使用 TensorFlow 2.0 实现深度音频降噪
原文链接
How To Build a Deep Audio De-Noiser Using TensorFlow 2.0
Practical deep learning audio de-noising

Introduction
语音去噪是一个长期存在的问题。给定一个嘈杂的输入信号,目标是在不降低感兴趣的信号的情况下过滤掉这些噪音。你可以想象这样一种场景,一个人在视频会议中说话,而背景中正在播放一段音乐。在这种情况下,语音去噪系统的工作是去除背景噪音,以改善语音信号。除了许多其他用例外,这种应用对于视频和音频会议尤其重要,因为噪音会大大降低语音的清晰度。
语音去噪的经典解决方案通常采用生成式建模(Generative modeling)。在这里,像高斯混合(Gaussian Mixtures)这样的统计方法估计感兴趣的噪声,然后恢复去除噪声的信号。然而,最近的发展表明,在有数据的情况下,深度学习往往优于这些解决方案。
在这篇文章中,我们使用卷积神经网络(CNNs: Convolutional Neural Networks)解决了语音去噪的问题。给定一个嘈杂的输入信号,我们的目标是建立一个统计模型,可以提取干净的信号(源)并将其返回给用户。在这里,我们专注于从城市街道环境中常见的十种不同类型的噪声中分离出常规语音信号的源。
Datasets
对于语音去噪的问题,我们使用了两个流行的公开可用的音频数据集。
- The Mozilla Common Voice (MCV)
- The UrbanSound8K dataset
正如Mozilla在MCV网站上所说:
Common Voice是Mozilla的一项倡议,旨在帮助教导机器真正的人类是如何讲话。
该数据集包含多达2454个录制小时,分布在简短的MP3文件中。该项目是开源的,任何人都可以在上面进行合作。在这里,我们使用了数据的英语部分,其中包含了30GB的780个有效小时的语音。这个数据集的一个非常好的特点是说话者的巨大差异性。它包含了来自不同年龄和口音的男性和女性的录音。
UrbanSound8K 数据集也包含小段的声音(<=4s)。然而,有8732个标记的例子,关于十个不同的在城市中常见的声音。完整的列表包括:
- 0 = 空调
- 1 = 汽车喇叭
- 2 = 儿童玩耍
- 3 = 狗吠
- 4 = 钻孔
- 5 = 发动机怠速
- 6 = 枪声
- 7 = 手提钻
- 8 = 警笛声
- 9 = 街头音乐
正如你这时可能想象的那样,我们要把城市的声音作为语音示例的噪声信号。换句话说,我们首先取一个小的语音信号,这可以是某人从MCV数据集中随机说出的一句话。
然后,我们给它添加噪音,比如一个女人正在说话,还有一只狗正在叫。最后,我们用这个人工的噪音信号作为我们的深度学习模型的输入。反过来,神经网络接收这个噪音信号,并试图输出一个清晰的信号。
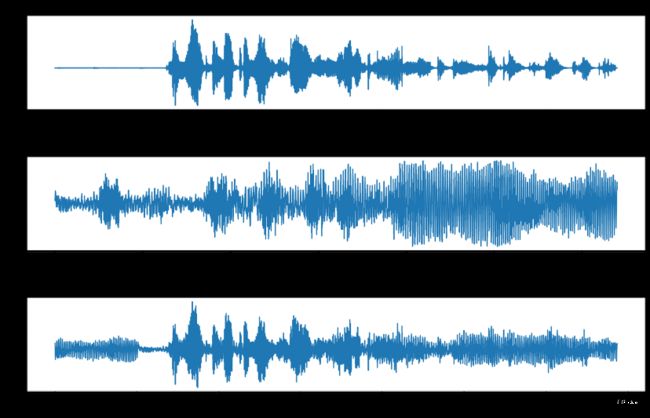
下图展示了来自三种途径的信号的直观表示,顶部为MCV的干净输入信号,中部为来自UrbanSound数据集的噪声信号,并将加入噪声信号后的输入语音放在底部。另外,请注意,噪声功率的设置是为了使信噪比(SNR: Signal-to-Noise Ratio)为0dB(分贝)。比值高于1:1(大于0dB)时表示信号多于噪声。
Data Preprocessing
当前深度学习技术的大部分好处在于,手工制作的特征不再是建立最先进模型的必要步骤。以SIFT和SURF等特征提取器为例,它们经常被用于全景拼接( Panorama Stitching)等计算机视觉问题。这些方法从图像的局部提取特征,以构建图像本身的内部表示。然而,为了实现必要的泛化目标,需要做大量的工作来创建足够强大的特征,足以适用于现实世界的场景。换句话说,这些特征需要对我们日常经常看到的常见变换不发生变化。这些可能包括旋转、平移、缩放等方面的变化。目前深度学习的一个很酷的地方是,这些属性大部分都是从数据和/或特殊操作中学习的,比如卷积。
对于音频处理,我们也希望神经网络能从数据中提取相关特征。然而,在将原始信号送入网络之前,我们需要将其转换成正确的格式。
首先,我们将音频信号(来自两个数据集)降频(下采样)到8kHz,并将其中的无声帧去除。目的是为了减少计算量和数据集的大小。
值得注意的是,音频数据与图像不同。由于我们的假设之一是将CNNs(最初为计算机视觉设计)用于音频去噪,因此必须意识到这种微妙的差异。音频数据的原始形式是一个一维的时间序列数据。另一方面,图像是对瞬间的时间的二维表示。由于这些原因,音频信号经常被转换为(时间/频率)二维表示。

