linux系统调用和内存管理以及栈帧
linux编程和C++笔记
目录
- linux编程和C++笔记
-
- 0. terminal操作快捷键等
- 1. vfork的子进程return程序会挂掉,但exit不会
- 2. C++内存管理详解
- 3. 关于堆和自由存储区概念的区别
- 4. cache和buffer的区别
- 5. C++实现线程池
- 6. 静态函数和虚函数的区别
- 7. C++里是怎么定义常量的?常量存放在内存的哪个位置?
- 8. 编译链接程序过程
- 9. C和C++中的const变量存储在那
- 10. C++priority_queue
-
- 方法一:priority_queue
- 方法二:利用vector
- 11. 友元
- 12. gcc
-
- 语法
- 选项
- 参数
- 实例
- 头文件链接选项 -I
- 编译时定义宏-D
- 自测实例
- 13. find命令
- 14. linux系统目录和文件类型
- 15. ls
- 16. cp
- 17. cat
- 18. more
- 19. grep
- 20. echo
- 20. 补充命令
-
- 20.1 ps
- 20.2 &
- 20.3 man
- 21. vim
-
- 21.1 vim配置文件
- 21.2 vim命令及模式切换
- 22. gdb调试
-
- gdb交互命令
- 运行
- 设置断点
- 查看源代码
- 打印表达式
- 查询运行信息
- 分割窗口
- 23. Linux进程状态
-
- (1)进程状态
- 24. 环境变量
-
-
- Linux环境变量分类
- Linux设置环境变量的方法
- Linux环境变量使用
-
- 25. 内核空间和用户空间
- 26. Makefile
- 27. 中断处理流程
- 28. 内核信号捕捉过程
- 29. Linux x86程序启动-main如何被执行到
- 30. Linux内存管理
-
- (1)进程空间数据结构关系
- 31. valgrind调试
- 32. gdb core文件调试
- 33. 调试段错误的方法
- 34. 函数调用过程
- 35. linux内核解析笔记
-
- 35.1register 寄存器
- 35.2 寻址模式和简单指令
- 35.3 函数调用过程
- 36. linux下检查内存状态的命令
-
- **1、free命令**
- **2、vmstat命令**
- **3、top命令**
- **4、cat /proc/meminfo**
- 5、 ps aux命令
- 二. C++笔记
-
- 1. 局部变量和全局变量问题
-
- (1)全局变量和局部变量可否重名
- (2)如何引用一个已经定义过的全局变量
- (3)全局变量可不可以定义在可被多个.C文件包含的头文件中?为什么?
- (4)static全局变量与普通的全局变量有什么区别?static局部变量和普通局部变量有什么区别?static函数与普通函数有什么区别?
- 2.malloc的底层实现
- 3. extern”C” 的作用
- 三. Unix环境高级编程
-
- 3.1 标准IO
-
- (1) fopen
- (2) fgetc和fputc
- (3) fgets和gets
- (4) fread和fwrite
- (5) printf函数族
- (6)scanf函数族
- (7)文件指针定位函数
- (8) fflush
- (9)getline
- (10) 临时文件
- (11)dup和dup2
- 3.2 文件IO或系统调用io
- 3.3 文件系统
-
- (1)获取文件属性
- (2) 文件访问权限
- (3)umask
- (4)文件权限更改和管理
- (5) 黏着位
- (6)文件系统
-
- UFS系统:
-
- 引导块
- 超级块
- Inode
- 数据块
- 空闲块
- (7)硬链接和符号链接
- (8)utime
- (9) 目录的创建和销毁
- (10)更改当前工作路径
- (11)分析目录和读取目录内容
- 3.4 系统数据文件
- 3.5 进程环境
-
- (1)main
-
-
- ` int main(int argc,char* argv)`
-
- (2)进程的终止
-
- a. exit()
- (3)命令行参数分析
- (4) 跳转函数setjmp和longjmp
- (5)fork的父子进程区别
- 3.6 守护进程
- 3.7 信号
-
- (1) Kill
- (2) raise
- (3)alarm
- (4)pause
- (5)sigprocmask
- (6)不可重入函数
- (7)signal函数
- (8)sigaction
- 3.8 计时器
-
- (1)getitimer
- (2)setitimer
- 3.9 线程
-
- (1)创建线程
- (2)线程终止和取消
- (3)重入
- 3.10 高级IO
-
- (1)非阻塞IO
- (2)内存映射
- (3)文件锁
- 3.11 网络编程
-
- (1)socket
- timerfd+epoll使用
0. terminal操作快捷键等
终端的设置项
对终端的设置主要包括:配置文件首选项和键盘快捷键的设置。选择“编辑” 菜单进入相关的设置。
创建终端的标签页
1 通过 Ctrl+Shift+T 快捷键创建新标签页。
2 选择 “文件” 菜单 -> 选择“打开标签页” 选项。
3 在终端中,单击鼠标右键(或按下键盘上的Application 键),选择 “打开标签页” 选项。
终端默认的常用快捷键
| 快捷键 | 描述 |
|---|---|
| Ctrl+Alt+T | 启动终端 |
| F1 | 打开帮助指南 |
| F10 | 激活菜单栏 |
| F11 | 全屏切换 |
| Alt+F | 打开 “文件” 菜单(file) |
| Alt+E | 打开 “编辑” 菜单(edit) |
| Alt+V | 打开 “查看” 菜单(view) |
| Alt+S | 打开 “搜索” 菜单(search) |
| Alt+T | 打开 “终端” 菜单(terminal) |
| Alt+H | 打开 “帮助” 菜单(help) |
| Ctrl+Shift+C | 复制 |
| Ctrl+Shift+V | 粘贴 |
| Ctrl+Shift+T | 新建标签页 |
| Ctrl+ Shift+n | 在已有终端上打开一个新的终端窗口 |
| Ctrl+Shift+W | 关闭标签页 |
| Ctrl+Shift+N | 新建终端窗口 |
| Ctrl+Shift+Q | 关闭终端窗口 |
| Ctrl+Shift+PgUp | 标签页左移 |
| Ctrl+Shift+PgDn | 标签页右移 |
| Alt+N | 切换到第 N个标签页(N=0…9) |
| Ctrl+PgUp | 切换到上一个标签页(page up) |
| Ctrl+PgDn | 切换到下一个标签页(pagedown) |
| Ctrl+Alt+Fn | 切换到字符界面(n=1…6) 如果需要切换回图形界面,需要使用Ctrl+Alt+F7 或 Alt+F7 |
| Ctrl+Shift++ | 放大窗口(包括窗口内的字体) |
| Ctrl± | 缩写窗口(包括窗口内的字体) |
| Ctrl+0 | 普通大小(阿拉伯数字 0) |
| Ctrl+d | 关闭一个tab,即关闭一个终端上的标签 |
| Ctrl+P | 显示上一条历史命令(同 up arrow功能) |
| Ctrl+N | 显示下一条历史命令(同 down arrow功能) |
| Ctrl+R | 反向搜索历史命令 |
| Ctrl+O | 回车(同enter 键功能) |
| Ctrl+J | 回车(同enter 键功能) |
| Ctrl+M | 回车(同enter 键功能) |
| Ctrl+A | 光标移动到行的开头 |
| Ctrl+E | 光标移动到行的结尾 |
| Ctrl+B | 光标向后移动一个位置(backward) |
| Ctrl+F | 光标向前移动一个位置(forward) |
| Ctrl+Left-Arrow | 光标移动到上一个单词的词首 |
| Ctrl+Right-Arrow | 光标移动到下一个单词的词尾 |
| Ctrl+T | 将光标位置的字符和前一个字符进行位置交换 |
| Ctrl+U | 剪切从行的开头到光标前一个位置的所有字符 |
| Ctrl+K | 剪切从光标位置到行末的所有字符 |
| Ctrl+Y | 粘贴 ctrl+u或者 ctrl+k 剪切的内容 |
| Ctrl+H | 删除光标位置的前一个字符(同backspace 键功能) |
| Ctrl+* | 删除光标位置的前一个字符(同 ctrl+h组合键功能) |
| Ctrl+D | 删除光标位置的一个字符(同 delete键功能) |
| Ctrl+W | 删除光标位置的前一个单词(同alt+backspace 组合键功能) |
| Ctrl+& | 恢复 ctrl+h或者 ctrl+d 或者 ctrl+w 删除的内容 |
| Ctrl+L | 清除当前屏幕内容(同 clear命令功能) |
| Ctrl+S | 暂停屏幕输出 |
| Ctrl+Q | 继续屏幕输出 |
小技巧
在终端窗口命令提示符下,连续按两次 Tab键、或者连续按三次 Esc 键、或者按 Ctrl+I组合键,将显示所有的命令及工具名称。
1. vfork的子进程return程序会挂掉,但exit不会
下面我把问题和我的回答发布在这里,也供更多的人查看。<引用>
#include
#include
#include
int main(void) {
intvar;
var = 88;
if((pid = vfork()) < 0) {
printf("vfork error");
exit(-1);
} elseif(pid == 0) { /* 子进程 */
var++;
return0;
}
printf("pid=%d, glob=%d, var=%d\n", getpid(), glob, var);
return 0;
}
基础知识:
首先说一下fork和vfork的差别:
- fork 是 创建一个子进程,并把父进程的内存数据copy到子进程中。
- vfork是 创建一个子进程,并和父进程的内存数据share一起用。
这两个的差别是,一个是copy,一个是share。(关于fork,可以参看酷壳之前的《一道fork的面试题》)
你 man vfork 一下,你可以看到,vfork是这样的工作的,
1)保证子进程先执行。
2)当子进程调用exit()或exec()后,父进程往下执行。
那么,为什么要干出一个vfork这个玩意? 原因在man page也讲得很清楚了:
意思是这样的—— 起初只有fork,但是很多程序在fork一个子进程后就exec一个外部程序,于是fork需要copy父进程的数据这个动作就变得毫无意了,而且这样干还很重(注:后来,fork做了优化,详见本文后面),所以,BSD搞出了个父子进程共享的 vfork,这样成本比较低。因此,vfork本就是为了exec而生。
为什么return会挂掉,exit()不会?
从上面我们知道,结束子进程的调用是exit()而不是return,如果你在vfork中return了,那么,这就意味main()函数return了,注意因为函数栈父子进程共享,所以整个程序的栈就跪了。
如果你在子进程中return,那么基本是下面的过程:
1)子进程的main() 函数 return了,于是程序的函数栈发生了变化。
2)而main()函数return后,通常会调用 exit()或相似的函数(如:_exit(),exitgroup())
3)这时,父进程收到子进程exit(),开始从vfork返回,但是尼玛,老子的栈都被你子进程给return干废掉了,你让我怎么执行?(注:栈会返回一个诡异一个栈地址,对于某些内核版本的实现,直接报“栈错误”就给跪了,然而,对于某些内核版本的实现,于是有可能会再次调用main(),于是进入了一个无限循环的结果,直到vfork 调用返回 error)
好了,现在再回到 return 和 exit,return会释放局部变量,并弹栈,回到上级函数执行。exit直接退掉。如果你用c++ 你就知道,return会调用局部对象的析构函数,exit不会。(注:exit不是系统调用,是glibc对系统调用 _exit()或_exitgroup()的封装)
可见,子进程调用exit() 没有修改函数栈,所以,父进程得以顺利执行。
2. C++内存管理详解
内存分配方式
简介
在C++中,内存分成5个区,他们分别是堆、栈、自由存储区、全局/静态存储区和常量存储区。 C语言不包括自由存储区。
栈:在执行函数时,函数内局部变量的存储单元都可以在栈上创建,函数执行结束时这些存储单元自动被释放。栈内存分配运算内置于处理器的指令集中,效率很高,但是分配的内存容量有限。
堆:就是那些由 malloc分配的内存块,他们的释放编译器不去管,由我们的应用程序去控制,一般一个malloc就要对应一个 free。如果程序员没有释放掉,那么在程序结束后,操作系统会自动回收。(是C语言的概念)
自由存储区:就是那些由new等分配的内存块,他和堆是十分相似的,不过它是用delete来结束自己的生命的。(是C++的抽象概念,因为大多数new操作是基于malloc实现的,所以,这种情况下自由存储区和堆是一样的,C++对象是分配在堆上的。而如果new操作被重载后不使用Malloc分配内存,则所谓自由存储区就不等价于堆区)
全局/静态存储区:全局变量和静态变量被分配到同一块内存中,在以前的C语言中,全局变量又分为初始化的和未初始化的,在C++里面没有这个区分了,他们共同占用同一块内存区。
常量存储区:这是一块比较特殊的存储区,他们里面存放的是常量,不允许修改。
明确区分堆与栈
堆与栈的区分问题,似乎是一个永恒的话题,由此可见,初学者对此往往是混淆不清的,所以我决定拿他第一个开刀。
首先,我们举一个例子:
void f() { int* p=new int[5]; }
这条短短的一句话就包含了堆与栈,看到new,我们首先就应该想到,我们分配了一块堆内存,那么指针p呢?他分配的是一块栈内存,所以这句话的意思就是:在栈内存中存放了一个指向一块堆内存的指针p。在程序会先确定在堆中分配内存的大小,然后调用operator new分配内存,然后返回这块内存的首地址,放入栈中,他在VC6下的汇编代码如下:
00401028 push 14h
0040102A call operator new (00401060)
0040102F add esp,4
00401032 mov dword ptr [ebp-8],eax
00401035 mov eax,dword ptr [ebp-8]
00401038 mov dword ptr [ebp-4],eax
这里,我们为了简单并没有释放内存,那么该怎么去释放呢? 是delete p么?澳,错了,应该是delete []p,这是为了告诉编译器:我删除的是一个数组,编译器就会根据相应的Cookie信息去进行释放内存的工作。
堆和栈究竟有什么区别
好了,我们回到我们的主题:堆和栈究竟有什么区别?
主要的区别由以下几点:
(1). 管理方式不同
(2). 空间大小不同
(3). 能否产生碎片不同
(4). 生长方向不同
(5). 分配方式不同
(6). 分配效率不同
管理方式:对于栈来讲,是由编译器自动管理,无需我们手工控制;对于堆来说,释放工作由程序员控制,容易产生memory leak。
空间大小:一般来讲在32位系统下,堆内存可以达到4G的空间,从这个角度来看堆内存几乎是没有什么限制的。但是对于栈来讲,一般都是有一定的空间大小的,例如,在VC6下面,默认的栈空间大小是1M(好像是,记不清楚了)。当然,我们可以修改:
打开工程,依次操作菜单如下:Project->Setting->Link,在Category 中选中Output,然后在Reserve中设定堆栈的最大值和commit。
注意:reserve最小值为4Byte;commit是保留在虚拟内存的页文件里面,它设置的较大会使栈开辟较大的值,可能增加内存的开销和启动时间。
碎片问题:对于堆来讲,频繁的new/delete势必会造成内存空间的不连续,从而造成大量的碎片,使程序效率降低。对于栈来讲,则不会存在这个问题,因为栈是先进后出的队列,他们是如此的一一对应,以至于永远都不可能有一个内存块从栈中间弹出,在他弹出之前,在他上面的后进的栈内容已经被弹出,详细的可以参考数据结构,这里我们就不再一一讨论了。
生长方向:对于堆来讲,生长方向是向上的,也就是向着内存地址增加的方向;对于栈来讲,它的生长方向是向下的,是向着内存地址减小的方向增长。
分配方式:堆都是动态分配的,没有静态分配的堆。栈有2种分配方式:静态分配和动态分配。静态分配是编译器完成的,比如局部变量的分配。动态分配由alloca函数进行分配,但是栈的动态分配和堆是不同的,他的动态分配是由编译器进行释放,无需我们手工实现。
分配效率:栈是机器系统提供的数据结构,计算机会在底层对栈提供支持:分配专门的寄存器存放栈的地址,压栈出栈都有专门的指令执行,这就决定了栈的效率比较高。堆则是C/C++函数库提供的,它的机制是很复杂的,例如为了分配一块内存,库函数会按照一定的算法(具体的算法可以参考数据结构/操作系统)在堆内存中搜索可用的足够大小的空间,如果没有足够大小的空间(可能是由于内存碎片太多),就有可能调用系统功能去增加程序数据段的内存空间,这样就有机会分到足够大小的内存,然后进行返回。显然,堆的效率比栈要低得多。
从这里我们可以看到,堆和栈相比,由于大量new/delete的使用,容易造成大量的内存碎片;由于没有专门的系统支持,效率很低;由于可能引发用户态和核心态的切换,内存的申请,代价变得更加昂贵。所以栈在程序中是应用最广泛的,就算是函数的调用也利用栈去完成,函数调用过程中的参数,返回地址,EBP和局部变量都采用栈的方式存放。所以,我们推荐大家尽量用栈,而不是用堆。
虽然栈有如此众多的好处,但是由于和堆相比不是那么灵活,有时候分配大量的内存空间,还是用堆好一些。
无论是堆还是栈,都要防止越界现象的发生(除非你是故意使其越界),因为越界的结果要么是程序崩溃,要么是摧毁程序的堆、栈结构,产生以想不到的结果,就算是在你的程序运行过程中,没有发生上面的问题,你还是要小心,说不定什么时候就崩掉,那时候debug可是相当困难的:)
常见的内存错误及其对策
- 内存分配未成功,却使用了它。编程新手常犯这种错误,因为他们没有意识到内存分配会不成功。常用解决办法是,在使用内存之前检查指针是否为
NULL。如果指针p是函数的参数,那么在函数的入口处用assert(p!=NULL)进行检查。如果是用malloc或new来申请内存,应该用if(p==NULL)或if(p!=NULL)进行防错处理。 - 内存分配虽然成功,但是尚未初始化就引用它。犯这种错误主要有两个起因:一是没有初始化的观念;二是误以为内存的缺省初值全为零,导致引用初值错误(例如数组)。内存的缺省初值究竟是什么并没有统一的标准,尽管有些时候为零值,我们宁可信其无不可信其有。所以无论用何种方式创建数组,都别忘了赋初值,即便是赋零值也不可省略,不要嫌麻烦。
- 内存分配成功并且已经初始化,但操作越过了内存的边界。例如在使用数组时经常发生下标“多1”或者“少1”的操作。特别是在
for循环语句中,循环次数很容易搞错,导致数组操作越界。 - 忘记了释放内存,造成内存泄露。含有这种错误的函数每被调用一次就丢失一块内存。刚开始时系统的内存充足,你看不到错误。终有一次程序突然死掉,系统出现提示:内存耗尽。动态内存的申请与释放必须配对,程序中
malloc与free的使用次数一定要相同,否则肯定有错误(new/delete同理)。 - 释放了内存却继续使用它。
有三种情况:
(1). 程序中的对象调用关系过于复杂,实在难以搞清楚某个对象究竟是否已经释放了内存,此时应该重新设计数据结构,从根本上解决对象管理的混乱局面。
(2). 函数的return语句写错了,注意不要返回指向“栈内存”的“指针”或者“引用”,因为该内存在函数体结束时被自动销毁。
(3). 使用free或delete释放了内存后,没有将指针设置为NULL。导致产生“野指针”。
那么如何避免产生野指针呢?这里列出了5条规则,平常写程序时多注意一下,养成良好的习惯。
规则1:用
malloc或new申请内存之后,应该立即检查指针值是否为NULL。防止使用指针值为NULL的内存。
规则2:不要忘记为数组和动态内存赋初值。防止将未被初始化的内存作为右值使用。
规则3:避免数组或指针的下标越界,特别要当心发生“多1”或者“少1”操作。
规则4:动态内存的申请与释放必须配对,防止内存泄漏。
规则5:用free或delete释放了内存之后,立即将指针设置为NULL,防止产生“野指针”。
3. 关于堆和自由存储区概念的区别
事实上,我在网上看的很多博客,划分自由存储区与堆的分界线就是new/delete与malloc/free。然而,尽管C++标准没有要求,但很多编译器的new/delete都是以malloc/free为基础来实现的。那么请问:借以malloc实现的new,所申请的内存是在堆上还是在自由存储区上?
从技术上来说,堆(heap)是C语言和操作系统的术语。堆是操作系统所维护的一块特殊内存,它提供了动态分配的功能,当运行程序调用malloc()时就会从中分配,稍后调用free可把内存交还。而自由存储是C++中通过new和delete动态分配和释放对象的抽象概念,通过new来申请的内存区域可称为自由存储区。基本上,所有的C++编译器默认使用堆来实现自由存储,也即是缺省的全局运算符new和delete也许会按照malloc和free的方式来被实现,这时藉由new运算符分配的对象,说它在堆上也对,说它在自由存储区上也正确。但程序员也可以通过重载操作符,改用其他内存来实现自由存储,例如全局变量做的对象池,这时自由存储区就区别于堆了。我们所需要记住的就是:
堆是操作系统维护的一块内存,而自由存储是C++中通过new与delete动态分配和释放对象的抽象概念。堆与自由存储区并不等价。
问题的来源
再回过头来来看看这个问题的起源在哪里。最先我们使用C语言的时候,并没有这样的争议,很明确地知道malloc/free是在堆上进行内存操作。直到我们在Bjarne Stroustrup的书籍中数次看到free store (自由存储区),说实话,我一直把自由存储区等价于堆。而在Herb Sutter的《exceptional C++》中,明确指出了free store(自由存储区) 与 heap(堆) 是有区别的。关于自由存储区与堆是否等价的问题讨论,大概就是从这里开始的:
Free Store
The free store is one of the two dynamic memory areas, allocated/freed by new/delete. Object lifetime can be less than the time the storage is allocated; that is, free store objects can have memory allocated without being immediately initialized, and can be destroyed without the memory being immediately deallocated. During the period when the storage is allocated but outside the object’s lifetime, the storage may be accessed and manipulated through a void* but none of the proto-object’s nonstatic members or member functions may be accessed, have their addresses taken, or be otherwise manipulated.
Heap
The heap is the other dynamic memory area, allocated/freed by malloc/free and their variants. Note that while the default global new and delete might be implemented in terms of malloc and free by a particular compiler, the heap is not the same as free store and memory allocated in one area cannot be safely deallocated in the other. Memory allocated from the heap can be used for objects of class type by placement-new construction and explicit destruction. If so used, the notes about free store object lifetime apply similarly here.
作者也指出,之所以把堆与自由存储区要分开来,是因为在C++标准草案中关于这两种区域是否有联系的问题一直很谨慎地没有给予详细说明,而且特定情况下new和delete是按照malloc和free来实现,或者说是放过来malloc和free是按照new和delete来实现的也没有定论。这两种内存区域的运作方式不同、访问方式不同,所以应该被当成不一样的东西来使用。
结论
自由存储是C++中通过new与delete动态分配和释放对象的抽象概念,而堆(heap)是C语言和操作系统的术语,是操作系统维护的一块动态分配内存。
new所申请的内存区域在C++中称为自由存储区。藉由堆实现的自由存储,可以说new所申请的内存区域在堆上。
堆与自由存储区还是有区别的,它们并非等价。
假如你来自C语言,从没接触过C++;或者说你一开始就熟悉C++的自由储存概念,而从没听说过C语言的malloc,可能你就不会陷入“自由存储区与堆好像一样,好像又不同”这样的迷惑之中。这就像Bjarne Stroustrup所说的:
usually because they come from a different language background.
大概只是语言背景不同罢了。
4. cache和buffer的区别
1、Buffer(缓冲区)是系统两端处理速度平衡(从长时间尺度上看)时使用的。它的引入是为了减小短期内突发I/O的影响,起到流量整形的作用。比如生产者——消费者问题,他们产生和消耗资源的速度大体接近,加一个buffer可以抵消掉资源刚产生/消耗时的突然变化。
2、Cache(缓存)则是系统两端处理速度不匹配时的一种折衷策略。因为CPU和memory之间的速度差异越来越大,所以人们充分利用数据的局部性(locality)特征,通过使用存储系统分级(memory hierarchy)的策略来减小这种差异带来的影响。
3、假定以后存储器访问变得跟CPU做计算一样快,cache就可以消失,但是buffer依然存在。比如从网络上下载东西,瞬时速率可能会有较大变化,但从长期来看却是稳定的,这样就能通过引入一个buffer使得OS接收数据的速率更稳定,进一步减少对磁盘的伤害。
4、TLB(Translation Lookaside Buffer,翻译后备缓冲器)名字起错了,其实它是一个cache.
5. C++实现线程池
#ifndef THREAD_POOL_H
#define THREAD_POOL_H
#include 使用方法:
#include 另一个例子
#include #ifndef ThreadPool_h
#define ThreadPool_h
#include - 简单版:https://www.cnblogs.com/lzpong/p/6397997.html
#pragma once
#ifndef THREAD_POOL_H
#define THREAD_POOL_H
#include ::type, 函数 f 的返回值类型
auto task = std::make_shared<std::packaged_task<RetType()> >(
std::bind(std::forward<F>(f), std::forward<Args>(args)...)
); // wtf !
std::future<RetType> future = task->get_future();
{ // 添加任务到队列
std::lock_guard<std::mutex> lock{ m_lock };//对当前块的语句加锁 lock_guard 是 mutex 的 stack 封装类,构造的时候 lock(),析构的时候 unlock()
tasks.emplace(
[task]()
{ // push(Task{...})
(*task)();
}
);
}
cv_task.notify_one(); // 唤醒一个线程执行
return future;
}
//空闲线程数量
int idlCount() { return idlThrNum; }
};
}
#endif
精简版:
class thread_pool
{
std::atomic_bool done;
thread_safe_queue<std::function<void()> > work_queue; // 1
std::vector<std::thread> threads; // 2
join_threads joiner; // 3
void worker_thread()
{
while(!done) // 4
{
std::function<void()> task;
if(work_queue.try_pop(task)) // 5
{
task(); // 6
}
else
{
std::this_thread::yield(); // 7
}
}
}
public:
thread_pool():
done(false),joiner(threads)
{
unsigned const thread_count=std::thread::hardware_concurrency(); // 8
try
{
for(unsigned i=0;i<thread_count;++i)
{
threads.push_back(
std::thread(&thread_pool::worker_thread,this)); // 9
}
}
catch(...)
{
done=true; // 10
throw;
}
}
~thread_pool()
{
done=true; // 11
}
template<typename FunctionType>
void submit(FunctionType f)
{
work_queue.push(std::function<void()>(f)); // 12
}
};
#include 6. 静态函数和虚函数的区别
静态函数在编译的时候就已经确定运行时机,虚函数在运行的时候动态绑定。虚函数因为用了虚函数表机制,调用的时候会增加一次内存开销
7. C++里是怎么定义常量的?常量存放在内存的哪个位置?
常量在C++里的定义就是一个top-level const加上对象类型,常量定义必须初始化。对于局部对象,常量存放在栈区,对于全局对象,常量存放在全局/静态存储区。对于字面值常量,常量存放在常量存储区。
8. 编译链接程序过程
一、g++执行的四个过程
1、预处理:条件编译,头文件包含,宏替换的处理,生成.i文件。
2、编译:将预处理后的文件转换成汇编语言,生成.s文件
3、汇编:汇编变为目标代码(机器代码)生成.o的文件
4、链接:连接目标代码,生成可执行程序
二、最简单的C++程序——“helloworld!\n”
// 新建hello.cpp文件,vim编辑
#include (1)预处理阶段
g++ -E hello.cpp > hello.i
通过vim打开hello.i文件,你会发现一些情况(最好是自己观察,看看哪些内容被换了);
宏的替换,还有注释的消除,还有找到相关的库文件,将#include文件的全部内容插入。若用<>括起文件则在系统的INCLUDE目录中寻找文件,若用""括起文件则在当前目录中寻找文件。
用编辑器打开hello.i会发现有很多很多代码,你只需要看最后部分就会发现,预处理做了宏的替换,还有注释的消除,可以理解为无关代码的清除。
(2)编译
g++ -S hello.cpp
生成hello.s文件,.s文件表示是汇编文件,用编辑器打开就都是汇编指令。(可以通过vim编辑器看看hello.s里面的内容【都是汇编指令,哈哈】)。
(3)汇编
g++ -c hello.cpp
汇编变为目标代码(机器代码)生成.o的文件,.o是gcc生成的目标文件,用编辑器打开就都是二进制机器码。
(4)链接——链接生成可执行文件(库文件进行链接)
g++ -o hello hello.cpp
程序运:./hello【输出hello world!】
在成功编译之后,就进入了链接阶段。在这里涉及到一个重要的概念:函数库(可以这么理解就是不带main()函数的.cpp生成的)。
可以重新查看这个小程序,在这个程序中并没有定义”cout”的函数(准确说cout不是函数,cout却很独特:既不是函数,似乎也不是C++特别规定出来的像if,for一类有特殊语法的“语句”,其实说到底还是函数调用,不过这函数有些特殊,用的是运算符重载,确切地说是重载了“<<”运算符。这里如果用pritf()函数说明会更好,暂且当做函数理解吧)实现,且在预编译中包含进的”iostream”中也只有该函数的声明,而没有定义函数的实现,那么,是在哪里实现”cout”函数的呢?系统把这些函数实现都被做到名为stdc++的库文件中去了,在没有特别指定时,g++会到系统默认的搜索路径”/usr/lib”下进行查找,也就是链接到stdc++库函数中去,这样就能实现函数”cout”了,而这也就是链接的作用。
9. C和C++中的const变量存储在那
c语言中const全局变量存储在只读数据段,编译期最初将其保存在符号表中,第一次使用时为其分配内存,在程序结束时释放。
而const局部变量(局部变量就是在函数中定义的一个const变量,)存储在栈中,代码块结束时释放。
在c语言中可以通过指针对const局部变量进行修改,而不可以对const全局变量进行修改。因为const全局变量是存储在只读数据段
而c++中,一个const不是必需创建内存空间,而在c中,一个const总是需要一块内存空间。
**在c++中是否要为const全局变量分配内存空间,取决于这个const变量的用途,如果是充当着一个值替换(即就是将一个变量名替换为一个值),那么就不分配内存空间,不过当对这个const全局变量取地址或者使用extern时,会分配内存,**存储在只读数据段。也是不能修改的。
c++中对于局部的const变量要区别对待:
对于基础数据类型,也就是const int a = 10这种,编译器会把它放到符号表中,不分配内存,当对其取地址时,会分配内存
对于基础数据类型,如果用一个变量初始化const变量,如果const int a = b,那么也是会给a分配内存
对于自定数据类型,比如类对象,那么也会分配内存。
c中const默认为外部连接,c++中const默认为内部连接.当c语言两个文件中都有const int a的时候,编译器会报重定义的错误。而在c++中,则不会,因为c++中的const默认是内部连接的。如果想让c++中的const具有外部连接,必须显示声明为: extern const int a = 10。
那我们先看以下几个常见的问题,加深C++编译器的理解
« 符号表如何存储静态变量(包括全局变量和局部变量)和类非静态成员变量有哪些区别?
对于静态变量,C++编译器的处理方法和Java解释器处理的方法有类似的地方。那就是访问控制符public/private/protected和static一样都会写入符号表;对于非静态成员变量符号表存储的什么内容?有没有这些访问控制符?类的非静态成员在类中的表示是通过偏移量来访问,只有和对象邦定以后才能找到其真实的地址,那么在编译后的目标文件中没有为成员分配地址,访问控制符也就没有写入到目标文件。【注1:为什么访问控制符是在编译期间处理,而不放在运行期间处理?如果要放在运行期间处理必须完成新的连接器和加载器来保证,另外重要的是运行效率的问题】【注2:参考CSDN上一篇文章,一个类的成员变量修改了访问控制符,在另外一个文件被引用,是否必须编译修改的文件才能连接成功?《今天面试碰到的一个以前没有想过的问题(顺便给一点分出去)》】。
« 符号表如何处理const、volatile变量?
C++编译器把Const对象放在了符号表之中,C语言一般是放在只读数据区。【为什么C++编译器这么做?我想一个原因就是减少一些存储操作次数】。对于volatile变量我们应该怎么考虑?声明的voliate告诉编译器不能优化它呀,我们只能在符号表中增加标识位来告诉编译器自己不优化volatile变量。
« 符号表怎么处理虚函数、虚继承、多继承的情况?
其实对于这些处理在Lippman的《Inside the C++ Object Model》中有详细的介绍。也许你知道那些应该放在符号表中,那些是不能的。例如对于局部静态对象static class obj;的定义那些不需要放在符号表中?【注:局部静态变量只要求在函数执行时初始化一次】,为了保证Obj满足要求,需要附加标志变量,这个附加变量能放在符号表中吗?不能,原因很简单,它需要在运行时控制对象的构造和析构。
10. C++priority_queue
方法一:priority_queue
这种方法需要#include
最基本的使用方法,对于一串数字建堆:
riority_queue heap;
这种情况下默认为最大堆,也就是堆顶元素值最大。
如果需要建立最小堆,可以采用如下方式:
priority_queue, greater >qi2;//最小堆priority_queue, less >qi2;//最大堆
然而在多数情况下,我们还需要记录一些排序元素的额外信息,比如索引之类的,则需要以下三个步骤:
- 定义堆中需要存储的结构体:
struct Node{
int x;int y;int val;
Node(int a,int b,int valin):x(a),y(b),val(valin){}
};
-
确定堆中元素的存储顺序,也就是最大堆还是最小堆
//设置比较函数,确定堆中元素的顺序,是最大堆还是最小堆, struct cmp{ bool operator()(const Node &a,const Node &b){ return a.val>b.val;//最小堆 //return a.val -
建堆
priority_queue<Node,vector<Node>,cmp> heap;//建堆 heap.pop();//出堆 heap.push();//入堆 heap.top();//获取堆顶元素
方法二:利用vector
这种法法需要#include #include
vector<int> a;
//建堆
make_heap(a.begin(),a.end(), less<int>() );//最大堆
make_heap(a.begin(),a.end(), greater<int>() );//最小堆
//pop
pop_heap(a.begin(),a.end(), less<int>() );//最大值出堆
pop_heap(a.begin(),a.end(), less<int>() );//最小值出堆
//插入元素
push_heap(a.begin(),a.end(),cmp);
//堆排序
sort_heap(a.begin(),a.end(),cmp);
// push_heap ( begin , end ) 将最后一个元素插入堆中(堆自动调整)
// pop_heap ( begin , end ) 将第一个元素从堆中删去(堆自动调整),并放到最后
// find ( begin , end , value ) 从begin到end查找value,若找不到,返回end
11. 友元
在C++中,我们使用类对数据进行了隐藏和封装,类的数据成员一般都定义为私有成员,成员函数一般都定义为公有的,以此提供类与外界的通讯接口。但是,有时需要定义一些函数,这些函数不是类的一部分,但又需要频繁地访问类的数据成员,这时可以将这些函数定义为该函数的友元函数。除了友元函数外,还有友元类,两者统称为友元。友元的作用是提高了程序的运行效率(即减少了类型检查和安全性检查等都需要时间开销),但它破坏了类的封装性和隐藏性,使得非成员函数可以访问类的私有成员。
友元函数 :
友元函数是可以直接访问类的私有成员的非成员函数。它是定义在类外的普通函数,它不属于任何类,但需要在类的定义中加以声明,声明时只需在友元的名称前加上关键字friend,其格式如下:
friend 类型 函数名(形式参数);
友元函数的声明可以放在类的私有部分,也可以放在公有部分,它们是没有区别的,都说明是该类的一个友元函数。
一个函数可以是多个类的友元函数,只需要在各个类中分别声明。
友元函数的调用与一般函数的调用方式和原理一致。
友元类 :
友元类的所有成员函数都是另一个类的友元函数,都可以访问另一个类中的隐藏信息(包括私有成员和保护成员)。
当希望一个类可以存取另一个类的私有成员时,可以将该类声明为另一类的友元类。定义友元类的语句格式如下:
friend class 类名;
其中:friend和class是关键字,类名必须是程序中的一个已定义过的类。
例如,以下语句说明类B是类A的友元类:
class A
{
…
public:
friend class B;
…
};
经过以上说明后,类B的所有成员函数都是类A的友元函数,能存取类A的私有成员和保护成员。
使用友元类时注意:
(1) 友元关系不能被继承。
(2) 友元关系是单向的,不具有交换性。若类B是类A的友元,类A不一定是类B的友元,要看在类中是否有相应的声明。
(3) 友元关系不具有传递性。若类B是类A的友元,类C是B的友元,类C不一定是类A的友元,同样要看类中是否有相应的申明
《windows环境多线程编程原理与应用》中解释:
如果将类的封装比喻成一堵墙的话,那么友元机制就像墙上了开了一个门,那些得
到允许的类或函数允许通过这个门访问一般的类或者函数无法访问的私有属性和方
法。友元机制使类的封装性得到消弱,所以使用时一定要慎重。
友元类:
将外界的某个类在本类别的定义中说明为友元,那么外界的类就成为本类的“朋
友”,那个类就可以访问本类的私有数据了。
class Merchant
{
private :
int m_MyMoney;
int m_MyRoom;
… …
Public:
Friend class Lawyer;
Int getmoney();
… …
};
Class Lawyer
{
Private:
… …
Public:
… …
};
只有你赋予某个类为你的友元时,那个类才有访问你的私有数据的权利。说明一个函数为一个类的友元函数则该函数可以访问此类的私有数据和方法。定义方法是在类的定义中,在函数名前加上关键字friend.
需要友元与友元的优缺点:
通常对于普通函数来说,要访问类的保护成员是不可能的,如果想这么做那么必须把类的成员都生命成为public(共用的),然而这做带来的问题遍是任何外部函数都可以毫无约束的访问它操作它,c++利用friend修饰符,可以让一些你设定的函数能够对这些保护数据进行操作,避免把类成员全部设置成public,最大限度的保护数据成员的安全。
友元能够使得普通函数直接访问类的保护数据,避免了类成员函数的频繁调用,可以节约处理器开销,提高程序的效率,但所矛盾的是,即使是最大限度大保护,同样也破坏了类的封装特性,这即是友元的缺点,在现在cpu速度越来越快的今天我们并不推荐使用它,但它作为c++一个必要的知识点,一个完整的组成部分,我们还是需要讨论一下的。 在类里声明一个普通数学,在前面加上friend修饰,那么这个函数就成了该类的友元,可以访问该类的一切成员。
下面我们来看一段代码,看看我们是如何利用友元来访问类的一切成员的:
#include 示例2:
分别定义一个类A和类B ,各有一个私有整数成员变量通过构造函数初始化;类A有一个成员函数Show(B &b)用来打印A和B的私有成员变量,请分别通过友元函数和友元类来实现此功能。使用友元类 和 友元函数实现:
#include 12. gcc
gcc命令 使用GNU推出的基于C/C++的编译器,是开放源代码领域应用最广泛的编译器,具有功能强大,编译代码支持性能优化等特点。现在很多程序员都应用GCC,怎样才能更好的应用GCC。目前,GCC可以用来编译C/C++、FORTRAN、JAVA、OBJC、ADA等语言的程序,可根据需要选择安装支持的语言。

