高并发高可用之ElasticSearch
目录
- ES对比MySql数据库
- Docker下安装ES和kibana
- 增删改查操作
- 高级检索Query DSL
- 映射
- 安装中文IK分词器
- SpringBoot整合ES
- 实战应用
- ES集群
ES里面的数据怎么保持与mysql实时同步?
都存内存 数据不会越来越多吗?有过期时间吗?
ES对比MySql数据库
ES的数据存储在磁盘中,数据操作在内存中。
- 索引:数据库
- 类型:数据表
- 文档:表里的数据
- 属性:表列名
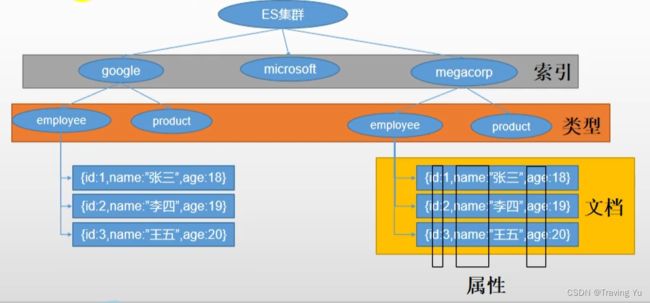
注意:ElasticSearch6.0之后移除了类型的概念。7.x使用类型会警告,8.x将彻底废除。
Docker下安装ES和kibana
安装ES
# 将docker里的目录挂载到linux的/mydata目录中
# 修改/mydata就可以改掉docker里的
mkdir -p /mydata/elasticsearch/config
mkdir -p /mydata/elasticsearch/data
# es可以被远程任何机器访问
echo "http.host: 0.0.0.0" >/mydata/elasticsearch/config/elasticsearch.yml
# 递归更改文件访问权限,es需要访问
chmod -R 777 /mydata/elasticsearch/
docker pull elasticsearch:7.4.2
docker pull kibana:7.4.2
版本要统一
# 9200是用户交互端口 9300是集群心跳端口
# -e指定是单阶段运行
# -e ES_JAVA_OPTS="-Xms64m -Xmx512m"指定初始占用内存大小和最大占用大小
# 反斜杠表示换行
docker run --name elasticsearch -p 9200:9200 -p 9300:9300 \
-e "discovery.type=single-node" \
-e ES_JAVA_OPTS="-Xms64m -Xmx512m" \
-v /mydata/elasticsearch/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml \
-v /mydata/elasticsearch/data:/usr/share/elasticsearch/data \
-v /mydata/elasticsearch/plugins:/usr/share/elasticsearch/plugins \
-d elasticsearch:7.4.2
# 设置开机启动elasticsearch
docker update elasticsearch --restart=always
查看日志命令:docker logs elasticsearch
查看docker镜像ID命令:docker ps -a
运行docker镜像:docker start 镜像ID
访问:
安装kibana
# 指定了ES交互端口9200和IP地址
docker run --name kibana -e ELASTICSEARCH_HOSTS=http://192.168.239.134:9200 -p 5601:5601 -d kibana:7.4.2
# 设置开机启动kibana
docker update kibana --restart=always
kibana访问地址:http://192.168.239.134:5601/
增删改查操作
(1)GET /_cat/nodes:查看所有节点
(2)GET /_cat/health:查看es健康状况
(3)GET /_cat/master:查看主节点
(4)GET /_cat/indices:查看所有索引 ,等价于mysql数据库的show databases;
新增/更新
PUT/POST /索引名/类型名/ID
http://192.168.56.10:9200/索引名/类型名/ID
请求参数Json:
{
"name":"John Doe"
}
支持put和post,post不写ID可以自动生产。对一个ID多次操作都会变为update操作。
查询
GET /索引名/类型名/ID
更新
POST /索引名/类型名/ID/_update
{
"doc":{
"name":"111"
}
}
加_update参数就要加doc。
POST时带_update会对比元数据,如果一样就不进行任何操作。
删除
删除文档数据
DELETE /索引名/类型名/ID
删除索引
DELETE /索引名
注:elasticsearch并没有提供删除类型的操作,只提供了删除索引和文档的操作。
批量执行
在指定索引和类型下批量执行
POST /索引名/类型名/_bulk
在整个ES中批量执行
POST /_bulk
高级检索Query DSL
-
query/match匹配查询
如果是非字符串,会进行精确匹配。如果是字符串,会进行全文检索GET bank/_search { "query": { "match": { "account_number": "20" } } } -
query/match_phrase 【不拆分匹配】
将需要匹配的值当成一整个单词(不分词)进行检索。
– match_phrase:不拆分字符串进行检索,包含就匹配成功。
– 字段.keyword:必须全匹配上才检索成功。GET bank/_search { "query": { "match_phrase": { "address": "990 Mill" } } }GET bank/_search { "query": { "match": { "address.keyword": "990 Mill" # 字段后面加上 .keyword } } } -
query/multi_math 【多字段匹配】
GET bank/_search { "query": { "multi_match": { # 前面的match仅指定了一个字段。 "query": "mill", "fields": [ # state和address有mill子串 不要求都有 "state", "address" ] } } } -
query/bool/must 【复合查询】
– must:必须达到must所列举的所有条件
– must_not:必须不匹配must_not所列举的所有条件。
– should:应该满足should所列举的条件。满足条件最好,不满足也可以,满足得分更高GET bank/_search { "query": { "bool": { "must": [ { "match": { "gender": "M" } }, { "match": { "address": "mill" } } ], "must_not": [ { "match": { "age": "18" } } ], "should": [ { "match": { "lastname": "Wallace" } } ] } } } -
query/filter 【结果过滤】
must 贡献得分
should 贡献得分
must_not 不贡献得分
filter 不贡献得分GET bank/_search { "query": { "bool": { "must": [ { "match": {"address": "mill" } } ], "filter": { # query.bool.filter "range": { "balance": { # 哪个字段 "gte": "10000", "lte": "20000" } } } } } } -
query/term
和match一样。匹配某个属性的值。
– 全文检索字段用match,
– 其他非text文本字段匹配用term。 -
aggs 【聚合】
复杂子聚合例子:查出所有年龄分布,并且这些年龄段中M的平均薪资和F的平均薪资以及这个年龄段的总体平均薪资GET bank/_search { "query": { "match_all": {} }, "aggs": { "ageAgg": { "terms": { # 看age分布 "field": "age", "size": 100 }, "aggs": { # 子聚合 "genderAgg": { "terms": { # 看gender分布 "field": "gender.keyword" # 注意这里,文本字段应该用.keyword }, "aggs": { # 子聚合 "balanceAvg": { "avg": { # 男性的平均 "field": "balance" } } } }, "ageBalanceAvg": { "avg": { #age分布的平均(男女) "field": "balance" } } } } }, "size": 0 }
