使用 PAI-Blade 优化 Stable Diffusion 推理流程(二)
背景
上一篇中,我们使用了 PAI-Blade 优化了 diffusers 中 Stable Diffusion 模型。本篇,我们继续介绍使用 PAI-Blade 优化 LoRA 和 Controlnet 的推理流程。相关优化已经同样在 registry.cn-beijing.aliyuncs.com/blade_demo/blade_diffusion镜像中可以直接使用。同时,我们将介绍 Stable-Diffusion-webui 中集成 PAI-Blade 优化的方法。
LoRA优化
PAI-Blade优化LoRA的方式,与前文方法基本相同。包括:加载模型、优化模型、替换原始模型。以下仅介绍与前文不同的部分。
首先,加载Stable DIffusion模型后,需要加载LoRA权重。
pipe.unet.load_attn_procs("lora/")
使用LoRA时,用户可能需要切换不同的LoRA权重,尝试不同的风格。因此,PAI-Blade需要在优化配置中,传入freeze_module=False,使得优化过程中,不对权重进行编译优化,从而不影响模型加载权重的功能。通过这种方式,PAI-Blade优化后的模型,依然可以使用pipe.unet.load_attn_procs()方式加载LoRA的权重,而不需要重新编译优化。
由于模型权重未进行优化流程,一些对常量的优化无法进行,因此会损失部分优化空间。为了解决性能受损的问题,PAI-Blade中,使用了部分patch,对原始模型进行python层级的替换,使得模型更适合PAI-Blade优化。通过在优化前,使用 torch_blade.monkey_patch优化 Stable Diffusion 模型中的 unet和vae部分,能更好的发挥PAI-Blade能力。
from torch_blade.monkey_patch import patch_utils
patch_utils.patch_conv2d(pipe.vae.decoder)
patch_utils.patch_conv2d(pipe.unet)
opt_cfg = torch_blade.Config()
...
opt_cfg.freeze_module = False
with opt_cfg, torch.no_grad():
...如果没有LoRA权重切换的需求,可以忽略上述步骤,获得更快的推理速度。
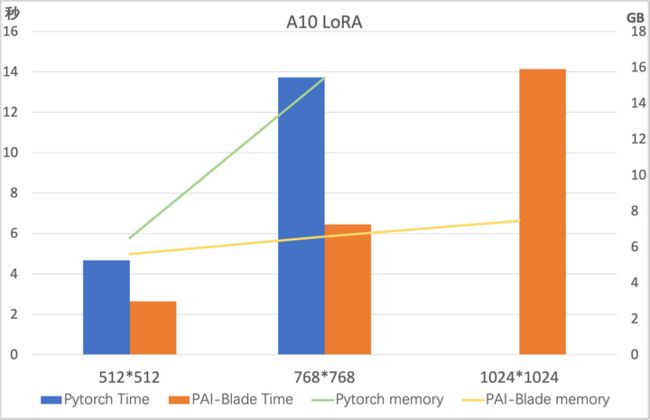
Benchmark
我们在A100/A10上测试了上述对LoRA优化的结果,测试模型为 runwayml/stable-diffusion-v1-5,测试采样步数为50。

ControlNet适配
根据 ControlNet 的模型结构图以及diffusers中ControlNet实现,可以将ControlNet的推理分为两部分。

- ControlNet部分,其input blocks和 mid block 结构与Stable DiffusionUnet的前半部分相同,剩余部分为卷积。ControlNet所有输出传入到Stable DIffusion的Unet中,作为输入;
- Stable Diffusion 的Unet除了原始输入外,额外增加了ControlNet的输出作为输入。
根据上述特点,我们可以做出以下的优化:
首先,优化ControlNet,
controlnet = torch_blade.optimize(pipe.controlnet, model_inputs=tuple(controlnet_inputs), allow_tracing=True)在优化unet模型时,由于torch2.0之前的版本,torch.jit.trace不支持使用dict作为输入,所以我们使用Wrapper包装Unet后便于trace和优化。同时,使用优化后的ControlNet执行一次推理,将其输出添加到Unet输入中。
class UnetWrapper(torch.nn.Module):
def __init__(self, unet):
super().__init__()
self.unet = unet
def forward(
self,
sample,
timestep,
encoder_hidden_states,
down_block_additional_residuals,
mid_block_additional_residual,
):
return self.unet(
sample,
timestep,
encoder_hidden_states=encoder_hidden_states,
down_block_additional_residuals=down_block_additional_residuals,
mid_block_additional_residual=mid_block_additional_residual,
)
...