语法
gcc(选项)(参数)
选项
-o:指定生成的输出文件名;
-E:仅执行编译预处理;
-S:将C代码转换为汇编代码;
-Wall:显示所有警告信息; wornging all
-c:仅执行预处理、编译和汇编操作,不进行连接操作。
-I:
-g: 支持gdb调试, 输出文件会变大
-On:(1~3级)三级编译优化,n越大优化越多
-D: 编译时定义宏,例如在编译时添加宏可以启动和关闭条件编译,主要起开关作用
参数
C源文件:指定C语言源代码文件。
实例
常用编译命令选项
假设源程序文件名为test.c
无选项编译链接
gcc test.c
将test.c预处理、汇编、编译并链接形成可执行文件。这里未指定输出文件,默认输出为a.out。
选项 -o
gcc test.c -o test
将test.c预处理、汇编、编译并链接形成可执行文件test。-o选项用来指定输出文件的文件名。
选项 -E
gcc -E test.c -o test.i
将test.c预处理输出test.i文件。
选项 -S
gcc -S test.i //注意是大写
将预处理输出文件test.i汇编成test.s文件。
选项 -c
做预处理、编译和汇编操作。得到二进制文件
gcc -c test.s
将汇编输出文件test.s编译输出test.o文件。
无选项链接
gcc test.o -o test
将编译输出文件test.o链接成最终可执行文件test。
选项 -O
gcc -O1 test.c -o test
使用编译优化级别1编译程序。级别为1~3,级别越大优化效果越好,但编译时间越长。
头文件链接选项 -I
编译文件时,只需要编译源文件就行,但是编译源文件的时候会去找头文件。如果头文件和源文件不在同一个目录下时,编译时无法找到头文件,则可以使用-I命令执行头文件的位置:
gcc -I./nextdir hello.c -o hello //hello.c的头文件在./nextdir下,-I命令位置可以在任意地方。而且-I后可以有空格可以没有
编译时定义宏-D
#include"hello.h"#ifdef DEBUG#define HI 20#endifint main(){ printf("\n",HI); }
gcc hello.c -o hello -D DEBUG
多源文件的编译方法
如果有多个源文件,基本上有两种编译方法:
假设有两个源文件为test.c和testfun.c
多个文件一起编译
gcc testfun.c test.c -o test
将testfun.c和test.c分别编译后链接成test可执行文件。
分别编译各个源文件,之后对编译后输出的目标文件链接。
gcc -c testfun.c #将testfun.c编译成testfun.ogcc -c test.c #将test.c编译成test.ogcc testfun.o test.o -o test #将testfun.o和test.o链接成test
以上两种方法相比较,第一中方法编译时需要所有文件重新编译,而第二种方法可以只重新编译修改的文件,未修改的文件不用重新编译。
自测实例
三个文件: test.h + test.cpp + main.cpp
分别编译并链接:
g++ -c test.cpp //自动生成test.o的目标文件g++ -c main.cpp //生成main.o的目标文件g++ test.o main.o -o main //链接所有的目标文件
13. find命令
find [option] path ... [expression] -type 按文件类型搜索 -name 按文件名搜索 -maxdepth 按指定深度搜索,默认是搜索所有子目录 -size 按文件大小查找,兆是'M',k是小写'k' -atime、ctime、mtime(最近访问、最近改动(文件内容)一天计算、最近更改(属性,mode、硬链接等)) -exec :将find搜索的结果集执行某一指定命令。 -ok :以交互式的方式,将find搜索的结果集执行某一指定命令 -xargs :分片处理结果集例如: find ./ -maxpath 1 -name '*.jpg' //只搜索本层级的所有文件 find ./ -maxpath 2 -name '*.jpg' //只搜索2层文件 find ./ -type f //搜索文件普通文件类型 find ./ -type 'l' //找出所有的软连接 find ./ -size +20M -size -50M //搜索大于20M小于50M的文件 find ./ -ctime 1 //查最近一天修改内容的文件 find ./ -name '*tmp*' -exec ls -l {} \; //将查找的内容装入{}中,执行ls
14. linux系统目录和文件类型