更多Aggregations聚合函数请参考官方文档:https://www.elastic.co/guide/en/elasticsearch/reference/7.5/search-aggregations.html
映射
存入数据后ES会把字段自动映射一个数据类型。如果自动映射的数据类型不正确还可以手动指定映射。
创建索引并指定映射
PUT /my_index
{
"mappings": {
"properties": {
"age": {
"type": "integer"
},
"email": {
"type": "keyword" # 指定为keyword
},
"name": {
"type": "text" # 全文检索。保存时候分词,检索时候进行分词匹配
}
}
}
}
查看映射:GET /my_index
有映射的情况下添加新的字段并指定映射
PUT /my_index/_mapping
{
"properties": {
"employee-id": {
"type": "keyword",
"index": false # 字段不能被检索。检索
}
}
}
更新映射
由于改变映射会影响到该字段下的数据,故想要更新映射只支持把数据迁移到新的映射规则下。
数据迁移:
POST _reindex
{
"source": {
"index": "bank", #数据源索引
"type": "account" #6.0后没有类型可以不写该行
},
"dest": {
"index": "newbank" #要迁移到的新索引
}
}
安装中文IK分词器
下载并解压elasticsearch-analysis-ik-7.4.2到安装ES时挂载的插件外部目录/mydata/elasticsearch/plugins
配置ik插件目录访问权限并重启ES容器
注意:IK版本必须和ES版本一致
使用:
支持两种分词模式:ik_smart , ik_max_word
GET _analyze
{
"analyzer": "ik_smart",
"text":"我是中国人"
}
扩展IK分词器有两种方式
- 编写一个项目让IK访问。
- 词条配置到一个nginx让IK访问
– 在nginx的html目录下创建es目录并创建fenci.txt文件,在fenci.txt中写入自定义的词语,每行一条。
– 修改/plugins/ik/config中的IKAnalyzer.cfg.xml文件:
– 配置远程扩展字典访问地址<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd"> <properties> <comment>IK Analyzer 扩展配置</comment> <!--用户可以在这里配置自己的扩展字典 --> <entry key="ext_dict"></entry> <!--用户可以在这里配置自己的扩展停止词字典--> <entry key="ext_stopwords"></entry> <!--用户可以在这里配置远程扩展字典 --> <entry key="remote_ext_dict">http://192.168.56.10/es/fenci.txt</entry> <!--用户可以在这里配置远程扩展停止词字典--> <!-- <entry key="remote_ext_stopwords">words_location</entry> --> </properties>
参考:https://github.com/medcl/elasticsearch-analysis-ik
SpringBoot整合ES
推荐使用Elasticsearch-Rest-Client:官方RestClient,封装了ES操作,API层次分明,上手简单。
-
创建一个es-search微服务,可以勾选spring web组件,依赖common模块,配置注册中心,配置中心等配置
-
引入maven依赖,依赖版本要和ES版本保持一致
<dependency> <groupId>org.elasticsearch.clientgroupId> <artifactId>elasticsearch-rest-high-level-clientartifactId> <version>7.4.2version> dependency>由于当前spring-boot版本默认依赖管理的ES版本是6.8.5,故要改为手动管理ES版本
<properties> <java.version>1.8java.version> <elasticsearch.version>7.4.2elasticsearch.version> properties> -
编写ES配置类
@Configuration public class ESConfig { //对所有请求进行配置项 public static final RequestOptions COMMON_OPTIONS; static { RequestOptions.Builder builder = RequestOptions.DEFAULT.toBuilder(); COMMON_OPTIONS = builder.build(); } @Bean public RestHighLevelClient esRestClient() { // 这里可以一次性指定多个es RestClientBuilder builder = RestClient.builder(new HttpHost("192.168.239.134", 9200, "http")); RestHighLevelClient client = new RestHighLevelClient(builder); return client; } } -
使用,参考官方文档 https://www.elastic.co/guide/en/elasticsearch/client/java-rest/current/java-rest-high-getting-started-initialization.html
package com.example.essearch; import com.alibaba.fastjson.JSON; import com.example.essearch.config.ESConfig; import org.elasticsearch.action.index.IndexRequest; import org.elasticsearch.action.index.IndexResponse; import org.elasticsearch.action.search.SearchRequest; import org.elasticsearch.action.search.SearchResponse; import org.elasticsearch.client.RestHighLevelClient; import org.elasticsearch.common.xcontent.XContentType; import org.elasticsearch.index.query.QueryBuilders; import org.elasticsearch.search.SearchHit; import org.elasticsearch.search.SearchHits; import org.elasticsearch.search.aggregations.AggregationBuilders; import org.elasticsearch.search.aggregations.Aggregations; import org.elasticsearch.search.aggregations.bucket.terms.Terms; import org.elasticsearch.search.aggregations.bucket.terms.TermsAggregationBuilder; import org.elasticsearch.search.aggregations.metrics.Avg; import org.elasticsearch.search.aggregations.metrics.AvgAggregationBuilder; import org.elasticsearch.search.builder.SearchSourceBuilder; import org.junit.jupiter.api.Test; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.boot.test.context.SpringBootTest; import