down_block_res_samples, mid_block_res_sample = controlnet(*controlnet_inputs)
unet_inputs += [tuple(down_block_res_samples), mid_block_res_sample]
unet = torch_blade.optimize(UnetWrapper(pipe.unet).eval(), model_inputs=tuple(unet_inputs), allow_tracing=True)结合上述功能,可以同时实现:
- LoRA权重替换;
- ControlNet权重替换,来使用不同ControlNet model。
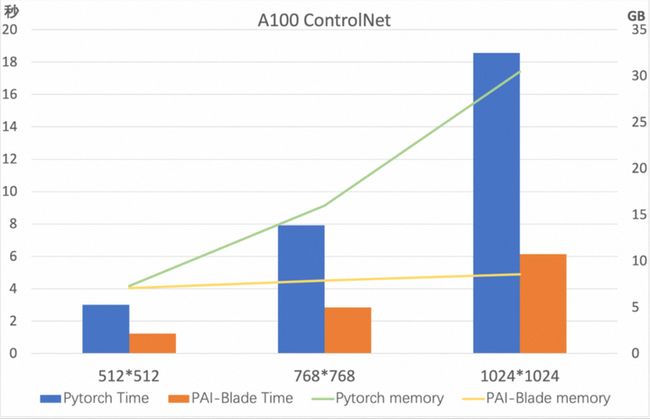
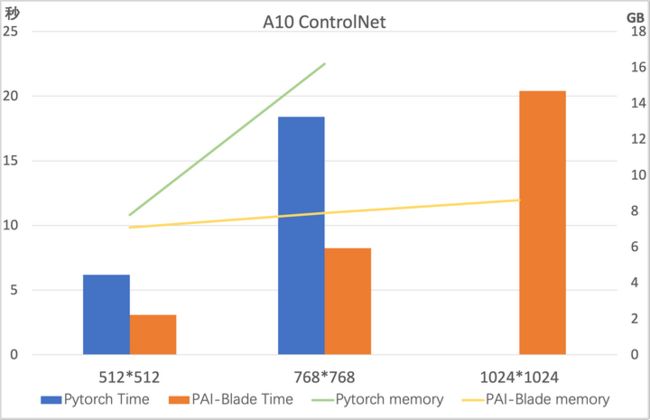
benchmark
我们在A100/A10上测试了上述对ControlNet优化的结果,测试模型为 runwayml/stable-diffusion-v1-5,测试采样步数为50。
小结
在上述部分,我们使用了PAI-Blade优化了Stable DIffusion模型的encoder、unet、decoder部分,大幅降低推理延时的同时,减少了显存占用,从而降低Stable DIffusion模型推理成本。同时,PAI-Blade支持了LoRA、ControlNet等常用功能,扩展了PAI-Blade的实用性。
webui适配
stable-diffusion-webui 是 Stable DIffusion非常热门的应用,PAI-Blade 同样提供了对其优化支持。目前,PAI-Blade已经支持了模型权重切换、LoRA、ControlNet等webui中常用的功能,同时通过 extension 的形式集成,可以便于用户使用。目前,相关优化已经集成到 PAI-EAS 的 eas-registry.cn-hangzhou.cr.aliyuncs.com/pai-eas/sdwebui-inference:0.0.2-py310-gpu-cu117-ubuntu2204-blade 镜像,可以通过PAI_EAS直接体验PAI-Blade的优化能力。
下面介绍该插件中,PAI-Blade在webui中优化方式和性能。webui优化原理与diffusers大致相同,以下是几个主要不同点:
分模块优化Unet和ControlNet
由于webui中,ControlNet需要逐个调用Unet的子模块,为了兼顾ControlNet,PAI-Blade并没有像diffusers中一样,优化整个Unet和ControlNet。而是采取逐个子模块优化的方法,将Unet、ControlNet中所有的down blocks、 mid block、up blocks分别进行优化和替换。经过测试,此种优化方式几乎不影响模型推理速度。
不冻结权重
webui的网页上,可以快捷的切换模型权重。因此,PAI-Blade采取和diffusers中LoRA优化同样的方法,不对权重进行优化。
LoRA优化
webui中,多个LoRA会逐个调用LoRA计算,计算时间随LoRA数量增多而变长。PAI-Blade 在加载LoRA权重时,将多个LoRA的权重与scale预先fuse,减少了运行时的开销。加载和fuse的开销,经测试可忽略不计。
Benchmark
我们在A10上测试了webui中,Stable DIffusion V1 模型在 batch size为1,分辨率为512*512条件下的推理速度。由于webui中涉及到网络传输等模型无关部分的延迟,因此本部分只测试了模型部分耗时。结果如下:
| steps |
eager |
xformers |
PAI-Blade |
|||||
| no LoRAs |
+ 2 LoRAs |
ControlNet |
no LoRAs |
+ 2 LoRAs |
ControlNet |
any LoRAs |
ControlNet |
|
| 20 |
2.03 |
2.94 |
2.75 |
1.57 |
2.46 |
2.14 |
1.15 |
1.62 |
| 50 |
4.77 |
7.17 |
6.64 |
3.63 |
5.86 |
5.06 |
2.59 |
3.75 |
| 100 |
9.45 |
14.18 |
13.13 |
7.10 |
11.54 |
9.90 |
4.96 |
7.35 |
由该表可知,webui在eager和xformers模式下,推理时间随LoRA数量增加而延长,而PAI-Blade将所有LoRA的权重融合到基础模型,所以推理时间与LoRA数量无关。
总结
这两篇文章中,我们介绍了PAI-Blade 在Stable DIffusion模型上的优化经验,目前已经支持了Diffusers和Stable-DIffusion-webui 两种主流推理方式。
我们调研了相关公开的竞品对Stable Diffusion的支持情况,结果如下:
| 框架/模型 | Base Model | LoRA | ControlNet | webui |
| xformers | ✅ | ✅ | ✅ | ✅ |
| AITemplete | ✅ | ❌ | ❌ | ❌ |
| OneFlow | ✅ | ✅ | ✅ | ❌ |
| TensorRT | ✅ | ❌ | ❌ | ❌ |
| PAI-Blade | ✅ | ✅ | ✅ | ✅ |
根据公开性能数字和业务实测,PAI-Blade对Stable DIffusion模型,不仅支持最为全面,同时性能和显存使用也是最佳水平。
原文链接
本文为阿里云原创内容,未经允许不得转载。