【Linux初阶】进程优先级 & 进程切换
hello,各位读者大大们你们好呀
系列专栏:【Linux初阶】
✒️✒️本篇内容:进程优先级的基本概念,查看进程优先级,top指令修改进程优先级,进程切换的相关内容,CPU功能概括,CPU查找内存代码方法,时间片概念,进程数据保护与恢复
作者简介:本科在读,计算机海洋的新进船长一枚,请多多指教( •̀֊•́ ) ̖́-
目录
一、进程优先级
1.基本概念
2.查看系统进程 /查看进程优先级
(1)PRI and NI
(2)PRI vs NI
3.更改进程优先级命令 - top
4.相关概念(竞争性/独立性/并行/并发)
二、进程切换
1.CPU能干什么?
2.CPU是如何在内存中找到对应的代码的?
3.一个进程不会一直占用CPU资源运行直至进程结束
4.一个进程在CPU内会运行多久?
5.进程切换下进程得以推进的基础-进程数据保存与恢复
一、进程优先级
1.基本概念
优先级和我们学过的权限有着本质的区别。权限是代表着一件事我们能不能做,而优先级代表的是一件事我们是先做还是后做的问题。
那么问题来了为什么会存在优先级呢?答案是计算机的资源是有限的。举一个例子,在一段时间内,要访问网卡的资源很多,但是网卡只有一个,唯有通过给进程设定优先级,重要的进程优先运行,最终实现资源的合理配置和运用。
Linux下的优先级设定十分简单,使得进程可以快速被选择和运行。事实上,优先级本质上是PCB中的一个整数数字(也可能是几个数字)。
补充:
- 进程的优先权/优先级(priority),就是cpu资源分配的先后顺序。
- 优先权高的进程有优先执行权利。配置进程优先权对多任务环境的linux很有用,可以改善系统性能。
- 还可以把进程运行到指定的CPU上,这样一来,把不重要的进程安排到某个CPU,可以大大改善系统整体性能。
2.查看系统进程 /查看进程优先级
在linux或者unix系统中,用 ps –la 命令则会类似输出以下几个内容:
 通过观察我们很容易注意到其中的几个重要信息,如下
通过观察我们很容易注意到其中的几个重要信息,如下
- UID : 代表执行者的身份
- PID : 代表这个进程的代号
- PPID :代表这个进程是由哪个进程发展衍生而来的,亦即父进程的代号
- PRI :代表这个进程可被执行的优先级,其值越小越早被执行,进程名来源于priority前三个字母大写
- NI :代表这个进程的nice
进程最终优先级 = 老的优先级(PRI)+ nice(NI)
Linux支持进程在运行中进行调整,调整的策略就是通过修改nice值(只能修改nice值),使得最终优先级改变。
(1)PRI and NI
PRI也还是比较好理解的,即进程的优先级,或者通俗点说就是程序被CPU执行的先后顺序,此值越小进程的优先级别越高。那NI呢?就是我们所要说的nice值了,其表示进程可被执行的优先级的修正数值。
PRI值越小越快被执行,那么加入nice值后,将会使得PRI变为:PRI(new)=PRI(old)+nice
无论我们如何修改nice值,PRI(old)的值都保持 80不变。
这样,当nice值为负值的时候,那么该程序将会优先级值将变小,即其优先级会变高,则其越快被执行。所以,调整进程优先级,在Linux下,就是调整进程nice值。
为了防止优先级被人为过度修改,保证操作系统的基本运行。nice其取值范围是-20至19,即[-20, 19],一共40个级别。最终我们可以知道 PRI(new) 的取值范围为[80 - 20, 80 + 19]。
(2)PRI vs NI
- 需要强调一点的是,进程的nice值不是进程的优先级,他们不是一个概念,但是进程nice值会影响到进程的优先级变化。
- 可以理解nice值是进程优先级的修正修正数据
3.更改进程优先级命令 - top
- top
- 进入top后按“r”–>输入进程PID–>输入nice值
- 输入“q”退出
Linux示例 :
创建循环文件
#include
#include
int main()
{
while (1)
{
printf("pid: %d\n", getpid());
sleep(1);
}
return 0;
} 输入top指令后,再输入 r(renice为更改nice的含义)
注意:修改优先级可能需要root权限,可在 top 指令前加 sudo

输入进程pid,开始修改

修改完成后,输入 q,退出
———— 我是一条知识分割线 ————
4.相关概念(竞争性/独立性/并行/并发)
- 竞争性: 系统进程数目众多,而CPU资源只有少量,甚至1个,所以进程之间是具有竞争属性的。为了高效完成任务,更合理竞争相关资源,便具有了优先级
- 独立性: 多进程运行,需要独享各种资源,多进程运行期间互不干扰(例:子进程崩溃不影响父进程继续运行)
- 并行: 多个进程在多个CPU下分别同时进行运行,这称之为并行
- 并发: 多个进程在一个CPU下采用进程切换的方式,在一段时间之内,让多个进程都得以推进,称之为并发
二、进程切换
通过对上文并发概念的学习,我们知道了,在一段时间内,通过进程切换,可以让多个进程同时可以推进。那么进程切换是什么呢?它又是怎么实现的呢?为了解答这些问题,让我们开启下面的学习吧!
1.CPU能干什么?
首先,我们要知道CPU能干什么?
CPU概括起来,主要干三件事:1.取指令;2.分析指令;3.执行指令。
2.CPU是如何在内存中找到对应的代码的?
其次,我们要知道,CPU是如何在内存中找到对应的代码的?