java.io.IOException; @SpringBootTest class EsSearchApplicationTests { @Autowired private RestHighLevelClient client; /** * 创建/更新索引 * @throws IOException */ @Test public void indexData() throws IOException { User user = new User(); user.setUserName("张三"); user.setAge(20); user.setGender("男"); String jsonString = JSON.toJSONString(user); // 设置索引,索引名为users IndexRequest indexRequest = new IndexRequest ("users"); indexRequest.id("1"); //设置要保存的内容,指定数据和类型 indexRequest.source(jsonString, XContentType.JSON); //执行创建索引和保存数据 IndexResponse index = client.index(indexRequest, ESConfig.COMMON_OPTIONS); System.out.println(index); } /** * 高级检索与聚合分析 * @throws IOException */ @Test public void searchData() throws IOException { SearchSourceBuilder sourceBuilder = new SearchSourceBuilder(); // 构造检索条件 //sourceBuilder.query(); //sourceBuilder.from(); //sourceBuilder.size(); //sourceBuilder.aggregation(); sourceBuilder.query(QueryBuilders.matchQuery("address","mill")); // 聚合 //AggregationBuilders工具类构建AggregationBuilder // 构建第一个聚合条件:按照年龄的值分布 TermsAggregationBuilder agg1 = AggregationBuilders.terms("agg1").field("age").size(10);// 设置聚合名称为agg1 sourceBuilder.aggregation(agg1); // 构建第二个聚合条件:平均薪资 AvgAggregationBuilder agg2 = AggregationBuilders.avg("agg2").field("balance");// 设置聚合名称为agg2 sourceBuilder.aggregation(agg2); System.out.println("检索条件"+sourceBuilder.toString()); // 1 创建检索请求 SearchRequest searchRequest = new SearchRequest(); searchRequest.indices("bank"); //设置请求索引为bank searchRequest.source(sourceBuilder); // 2 执行检索 SearchResponse response = client.search(searchRequest, ESConfig.COMMON_OPTIONS); // 3 分析响应结果 System.out.println(response.toString()); // 3.1 获取java bean SearchHits hits = response.getHits(); SearchHit[] hitsList = hits.getHits(); for (SearchHit hit : hitsList) { hit.getId(); hit.getIndex(); String sourceAsString = hit.getSourceAsString(); Account account = JSON.parseObject(sourceAsString, Account.class); System.out.println(account); } // 3.2 获取检索到的聚合分析信息 Aggregations aggregations = response.getAggregations(); Terms agg1Terms = aggregations.get("agg1"); for (Terms.Bucket bucket : agg1Terms.getBuckets()) { String keyAsString = bucket.getKeyAsString(); System.out.println("年龄:"+keyAsString+"=====>"+bucket.getDocCount()); } Avg agg2Avg = aggregations.get("agg2"); System.out.println("平均薪资:"+agg2Avg.getValue()); } class User{ private String userName; private Integer age; private String gender; public String getUserName() { return userName; } public void setUserName(String userName) { this.userName = userName; } public Integer getAge() { return age; } public void setAge(Integer age) { this.age = age; } public String getGender() { return gender; } public void setGender(String gender) { this.gender = gender; } } static class Account { private int account_number; private int balance; private String firstname; private String lastname; private int age; private String gender; private String address; private String employer; private String email; private String city; private String state; public void setAccount_number(int account_number){ this.account_number = account_number; } public int getAccount_number(){ return this.account_number; } public void setBalance(int balance){ this.balance = balance; } public int getBalance(){ return this.balance; } public void setFirstname(String firstname){ this.firstname = firstname; } public String getFirstname(){ return this.firstname; } public void setLastname(String lastname){ this.lastname = lastname; } public String getLastname(){ return this.lastname; } public void setAge(int age){ this.age = age; } public int getAge(){ return this.age; } public void setGender(String gender){ this.gender = gender; } public String getGender(){ return this.gender; } public void setAddress(String address){ this.address = address; } public String getAddress(){ return this.address; } public void setEmployer(String employer){ this.employer = employer; } public String getEmployer(){ return this.employer; } public void setEmail(String email){ this.email = email; } public String getEmail(){ return this.email; } public void setCity(String city){ this.city = city; } public String getCity(){ return this.city; } public void setState(String state){ this.state = state; } public String getState(){ return this.state; } } }