其中: usr: unix software resource
bin: 存二进制可执行文件,shell命令
目录表示:
标识符:~ :家目录,但不是home目录,而是用户目录,home下包含所有用户. :当前目录.. :上一级目录- :上次使用的目录cd ~cd .cd ..cd -
15. ls
ls: -a 隐藏文件 -l 列出文件详细信息 -R 递归查同级下的所有目录和文件的内容 -dl 列出目录的详细信息,后面可以跟目录名称,默认是当前目录的信息
-R递归查询所有文件:


16. cp
拷贝文件
cp file1 file2 #会将file2中的内容覆盖,file1和file2内容一样cp file2 dir/ #拷贝到目录下cp file1 ../ #拷贝到上一级
拷贝目录:
cp dir1 dir2 -r #递归拷贝非空目录cp dir1 ~/ -rcp -a dir1 .. #拷贝目录的所有内容到上级,而且目录的时间戳不变,而-r则会更新
17. cat
cat file # 查看文件内容cat # 从标准输入读入,遇到换行则回显终端下输入ctrl -d结束tac file #倒着查看文件内容
18. more
查看文件内容,空格翻页,回车下一行,q结束
19. grep
以文件内容为对象查找
grep [选项] ‘查找的内容’ path[选项] : -c 只输出匹配行的计数 -I 不区分大小写(只适用于单字符) -h 查询多文件时不显示文件名 -l 查询多文件时只输出包含匹配字符的文件名 -n 显示匹配行的行号 -s -v -R 递归查子目录下的所有文件 可以查询某个进程的信息 ps aux | grep 'bash' #查询bash的进程
20. echo
echo [选项] [字符串]
1.输入一行文本并显示在标准输出上
$ echo Tecmint is a community of Linux Nerds
会输出下面的文本:
Tecmint is a community of Linux Nerds
2.输出一个声明的变量值
比如,声明变量x并给它赋值为10。
$ x=10
会输出它的值:
$ echo The value of variable x = $x The value of variable x = 10
3.使用echo命令打印所有的文件和文件夹(ls命令的替代)
$ echo *
4.打印制定的文件类型
比如,让我们假设你想要打印所有的‘.jpeg‘文件,使用下面的命令。
$ echo *.jpeg network.jpeg
5.echo可以使用重定向符来输出到一个文件而不是标准输出
$ echo "Test Page" > testpage ## Check Contentavi@tecmint:~$ cat testpage Test Page
20. 补充命令
20.1 ps
最详解析https://developer.aliyun.com/article/710681
20.2 &
$: ./a.out & 在后台运行进程
20.3 man
man命令是Linux下的帮助指令,通过man指令可以查看Linux中的指令帮助、配置文件帮助和编程帮助等信息。
语法
man(选项)(参数) 选项可有可无,但参数必须有。
选项
-a:在所有的man帮助手册中搜索;-f:等价于whatis指令,显示给定关键字的简短描述信息;-P:指定内容时使用分页程序;-M:指定man手册搜索的路径。
参数
- 数字:指定从哪本man手册中搜索帮助;
- 关键字:指定要搜索帮助的关键字。
也可以这样输入命令:“man [章节号] 手册名称”。
man是按照手册的章节号的顺序进行搜索的,比如:
man sleep
只会显示sleep命令的手册,如果想查看库函数sleep,就要输入:(如下所示)
man 3 sleep
Linux的man手册共有以下几个章节:
1、Standard commands (标准命令)
2、System calls (系统调用)
3、Library functions (库函数)
4、Special devices (设备说明)
5、File formats (文件格式)
6、Games and toys (游戏和娱乐)
7、Miscellaneous (杂项)
8、Administrative Commands (管理员命令)
21. vim
21.1 vim配置文件
添加~/.vimrc配置文件,.vimrc文件可编写内容如下:
set nocompatible " required
filetype off " required
" set the runtime path to include Vundle and initialize
set rtp+=~/.vim/bundle/Vundle.vim
call vundle#begin()
" alternatively, pass a path where Vundle should install plugins
"call vundle#begin('~/some/path/here')
" let Vundle manage Vundle, required
Plugin 'gmarik/Vundle.vim'
" Add all your plugins here (note older versions of Vundle used Bundle instead of Plugin)
" All of your Plugins must be added before the following line
call vundle#end() " required
filetype plugin indent on " required
"显示行号
set nu
"启动时隐去援助提示
set shortmess=atI
"语法高亮
syntax on
"使用vim的键盘模式
"set nocompatible
"不需要备份
set nobackup
"没有保存或文件只读时弹出确认
set confirm
"鼠标可用
set mouse=a
"tab缩进
set tabstop=4
set shiftwidth=4
set expandtab
set smarttab
"文件自动检测外部更改
set autoread
"c文件自动缩进
set cindent
"自动对齐
set autoindent
"智能缩进
set smartindent
"高亮查找匹配
set hlsearch
"背景色
"set background=dark"
"显示匹配
set showmatch
"显示标尺,就是在右下角显示光标位置
set ruler
"去除vi的一致性
set nocompatible
"允许折叠
set foldenable
"""""""""""""""""设置折叠"""""""""""""""""""""
"
"根据语法折叠
set fdm=syntax
"手动折叠
"set fdm=manual
"设置键盘映射,通过空格设置折叠
nnoremap @=((foldclosed(line('.')<0)?'zc':'zo'))
" """""""""""""""""""""""""""""""""""""""""""""
"不要闪烁
set novisualbell
"启动显示状态行
set laststatus=2
"浅色显示当前行
autocmd InsertLeave * se nocul
"用浅色高亮当前行
autocmd InsertEnter * se cul
"显示输入的命令
set showcmd
"被分割窗口之间显示空白
set fillchars=vert:/
set fillchars=stl:/
set fillchars=stlnc:/
21.2 vim命令及模式切换
三种模式切换:

(1)由命令模式切换到文本模式:
vi从命令模式切换到文本输入模式。每个键以不同方式使vi进入文本输入模式。按****[ESC]****键使vi从文本输入模式回到命令模式。表1列出了vi从命令模式切换到文本输入模式的命令键及其功能。
表1 切换到文本输入模式的命令键
| 键 | 功能 |
|---|---|
| i | 在光标左侧输入正文 |
| I | 在光标所在行的行首输入正文 |
| a | 在光标右侧输入正文 |
| A | 在光标所在行的行尾输入正文 |
| o | 在光标所在行的下一行增添新行,光标位于新行的行首 |
| O | 在光标所在行的上一行增添新行,光标位于新行的行首 |
| s | 光标所在处的一个字符被删除,进入文本模式 |
| S | 删除光标所在处的整行,进入文本模式 |
(2)命令模式光标移动:
h j k l : 左 下 上 右
(3)自动调整格式:
gg=G (命令模式)
(4)大括号对应跳转切换:
% (命令模式) 前提光标在括号位置
(5)删除:
1. 从光标位置开始到行尾:D (命令模式) 2. 从光标开始到行首:d03. 多行删除:ndd(n=1,2,3,4.....)4. 单行删除:dd5. 删除单个字符:x (命令模式) 工作模式不切换6. 删除单个单词: 光标置于单词首字母位置 d+w (命令模式) 7. 全选删除: 命令模式下 gg +dG
(6)光标移动:
1. 移至行首:02. 移至行尾:$3. 跳转到文首,命令模式: gg 4. 跳转到文尾,命令模式: G 5. 跳转到指定位置,命令模式: n + G (n为行号) ; 末行模式:n
(7)撤销上一步操作:
u
(8)恢复上一步被撤销的操作:
ctrl+r
(9)复制
单行复制 在命令模式下,将光标移动到将要复制的行处,按“yy”进行复制;
多行复制 在命令模式下,将光标移动到将要复制的首行处,按“nyy”复制n行;
其中n为1、2、3……全选复制 在命令模式下,ggyG自定义选中要复制的内容:命令模式v+(hjkl)自由选中,,也也就是说v是开启选中模式跨文件复制内容从a文件复制到b文件,打开b文件,然后末行模式:r!cat b回车
Vim跨文件复制
现在把a.txt的三行复制到b.txt
1、用vim打开a.txt
# vim a.txt
Esc进入指令模式(默认刚打开就是这个模式)
输入"a3yy
解释:引号要结合shift输入,a代表剪贴板a(26个英文字母都可以),3yy当然代表从当前行复制3行了
退出a.txt
:q
2、打开b.txt
光标移动到你想要复制的位置
进入指令模式,输入"ap
解释:引号要结合shift输入,a代表使用剪贴板a,p当然代表粘贴了
(10)粘贴
在命令模式下,将光标移动到将要粘贴的行处,按“p”进行粘贴
(11)折叠:
在可折叠处(大括号中间):zc 折叠所有的大括号zn 打开所有的折叠zC 对所在范围内所有嵌套的折叠点进行折叠zo 展开折叠zO 对所在范围内所有嵌套的折叠点展开[z 到当前打开的折叠的开始处。]z 到当前打开的折叠的末尾处。zj 向下移动。到达下一个折叠的开始处。关闭的折叠也被计入。zk 向上移动到前一折叠的结束处。关闭的折叠也被计入。
(12)分屏
: new 末行模式,新建一个文件:splite filename 末行模式,水平打开一个已存在文件:vsplite filename 末行模式,垂直打开一个已存在文件ctrl+w+j 命令模式,切换到下面的文件输入ctrl+w+k 命令模式,切换到上面的文件输入ctrl+w+v 命令模式,垂直打开一个匿名文件,复制当前文件内容ctrl+w+s 命令模式,水平打开一个匿名文件,复制当前文件内容ctrl+w+o 命令模式,只保留一个文件,关闭其他文件ctrl+s 锁定键入ctrl+q 解锁
(13)剪切
命令模式: v //进入visual模式按字符选中,使用hjkl控制选择区域命令模式: V //进入visual模式按行选中,使用jk控制选择区域命令模式: ctrl+v //进入visual模式按块选中

