冲的数据数;
C_S_AXIS_TDATA_WIDTH:传输数据位宽,默认为32位;
代码说明:
Slave Logic为从机接口逻辑;
Slave Master为主机接口逻辑;
application为应用程序逻辑;
说明:假设application逻辑需要32个clk完成加解密(加解密模块);
5.4 仿真
仿真源码:
`timescale 1ns / 1ps
//
// Company:
// Engineer:
//
// Create Date: 2023/03/01 19:46:39
// Design Name:
// Module Name: AXI_Stream_tb
// Project Name:
// Target Devices:
// Tool Versions:
// Description:
//
// Dependencies:
//
// Revision:
// Revision 0.01 - File Created
// Additional Comments:
//
//
module AXI_Stream_tb(
);
parameter integer C_S_AXIS_TDATA_WIDTH = 32;
parameter integer C_M_AXIS_TDATA_WIDTH = 32;
reg S_AXIS_ACLK;
reg S_AXIS_ARESETN;
wire S_AXIS_TREADY;
reg [C_S_AXIS_TDATA_WIDTH-1 : 0] S_AXIS_TDATA;
reg [(C_S_AXIS_TDATA_WIDTH/8)-1 : 0] S_AXIS_TSTRB;
reg S_AXIS_TLAST;
reg S_AXIS_TVALID;
wire M_AXIS_ACLK;
wire M_AXIS_ARESETN;
wire M_AXIS_TVALID;
wire [C_M_AXIS_TDATA_WIDTH-1 : 0] M_AXIS_TDATA;
wire[(C_M_AXIS_TDATA_WIDTH/8)-1 : 0] M_AXIS_TSTRB;
wire M_AXIS_TLAST;
reg M_AXIS_TREADY;
assign M_AXIS_ACLK = S_AXIS_ACLK;
assign M_AXIS_ARESETN = S_AXIS_ARESETN;
// assign M_AXIS_TREADY = 1'b1;
initial begin
S_AXIS_ACLK = 0;
forever begin
#1 S_AXIS_ACLK = ~S_AXIS_ACLK;
end
end
initial begin
S_AXIS_ARESETN = 1'b0;
#2 S_AXIS_ARESETN = 1'b1;
end
always @(posedge S_AXIS_ACLK) begin : proc_
if(~S_AXIS_ARESETN) begin
S_AXIS_TLAST <= 1'b0;
S_AXIS_TVALID <= 0;
S_AXIS_TDATA <= 0;
end else begin
S_AXIS_TVALID <= 1;
if((S_AXIS_TDATA!='d32)&(S_AXIS_TREADY == 1'b1))
S_AXIS_TDATA <= S_AXIS_TDATA+1'b1;
end
end
initial begin
M_AXIS_TREADY = 1;
// #100 M_AXIS_TREADY = 0;
// #100 M_AXIS_TREADY = 1;
end
axi_stream_test #
(
.C_S_AXIS_TDATA_WIDTH (C_S_AXIS_TDATA_WIDTH)
)axi_stream_test_inist0
(
. S_AXIS_ACLK( S_AXIS_ACLK),
.S_AXIS_ARESETN(S_AXIS_ARESETN),
. S_AXIS_TREADY( S_AXIS_TREADY),
. S_AXIS_TDATA( S_AXIS_TDATA),
. S_AXIS_TSTRB( S_AXIS_TSTRB),
. S_AXIS_TLAST( S_AXIS_TLAST),
. S_AXIS_TVALID( S_AXIS_TVALID),
// . M_AXIS_ACLK( M_AXIS_ACLK),
// .M_AXIS_ARESETN(M_AXIS_ARESETN),
. M_AXIS_TVALID( M_AXIS_TVALID),
. M_AXIS_TDATA( M_AXIS_TDATA),
. M_AXIS_TSTRB( M_AXIS_TSTRB),
. M_AXIS_TLAST( M_AXIS_TLAST),
. M_AXIS_TREADY( M_AXIS_TREADY)
);
endmodule
仿真波形:
我们可以看到,输出是连续的递增的,对应了连续的输入;
 通过仿真,其基本原理正确;
通过仿真,其基本原理正确;
后续将给出模块IP封装和上板后实际运行的过程;