实战应用
ES数据模型结构的设计
空间和时间不可兼得两种只能选其一。
方案1:
{
skuId:1
spuId:11
skyTitile:华为xx
price:999
saleCount:99
attr:[
{尺寸:5},
{CPU:高通945},
{分辨率:全高清}
]
缺点:如果每个sku都存储规格参数(如尺寸),会有冗余存储,因为每个spu对应的sku的规格参数都一样
方案2:
sku索引
{
spuId:1
skuId:11
}
attr索引
{
skuId:11
attr:[
{尺寸:5},
{CPU:高通945},
{分辨率:全高清}
]
}
先找到4000个符合要求的spu,再根据4000个spu查询对应的属性,封装了4000个id,
每次传输大小:如id为long类型,8B*4000=32000B=32KB
1K个人检索,就是32MB,高并发下会造成严重阻塞。
结论:如果将规格参数单独建立索引,会出现检索时出现大量数据传输的问题,会引起网络网络
创建索引并设置映射
PUT product
{
"mappings":{
"properties": {
"skuId":{ "type": "long" },
"spuId":{ "type": "keyword" }, # 不可分词
"skuTitle": {
"type": "text",
"analyzer": "ik_smart" # 中文分词器
},
"skuPrice": { "type": "keyword" },
"skuImg" : {
"type": "keyword" ,
"index": false, # 降低占用空间,不可被检索,不生成索引,只用做页面展示
"doc_values": false # 降低占用空间,不可被聚合,默认为true
},
"saleCount":{ "type":"long" },
"hasStock": { "type": "boolean" },
"hotScore": { "type": "long" },
"brandId": { "type": "long" },
"catalogId": { "type": "long" },
"brandName": { "type": "keyword" },
"brandImg":{
"type": "keyword",
"index": false,
"doc_values": false
},
"catalogName": {"type": "keyword" },
"attrs": {
"type": "nested", # 重要!!!表示嵌入式,防止被ES自动扁平化处理
"properties": {
"attrId": {"type": "long" },
"attrName": {
"type": "keyword",
"index": false,
"doc_values": false
},
"attrValue": {"type": "keyword" }
}
}
}
}
}
创建ES数据模型实体类
@Data
public class SkuEsModel {
private Long skuId;
private Long spuId;
private String skuTitle;
private BigDecimal skuPrice;
private String skuImg;
private Long saleCount;
private Boolean hasStock;
private Long hotScore;
private Long brandId;
private Long catalogId;
private String brandName;
private String brandImg;
private String catalogName;
private List<Attr> attrs;
@Data
public static class Attr{
private Long attrId;
private String attrName;
private String attrValue;
}
}
封装数据到ES数据模型实体类并存入ES
商品上架的同时进行封装商品数据并远程调用ES微服务保存到ES中
(封装代码略)
编写ES微服务保存数据的Controller层
/*** 上架商品*/
@PostMapping("/product") // ElasticSaveController
public R productStatusUp(@RequestBody List<SkuEsModel> skuEsModels){
boolean status;
try {
status = productSaveService.productStatusUp(skuEsModels);
} catch (IOException e) {
log.error("ElasticSaveController商品上架错误: {}", e);
return R.error(BizCodeEnum.PRODUCT_UP_EXCEPTION.getCode(), BizCodeEnum.PRODUCT_UP_EXCEPTION.getMsg());
}
if(!status){
return R.ok();
}
return R.error(BizCodeEnum.PRODUCT_UP_EXCEPTION.getCode(), BizCodeEnum.PRODUCT_UP_EXCEPTION.getMsg());
}
编写ES微服务保存数据的Service层
public class ProductSaveServiceImpl implements ProductSaveService {
@Resource
private RestHighLevelClient client;
/**
* 将数据保存到ES
* 用bulk代替index,进行批量保存
* BulkRequest bulkRequest, RequestOptions options
*/
@Override // ProductSaveServiceImpl
public boolean productStatusUp(List<SkuEsModel> skuEsModels) throws IOException {
// 1.给ES建立一个索引 product
BulkRequest bulkRequest = new BulkRequest();
// 2.构造保存请求
for (SkuEsModel esModel : skuEsModels) {
// 设置es索引
IndexRequest indexRequest = new IndexRequest(EsConstant.PRODUCT_INDEX);
// 设置索引id
indexRequest.id(esModel.getSkuId().toString());
// json格式
String jsonString = JSON.toJSONString(esModel);
indexRequest.source(jsonString, XContentType.JSON);
// 添加到文档
bulkRequest.add(indexRequest);
}
// bulk批量保存
BulkResponse bulk = client.bulk(bulkRequest, GuliESConfig.COMMON_OPTIONS);
// TODO 是否拥有错误