- 每个CPU中都含有一套寄存器(一套内有多个),其中有部分关键寄存器储存了PCB(进程控制块)的地址,通过PCB就可以找到对应的代码数据(可以具体到某行或者某个指令)。
- 寄存器 pc/eip保存的就是当前正在执行指令的下一条指令的地址。
- 当我们的进程在运行时,一定会产生非常多的临时数据,这份数据属于当前进程!
- CPU内部虽然只有一套寄存器硬件,但是,寄存器里面保存的数据,只属于当前进程。
- 寄存器硬件 != 寄存器内的数据
———— 我是一条知识分割线 ————
3.一个进程不会一直占用CPU资源运行直至进程结束
上面的文章中,我们已经大概了解了CPU是如何获取代码的,接下来,我们还需要知道:
- 进程在运行的时候,占用CPU,但是,进程不是一直占有到进程结束。
- 例如有一个死循环程序在运行,假设他需要占用到进程结束,那其他程序将会被卡死,永远无法使用。事实上,这种情况并不存在,我们在循环程序运行过程中,依旧可以输入指令停止它的运行,或者进行一些其他的操作。
4.一个进程在CPU内会运行多久?
那一个进程在CPU内运行多久呢?这取决于该进程的时间片。
也是从这里开始出现了进程切换的概念。
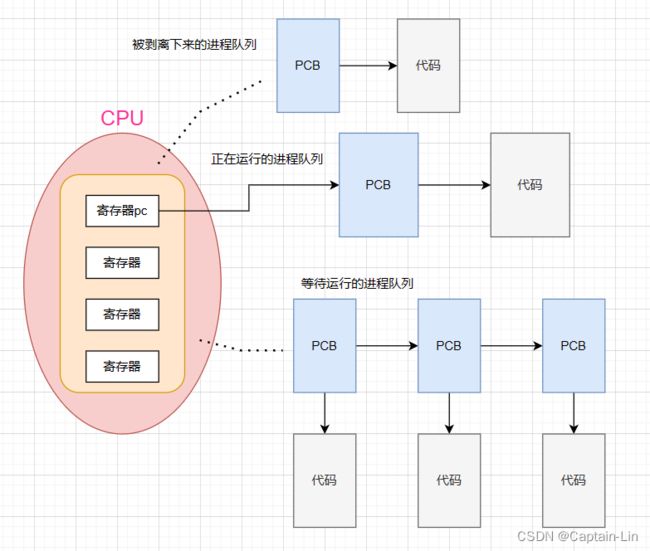
每一个进程在Linux当中,都有属于自己的时间片。即CPU给予该进程的运行时间,一个进程运行特定时间后,无论这个进程是否运行完成,都会被CPU剥离下来,等待下一次运行,CPU会更换其他进程运行。
———— 我是一条知识分割线 ————
5.进程切换下进程得以推进的基础-进程数据保存与恢复
为了进程在下一次被CPU运行时能够及时恢复正常运行,进程在被剥离下来时需要保存相关的运行情况的数据(这里的数据来源与CPU内的寄存器数据,此处我们暂时将它认为是保存到PCB中)。而在一个未运行完成的进程重新开始占用CPU运行时,它首先需要从PCB中将它对应的数据进行恢复。
举一个简单的例子,计算机正在编译第100行代码1+1 = ?,CPU获取到内存里的代码数据后,刚刚把结果2计算出来,该进程的时间片到了,进程被剥离下来。此时计算机会将寄存器中代码运行到哪一行(pc/eip)、具体运行数据、运行结果等等的临时数据保存起来到PCB中,再将进程剥离下来,让别的进程占用CPU运行。隔了一段时间,该进程重新占用CPU资源,恢复对应数据,重新开始运行,将结果2返回给内存,结束该进程。其他进程以此类推,如果没有运行完成则重复上述动作。
总结:进程在切换时,需要进行上下文保护。当进程在恢复运行时,要进行上下文恢复。寄存器(硬件)被所有进程共享,但是寄存器内的数据,只属于当前进程。
———— 我是一条知识分割线 ————
那这时会有朋友问了,寄存器能放下我写的那么多的代码数据吗?
答案是不能的。但是,CPU只需要加载当前需要运行的这一行代码的相关数据就可以了,不需要将所有数据都加载到CPU中。
当然,你们可能也会有相关的担忧,进程的保护和恢复成本会不会很高?实际上,CPU/寄存器的速度远超我们常人的想象。
我们不得不接受的一个令人惊叹的事实是:CPU快得离谱。
我们常见的时间单位为:纳秒(ns,十亿分之一秒),毫秒(ms,千分之一秒),和秒(s)。在Core 2 3.0GHz(Intel Core 2 Duo 3.0GHz)上,大部分简单指令的执行只需要一个时钟周期,也就是1/3纳秒。即使是我们常见的电脑大型应用,CPU也可以在1秒内将它对应的程序运行很多遍,使得我们感觉上,好像是多个程序在同时运行。
举一个简单的例子,我可以在我的电脑上打开网易云音乐,微信,和CSDN,我可以一边挂着微信,一边听歌,一边写博客。
现在我们再回过头来看并发的概念,就不难理解 并发/进程切换 的实现原理了。并发: 多个进程在一个CPU下采用进程切换的方式,在一段时间之内,让多个进程都得以推进,称之为并发。通过进程切换,最终我们就可以实现并发式开发。
Linux进程优先级 & 进程切换 的知识大概就讲到这里啦,博主后续会继续更新更多Linux操作系统的相关知识,干货满满,如果觉得博主写的还不错的话,希望各位小伙伴不要吝啬手中的三连哦!你们的支持是博主坚持创作的动力!