命令模式:x或d //选中代码后,执行删除,则会放入剪切板,之后使用p粘贴
(14)块移动
选中一段代码后进行左移右移::shift+> 右移 : shift+< 左移 末行模式:按行号选择块移动:10,100> //第10行到第100行右缩进
(15)处理大小写
1. 单个字符的处理
- ~:切换光标所在位置的字符的大小写形式,大写转换为小写,小写转换为大写
- 3~:将光标位置开始的3个字母改变其大小写
2. 文本整体的处理
gu:切换为小写,gU:切换为大写,剩下的就是对这两个命令的限定(限定行字母和单词)等等。
2.1 整篇文章
无须进入命令行模式,键入:
- ggguG:整篇文章转换为小写,gg:文件头,G:文件尾,gu:切换为小写
- gggUG:整篇文章切换为大写,gg:文件头,G:文件尾,gU:切换为大写
2.2 只转化某个单词
- guw、gue
- gUw、gUe
- gu5w:转换 5 个单词
- gU5w
2.3 转换行
- gU0 :从光标所在位置到行首,都变为大写
- gU$ :从光标所在位置到行尾,都变为大写
- gUG :从光标所在位置到文章最后一个字符,都变为大写
- gU1G :从光标所在位置到文章第一个字符,都变为大写
22. gdb调试
gdb交互命令
启动gdb后,进入到交互模式,通过以下命令完成对程序的调试;注意高频使用的命令一般都会有缩写,熟练使用这些缩写命令能提高调试的效率;
运行
- run:简记为 r ,其作用是运行程序,当遇到断点后,程序会在断点处停止运行,等待用户输入下一步的命令。
- continue (简写c ):继续执行,到下一个断点处(或运行结束)
- next:(简写 n),单步跟踪程序,当遇到函数调用时,也不进入此函数体;此命令同 step 的主要区别是,step 遇到用户自定义的函数,将步进到函数中去运行,而 next 则直接调用函数,不会进入到函数体内。
- step (简写s):单步调试如果有函数调用,则进入函数;与命令n不同,n是不进入调用的函数的
- until:当你厌倦了在一个循环体内单步跟踪时,这个命令可以运行程序直到退出循环体。
- until+行号: 运行至某行,不仅仅用来跳出循环
- finish: 运行程序,直到当前函数完成返回,并打印函数返回时的堆栈地址和返回值及参数值等信息。
- call 函数(参数):调用程序中可见的函数,并传递“参数”,如:call gdb_test(55)
- quit:简记为 q ,退出gdb
设置断点
-
-
break n (简写b n):在第n行处设置断点
(可以带上代码路径和代码名称: b OAGUPDATE.cpp:578)
-
-
b fn1 if a>b:条件断点设置
-
break func(break缩写为b):在函数func()的入口处设置断点,如:break cb_button
-
delete 断点号n:删除第n个断点
-
disable 断点号n:暂停第n个断点
-
enable 断点号n:开启第n个断点
-
clear 行号n:清除第n行的断点
-
info b (info breakpoints) :显示当前程序的断点设置情况
-
delete breakpoints:清除所有断点:
查看源代码
- list :简记为 l ,其作用就是列出程序的源代码,默认每次显示10行。
- list 行号:将显示当前文件以“行号”为中心的前后10行代码,如:list 12
- list 函数名:将显示“函数名”所在函数的源代码,如:list main
- list :不带参数,将接着上一次 list 命令的,输出下边的内容。
打印表达式
- print 表达式:简记为 p ,其中“表达式”可以是任何当前正在被测试程序的有效表达式,比如当前正在调试C语言的程序,那么“表达式”可以是任何C语言的有效表达式,包括数字,变量甚至是函数调用。
- print a:将显示整数 a 的值
- print ++a:将把 a 中的值加1,并显示出来
- print name:将显示字符串 name 的值
- print gdb_test(22):将以整数22作为参数调用 gdb_test() 函数
- print gdb_test(a):将以变量 a 作为参数调用 gdb_test() 函数
- display 表达式:在单步运行时将非常有用,使用display命令设置一个表达式后,它将在每次单步进行指令后,紧接着输出被设置的表达式及值。如: display a
- watch 表达式:设置一个监视点,一旦被监视的“表达式”的值改变,gdb将强行终止正在被调试的程序。如: watch a
- whatis :查询变量或函数
- info function: 查询函数
- 扩展info locals: 显示当前堆栈页的所有变量
查询运行信息
- where/bt :当前运行的堆栈列表;
- bt backtrace 显示当前调用堆栈
- up/down 改变堆栈显示的深度
- set args 参数:指定运行时的参数
- show args:查看设置好的参数
- info program: 来查看程序的是否在运行,进程号,被暂停的原因。
分割窗口
- layout:用于分割窗口,可以一边查看代码,一边测试:
- layout src:显示源代码窗口
- layout asm:显示反汇编窗口
- layout regs:显示源代码/反汇编和CPU寄存器窗口
- layout split:显示源代码和反汇编窗口
- Ctrl + L:刷新窗口
23. Linux进程状态

(1)进程状态
- D:uninterruptible sleep (usually IO)
- R:running or runnable (on run queue) 可执行状态或运行态
- S:interruptible sleep (waiting for an event to complete) 可中断的睡眠状态
- T:stopped by job control signal
- t:stopped by debugger during the tracing
- W:paging (not valid since the 2.6.xx kernel)
- X:dead (should never be seen)
- Z:defunct (“zombie”) process, terminated but not - reaped by its parent
R (TASK_RUNNING),可执行状态
只有在该状态的进程才可能在CPU上运行。而同一时刻可能有多个进程处于可执行状态,这些进程的task_struct结构(进程控制块)被放入对应CPU的可执行队列中(一个进程最多只能出现在一个CPU的可执行队列中)。进而,进程调度器就从各个CPU的可执行队列中分别选择一个进程在该CPU上运行。
S (TASK_INTERRUPTIBLE),可中断的睡眠状态
处于这个状态的进程因为等待某某事件的发生(比如等待socket连接、等待信号量),而被挂起。这些进程的task_struct结构(进程控制块)被放入对应事件的等待队列中。当这些事件发生时(由外部中断触发、或由其他进程触发),对应的等待队列中的一个或多个进程将被唤醒。
通过ps命令会看到,一般情况下,进程列表中的绝大多数进程都处于TASK_INTERRUPTIBLE状态(除非机器的负载很高)。毕竟CPU就这么几个,进程动辄几十上百个,如果不是绝大多数进程都在睡眠,CPU又怎么响应得过来。
D (TASK_UNINTERRUPTIBLE),不可中断的睡眠状态
与TASK_INTERRUPTIBLE状态类似,进程处于睡眠状态,但是此刻进程是不可中断的。不可中断,指的并不是CPU不响应外部硬件的中断,而是指进程不响应异步信号。
绝大多数情况下,进程处在睡眠状态时,总是应该能够响应异步信号的。否则你将惊奇的发现,kill -9竟然杀不死一个正在睡眠的进程了!于是我们也很好理解,为什么ps命令看到的进程几乎不会出现TASK_UNINTERRUPTIBLE状态,而总是TASK_INTERRUPTIBLE状态。
而TASK_UNINTERRUPTIBLE状态存在的意义就在于,内核的某些处理流程是不能被打断的。如果响应异步信号,程序的执行流程中就会被插入一段用于处理异步信号的流程(这个插入的流程可能只存在于内核态,也可能延伸到用户态),于是原有的流程就被中断了。 例如,在进程对某些硬件进行操作时(比如进程调用read系统调用对某个设备文件进行读操作,而read系统调用最终执行到对应设备驱动的代码,并与对应的物理设备进行交互),可能需要使用TASK_UNINTERRUPTIBLE状态对进程进行保护,以避免进程与设备交互的过程被打断,造成设备陷入不可控的状态。这种情况下的TASK_UNINTERRUPTIBLE状态总是非常短暂的,通过ps命令基本上不可能捕捉到。
T/t (TASK_STOPPED or TASK_TRACED),暂停状态或跟踪状态
T (TASK_STOPPED)状态:向进程发送一个SIGSTOP信号,它就会因响应该信号而进入TASK_STOPPED状态(除非该进程本身处于TASK_UNINTERRUPTIBLE状态而不响应信号)。 SIGSTOP与SIGKILL信号一样,是非常强制的。不允许用户进程通过signal系列的系统调用重新设置对应的信号处理函数。 向进程发送一个SIGCONT信号(kill -18),可以让其从TASK_STOPPED状态恢复到TASK_RUNNING状态;或者kill -9直接尝试杀死。
t (TASK_STOPPED)状态:当进程正在被跟踪时,它处于TASK_TRACED这个特殊的状态。“正在被跟踪”指的是进程暂停下来,等待跟踪它的进程对它进行操作。比如在gdb(UNIX及UNIX-like下的调试工具)调试中对被跟踪的进程下一个断点,进程在断点处停下来的时候就处于TASK_TRACED状态。而在其他时候,被跟踪的进程还是处于前面提到的那些状态。
Z (TASK_DEAD - EXIT_ZOMBIE),退出状态,进程成为僵尸进程
进程在退出的过程中,处于TASK_DEAD状态。在这个退出过程中,进程占有的所有资源将被回收,除了task_struct结构(以及少数资源)以外。于是进程就只剩下task_struct这么个空壳,故称为僵尸。
之所以保留task_struct,是因为task_struct里面保存了进程的退出码、以及一些统计信息。而其父进程很可能会关心这些信息。父进程可以通过wait系列的系统调用(如wait4、waitid)来等待某个或某些子进程的退出,并获取它的退出信息(保存在task_struct里)。然后wait系列的系统调用会顺便将子进程的尸体(task_struct)也释放掉。
X (TASK_DEAD - EXIT_DEAD),退出状态,进程即将被销毁
进程在退出过程中也可能不会保留它的task_struct。比如这个进程是多线程程序中被detach过的进程。或者父进程通过设置SIGCHLD信号的handler为SIG_IGN,显式的忽略了SIGCHLD信号。(这是posix的规定,尽管子进程的退出信号可以被设置为SIGCHLD以外的其他信号。) 此时,进程将被置于EXIT_DEAD退出状态,这意味着接下来的代码立即就会将该进程彻底释放。所以EXIT_DEAD状态是非常短暂的,几乎不可能通过ps命令捕捉到。
24. 环境变量
Linux是一个多用户多任务的操作系统,可以在Linux中为不同的用户设置不同的运行环境,具体做法是设置不同用户的环境变量。
Linux环境变量分类
一、按照生命周期来分,Linux环境变量可以分为两类:
1、永久的:需要用户修改相关的配置文件,变量永久生效。
2、临时的:用户利用export命令,在当前终端下声明环境变量,关闭Shell终端失效。
二、按照作用域来分,Linux环境变量可以分为:
1、系统环境变量:系统环境变量对该系统中所有用户都有效。
2、用户环境变量:顾名思义,这种类型的环境变量只对特定的用户有效。
Linux设置环境变量的方法
一、在/etc/profile文件中添加变量 对所有用户生效(永久的)
用vim在文件/etc/profile文件中增加变量,该变量将会对Linux下所有用户有效,并且是“永久的”。
例如:编辑/etc/profile文件,添加CLASSPATH变量
vim /etc/profile
export CLASSPATH=./JAVA_HOME/lib;$JAVA_HOME/jre/lib
注:修改文件后要想马上生效还要运行source /etc/profile不然只能在下次重进此用户时生效。
二、在用户目录下的.bash_profile文件中增加变量 【对单一用户生效(永久的)】
用vim ~/.bash_profile文件中增加变量,改变量仅会对当前用户有效,并且是“永久的”。
vim ~/.bash.profileexport
CLASSPATH=./JAVA_HOME/lib;$JAVA_HOME/jre/lib
注:修改文件后要想马上生效还要运行$ source ~/.bash_profile不然只能在下次重进此用户时生效。
三、直接运行export命令定义变量 【只对当前shell(BASH)有效(临时的)】
在shell的命令行下直接使用export 变量名=变量值
定义变量,该变量只在当前的shell(BASH)或其子shell(BASH)下是有效的,shell关闭了,变量也就失效了,再打开新shell时就没有这个变量,需要使用的话还需要重新定义。
Linux环境变量使用
一、Linux中常见的环境变量有:
- PATH:指定命令的搜索路径
PATH声明用法:
PATH=$PAHT:: : :--------:< PATH n >
export PATH
你可以自己加上指定的路径,中间用冒号隔开。环境变量更改后,在用户下次登陆时生效。
可以利用echo $PATH查看当前当前系统PATH路径。
- HOME:指定用户的主工作目录(即用户登陆到Linux系统中时,默认的目录)。
- HISTSIZE:指保存历史命令记录的条数。
- LOGNAME:指当前用户的登录名。
- HOSTNAME:指主机的名称,许多应用程序如果要用到主机名的话,通常是从这个环境变量中来取得的
- SHELL:指当前用户用的是哪种Shell。
- LANG/LANGUGE:和语言相关的环境变量,使用多种语言的用户可以修改此环境变量。
- MAIL:指当前用户的邮件存放目录。
注意:上述变量的名字并不固定,如HOSTNAME在某些Linux系统中可能设置成HOST
二、Linux也提供了修改和查看环境变量的命令,下面通过几个实例来说明:
- echo 显示某个环境变量值 echo $PATH
- export 设置一个新的环境变量 export HELLO=“hello” (可以无引号)
- env 显示所有环境变量
- set 显示本地定义的shell变量
- unset 清除环境变量 unset HELLO
- readonly 设置只读环境变量 readonly HELLO
三、C程序调用环境变量函数
- getenv()返回一个环境变量。
- setenv()设置一个环境变量。
- unsetenv()清除一个环境变量。
25. 内核空间和用户空间
内核态:cpu可以访问内存的所有数据,包括外围设备,例如硬盘,网卡,cpu也可以将自己从一个程序切换到另一个程序。
用户态:只能受限的访问内存,且不允许访问外围设备,占用cpu的能力被剥夺,cpu资源可以被其他程序获取。
为什么要有用户态和内核态?
由于需要限制不同的程序之间的访问能力, 防止他们获取别的程序的内存数据, 或者获取外围设备的数据, 并发送到网络, CPU划分出两个权限等级 – 用户态和内核态。
现代的计算机体系结构中存储管理通常都包含保护机制。提供保护的目的,是要避免系统中的一个任务访问属于另外的或属于操作系统的存储区域。如在 IntelX86体系中,就提供了特权级这种保护机制,通过特权级别的区别来限制对存储区域的访问。 基于这种构架,Linux操作系统对自身进行了划分:一部分核心软件独立于普通应用程序,运行在较高的特权级别上,(Linux 使用Intel体系的特权级3来运行内核。)它们驻留在被保护的内存空间上,拥有访问硬件设备的所有权限, Linux将此称为内核空间。
相对的,其它部分被作为应用程序在用户空间执行。它们只能看到允许它们使用的部分系统资源,并且不能使用某些特定的系统功能,不能直接访问硬件,不能直接访问内核空间,当然还有其他一些具体的使用限制。(Linux使用 Intel体系的特权级0来运行用户程序。)
从 安全角度讲将用户空间和内核空间置于这种非对称访问机制下是很有效的,它能抵御恶意用户的窥探,也能防止质量低劣的用户程序的侵害,从而使系统运行得更稳 定可靠。但是,如果像这样完全不允许用户程序访问和使用内核空间的资源,那么我们的系统就无法提供任何有意义的功能了。为了方便用户程序使用在内核空间才 能完全控制的资源,而又不违反上述的特权规定,从硬件体系结构本身到操作系统,都定义了标准的访问界面。
内核与用户空间信息交互方式:
(1)使用内存映像
Linux通 过内存映像机制来提供用户程序对内存直接访问的能力。内存映像的意思是把内核中特定部分的内存空间映射到用户级程序的内存空间去。也就是说,用户空间和内 核空间共享一块相同的内存。这样做的直观效果显而易见:内核在这块地址内存储变更的任何数据,用户可以立即发现和使用,根本无须数据拷贝。而在使用系统调 用交互信息时,在整个操作过程中必须有一步数据拷贝的工作——或者是把内核数据拷贝到用户缓冲区,或只是把用户数据拷贝到内核缓冲区——这对于许多数据传 输量大、时间要求高的应用,这无疑是致命的一击:许多应用根本就无法忍受数据拷贝所耗费的时间和资源。
(2)编写自己的系统调用
从前文可以看出,系统调用是用户级程序访问内核最基本的方法。目前linux大致提供了二百多个标准的系统调用 , 并且允许我们添加自己的系统调用来实现和内核的信息交换。比如我们希望建立一个系统调用日志系统,将所有的系统调用动作记录下来,以便进行入侵检测。此 时,我们可以编写一个内核服务程序。该程序负责收集所有的系统调用请求,并将这些调用信息记录到在内核中自建的缓冲里。我们无法在内核里实现复杂的入侵检 测程序,因此必须将该缓冲里的记录提取到用户空间。最直截了当的方法是自己编写一个新系统调用实现这种提取缓冲数据的功能。当内核服务程序和新系统调用都 实现后,我们就可以在用户空间里编写用户程序进行入侵检测任务了,入侵检测程序可以定时、轮训或在需要的时候调用新系统调用从内核提取数据,然后进行入侵 检测(具体步骤和代码参见Linux内核之旅网站电子杂志第四期)。
1)用户态切换到内核态的3种方式
a. 系统调用
这是用户态进程主动要求切换到内核态的一种方式,用户态进程通过系统调用申请使用操作系统提供的服务程序完成工作,比如前例中fork()实际上就是执行了一个创建新进程的系统调用。而系统调用的机制其核心还是使用了操作系统为用户特别开放的一个中断来实现,例如Linux的int 80h中断。
b. 异常
当CPU在执行运行在用户态下的程序时,发生了某些事先不可知的异常,这时会触发由当前运行进程切换到处理此异常的内核相关程序中,也就转到了内核态,比如缺页异常。
c. 外围设备的中断
当外围设备完成用户请求的操作后,会向CPU发出相应的中断信号,这时CPU会暂停执行下一条即将要执行的指令转而去执行与中断信号对应的处理程序,如果先前执行的指令是用户态下的程序,那么这个转换的过程自然也就发生了由用户态到内核态的切换。比如硬盘读写操作完成,系统会切换到硬盘读写的中断处理程序中执行后续操作等。
26. Makefile
一个规则,两个函数,三个自动变量
makefile命令规则:makefile 和Makefile
写makefile文件为了便于管理项目,可以先分别编译每个文件,,然后联编。这样的话改动一个文件则其他.o文件不需要更改。
(1)一个规则
语法: 目标: 依赖条件
hello:hello.c[一个table]gcc hello.c -o hello
分部编译:
hello:hello.o gcc hello.o -o hellohello.o:hello.c gcc -c hello.c -o hello.o
(2)两个函数
src=$(wildcard *.c) //找到当前目录下所有后缀为.c的文件,赋值给srcobj=$(patsubst %.c,%.o, $(src)) //把src变量里所有后缀为.c的文件替换成.o
例子: 现有文件add.c sub.c div.c hello.c
src=$(wildcard *.c)obj=$(patsubset %.c,%.o,$(src))all:a.outa.out:$(obj) gcc $(obj) -o a.outclean: -rm -rf $(obj) a.out //"-"作用是删除不存在的文件时,不报错,顺序执行。
在使用make clean的时候可以使用:make clean -n命令,来模拟执行,避免误删。
(3)三个自动变量
$@ 表示规则命令中的目标$< 表示规则中的第一个条件$^ 表示规则中的所有条件,组成一个列表,以空格隔开,如果这个列表中有重复的项则消除重复的项
模式规则:
%.o:%.c gcc -c $< -o $@
通常在makefile中定义一些变量,方便修改维护:
src =main.c fun1.c fun2.cCC=gccCPPFLAGS:c预处理的选项 如-ICFLAGS:C编译器的选项 -Wall -g -cLDFLAGS:连接器选项 -L -l
27. 中断处理流程
(1)获取中断号
将中断号压入栈中,将当前寄存器信息压入栈中,栈上的信息作为函数参数,调用do_IRQ函数
当中断发生时,Linux系统会跳转到asm_do_IRQ()函数(所有中断程序的总入口函数),并且把中断号irq传进来。根据中断号,找到中断号对应的irq_desc结构(irq_desc结构为内核中中断的描述结构,内核中有一个irq_desc结构的数组irq_desc_ptrs[NR_IRQS]),然后调用irq_desc中的handle_irq函数,即中断入口函数。我们编写中断的驱动,即填充并注册irq_desc结构。
较好的解释:
https://www.cnblogs.com/aaronLinux/p/10842499.html
28. 内核信号捕捉过程
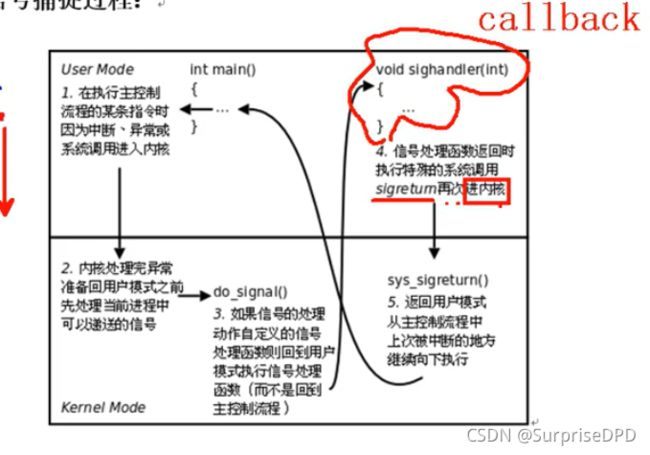
29. Linux x86程序启动-main如何被执行到
https://zhuanlan.zhihu.com/p/52054044
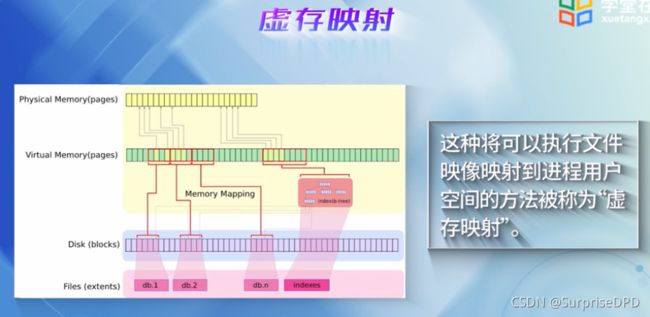
30. Linux内存管理
(1)进程空间数据结构关系