boolean hasFailures = bulk.hasFailures();
if(hasFailures){
List<String> collect = Arrays.stream(bulk.getItems()).map(item -> item.getId()).collect(Collectors.toList());
log.error("商品上架错误:{}",collect);
}
return hasFailures;
}
}
检索查询参数模型分析
可能用到的参数:
全文检索:skuTitle->keyword
排序:saleCount(销量)、hotScore(热度分)、skuPrice(价格)
过滤:hasStock、skuPrice区间、brandId、catalog3Id、attrs(规格属性)
聚合:attrs
/**
封装页面所有可能传递过来的关键字
* catalog3Id=225&keyword=华为&sort=saleCount_asc&hasStock=0/1&brandId=25&brandId=30
*/
@Data
public class SearchParam {
// 页面传递过来的全文匹配关键字
private String keyword;
/** 三级分类id*/
private Long catalog3Id;
//排序条件:sort=price/salecount/hotscore_desc/asc
private String sort;
// 仅显示有货
private Integer hasStock;
/*** 价格区间 */
private String skuPrice;
/*** 品牌id 可以多选 */
private List<Long> brandId;
/*** 按照属性进行筛选 */
private List<String> attrs;
/*** 页码*/
private Integer pageNum = 1;
/*** 原生所有查询属性*/
private String _queryString;
}
检索返回结果模型分析
/**
* Title: SearchResponse
* Description:包含页面需要的所有信息
*/
@Data
public class SearchResult {
/** * 查询到的所有商品信息(即前面的ES数据模型实体类)*/
private List<SkuEsModel> products;
/*** 当前页码*/
private Integer pageNum;
/** 总记录数*/
private Long total;
/** * 总页码*/
private Integer totalPages;
/** 当前查询到的结果, 所有涉及到的品牌*/
private List<BrandVo> brands;
/*** 当前查询到的结果, 所有涉及到的分类*/
private List<CatalogVo> catalogs;
/** * 当前查询的结果 所有涉及到所有属性*/
private List<AttrVo> attrs;
/** 导航页 页码遍历结果集(分页) */
private List<Integer> pageNavs;
// ================以上是返回给页面的所有信息================
/** 导航数据*/
private List<NavVo> navs = new ArrayList<>();
/** 便于判断当前id是否被使用*/
private List<Long> attrIds = new ArrayList<>();
@Data
public static class NavVo {
private String name;
private String navValue;
private String link;
}
@Data
public static class BrandVo {
private Long brandId;
private String brandName;
private String brandImg;
}
@Data
public static class CatalogVo {
private Long catalogId;
private String catalogName;
}
@Data
public static class AttrVo {
private Long attrId;
private String attrName;
private List<String> attrValue;
}
}
写出DSL检索语句,(如果是嵌入式的映射属性字段,检索查询,聚合,分析等都应该用相应的嵌入式语法nested)
GET gulimall_product/_search
{
"query": {
"bool": {
"must": [ {"match": { "skuTitle": "华为" }} ], # 检索出华为
"filter": [ # 过滤
{ "term": { "catalogId": "225" } },
{ "terms": {"brandId": [ "2"] } },
{ "term": { "hasStock": "false"} },
{
"range": {
"skuPrice": { # 价格1K~7K
"gte": 1000,
"lte": 7000
}
}
},
{
"nested": {
"path": "attrs", # 聚合名字
"query": {
"bool": {
"must": [
{
"term": { "attrs.attrId": { "value": "6"} }
}
]
}
}
}
}
]
}
},
"sort": [ {"skuPrice": {"order": "desc" } } ],
"from": 0,
"size": 5,
"highlight": {
"fields": {"skuTitle": {}}, # 高亮的字段
"pre_tags": "", # 前缀
"post_tags": ""
},
"aggs": { # 查完后聚合
"brandAgg": {
"terms": {
"field": "brandId",
"size": 10
},
"aggs": { # 子聚合
"brandNameAgg": { # 每个商品id的品牌
"terms": {
"field": "brandName",
"size": 10
}
},
"brandImgAgg": {
"terms": {
"field": "brandImg",
"size": 10
}
}
}
},
"catalogAgg":{
"terms": {
"field": "catalogId",
"size": 10
},
"aggs": {
"catalogNameAgg": {
"terms": {
"field": "catalogName",
"size": 10
}
}
}
},
"attrs":{
"nested": {"path": "attrs" },
"aggs": {
"attrIdAgg": {
"terms": {
"field": "attrs.attrId",
"size": 10
},
"aggs": {
"attrNameAgg": {
"terms": {
"field": "attrs.attrName",
"size": 10
}
}
}
}
}
}
}
}
检索查询代码实现
controller
@GetMapping(value = {"/search.html","/"})
public String getSearchPage(SearchParam searchParam, // 检索参数,
Model model, HttpServletRequest request) {
searchParam.set_queryString(request.getQueryString());//_queryString是个字段
SearchResult result=searchService.getSearchResult(searchParam);
model.addAttribute("result", result);
return "search";
}
service
@Slf4j
@Service
public class ProductSearchServiceImpl {
@Resource
private RestHighLevelClient restHighLevelClient;
/**
* 根据请求参数检索ES数据,并将检索结果封装为系统返回响应实体类
* @param searchParam
* @return
*/