Mel-frequency Cepstral Coefficients(MFCCs)和constant-Q spectrum是两个常用于音频应用的表示方法。对于深度学习来说,可以避免使用经典的MFCCs,因为它们删除了很多信息,而且不保留空间关系。然而,对于声源分离任务,计算通常是在时频域中进行的。音频信号在大多数情况下都是非稳态的。换句话说,信号的均值和方差不是随时间变化的常数。因此,在整个音频信号上计算傅里叶变换并没有什么意义。出于这个原因,我们将经过256-point Short Time Fourier Transform(STFT)计算的频谱幅度向量提供给了DL系统。你可以在下面看到音频信号的常见表示方法:
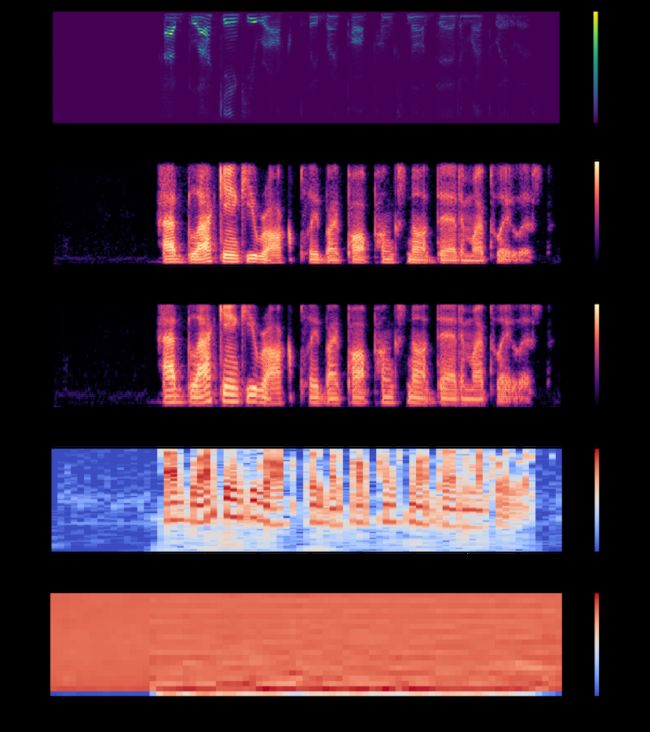
音频数据常见的2D表示,从上到下依次为:
(1) 短时傅里叶变换幅值谱:STFT magnitude spectrum;
(2) 频谱图:Spectrogram;
(3) 梅尔频谱图:Mel spectrogram;
(4) 恒定Q频谱:Constant-q;
(5) 梅尔频率倒谱系数:Mel-Frequency Cepstral Coefficients (MFCCs)
为了计算一个信号的STFT,我们需要定义一个长度为M的窗口和一个跳动大小值R,后者定义了窗口如何在信号上移动。然后,我们在信号上滑动窗口,并计算窗口内数据的离散傅里叶变换(DFT: discrete Fourier Transform)。因此,STFT只是在数据的不同部分应用傅里叶变换。最后,我们从256-point STFT向量中提取幅度向量,并通过去除对称的一半来得到前129-point。所有这些过程都是使用Python Librosa库完成的。下面的图片来自MATLAB,说明了这个过程。