31. valgrind调试
valgrind。
valgrind是一款专门用作内存调试,内存泄露检测的开源工具软件,valgrind这个名字取自北欧神话英灵殿的入口,不过,不能不承认,它确实是Linux下做内存调用分析的神器。一般Linux系统上应该没有自带valgrind,需要自行进行下载安装。
下载地址:http://valgrind.org/downloads/current.html
进入下载文件夹,分别执行(需要root权限,且必须按默认路径安装,否则有加载错误):
./configure
make
make install
安装成功后,使用类似如下命令启动程序:
valgrind --tool=memcheck --leak-check=full --track-origins=yes --leak-resolution=high --show-reachable=yes --log-file=memchecklog ./controller_test
其中,–log-file=memchecklog指记录日志文件,名字为memchecklog;–tool=memcheck和**–leak-check=ful**l用于内存检测。
可以得到类似的记录:
==23735====23735== Thread 1:==23735== Invalid read of size 4==23735== at 0x804F327: ResourceHandler::~ResourceHandler() (ResourceHandler.cpp:48)==23735== by 0x804FDBE: ConnectionManager::~ConnectionManager() (ConnectionManager.cpp:74)==23735== by 0×8057288: MainThread::~MainThread() (MainThread.cpp:73)==23735== by 0x8077B2F: main (Main.cpp:177)==23735== Address 0×0 is not stack’d, malloc’d or (recently) free’d==23735==
可以看到说明为无法访问Address 0x0,明显为一处错误。
这样valgrind直接给出了出错原因以及程序中所有的内存调用、释放记录,非常智能,在得知错误原因的情况下,找出错误就效率高多了。
再说一句,valgrind同时给出了程序的Memory Leak情况的报告,给出了new-delete对应情况,所有泄漏点位置给出,这一点在其他工具很难做到,十分好用。
32. gdb core文件调试
linux core dump 文件 gdb分析
core dump又叫核心转储, 当程序运行过程中发生异常, 程序异常退出时, 由操作系统把程序当前的内存状况存储在一个core文件中, 叫core dump. (linux中如果内存越界会收到SIGSEGV信号,然后就会core dump)
在程序运行的过程中,有的时候我们会遇到Segment fault(段错误)这样的错误。这种看起来比较困难,因为没有任何的栈、trace信息输出。该种类型的错误往往与指针操作相关。往往可以通过这样的方式进行定位。
一 造成segment fault,产生core dump的可能原因
1.内存访问越界
a) 由于使用错误的下标,导致数组访问越界
b) 搜索字符串时,依靠字符串结束符来判断字符串是否结束,但是字符串没有正常的使用结束符
c) 使用strcpy, strcat, sprintf, strcmp, strcasecmp等字符串操作函数,将目标字符串读/写爆。应该使用strncpy, strlcpy, strncat, strlcat, snprintf, strncmp, strncasecmp等函数防止读写越界。
2 多线程程序使用了线程不安全的函数。
3 多线程读写的数据未加锁保护。对于会被多个线程同时访问的全局数据,应该注意加锁保护,否则很容易造成core dump
4 非法指针
a) 使用空指针
b) 随意使用指针转换。一个指向一段内存的指针,除非确定这段内存原先就分配为某种结构或类型,或者这种结构或类型的数组,否则不要将它转换为这种结构或类型的指针,而应该将这段内存拷贝到一个这种结构或类型中,再访问这个结构或类型。这是因为如果这段内存的开始地址不是按照这种结构或类型对齐的,那么访问它时就很容易因为bus error而core dump.
5 堆栈溢出.不要使用大的局部变量(因为局部变量都分配在栈上),这样容易造成堆栈溢出,破坏系统的栈和堆结构,导致出现莫名其妙的错误。
二 配置操作系统使其产生core文件
首先通过ulimit命令查看一下系统是否配置支持了dump core的功能。通过ulimit -c或ulimit -a,可以查看core file大小的配置情况,如果为0,则表示系统关闭了dump core。可以通过ulimit -c unlimited来打开。若发生了段错误,但没有core dump,是由于系统禁止core文件的生成。
解决方法:
$ulimit -c unlimited (只对当前shell进程有效)
或在**~/.bashrc** 的最后加入: ulimit -c unlimited (一劳永逸)
\# ulimit -c
0
$ ulimit -a
core file size (blocks, -c) 0
data seg size (kbytes, -d) unlimited
file size (blocks, -f) unlimited
三 用gdb查看core文件
发生core dump之后, 用gdb进行查看core文件的内容, 以定位文件中引发core dump的行.
gdb [exec file] [core file]
如: gdb ./test test.core
使用gdb 调试方法,首先要在gcc编译时加入-g选项。
调试core文件,在Linux命令行下:gdb pname corefile。
例如,程序名为controller_tester,core文件为core.3421,则为:gdb controller_tester core.3421。
这样进入了gdb core调试模式。
追踪产生segmenttation fault的位置及代码函数调用情况:
gdb>bt
这样,一般就可以看到出错的代码是哪一句了,还可以打印出相应变量的数值,进行进一步分析。
gdb>print 变量名
之后,就全看各位自己的编程功力与经验了,gdb已经做了很多了。
33. 调试段错误的方法
1 dmesg
dmesg可以在应用程序crash掉时,显示内核中保存的相关信息。如下所示,通过dmesg命令可以查看发生段错误的程序名称、引起段错误发生的内存地址、指令指针地址、堆栈指针地址、错误代码、错误原因等。以程序2.3为例:
panfeng@ubuntu:~/segfault$ dmesg[ 2329.479037] segfault3[2700]: segfault at 80484e0 ip 00d2906a sp bfbbec3c error 7 in libc2.10.1.so[cb4000+13e000]12
2 -g
使用gcc编译程序的源码时,加上-g参数,这样可以使得生成的二进制文件中加入可以用于gdb调试的有用信息。以程序2.3为例:
panfeng@ubuntu:~/segfault$ gcc -g -o segfault3 segfault3.c1
3.3 nm
使用nm命令列出二进制文件中的符号表,包括符号地址、符号类型、符号名等,这样可以帮助定位在哪里发生了段错误。以程序2.3为例:
复制代码
panfeng@ubuntu:~/segfault$ nm segfault308049f20 d _DYNAMIC08049ff4 d _GLOBAL_OFFSET_TABLE_080484dc R _IO_stdin_used w _Jv_RegisterClasses08049f10 d __CTOR_END__08049f0c d __CTOR_LIST__08049f18 D __DTOR_END__08049f14 d __DTOR_LIST__080484ec r __FRAME_END__08049f1c d __JCR_END__08049f1c d __JCR_LIST__0804a014 A __bss_start0804a00c D __data_start08048490 t __do_global_ctors_aux08048360 t __do_global_dtors_aux0804a010 D __dso_handle w __gmon_start__0804848a T __i686.get_pc_thunk.bx08049f0c d __init_array_end08049f0c d __init_array_start08048420 T __libc_csu_fini08048430 T __libc_csu_init U __libc_start_main@@GLIBC_2.00804a014 A _edata0804a01c A _end080484bc T _fini080484d8 R _fp_hw080482bc T _init08048330 T _start0804a014 b completed.69900804a00c W data_start0804a018 b dtor_idx.6992080483c0 t frame_dummy080483e4 T main U memcpy@@GLIBC_2.0123456789101112131415161718192021222324252627282930313233343536
4.ldd
使用ldd命令查看二进制程序的共享链接库依赖,包括库的名称、起始地址,这样可以确定段错误到底是发生在了自己的程序中还是依赖的共享库中。以程序2.3为例:
panfeng@ubuntu:~/segfault$ ldd ./segfault3 linux-gate.so.1 => (0x00e08000) libc.so.6 => /lib/tls/i686/cmov/libc.so.6 (0x00675000) /lib/ld-linux.so.2 (0x00482000)1234
2.段错误的调试方法
2.1 使用printf输出信息
这个是看似最简单但往往很多情况下十分有效的调试方式,也许可以说是程序员用的最多的调试方式。简单来说,就是在程序的重要代码附近加上像printf这类输出信息,这样可以跟踪并打印出段错误在代码中可能出现的位置。
为了方便使用这种方法,可以使用条件编译指令#ifdef DEBUG和#endif把printf函数包起来。这样在程序编译时,如果加上-DDEBUG参数就能查看调试信息;否则不加该参数就不会显示调试信息。
2.2 使用gcc和gdb
2.2.1 调试步骤
1、为了能够使用gdb调试程序,在编译阶段加上-g参数,以程序2.3为例:
panfeng@ubuntu:~/segfault$ gcc -g -o segfault3 segfault3.c1
2、使用gdb命令调试程序:
panfeng@ubuntu:~/segfault$ gdb ./segfault3 GNU gdb (GDB) 7.0-ubuntuCopyright (C) 2009 Free Software Foundation, Inc.License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html>This is free software: you are free to change and redistribute it.There is NO WARRANTY, to the extent permitted by law. Type "show copying"and "show warranty" for details.This GDB was configured as "i486-linux-gnu".For bug reporting instructions, please see:<http://www.gnu.org/software/gdb/bugs/>...Reading symbols from /home/panfeng/segfault/segfault3...done.(gdb) 123456789101112
3、进入gdb后,运行程序:
(gdb) runStarting program: /home/panfeng/segfault/segfault3 Program received signal SIGSEGV, Segmentation fault.0x001a306a in memcpy () from /lib/tls/i686/cmov/libc.so.6(gdb) 123456
从输出看出,程序2.3收到SIGSEGV信号,触发段错误,并提示地址0x001a306a、调用memcpy报的错,位于/lib/tls/i686/cmov/libc.so.6库中。
4、完成调试后,输入quit命令退出gdb:
(gdb) quitA debugging session is active. Inferior 1 [process 3207] will be killed.Quit anyway? (y or n) y123456
2.2.2 适用场景
1、仅当能确定程序一定会发生段错误的情况下使用。
2、当程序的源码可以获得的情况下,使用-g参数编译程序。
3、一般用于测试阶段,生产环境下gdb会有副作用:使程序运行减慢,运行不够稳定,等等。
4、即使在测试阶段,如果程序过于复杂,gdb也不能处理。
2.3 使用core文件和gdb
在4.2节中提到段错误会触发SIGSEGV信号,通过man 7 signal,可以看到SIGSEGV默认的handler会打印段错误出错信息,并产生core文件,由此我们可以借助于程序异常退出时生成的core文件中的调试信息,使用gdb工具来调试程序中的段错误。
2.3.1 调试步骤
1、在一些Linux版本下,默认是不产生core文件的,首先可以查看一下系统core文件的大小限制:
panfeng@ubuntu:~/segfault$ ulimit -c012
2、可以看到默认设置情况下,本机Linux环境下发生段错误时不会自动生成core文件,下面设置下core文件的大小限制(单位为KB):
panfeng@ubuntu:~/segfault$ ulimit -c
1024panfeng@ubuntu:~/segfault$ ulimit -c10241234
3、运行程序2.3,发生段错误生成core文件:
panfeng@ubuntu:~/segfault$ ./segfault3段错误 (core dumped)12
4、加载core文件,使用gdb工具进行调试:
panfeng@ubuntu:~/segfault$ gdb ./segfault3 ./core GNU gdb (GDB) 7.0-ubuntuCopyright (C) 2009 Free Software Foundation, Inc.License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html>This is free software: you are free to change and redistribute it.There is NO WARRANTY, to the extent permitted by law. Type "show copying"and "show warranty" for details.This GDB was configured as "i486-linux-gnu".For bug reporting instructions, please see:<http://www.gnu.org/software/gdb/bugs/>...Reading symbols from /home/panfeng/segfault/segfault3...done.warning: Can't read pathname for load map: 输入/输出错误.Reading symbols from /lib/tls/i686/cmov/libc.so.6...(no debugging symbols found)...done.Loaded symbols for /lib/tls/i686/cmov/libc.so.6Reading symbols from /lib/ld-linux.so.2...(no debugging symbols found)...done.Loaded symbols for /lib/ld-linux.so.2Core was generated by `./segfault3'.Program terminated with signal 11, Segmentation fault.#0 0x0018506a in memcpy () from /lib/tls/i686/cmov/libc.61234567891011121314151617181920
从输出看出,同4.2.1中一样的段错误信息。
5、完成调试后,输入quit命令退出gdb:
(gdb) quit1
4.3.2 适用场景
1、适合于在实际生成环境下调试程序的段错误(即在不用重新发生段错误的情况下重现段错误)。
2、当程序很复杂,core文件相当大时,该方法不可用。
4.4 使用objdump
4.4.1 调试步骤
1、使用dmesg命令,找到最近发生的段错误输出信息:
panfeng@ubuntu:~/segfault$ dmesg... ...[17257.502808] segfault3[3320]: segfault at 80484e0 ip 0018506a sp bfc1cd6c error 7 in libc-2.10.1.so[110000+13e000]123
其中,对我们接下来的调试过程有用的是发生段错误的地址:80484e0和指令指针地址:0018506a。
2、使用objdump生成二进制的相关信息,重定向到文件中:
panfeng@ubuntu:~/segfault$ objdump -d ./segfault3 > segfault3Dump1
其中,生成的segfault3Dump文件中包含了二进制文件的segfault3的汇编代码。
3、在segfault3Dump文件中查找发生段错误的地址:
panfeng@ubuntu:~/segfault$ grep -n -A 10 -B 10 "80484e0" ./segfault3Dump 121- 80483df: ff d0 call *%eax122- 80483e1: c9 leave 123- 80483e2: c3 ret 124- 80483e3: 90 nop125-126-080483e4 <main>:127- 80483e4: 55 push %ebp128- 80483e5: 89 e5 mov %esp,%ebp129- 80483e7: 83 e4 f0 and $0xfffffff0,%esp130- 80483ea: 83 ec 20 sub $0x20,%esp131: 80483ed: c7 44 24 1c e0 84 04 movl $0x80484e0,0x1c(%esp)132- 80483f4: 08 133- 80483f5: b8 e5 84 04 08 mov $0x80484e5,%eax134- 80483fa: c7 44 24 08 05 00 00 movl $0x5,0x8(%esp)135- 8048401: 00 136- 8048402: 89 44 24 04 mov %eax,0x4(%esp)137- 8048406: 8b 44 24 1c mov 0x1c(%esp),%eax138- 804840a: 89 04 24 mov %eax,(%esp)139- 804840d: e8 0a ff ff ff call 804831c <memcpy@plt>140- 8048412: c9 leave 141- 8048413: c3 ret 12345678910111213141516171819202122
通过对以上汇编代码分析,得知段错误发生main函数,对应的汇编指令是movl $0x80484e0,0x1c(%esp),接下来打开程序的源码,找到汇编指令对应的源码,也就定位到段错误了。
4.4.2 适用场景
1、不需要-g参数编译,不需要借助于core文件,但需要有一定的汇编语言基础。
2、如果使用了gcc编译优化参数(-O1,-O2,-O3)的话,生成的汇编指令将会被优化,使得调试过程有些难度。
4.5 使用catchsegv
catchsegv命令专门用来扑获段错误,它通过动态加载器(ld-linux.so)的预加载机制(PRELOAD)把一个事先写好的库(/lib/libSegFault.so)加载上,用于捕捉断错误的出错信息。
panfeng@ubuntu:~/segfault$ catchsegv ./segfault3Segmentation fault (core dumped)*** Segmentation faultRegister dump: EAX: 00000000 EBX: 00fb3ff4 ECX: 00000002 EDX: 00000000 ESI: 080484e5 EDI: 080484e0 EBP: bfb7ad38 ESP: bfb7ad0c EIP: 00ee806a EFLAGS: 00010203 CS: 0073 DS: 007b ES: 007b FS: 0000 GS: 0033 SS: 007b Trap: 0000000e Error: 00000007 OldMask: 00000000 ESP/signal: bfb7ad0c CR2: 080484e0Backtrace:/lib/libSegFault.so[0x3b606f]??:0(??)[0xc76400]/lib/tls/i686/cmov/libc.so.6(__libc_start_main+0xe6)[0xe89b56]/build/buildd/eglibc-2.10.1/csu/../sysdeps/i386/elf/start.S:122(_start)[0x8048351]Memory map:00258000-00273000 r-xp 00000000 08:01 157 /lib/ld-2.10.1.so00273000-00274000 r--p 0001a000 08:01 157 /lib/ld-2.10.1.so00274000-00275000 rw-p 0001b000 08:01 157 /lib/ld-2.10.1.so003b4000-003b7000 r-xp 00000000 08:01 13105 /lib/libSegFault.so003b7000-003b8000 r--p 00002000 08:01 13105 /lib/libSegFault.so003b8000-003b9000 rw-p 00003000 08:01 13105 /lib/libSegFault.so00c76000-00c77000 r-xp 00000000 00:00 0 [vdso]00e0d000-00e29000 r-xp 00000000 08:01 4817 /lib/libgcc_s.so.100e29000-00e2a000 r--p 0001b000 08:01 4817 /lib/libgcc_s.so.100e2a000-00e2b000 rw-p 0001c000 08:01 4817 /lib/libgcc_s.so.100e73000-00fb1000 r-xp 00000000 08:01 1800 /lib/tls/i686/cmov/libc-2.10.1.so00fb1000-00fb2000 ---p 0013e000 08:01 1800 /lib/tls/i686/cmov/libc-2.10.1.so00fb2000-00fb4000 r--p 0013e000 08:01 1800 /lib/tls/i686/cmov/libc-2.10.1.so00fb4000-00fb5000 rw-p 00140000 08:01 1800 /lib/tls/i686/cmov/libc-2.10.1.so00fb5000-00fb8000 rw-p 00000000 00:00 008048000-08049000 r-xp 00000000 08:01 303895 /home/panfeng/segfault/segfault308049000-0804a000 r--p 00000000 08:01 303895 /home/panfeng/segfault/segfault30804a000-0804b000 rw-p 00001000 08:01 303895 /home/panfeng/segfault/segfault309432000-09457000 rw-p 00000000 00:00 0 [heap]b78cf000-b78d1000 rw-p 00000000 00:00 0b78df000-b78e1000 rw-p 00000000 00:00 0bfb67000-bfb7c000 rw-p 00000000 00:00 0 [stack]123456789101112131415161718192021222324252627282930313233343536373839404142434445
- 一些注意事项
1、出现段错误时,首先应该想到段错误的定义,从它出发考虑引发错误的原因。
2、在使用指针时,定义了指针后记得初始化指针,在使用的时候记得判断是否为NULL。
3、在使用数组时,注意数组是否被初始化,数组下标是否越界,数组元素是否存在等。
4、在访问变量时,注意变量所占地址空间是否已经被程序释放掉。
5、在处理变量时,注意变量的格式控制是否合理等。
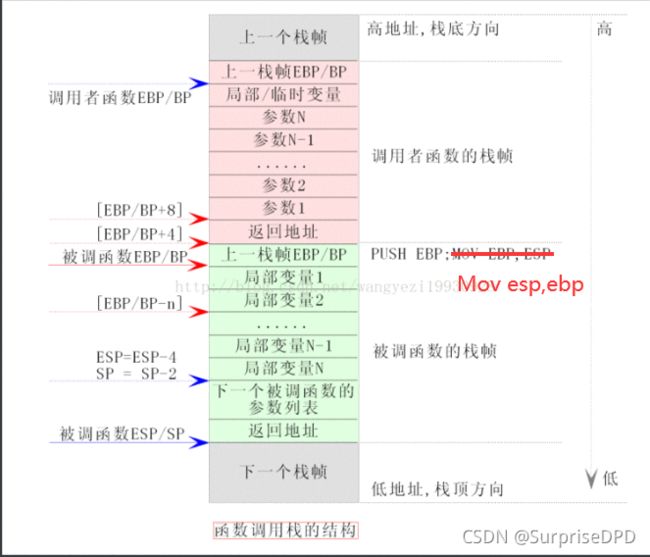
34. 函数调用过程
当发生函数调用的时候,栈空间中存放的数据是这样的:
1、调用者函数把被调函数所需要的参数按照与被调函数的形参顺序相反的顺序压入栈中,即:从右向左依次把被调函数所需要的参数压入栈;
2、调用者函数使用call指令调用被调函数,并把call指令的下一条指令的地址当成返回地址压入栈中(这个压栈操作隐含在call指令中);
3、在被调函数中,被调函数会先保存调用者函数的栈底地址(push ebp),然后再保存调用者函数的栈顶地址,即:当前被调函数的栈底地址(mov ebp,esp);
4、在被调函数中,从ebp的位置处开始存放被调函数中的局部变量和临时变量,并且这些变量的地址按照定义时的顺序依次减小,即:这些变量的地址是按照栈的延伸方向排列的,先定义的变量先入栈,后定义的变量后入栈;
所以,发生函数调用时,入栈的顺序为:
参数N
参数N-1
参数N-2
…
参数3
参数2
参数1
函数返回地址
上一层调用函数的EBP/BP
局部变量1
局部变量2
…
局部变量N
*函数调用栈如下图所示:*
35. linux内核解析笔记
35.1register 寄存器