public SearchResult getSearchResult(SearchParam searchParam) {//根据带来的请求内容封装
SearchResult searchResult= null;
// 通过请求参数构建es查询请求
SearchRequest request = bulidSearchRequest(searchParam);
try {
SearchResponse searchResponse = restHighLevelClient.search(request,
ESConfig.COMMON_OPTIONS);
// 将es响应数据封装成结果
searchResult = bulidSearchResult(searchParam,searchResponse);
} catch (IOException e) {
e.printStackTrace();
}
return searchResult;
}
/**
* 通过请求参数构建ES查询请求
* @param searchParam
* @return
*/
private SearchRequest bulidSearchRequest(SearchParam searchParam) {
// 用于构建DSL语句
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
//1. 构建bool query
BoolQueryBuilder boolQueryBuilder = new BoolQueryBuilder();
//1.1 bool must
if (!StringUtils.isEmpty(searchParam.getKeyword())) {
boolQueryBuilder.must(QueryBuilders.matchQuery("skuTitle", searchParam.getKeyword()));
}
//使用不参与评分的filter,性能效率更高
//1.2 bool filter
//1.2.1 catalog
if (searchParam.getCatalog3Id()!=null){
boolQueryBuilder.filter(QueryBuilders.termQuery("catalogId", searchParam.getCatalog3Id()));
}
//1.2.2 brand
if (searchParam.getBrandId()!=null&&searchParam.getBrandId().size()>0) {
//值有多个为List时termsQuery
boolQueryBuilder.filter(QueryBuilders.termsQuery("brandId",searchParam.getBrandId()));
}
//1.2.3 hasStock
if (searchParam.getHasStock() != null) {
boolQueryBuilder.filter(QueryBuilders.termQuery("hasStock", searchParam.getHasStock() == 1));
}
//1.2.4 priceRange
//解析自定义的区间参数格式,这里为0_6000,_6000,6000_分别表示大于0小于6000,小于6000,大于6000
RangeQueryBuilder rangeQueryBuilder = QueryBuilders.rangeQuery("skuPrice");
if (!StringUtils.isEmpty(searchParam.getSkuPrice())) {
String[] prices = searchParam.getSkuPrice().split("_");
if (prices.length == 1) {
if (searchParam.getSkuPrice().startsWith("_")) {
rangeQueryBuilder.lte(Integer.parseInt(prices[0]));
}else {
rangeQueryBuilder.gte(Integer.parseInt(prices[0]));
}
} else if (prices.length == 2) {
//_6000会截取成["","6000"]
if (!prices[0].isEmpty()) {
rangeQueryBuilder.gte(Integer.parseInt(prices[0]));
}
rangeQueryBuilder.lte(Integer.parseInt(prices[1]));
}
boolQueryBuilder.filter(rangeQueryBuilder);
}
//1.2.5 attrs-nested 嵌入式属性使用嵌入式语法
//attrs=1_5寸:8寸&2_16G:8G
List<String> attrs = searchParam.getAttrs();
BoolQueryBuilder queryBuilder = new BoolQueryBuilder();
if (attrs!=null&&attrs.size() > 0) {
attrs.forEach(attr->{
String[] attrSplit = attr.split("_");
queryBuilder.must(QueryBuilders.termQuery("attrs.attrId", attrSplit[0]));
String[] attrValues = attrSplit[1].split(":");
queryBuilder.must(QueryBuilders.termsQuery("attrs.attrValue", attrValues));
});
}
NestedQueryBuilder nestedQueryBuilder = QueryBuilders.nestedQuery("attrs", queryBuilder, ScoreMode.None);
boolQueryBuilder.filter(nestedQueryBuilder);
//1.X bool query构建完成
searchSourceBuilder.query(boolQueryBuilder);
//2. sort eg:sort=saleCount_desc/asc
if (!StringUtils.isEmpty(searchParam.getSort())) {
String[] sortSplit = searchParam.getSort().split("_");
searchSourceBuilder.sort(sortSplit[0], sortSplit[1].equalsIgnoreCase("asc") ? SortOrder.ASC : SortOrder.DESC);
}
//3. 分页 // 是检测结果分页
searchSourceBuilder.from((searchParam.getPageNum() - 1) * EsConstant.PRODUCT_PAGESIZE);
searchSourceBuilder.size(EsConstant.PRODUCT_PAGESIZE);
//4. 高亮highlight
if (!StringUtils.isEmpty(searchParam.getKeyword())) {
HighlightBuilder highlightBuilder = new HighlightBuilder();
highlightBuilder.field("skuTitle");
highlightBuilder.preTags("");
highlightBuilder.postTags("");
searchSourceBuilder.highlighter(highlightBuilder);
}
//5. 聚合
//5.1 按照brand聚合
TermsAggregationBuilder brandAgg = AggregationBuilders.terms("brandAgg").field("brandId");
TermsAggregationBuilder brandNameAgg = AggregationBuilders.terms("brandNameAgg").field("brandName");
TermsAggregationBuilder brandImgAgg = AggregationBuilders.terms("brandImgAgg").field("brandImg");
//通过子聚合的方式就可以获取brand的中文名和图片了!!!