图片来源: MATLAB STFT docs
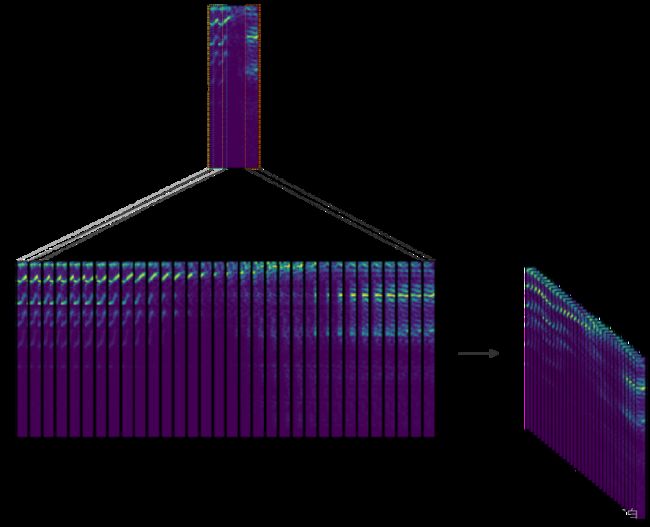
在这里,我们将STFT窗口定义为一个周期性的汉明窗(Hamming Window),长度为256,跳数为64。这确保了STFT向量之间有75%的重叠。最后,我们将8个连续的噪声STFT向量连接起来,并将它们作为输入。因此,一个输入矢量的形状是(129, 8),由当前的STFT噪声向量加上之前的七个噪声STFT向量组成。换句话说,该模型是一个自回归系统,根据过去的观察结果预测当前信号。因此,目标由来自纯净音频中形状为(129, 1)的单一STFT频率表示组成。下面的图片描述了特征向量的创建:
Deep Learning Architecture
我们的深度卷积神经网络(DCNN)主要是基于论文A Full Convolutional Neural Network for Speech Enhancement中所做的工作。在这里,作者提出了Cascaded Redundant Convolutional Encoder-Decoder Network(CR-CED)。
该模型是基于对称的编码器-解码器结构。两个组件都包含卷积、ReLU和批量规范化的重复块。总的来说,该网络包含16个这样的块,加起来总共有33K个参数。
此外,一些编码器和解码器块之间有跳过的连接。在这里,来自两个组件的特征向量通过加法结合起来。跳跃连接加快了收敛速度,减少了梯度的消失,这与ResNets非常相似。
CR-CED网络的另一个重要特征是卷积只在一个维度上进行。更具体地说,给定一个形状为(129 x 8)的输入频谱,卷积只在频率轴(即第一轴)上进行。这确保了频率轴在转发传播过程中保持不变。
少量的训练参数和模型结构的结合,使得这个模型超轻,执行速度快,特别是在移动或边缘设备上。
一旦网络产生了输出估计值,我们就优化(最小化)输出和目标(纯净音频)信号之间的均方误差(MSE: Mean Squared Error)。

Results and Discussion
让我们检查一下CNN去噪器所取得的一些结果。
首先,听一下来自MCV和UrbanSound数据集的测试例子。它们分别是干净的语音和噪声信号。概括地说,纯净信号作为目标,而噪声音频被用作噪声源。
如果你在听这些样本时遇到困难,你可以在这里访问原始文件。
Clean Input
Noise Signal
现在,看一看作为模型输入传递的噪声信号和相应的去噪结果。
Noisy Input
Denoised
在下面,您可以将去噪后的CNN估计(底部图像)与目标(干净信号,顶部图像)和噪声信号(用作输入,中部图像)进行比较。

正如你所看到的,考虑到任务的难度,结果是可以接受的,但并不完美。事实上,在大多数示例中,模型设法平滑了噪声,但并没有完全消除噪声。看一个不同的例子,这一次背景中有一只狗在吠叫。
Dog Noisy
Dog Clean
妨碍得到更好估计的原因之一是损失函数。均方误差(MSE: Mean Squared Error)成本优化了训练示例的平均值。我们可以认为它是找到平滑输入噪声音频的均值模型,可以提供干净信号的估计。因此,解决方案之一是为源分离任务设计更具体的损失函数。
一个特别有趣的可能性是使用生成对抗网络(GANs: Generative Adversarial Networks)去学习损失函数本身。实际上,音频去噪问题可以被定义为信号到信号的转换问题。与图像到图像的转换非常相似,首先,生成器网络接收了一个噪声信号,并输出一个干净信号的估计值。然后,鉴别器网络(Discriminator net)接收噪声输入以及发生器的预测器或真实目标信号。这样,GAN将能够学习适当的损失函数,以将输入噪声信号映射到它们各自的纯净的对应物。这是我们期待实施的一种有趣的可能性。
Conclusion
音频去噪是一个长期存在的问题。通过遵循本文中描述的方法,我们以相对较小的努力获得了可接受的结果。轻量级模型的好处使它对边缘应用领域非常有趣。作为下一步,我们希望探索新的损失函数和模型训练程序。
你可以在这里得到完整的代码。
非常感谢您的阅读!