cpu实际取指令时是通过cs:eip来定位一条指令。
另外还有标志寄存器,参数比较多。
35.2 寻址模式和简单指令

pushl %eax 等价的命令为:subl $4,%esp //将栈顶指针esp减4,因为栈是向下增长,向低地址增加movl %eax,(%esp)//然后将eax中存放的值放到esp所指地址中至此就完成了压栈动作
popl %eax 等价命令:movl (%esp),%eax //将esp保存的地址的值赋给eaxaddl $4,%esp //将esp保存的地址加4至此完成了弹栈操作
call 0x12345 等价命令:pushl %eip(*) //将eip保存的下一条指令地址压栈movl $0x12345 ,%eip(*) //将0x12345这个地址作为立即数赋给eip,完成跳转
ret 命令等价于:popl %eip(*) //从堆栈中弹出下一条指令到eip执行
两个宏指令
enter 等价于:pushl %ebp //创建栈帧movl %esp,%ebp
leave 等价于:movl %ebp,%esp //栈帧回退,esp转到当前栈帧的ebp位置,popl %ebp //ebp变为从栈中弹出的值,即上个栈帧的ebp位置
35.3 函数调用过程

整个栈操作的过程是:
1.调用者执行call指令,调用背调函数,call指令完成:将eip(保存着下一条指令)压入栈中,设置eip为被调用代码的第一条指令。2.进入被调用函数体内,创建被调用函数的栈帧,先将上一个栈帧的ebp入栈,然后将ebp与esp调整到相同位置,此位置为这个函数栈帧的开始位置。3.然后就是执行函数体4.退栈,将ebp保存的地址赋给esp,这样就使esp跳转到了这个函数栈帧的底部,并重新给ebp赋值,然后就进入了调用函数的栈帧。5.然后执行ret从栈中弹出eip的新指令,进入调用者的下一条指令执行。
g: pushl %ebp movl %esp,%ebp movl 8(%ebp),%eax addl $3,%eax popl %ebp retf: pushl %ebp movl %esp, %ebp subl $4, %esp movl 8(%ebp), %eax movl %eax, (%esp) call g leave retmain: pushl %ebp movl %esp, %ebp subl $4, %esp movl $8, (%esp) call f addl $1, %eax leave ret
36. linux下检查内存状态的命令
1、free命令
free 命令会显示系统内存的使用情况,包括物理内存、交换内存(swap)和内核缓冲区内存等。
$ free total used free shared buff/cache availableMem: 32946324 2489392 11422656 1622872 19034276 28352888Swap: 0 0 0
释义:
Mem:内存使用情况。
Swap:交换空间(虚拟内存)使用情况。
total:系统总共可用物理内存、交换空间大小。
used:已经被使用的物理内存、交换空间大小。
free:剩余可用物理内存、交换空间大小。
shared:被共享使用的物理内存大小。
buff/cache:被 buffer 和 cache 使用的物理内存大小。
available:还可以被应用程序使用的物理内存大小。
常见用法:
free -h //以更友好的方式显示,会以K、M、G为单位来显示free -h -s 3 //以一定时间间隔重复的输出,这个命令是每3秒输出一次
free 命令中的信息都来自于 /proc/meminfo 文件。
2、vmstat命令
vmstat 是Virtual Meomory Statistics(虚拟内存统计)的缩写,可对操作系统的虚拟内存、进程、CPU活动进行监控,是对系统的整体情况进行的统计。
$ vmstatprocs -----------memory----------- --swap-- --io-- --system-- -----cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 1 0 0 14376368 161976 1130836 0 0 0 3 2 2 0 0 100 0 0
与内存使用情况相关的是memory列和swap列,我们只看这两列。
memory列
swpd:使用的虚拟内存大小。
free:空闲物理内存大小。
buff:buffer cache内存大小。
cache:page cache的内存大小。
swap列
si:每秒从交换区读入到内存的大小,由磁盘调入内存(单位:kb/s)
so:每秒从内存写出到交换区的大小,由内存调入磁盘(单位:kb/s)
常见用法:
vmstat 1 //每隔1s打印一次vmstat 1 5 //每隔1秒打印一次,打印五次vmstat -s //显示内存相关统计信息及多种系统活动数量
3、top命令
使用top命令,可以查看正在运行的进程和系统负载信息,包括cpu负载、内存使用、各个进程所占系统资源等,top命令以一定频率动态更新这些统计信息。
top - 10:45:21 up 211 days, 17:14, 2 users, load average: 0.08, 0.09, 0.03Tasks: 228 total, 1 running, 227 sleeping, 0 stopped, 0 zombieCpu(s): 0.4%us, 0.1%sy, 0.1%ni, 99.4%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%stMem: 32880232k total, 22032060k used, 10848172k free, 569680k buffersSwap: 0k total, 0k used, 0k free, 17771208k cached PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 9757 root 20 0 15160 1224 836 R 2.0 0.0 0:00.01 top 1 root 20 0 19364 1644 1312 S 0.0 0.0 2:06.03 init 2 root 20 0 0 0 0 S 0.0 0.0 0:00.30 kthreadd 3 root RT 0 0 0 0 S 0.0 0.0 0:02.75 migration/0 4 root 20 0 0 0 0 S 0.0 0.0 2:04.41 ksoftirqd/0 5 root RT 0 0 0 0 S 0.0 0.0 0:00.00 stopper/0 6 root RT 0 0 0 0 S 0.0 0.0 0:39.92 watchdog/0 7 root RT 0 0 0 0 S 0.0 0.0 0:01.44 migration/1 8 root RT 0 0 0 0 S 0.0 0.0 0:00.00 stopper/1 9 root 20 0 0 0 0 S 0.0 0.0 1:23.26 ksoftirqd/1 10 root RT 0 0 0 0 S 0.0 0.0 0:31.05 watchdog/1 11 root RT 0 0 0 0 S 0.0 0.0 0:02.06 migration/2 12 root RT 0 0 0 0 S 0.0 0.0 0:00.00 stopper/2 13 root 20 0 0 0 0 S 0.0 0.0 0:45.78 ksoftirqd/2 14 root RT 0 0 0 0 S 0.0 0.0 0:29.91 watchdog/2 15 root RT 0 0 0 0 S 0.0 0.0 0:10.61 migration/3 16 root RT 0 0 0 0 S 0.0 0.0 0:00.00 stopper/3 17 root 20 0 0 0 0 S 0.0 0.0 1:57.03 ksoftirqd/3 18 root RT 0 0 0 0 S 0.0 0.0 0:32.77 watchdog/3 19 root RT 0 0 0 0 S 0.0 0.0 0:01.82 migration/4 20 root RT 0 0 0 0 S 0.0 0.0 0:00.00 stopper/4 21 root 20 0 0 0 0 S 0.0 0.0 1:58.64 ksoftirqd/4 22 root RT 0 0 0 0 S 0.0 0.0 0:32.96 watchdog/4 23 root RT 0 0 0 0 S 0.0 0.0 0:03.28 migration/5 24 root RT 0 0 0 0 S 0.0 0.0 0:00.00 stopper/5 25 root 20 0 0 0 0 S 0.0 0.0 0:50.67 ksoftirqd/5 26 root RT 0 0 0 0 S 0.0 0.0 0:30.28 watchdog/5 27 root RT 0 0 0 0 S 0.0 0.0 0:06.60 migration/6 28 root RT 0 0 0 0 S 0.0 0.0 0:00.00 stopper/6
反映系统内存使用状况的是下面这两行:
Mem: 32880232k total, 22032060k used, 10848172k free, 569680k buffersSwap: 0k total, 0k used, 0k free, 17771208k cached
Mem行是物理内存使用情况,分别是:物理内存总量,已使用的物理内存总量,空闲物理内存总量,用作内核缓存区的内存量。
Swap行是交换区使用情况,分别是:交换区总量,已使用的交换区总量,空闲交换区总量,缓冲的交换区总量。
Top命令的下侧区域显示的是各个进程使用的系统资源统计信息,内存相关列如下:
- VIRT列:进程使用的虚拟内存总量,单位kb。
- RES列:进程使用的、未被换出的物理内存大小,单位kb。
- SHR列:共享内存大小,单位kb。
- %MEM 列:进程使用的物理内存百分比。
4、cat /proc/meminfo
/proc/meminfo是了解Linux系统内存使用状况的主要接口,我们最常用的”free”、”vmstat”等命令就是通过它获取数据的。/proc/meminfo所包含的信息比”free”等命令要丰富得多,但也很复杂,不再一一解释了。感兴趣的话可以看看这篇文章:http://linuxperf.com/?p=142,对 /proc/meminfo 有较详细的解释。
[[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-yaxwX3PI-1631758063265)(linux编程笔记和C++编程笔记.assets/copycode.gif)]](javascript:void(0)
$ cat /proc/meminfoMemTotal: 16430636 kBMemFree: 14376492 kBMemAvailable: 15298732 kBBuffers: 161976 kBCached: 1022440 kBSwapCached: 0 kBActive: 1369780 kBInactive: 438696 kBActive(anon): 624376 kBInactive(anon): 49444 kBActive(file): 745404 kBInactive(file): 389252 kBUnevictable: 0 kBMlocked: 0 kBSwapTotal: 0 kBSwapFree: 0 kBDirty: 60 kBWriteback: 0 kBAnonPages: 624068 kBMapped: 88140 kBShmem: 49752 kBSlab: 108076 kBSReclaimable: 82864 kBSUnreclaim: 25212 kBKernelStack: 4464 kBPageTables: 10480 kBNFS_Unstable: 0 kBBounce: 0 kBWritebackTmp: 0 kBCommitLimit: 8215316 kBCommitted_AS: 1811204 kBVmallocTotal: 34359738367 kBVmallocUsed: 34780 kBVmallocChunk: 34359695100 kBHardwareCorrupted: 0 kBAnonHugePages: 182272 kBCmaTotal: 0 kBCmaFree: 0 kBHugePages_Total: 0HugePages_Free: 0HugePages_Rsvd: 0HugePages_Surp: 0Hugepagesize: 2048 kBDirectMap4k: 169832 kBDirectMap2M: 8218624 kBDirectMap1G: 10485760 kB
[[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rTN1OVnJ-1631758063265)(linux编程笔记和C++编程笔记.assets/copycode.gif)]](javascript:void(0)
5、 ps aux命令
ps aux 命令可以查看系统中各个进程的运行情况,包括了进程占用的内存,%MEM 列就是各个进程的内存占用百分比。
[[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-G34xQvWa-1631758063266)(linux编程笔记和C++编程笔记.assets/copycode.gif)]](javascript:void(0)
$ ps auxUSER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMANDroot 1231 0.9 2.2 1368496 375824 ? SNl Jun21 346:39 ./bcm-agentbls 6891 0.1 0.9 2892024 159516 ? Sl Jun21 55:29 /opt/bls/lib/jre/bin/java -Duser.language=en_us -Xmx500m -XX:+UseParallelGC -XX:+UseParallelOldGC -root 389 0.0 0.2 96376 46212 ? Ss Jun21 0:14 /usr/lib/systemd/systemd-journaldroot 1245 0.0 0.2 1200080 40200 ? Sl Jun21 19:48 /opt/hosteye/bin/hosteye --is_child_mode=true --is_console_mode=false --start_mode=0root 1199 0.0 0.1 288132 28188 ? Ssl Jun21 2:06 /usr/sbin/rsyslogd -nroot 898 0.0 0.1 573840 17152 ? Ssl Jun21 5:08 /usr/bin/python -Es /usr/sbin/tuned -l -P
[[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-B9WCXKAw-1631758063266)(linux编程笔记和C++编程笔记.assets/copycode.gif)]](javascript:void(0)
二. C++笔记
1. 局部变量和全局变量问题
(1)全局变量和局部变量可否重名
可以,局部变量会屏蔽全局。使用全局变量需要用”::“
(2)如何引用一个已经定义过的全局变量
答:extern
可以用引用头文件的方式,也可以用extern关键字,如果用引用头文件方式来引用某个在头文件中声明的全局变理,假定你将那个变写错了,那么在编译期间会报错,如果你用extern方式引用时,假定你犯了同样的错误,那么在编译期间不会报错,而在连接期间报错。
(3)全局变量可不可以定义在可被多个.C文件包含的头文件中?为什么?
答:可以,在不同的C文件中以static形式来声明同名全局变量。
可以在不同的C文件中声明同名的全局变量,前提是其中只能有一个C文件中对此变量赋初值,此时连接不会出错
(4)static全局变量与普通的全局变量有什么区别?static局部变量和普通局部变量有什么区别?static函数与普通函数有什么区别?
全局变量(外部变量)的说明之前再冠以static 就构成了静态的全局变量。全局变量本身就是静态存储方式,静态全局变量当然也是静态存储方式。 这两者在存储方式上并无不同。这两者的区别虽在于非静态全局变量的作用域是整个源程序,当一个源程序由多个源文件组成时,非静态的全局变量在各个源文件中都是有效的。而静态全局变量则限制了其作用域, 即只在定义该变量的源文件内有效, 在同一源程序的其它源文件中不能使用它。由于静态全局变量的作用域局限于一个源文件内,只能为该源文件内的函数公用,因此可以避免在其它源文件中引起错误。
从以上分析可以看出, 把局部变量改变为静态变量后是改变了它的存储方式即改变了它的生存期。把全局变量改变为静态变量后是改变了它的作用域,限制了它的使用范围。
static函数与普通函数作用域不同,仅在本文件。只在当前源文件中使用的函数应该说明为内部函数(static),内部函数应该在当前源文件中说明和定义。对于可在当前源文件以外使用的函数,应该在一个头文件中说明,要使用这些函数的源文件要包含这个头文件
static全局变量与普通的全局变量有什么区别:static全局变量只初使化一次,防止在其他文件单元中被引用;
static局部变量和普通局部变量有什么区别:static局部变量只被初始化一次,下一次依据上一次结果值;
static函数与普通函数有什么区别:static函数在内存中只有一份,普通函数在每个被调用中维持一份拷贝.
5、程序的局部变量存在于(堆栈)中,全局变量存在于(静态区 )中,动态申请数据存在于( 堆)中。
变量可以在程序中三个地方说明: 函数内部、函数的参数定义中或所有的函数外部。根据所定义位置的不同, 变量可分为局部变量、形式参数和全程变量。从空间角度来看,变量可以分为全局变量和局部变量,而从时间角度来分的 可以有静态存储变量和动态存储变量之分。
2.malloc的底层实现
解析:回顾进程的空间模型,如图2-1所示,