brandAgg.subAggregation(brandNameAgg);
brandAgg.subAggregation(brandImgAgg);
searchSourceBuilder.aggregation(brandAgg);
//5.2 按照catalog聚合
TermsAggregationBuilder catalogAgg = AggregationBuilders.terms("catalogAgg").field("catalogId");
// 子聚合
TermsAggregationBuilder catalogNameAgg = AggregationBuilders.terms("catalogNameAgg").field("catalogName");
catalogAgg.subAggregation(catalogNameAgg);
searchSourceBuilder.aggregation(catalogAgg);
//5.3 按照attrs聚合 嵌入式属性使用嵌入式聚合语法
NestedAggregationBuilder nestedAggregationBuilder = new NestedAggregationBuilder("attrs", "attrs");
//按照attrId聚合 //按照attrId聚合之后再按照attrName和attrValue聚合
TermsAggregationBuilder attrIdAgg = AggregationBuilders.terms("attrIdAgg" ).field("attrs.attrId");
TermsAggregationBuilder attrNameAgg = AggregationBuilders.terms("attrNameAgg" ).field("attrs.attrName");
TermsAggregationBuilder attrValueAgg = AggregationBuilders.terms("attrValueAgg").field("attrs.attrValue");
attrIdAgg.subAggregation(attrNameAgg);
attrIdAgg.subAggregation(attrValueAgg);
nestedAggregationBuilder.subAggregation(attrIdAgg);
searchSourceBuilder.aggregation(nestedAggregationBuilder);
log.debug("构建的DSL语句 {}",searchSourceBuilder.toString());
SearchRequest request = new SearchRequest(new String[]{EsConstant.PRODUCT_INDEX}, searchSourceBuilder);
return request;
}
/**
* 将ES响应数据封装成结果
* @param searchParam
* @param searchResponse
* @return
*/
private SearchResult bulidSearchResult(SearchParam searchParam, SearchResponse searchResponse) {
SearchResult result = new SearchResult();
SearchHits hits = searchResponse.getHits();
//1. 封装查询到的商品信息
if (hits.getHits()!=null&&hits.getHits().length>0){
List<SkuEsModel> skuEsModels = new ArrayList<>();
for (SearchHit hit : hits) {
String sourceAsString = hit.getSourceAsString();
SkuEsModel skuEsModel = JSON.parseObject(sourceAsString, SkuEsModel.class);
//设置高亮属性
if (!StringUtils.isEmpty(searchParam.getKeyword())) {
HighlightField skuTitle = hit.getHighlightFields().get("skuTitle");
String highLight = skuTitle.getFragments()[0].string();
skuEsModel.setSkuTitle(highLight);
}
skuEsModels.add(skuEsModel);
}
result.setProducts(skuEsModels);
}
//2. 封装分页信息
//2.1 当前页码
result.setPageNum(searchParam.getPageNum());
//2.2 总记录数
long total = hits.getTotalHits().value;
result.setTotal(total);
//2.3 总页码
Integer totalPages = (int)total % EsConstant.PRODUCT_PAGESIZE == 0 ?
(int)total / EsConstant.PRODUCT_PAGESIZE : (int)total / EsConstant.PRODUCT_PAGESIZE + 1;
result.setTotalPages(totalPages);
List<Integer> pageNavs = new ArrayList<>();
for (int i = 1; i <= totalPages; i++) {
pageNavs.add(i);
}
result.setPageNavs(pageNavs);
//3. 查询结果涉及到的品牌
List<SearchResult.BrandVo> brandVos = new ArrayList<>();
Aggregations aggregations = searchResponse.getAggregations();
//ParsedLongTerms用于接收terms聚合的结果,并且可以把key转化为Long类型的数据
ParsedLongTerms brandAgg = aggregations.get("brandAgg");
for (Terms.Bucket bucket : brandAgg.getBuckets()) {
//3.1 得到品牌id
Long brandId = bucket.getKeyAsNumber().longValue();
//获取子聚合拿到brand中文名和图片
Aggregations subBrandAggs = bucket.getAggregations();
//3.2 得到品牌图片
ParsedStringTerms brandImgAgg=subBrandAggs.get("brandImgAgg");
String brandImg = brandImgAgg.getBuckets().get(0).getKeyAsString();
//3.3 得到品牌名字
Terms brandNameAgg=subBrandAggs.get("brandNameAgg");
String brandName = brandNameAgg.getBuckets().get(0).getKeyAsString();
SearchResult.BrandVo brandVo = new SearchResult.BrandVo(brandId, brandName, brandImg);
brandVos.add(brandVo);
}
result.setBrands(brandVos);
//4. 查询涉及到的所有分类
List<SearchResult.CatalogVo> catalogVos = new ArrayList<>();
ParsedLongTerms catalogAgg = aggregations.get("catalogAgg");
for (Terms.Bucket bucket : catalogAgg.getBuckets()) {
//4.1 获取分类id
Long catalogId = bucket.getKeyAsNumber().longValue();
Aggregations subcatalogAggs = bucket.getAggregations();
//4.2 获取分类名
ParsedStringTerms catalogNameAgg=subcatalogAggs.get("catalogNameAgg");
String catalogName = catalogNameAgg.getBuckets().get(0).getKeyAsString();
SearchResult.CatalogVo catalogVo = new SearchResult.CatalogVo(catalogId, catalogName);
catalogVos.add(catalogVo);
}
result.setCatalogs(catalogVos);
//5 查询涉及到的所有属性
List<SearchResult.AttrVo> attrVos = new ArrayList<>();
//ParsedNested用于接收内置嵌入式属性的聚合
ParsedNested parsedNested=aggregations.get("attrs");
ParsedLongTerms attrIdAgg=parsedNested.getAggregations().get("attrIdAgg");
for (Terms.Bucket bucket : attrIdAgg.getBuckets()) {
//5.1 查询属性id
Long attrId = bucket.getKeyAsNumber().longValue();
//获取子聚合
Aggregations subAttrAgg = bucket.getAggregations();
//5.2 查询属性名
ParsedStringTerms attrNameAgg=subAttrAgg.get("attrNameAgg");
String attrName = attrNameAgg.getBuckets().get(0).getKeyAsString();
//5.3 查询属性值
ParsedStringTerms attrValueAgg = subAttrAgg.get("attrValueAgg");
List<String> attrValues = new ArrayList<>();
for (Terms.Bucket attrValueAggBucket : attrValueAgg.getBuckets()) {
String attrValue = attrValueAggBucket.getKeyAsString();
attrValues.add(attrValue);
List<SearchResult.NavVo> navVos = new ArrayList<>();
}
SearchResult.AttrVo attrVo = new SearchResult.AttrVo(attrId, attrName, attrValues);
attrVos.add(attrVo);
}
result.setAttrs(attrVos);
return result;
}
}
ES集群
ELasticsearch的集群是由多个节点组成的,通过cluster.name设置集群名称,并且用于区分其它的集群,每个节点通过node.name指定节点的名称。
ES集群中的节点类型:
1、主节点
主节点负责创建索引、删除索引、分配分片、追踪集群中的节点状态等工作。ElasticSearch中的主节点的工作量相对较轻,用户的请求可以发往集群中任何一个节点,由该节点负责分发和返回结果,而不需要经过主节点转发。而主节点是由候选主节点通过ZenDiscovery机制选举出来的,所以要想成为主节点,首先要先成为候选主节点。
2、候选主节点
在ElasticSearch集群初始化或者主节点宕机的情况下,由候选主节点中选举其中一个作为主节点。指定候选主节点的配置为:node.master:true。
3、数据节点
数据节点负责数据的存储和相关具体操作,比如CRUD、搜索、聚合。所以,数据节点对机器配置要求比较高,首先需要有足够的磁盘空间来存储数据,其次数据操作对系统CPU、Memory和IO的性能消耗都很大。通常随着集群的扩大,需要增加更多的数据节点来提高可用性。指定数据节点的配置:node.data:true。
ElasticSearch是允许一个节点既做候选主节点也做数据节点的,但是数据节点的负载较重,所以需要考虑将二者分离开,设置专用的候选主节点和数据节点,避免因数据节点负责重导致主节点不响应。
4、客户端节点
客户端节点就是既不做候选主节点也不做数据节点的节点,只负责请求的分发、汇总等等,但是这样的工作,其实任何一个节点都可以完成,因为在ElasticSearch中一个集群内的节点都可以执行任何请求,其会负责将请求转发给对应的节点进行处理。所以单独增加这样的节点更多是为了负载均衡。指定该节点的配置为:
node.master:false
node.data:false
分片
为了将数据添加到Elasticsearch,我们需要索引(index)——一个存储关联数据的地方。实际上,索引只是一个用来指向一个或多个分片(shards)的“逻辑命名空间(logical namespace)”.

集群新增节点
-
向集群增加一个节点前后,索引发生了些什么。在左端,索引的主分片全部分配到节点 Node1,而副本分片没有地方分配。在这种状态下,集群是黄色的。
-
一旦第二个节点加入,尚未分配的副本分片就会分配到新的节点 Node2,这使得集群变为了绿色的状态。
-
当另一个节点加入的时候,Elasticsearch 会自动地尝试将分片在所有节点上进行均匀分配。

集群参考:http://dljz.nicethemes.cn/news/show-107233.html
集群参考:https://blog.csdn.net/qq_40977118/article/details/123301013