图2-1进程空间示意图
与1.1.5节的图相比,多了一个program break指针,Linux维护一个break指针,这个指针指向堆空间的某个地址。从堆起始地址到break之间的地址空间为映射好的,可以供进程访问;而从break往上,是未映射的地址空间,如果访问这段空间则程序会报错。我们用malloc进行内存分配就是从break往上进行的。

图2-2堆内部机制
获取了break地址,也就是内存申请的初始地址,下面是malloc的整体实现方案:
malloc函数的实质是它有一个将可用的内存块连接为一个长长的列表的所谓空闲链表。 调用malloc()函数时,它沿着连接表寻找一个大到足以满足用户请求所需要的内存块。 然后,将该内存块一分为二(一块的大小与用户申请的大小相等,另一块的大小就是剩下来的字节)。 接下来,将分配给用户的那块内存存储区域传给用户,并将剩下的那块(如果有的话)返回到连接表上。 调用free函数时,它将用户释放的内存块连接到空闲链表上。 到最后,空闲链会被切成很多的小内存片段,如果这时用户申请一个大的内存片段, 那么空闲链表上可能没有可以满足用户要求的片段了。于是,malloc()函数请求延时,并开始在空闲链表上检查各内存片段,对它们进行内存整理,将相邻的小空闲块合并成较大的内存块。
3. extern”C” 的作用
解析:
我们可以在C++中使用C的已编译好的函数模块,这时候就需要用到extern”C”。这是为了避免C++ name mangling,主要用于动态链接库,使得在C++里导出函数名称与C语言规则一致(不改变),方便不同的编译器甚至是不同的开发语言调用。
那么我们来看看C++语言规则和C语言规则有何不同。如果我们定义一个函数:
int fun(int a);
如果是C++编译器,则可能将此函数改名为int_fun_int,(C++重载机制就这么来的)。如果有加上extern”C修饰,则c++编译器会按照C语言编译器一样编译为_fun。
**答:**extern”C”的作用在于C++代码中调用的C函数的声明,或C++中编译的函数要在C中调用。
注意:
1)C++调用一个C语言编写的.so库时,包含描述.so库中函数的头文件时,应该将对应的头文件放置在extern “C”{}格式的{}中,。
2)C中引用C++中的全局函数时,C++的头文件需要加extern “C”,而C文件中不能用extern “C”,只能使用extern关键字。
3)也就是extern“C” 都是在c++文件里添加的!
三. Unix环境高级编程
3.1 标准IO
打开关闭: fopen() fclose()读写: fgetc() 字符 fputc() fgets() 字符串 fputs() fread() fwrite()输入输出: printf() scanf()文件指针定位: fseek() ftell() rewind()流: fflush()
(1) fopen
读写权限:

而且在posix标准下的文件读写可以忽略读写权限的"b",即二进制流,在linux下不需指定。
perror()函数原型:可以关联全局变量errno打印错误输出信息

strerror()函数原型:返回错误好对应的字符串描述
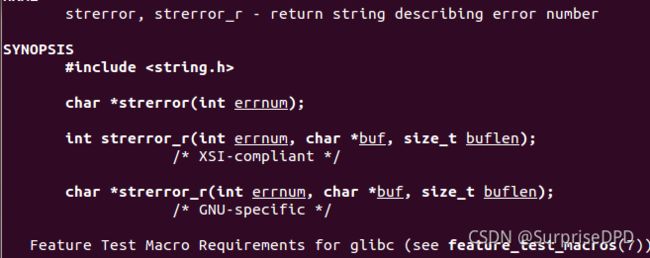
#include (2) fgetc和fputc
编写拷贝文件函数:
钩子函数则是用来解决前面资源正确打开,而后面的某个地方出错了,则必须关闭前的资源时处理很繁琐,因此,可以利用钩子函数处理。
#include \n",argv[0]);//如果输入错误,则提示实际应当输入的格式 exit(1);//如果出错则异常退出 } FILE* fps=fopen(argv[1],"r"); if(fps==NULL) { perror("fopen argv[1] falied,"); exit(1); } FILE* fpd=fopen(argv[2],"w"); if(fpd==NULL) { fclose(fps);//如果前面没错,但是这里出错了,则也应该关闭前面打开的资源。、 //钩子函数则是用来解决此类问题的 perror("fopen argv[2] falied,"); exit(1); } int ch; while(1) { ch= fgetc(fps); if(ch==EOF) { break; } fputc(ch,fpd); } fclose(fpd); fclose(fps); return 0;}
(3) fgets和gets
gets有Bug,不检查缓冲区溢出,应该用fgets
fgets( const char* ,size, stream):行缓冲模式,两种情况读结束:1>读到size -1个字符,最后一个字符存放字符串结束标志’\0’;2>读到换行符‘\n’。
上述拷贝文件的程序修改如下:
int ch;/* while(1) { ch= fgetc(fps); if(ch==EOF) { break; } fputc(ch,fpd); }*/ char buf[BUFSIZE]; while(fgets(buf,BUFSIZE,fps)!=NULL) { fputs(buf,fpd); }
(4) fread和fwrite
按对象大小读写,如果文件中出现不够一个对象大小,则读写返回0,即读写失败。
最好是每次都只读一个对象的大小,而不是几个对象一起读写。
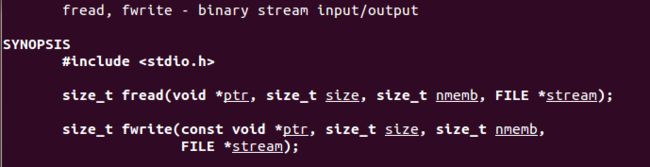
拷贝文件程序修改如下:

(5) printf函数族
-
printf(格式,输出变量)
-
int sprintf(char* shr,const char* format,…)某一特定格式化输出,例如: 年-月-日

输出为 2014-5-13 -
int snprintf(char* str,size_t size,const char* format,…);
防止sprintf内存溢出
(6)scanf函数族
慎用%s格式,因为不知道输入的长度是多少

(7)文件指针定位函数
fseek和ftell定位的文件大小不能 超过2G大小,因为偏移量为long类型,但是在不同位数计算机又不同

将offset的类型重定义为一个off_t类型:

下文有:
On some architectures, both off_t and long are 32-bit types, but defining _FILE_OFFSET_BITS with the value 64 (before including any header files) will turn off_t into a 64-bit type.或 #define _FILE_OFFSET_BITS 64
将off_t类型设置为64位的方法:(1)在引入任何头文件之前定义(2)在编译时添加:gcc a.c -o a -D_FILE_OFFSET_BITS=64(3)在makefile里添加:EFLAGS+=-D_FILE_OFFSET_BITS=64,然后直接make a。
(8) fflush
强制冲洗所有打开的流
(9)getline

#include \n" ,argv[0]); exit(1); } FILE* fp=fopen(argv[1],"r"); if(fp==NULL) { perror("fopen falied"); exit(1); } size_t linesize=0; while(1) { if(getline(&linebuf,&linesize,fp)<0) break; printf("%ld\n",strlen(linebuf)); } return 0;}
(10) 临时文件
tmpnam和tmpfile,使用场景,将临时数据保存到临时文件中
考虑两个问题:1.如何不冲突,2.未及时销毁
char * tmpnam(char* s):为临时文件创建一个可用名字;
FILE* tmpfile(void) :创建一个匿名临时文件;以二进制读写打开
(11)dup和dup2
dup和dup2都可用来复制一个现存的文件描述符,使两个文件描述符指向同一个file结构体。如果两个文件描述符指向同一个file结构体,File Status Flag和读写位置只保存一份在file结构体中,并且file结构体的引用计数是2。如果两次open同一文件得到两个文件描述符,则每个描述符对应一个不同的file结构体,可以有不同的File Status Flag和读写位置。请注意区分这两种情况。
#include 如果调用成功,这两个函数都返回新分配或指定的文件描述符,如果出错则返回-1。dup返回的新文件描述符一定该进程未使用的最小文件描述符,这一点和open类似。dup2可以用newfd参数指定新描述符的数值。如果newfd当前已经打开,则先将其关闭再做dup2操作,如果oldfd等于newfd,则dup2直接返回newfd而不用先关闭newfd再复制。
下面这个例子演示了dup和dup2函数的用法,请结合后面的连环画理解程序的执行过程。
/*实现:分别向文件和终端分别输出this is a test*/#include <unistd.h>#include <sys/stat.h> #include <fcntl.h> #include <stdio.h> #include <stdlib.h> #include <string.h> int main(void) { int fd, save_fd; char msg[] = "This is a test\n"; fd = open("somefile", O_RDWR|O_CREAT, S_IRUSR|S_IWUSR); //打开一个somefile文件,fd引用 if(fd<0) { perror("open"); exit(1); } save_fd = dup(STDOUT_FILENO); //save_fd也和STDOUT_FILENO共享输出终端 dup2(fd, STDOUT_FILENO);//先关闭STDOUT_FILENO对输出终端的引用,然后STDOUT_FILENO指向fd的文件 close(fd);//关闭一个对文件引用的fd write(STDOUT_FILENO, msg, strlen(msg)); //向文件写 dup2(save_fd, STDOUT_FILENO); //将STDOUT_FILENO指向的文件关闭,然后将它指向终端。 write(STDOUT_FILENO, msg, strlen(msg)); //向终端写 close(save_fd); //关闭指向终端的save_fd return 0; }

重点解释两个地方:
第3幅图,要执行dup2(fd, 1);,文件描述符1原本指向tty,现在要指向新的文件somefile,就把原来的关闭了,但是tty这个文件原本有两个引用计数,还有文件描述符save_fd也指向它,所以只是将引用计数减1,并不真的关闭文件。
第5幅图,要执行dup2(save_fd, 1);,文件描述符1原本指向somefile,现在要指向新的文件tty,就把原来的关闭了,somefile原本只有一个引用计数,所以这次减到0,是真的关闭了。
3.2 文件IO或系统调用io
文件IO和标准IO不要混用,因为可能文件指针位置不同
编程实现:删除一个文件的第十行
3.3 文件系统
(1)获取文件属性
stat ,fstat , lstat
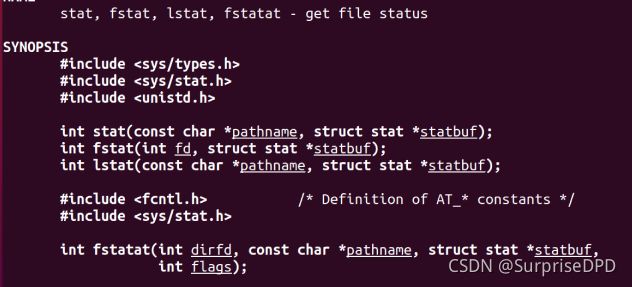
stat函数获得pathname文件的属性放到statbuf结构体中,结构体如下:
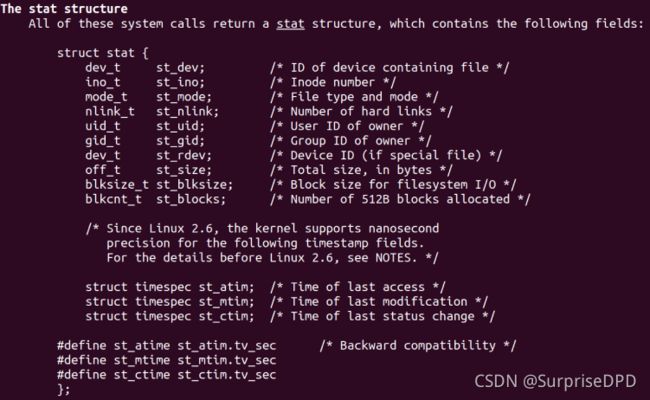
空洞文件不一定会占据文件大小个字节,文件系统会判断如果全是空字节的文件会压缩他实际占用的block块。
(2) 文件访问权限
st_mode是一个16位的位图,用于表示文件类型,文件访问权限,即特殊权限
(3)umask
作用:防止产生权限过松的权限
通常umask=000或0002或0022
实际权限= mode&~umask
(4)文件权限更改和管理
chomd和fchmod,fchmod是针对fd的
(5) 黏着位
t位,
#ls -dl /tmp
drwxrwxrwt 4 root root …
注意other位置的t,这便是粘连位。
当一个目录设置为粘着位时,它将发挥特殊的作用,
即当一个目录被设置为"粘着位"(用chmod a+t),则该目录下的文件只能由
1)、超级管理员删除
2)、该目录的所有者删除
3)、该文件的所有者删除
也就是说,即便该目录是任何人都可以写,但也只有文件的属主才可以删除文件。
(6)文件系统
文件或数据的存储和管理系统。
UFS系统:
UFS 文件系统的柱面组结构
创建 UFS 文件系统时,磁盘片被分成若干个柱面组。柱面组由一个或多个连续的磁盘柱面组成。柱面组又进一步分成若干个可寻址的块,以控制和组织柱面组中文件的结构。在文件系统中,每种类型的块都具有特定的功能。UFS 文件系统具有以下四种类型的块。
| 块类型 | 所存储信息的类型 |
|---|---|
| 引导块 | 在引导系统时使用的信息 |
| 超级块 | 有关文件系统的详细信息 |
| Inode | 有关文件的所有信息 |
| 存储块或数据块 | 每个文件的数据 |
引导块
引导块存储在引导系统时使用的对象。如果文件系统不用于引导,则将引导块保留为空。引导块仅出现在第一个柱面组(柱面组 0)中,它是片中的前 8 KB。
超级块
超级块存储有关文件系统的大多数信息,其中包括:
- 文件系统的大小和状态
- 标号,包括文件系统名称和卷名称
- 文件系统逻辑块的大小
- 上次更新的日期和时间
- 柱面组的大小
- 柱面组中的数据块数
- 摘要数据块
- 文件系统状态
- 最后一个挂载点的路径名
由于超级块包含关键数据,因此在创建文件系统时建立了多个超级块。
摘要信息块保留在超级块内。不复制摘要信息块,而是将其与主超级块组合在一起(通常在柱面组 0 中)。摘要块记录在使用文件系统时发生的更改。此外,摘要块列出文件系统中的 inode、目录、段和存储块的数目。
Inode
inode 包含有关文件的所有信息,但文件的名称(保存在目录中)除外。一个 inode 为 128 字节。inode 信息保存在柱面信息块中,它包含以下内容:
- 文件类型:
- 常规
- 目录
- 块特殊
- 字符特殊
- FIFO,也称为命名管道
- 符号链接
- 套接字
- 其他 inode-属性目录和阴影(用于 ACL)
- 文件的模式(读-写-执行权限集)
- 指向文件的硬链接数
- 文件属主的用户 ID
- 文件所属的组 ID
- 文件中的字节数
- 包含 15 个磁盘块地址的数组
- 上次访问文件的日期和时间
- 上次修改文件的日期和时间
- 更改 inode 的日期和时间
包含 15 个磁盘块地址(0 到 14)的数组指向存储文件内容的数据块。前 12 个地址是直接地址。即,它们直接指向文件内容的前 12 个逻辑存储块。如果文件大于 12 个逻辑块,则第 13 个地址指向间接块,该块包含直接块地址而不是文件内容。第 14 个地址指向双重间接块,该块包含间接块的地址。第 15 个地址用于三重间接地址。下图描述从 inode 开始这些地址块之间的关系链。图 23–1 UFS 文件系统的地址链

数据块
数据块也称为存储块,它包含为文件系统分配的其余空间。这些数据块的大小是在创建文件系统时确定的。缺省情况下,为数据块分配以下两种大小:8 KB 的逻辑块大小和 1 KB 的段大小 (fragment size)。
对于常规文件,数据块包含文件的内容。对于目录,数据块包含提供目录中文件的 inode 编号和文件名的项。
空闲块
在柱面组图中,当前未用作 inode、间接地址块或存储块的块被标记为空闲。此图还跟踪段以防止段化降低磁盘的性能。
为使您了解典型的 UFS 文件系统结构,下图说明普通 UFS 文件系统中的一系列柱面组。图 23–2 典型的 UFS 文件系统

(7)硬链接和符号链接
硬链接是目录项的同义词,建立硬链接有限制,不能给分区建立,不能给目录建立。符号链接有点:可以跨分区,,可以给目录建立。
unlink, rename改名, remove
(8)utime
utime可以更改文件的atime和mtime。

(9) 目录的创建和销毁
mkdir和rmdir ,rmdir只能删除空目录。
(10)更改当前工作路径
chdir
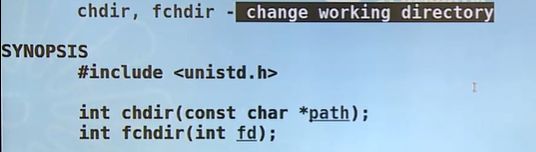
fchdir,getcwd
(11)分析目录和读取目录内容
glob();可以实现以下所有的
opendir,closedir,readdir, rewinddir,seekdir,
- glob 分析目录,包括模式匹配方式,(解析模式或通配符)
#include 
- opendir();参数是文件名,返回指向目录的指针
- readdir(dirp); dirp是指向一个目录的指针


//实现读取一个目录下的所有文件
#include - du 命令可以分析出给定的目录所占磁盘空间的大小
#include " ,argv[0]);
exit(1);
}
printf("%ld, %s \n",du(argv[1])/2,argv[1]);
return 0;
}
3.4 系统数据文件
- /etc/passwd : getpwuid() getpwnam()
#include -
/etc/group : getgrnam() getgrgid()
-
/etc/shadow root权限
crypt() 密码和数据加密
getpass() 从终端获得一个密码,关闭终端回显功能
getspnam()
crypt()是密码加密功能。 它基于数据加密标准(除其他事项外)旨在阻止使用硬件实现的算法关键搜索提示。key是用户输入的密码。salt是从[a-zA-Z0-9./]集中选择的两个字符的字符串。 该字符串用于以4096种不同方式之一扰乱算法。
//密码校验程序
#include - 时间函数:
time_t time(time_t *t );获得一个以秒计数的函数
用法: time_t stamp;定义一个time_t变量
time(&stamp); 将时间值返回到stamp中
stamp=*time(NULL);将时间作为返回值返回到stamp中
struct tm* gmtime(const time_t* timep);
struct tm* localtime(const time_t* timep);
用法: tm=localtime();
struct tm* localtime_r(const time_t* timep,struct tm* result);
time_t mktime(struct tm* );
strftime(); //format date and time
用法: strftime(buf,BUFSIZE,"%Y-%m-%d",tm);
//在外文件中格式化打印当前时间,
#include 3.5 进程环境
(1)main
int main(int argc,char* argv)
(2)进程的终止
-
正常终止:
从main返回
调用exit(库函数)
调用_exit 或 _EXIT(系统调用)
最后一个线程从其启动例程返回
最后一个线程调用pthread_exit
-
异常终止:
调用abort
收到一个信号并终止
最后一个线程对其取消请求作出响应
a. exit()
在exit调用之后,会调用钩子函数:atexit(void (*function)(void ))或on_exit,atexit注册调用exit之后要做的事情。
(3)命令行参数分析
getopt() 和getopt_long
(4) 跳转函数setjmp和longjmp
在 介绍信号的时候,我们看到多个地方要求进程在检查收到信号后,从原来的系统调用中直接返回,而不是等到该调用完成。这种进程突然改变其上下文的情况,就是 使用setjmp和longjmp的结果。setjmp将保存的上下文存入用户区,并继续在旧的上下文中执行。这就是说,进程执行一个系统调用,当因为资 源或其他原因要去睡眠时,内核为进程作了一次setjmp,如果在睡眠中被信号唤醒,进程不能再进入睡眠时,内核为进程调用longjmp,该操作是内核 为进程将原先setjmp调用保存在进程用户区的上下文恢复成现在的上下文,这样就使得进程可以恢复待资源前的状态,而且内核为setjmp返回1,使 得进程知道该次系统调用失败。这就是它们的作用。
int setjmp()设置一个跳转点,
void longjmp()跳转
(5)fork的父子进程区别
父子进程不同点:
pid 不同
进程ppid不同
父子进程返回不同
父进程用的资源会在子进程清零
父进程信号掩码不继承
父进程的文件锁子进程不继承
3.6 守护进程
一个守护进程的父进程是init进程,因为它真正的父进程在fork出子进程后就先于子进程exit退出了,所以它是一个由init继承的孤儿进程。守护进程是非交互式程序,没有控制终端,所以任何输出,无论是向标准输出设备stdout还是标准出错设备stderr的输出都需要特殊处理。
守护进程的名称通常以d结尾,比如sshd、xinetd、crond等
创建守护进程步骤
首先我们要了解一些基本概念:
进程组 :
- 每个进程也属于一个进程组
- 每个进程主都有一个进程组号,该号等于该进程组组长的PID号 .
- 一个进程只能为它自己或子进程设置进程组ID号
会话期:
会话期(session)是一个或多个进程组的集合。
setsid()函数可以建立一个对话期:
如果,调用setsid的进程不是一个进程组的组长,此函数创建一个新的会话期。
(1)此进程变成该对话期的首进程
(2)此进程变成一个新进程组的组长进程。
(3)此进程没有控制终端,如果在调用setsid前,该进程有控制终端,那么与该终端的联系被解除。 如果该进程是一个进程组的组长,此函数返回错误。
(4)为了保证这一点,我们先调用fork()然后exit(),此时只有子进程在运行
现在我们来给出创建守护进程所需步骤:
编写守护进程的一般步骤步骤:
(1)在父进程中执行fork并exit推出;
(2)在子进程中调用setsid函数创建新的会话;
(3)在子进程中调用chdir函数,让根目录 ”/” 成为子进程的工作目录;
(4)在子进程中调用umask函数,设置进程的umask为0;
(5)在子进程中关闭任何不需要的文件描述符,
(6)通常将终端都重定向到/dev/null下,例如文件描述符0,1,2
说明:
\1. 在后台运行。
为避免挂起控制终端将Daemon放入后台执行。方法是在进程中调用fork使父进程终止,让Daemon在子进程中后台执行。
if(pid=fork())
exit(0);//是父进程,结束父进程,子进程继续
\2. 脱离控制终端,登录会话和进程组
有必要先介绍一下Linux中的进程与控制终端,登录会话和进程组之间的关系:进程属于一个进程组,进程组号(GID)就是进程组长的进程号(PID)。登录会话可以包含多个进程组。这些进程组共享一个控制终端。这个控制终端通常是创建进程的登录终端。
控制终端,登录会话和进程组通常是从父进程继承下来的。我们的目的就是要摆脱它们,使之不受它们的影响。方法是在第1点的基础上,调用setsid()使进程成为会话组长:
setsid();
说明:当进程是会话组长时setsid()调用失败。但第一点已经保证进程不是会话组长。setsid()调用成功后,进程成为新的会话组长和新的进程组长,并与原来的登录会话和进程组脱离。由于会话过程对控制终端的独占性,进程同时与控制终端脱离。
\3. 禁止进程重新打开控制终端
现在,进程已经成为无终端的会话组长。但它可以重新申请打开一个控制终端。可以通过使进程不再成为会话组长来禁止进程重新打开控制终端:
if(pid=fork())
exit(0);//结束第一子进程,第二子进程继续(第二子进程不再是会话组长)
\4. 关闭打开的文件描述符
进程从创建它的父进程那里继承了打开的文件描述符。如不关闭,将会浪费系统资源,造成进程所在的文件系统无法卸下以及引起无法预料的错误。按如下方法关闭它们:
for(i=0;i 关闭打开的文件描述符close(i);>
\5. 改变当前工作目录
进程活动时,其工作目录所在的文件系统不能卸下。一般需要将工作目录改变到根目录。对于需要转储核心,写运行日志的进程将工作目录改变到特定目录如/tmpchdir(“/”)
\6. 重设文件创建掩模
进程从创建它的父进程那里继承了文件创建掩模。它可能修改守护进程所创建的文件的存取位。为防止这一点,将文件创建掩模清除:umask(0);
\7. 处理SIGCHLD信号
处理SIGCHLD信号并不是必须的。但对于某些进程,特别是服务器进程往往在请求到来时生成子进程处理请求。如果父进程不等待子进程结束,子进程将成为僵尸进程(zombie)从而占用系统资源。如果父进程等待子进程结束,将增加父进程的负担,影响服务器进程的并发性能。在Linux下可以简单地将SIGCHLD信号的操作设为SIG_IGN。
signal(SIGCHLD,SIG_IGN);
这样,内核在子进程结束时不会产生僵尸进程。这一点与BSD4不同,BSD4下必须显式等待子进程结束才能释放僵尸进程。
3.7 信号
“信号”的响应总结为一句话:应用态进程由于系统调用、中断或异常,而陷入内核态后,在返回应用态之前,内核会进行信号的检查和处理。
一个进程原先设置要捕捉的信号,当其执行exec一个新程序后,就不能再捕捉了,因为信号捕捉函数的地址很可能在所执行的新程序文件中无意义。
pcb中有mask和pending 两个set来管理信号,mask可以自定义设置,用来阻塞信号。
查看所有信号的命令:kill -l
(1) Kill
int kill(pid_t pid,int sig);//发送一个信号给一个进程或进程组
pid>0 则信号sig是发给某个进程的;
pid=0 则信号是发送给当前所在进程组的每个进程;
pid=-1 则信号是全局广播信号,发送给所有的进程,除了Init进程;
pid<-1 则发送给进程组id为-pid的所有进程;
sig=0 则没有信号发送但是有错误值修改,用于检测一个进程或者一个进程组是否存在。
返回值: 0成功,-1失败,and errno is set
(2) raise
int raise(int sig);//给调用进程或线程发送一个信号,等价于kill(getpid(),sig)
(3)alarm
unigned int alarm (unsigned int seconds);//设置用于传递SIGALRM信号给调用进程一个程序有多个alarm则最后一个有用,其他失效
//利用信号延时5秒,
#include 
左图为优化后的代码,陷入死循环,解决方法是,将loop定义成volatile
(4)pause
int pause(void); // wait for a signal
(5)sigprocmask
int sigprocmask(int how ,const sigset_t * set,sigset_t * oldset);
how: SIG_BLOCK ,SIG_UNBLOCK,SIG_SETMASK
set: 要修改的信号集mask
oldset: 之前的信号集mask
#include (6)不可重入函数
特征: a.已知他们使用了静态数据结构;b.他们调用了malloc或free;c.他们是标准IO函数.
标准IO库的很多实现都以不可重入方式使用全局数据结构。
P263程序结论:在信号处理程序中调用不可重入函数的结果是不可预知的。
(7)signal函数
在每次注册一个信号后,当信号产生后,进入信号处理程序会将该信号设置为默认值,如果不在信号处理程序中重新注册则这个信号只响应一次。
(8)sigaction
3.8 计时器

这些系统调用提供一种获取计时器的方式,这个计时器会在未来到期并定期到期。当一个时钟到期时,会产生一个信号,并且计时器被重置为具体的计时间隔。有三种计时方式(which参数指定),每种方式依赖的时钟不同,产生的信号也不同。
ITIMER_REAL This timer counts down in real (i.e., wall clock)time. At each
expiration, a SIGALRM signal is generated.(按实时时间递减)
ITIMER_VIRTUAL At each expiration, a SIGVTALRM signal is generated.(按用户cpu时间递减)
ITIMER_PROF At each expiration, a SIG‐PROF signal is generated.(按用户和系统cpu时间递减)
Timer values are defined by the following structures:
struct itimerval {
struct timeval it_interval; /* Interval for periodic timer */(每个计时周期)
struct timeval it_value; /* Time until next expiration */(下个计时周期)
};每个计时周期it_interval会赋值给it_value,
struct timeval {
time_t tv_sec; /* seconds */
suseconds_t tv_usec; /* microseconds */
};
这两个函数误差不累积
最重要的特点是:如果设置it_value=10,it_interval=1,则这个计时器会在10秒后启动,将it_interval值付给it_value之后则按每秒一次地计时。
如果设置it_value=1,it_interval=1则是周期地每秒计时。
(1)getitimer
获得一个间隔计时器的值.
函数getitimer()将指定的计时器的当前值放置在curr_value所指向的缓冲区中。在it_value子结构中填充直到指定计时器的下一次到期为止的剩余时间量。 这个值随着计时器的倒数而变化,并将重置为定时器到期时的it_interval。 如果it_value的两个字段都为零,则该计时器当前处于撤防状态(无效)。
it_interval子结构填充有计时器间隔。如果it_interval的两个字段均为零,则为单发计时器(即,它只过期一次)。
(2)setitimer
设置一个间隔计时器的值
函数setitimer()启用或撤消由以下命令指定的计时器通过将计时器设置为new_value指定的值。 如果old_value为非NULL,它指向的缓冲区用于返回计时器的先前值(即与由getitimer()返回结果相同)。如果new_value.it_value中的任何一个字段都不为零,则计时器为最初在指定时间到期。 如果两个字段都在
new_value.it_value为零,则撤防计时器。new_value.it_interval字段指定了新的间隔计时器 如果其两个子字段均为零,则计时器为单触发。
#include 使用gcc 编译,就会正常每隔一秒计时一次
3.9 线程
(1)创建线程
NAME
pthread_create - create a new thread
SYNOPSIS
#include (2)线程终止和取消
从启动例程返回,返回值为线程的退出码
被同一进程 的其他线程取消
调用pthread_exit
int pthread_join(pthread_t thread,void **retval);
栈清理:
pthread_cleanup_push(void (*routine)(void *))//类似钩子函数pthread_cleanup_pop(int execute);
线程取消:
pthread_cancel();//应用场景,例如:多线程查找一个数组,每个线程一部分,当一个线程找到了,那么则可以取消掉其他线程了。
pthread_setcancelstate();设置是否允许取消
pthread_setcanceltype();设置取消方式
pthread_testcancel();只是一个取消计算
取消有两种状态:允许和不允许
允许分:异步cancel,推迟cancel(默认)->推迟到cancel点响应。例如posix定义的cancel都是可能引发阻塞的系统调用
线程分离:
pthread_detach(pthread_t thread);//之后不能被召回该线程
(3)重入
3.10 高级IO
(1)非阻塞IO
(2)内存映射
将一个磁盘文件映射到内存中的某块缓冲区中,这块读写这个char*的缓冲区则就相当于读写这个文件。
void* mmap();
munmap();
#include(3)文件锁
fcntllockf
3.11 网络编程
(1)socket
int socket(int domain,int type,int protocol);
domain:协议族,ipv4,ipv6
type:数据类型,流式,报文式
protocol:
timerfd+epoll使用
#include