反爬虫的常见应对方法
反爬虫
反爬虫 是网站限制爬虫的一种策略。它并不是禁止爬虫(完全禁止爬虫几乎不可能,也可能误伤正常用户),而是限制爬虫,让爬虫在网站可接受的范围内爬取数据,不至于导致网站瘫痪无法运行。而且只要是爬虫获取的数据基本上都是用户可以看到的数据,所以理论上公网上的数据都可以通过爬虫来获取到,但是很多网站爬取的数据不可用来商用!
常见的反爬虫方式有判别身份和IP限制两种
判别身份
有些网站在识别出爬虫后,会拒绝爬虫的访问,比如豆瓣。我们以豆瓣图书 Top250 为例,如果用爬虫直接爬取它
import requests
res = requests.get('https://book.douban.com/top250')
print(res.text)
输出结果为空,什么都没有。这是因为豆瓣将我们的爬虫识别了出来并拒绝提供内容。
不管是浏览器还是爬虫,访问网站时都会带上一些信息用于身份识别。而这些信息都被存储在一个叫 请求头(request headers)的地方。
服务器会通过请求头里的信息来判别访问者的身份。请求头里的字段有很多,我们只需了解 user-agent(用户代理)即可。user-agent 里包含了操作系统、浏览器类型、版本等信息,通过修改它我们就能成功地伪装成浏览器。
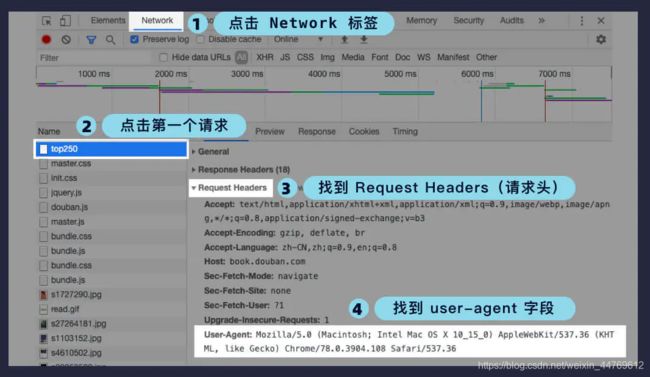
我们首先打开浏览器的开发者工具,然后按照图中的步骤,先点击 Network 标签(里面记录了所有网络请求),然后在左边的列表中找到第一个请求(如果请求太多需要往上翻),点击第一个请求后,在右边的详情中找到 Request Headers 里的 user-agent 字段即可。
因此我们需要修改请求头里的 user-agent 字段内容,将爬虫伪装成浏览器。我们只需定义一个 字典(请求头字段作为键,字段内容作为值)传递给 headers 参数即可。我们将刚刚找到的浏览器的 user-agent 复制粘贴到代码里:
import requests
# 从浏览器中复制粘贴的请求头
headers = {
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36'
}
res = requests.get('https://book.douban.com/top250', headers=headers)
print(res.text)
判别身份是最简单的一种反爬虫方式,我们也能通过一行代码,将爬虫伪装成浏览器轻易地绕过这个限制。所以,大部分网站还会进行 IP 限制 防止过于频繁的访问。
IP限制
当我们爬取大量数据时,如果我们不加以节制地访问目标网站,会使网站超负荷运转,一些个人小网站没什么反爬虫措施可能因此瘫痪。而大网站一般会限制你的访问频率,因为正常人是不会在 1s 内访问几十次甚至上百次网站的。
所以,如果访问过于频繁,即使改了 user-agent 伪装成浏览器了,也还是会被识别为爬虫,并限制你的 IP 访问该网站。
因此,我们常常使用 time.sleep() 来降低访问的频率,比如上一节中的爬取整个网站的代码,我们每爬取一个网页就暂停一秒。这样,对网站服务器的压力不会太大虽然速度较慢,但也能获取到我们想要的数据了。
除了降低访问频率之外,我们也可以使用代理来解决 IP 限制的问题。代理的意思是通过别的 IP 访问网站。这样,在 IP 被封后我们可以换一个 IP 继续爬取数据,或者每次爬取数据时都换不同的 IP,避免同一个 IP 访问的频率过高,这样就能快速地大规模爬取数据了。
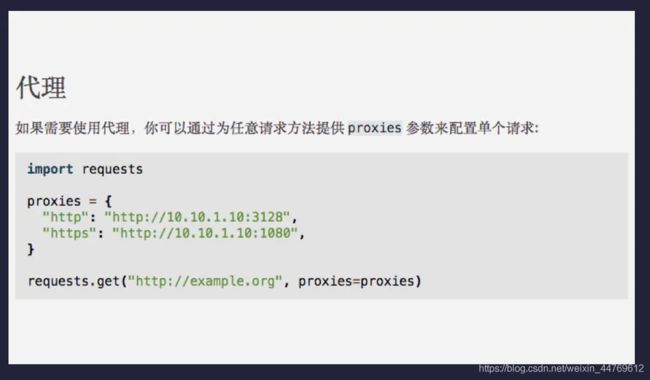
和 headers 一样,也是定义一个字典,但传递给的是 proxies 参数。我们需要将 http 和 https 这两种协议作为键,对应的 IP 代理作为值,最后将整个字典作为 proxies 参数传递给 requests.get() 方法即可。
官方文档中给了代理的基本用法,但在爬取大量数据时我们需要很多的 IP 用于切换。因此,我们需要建立一个 IP 代理池(列表),每次从中随机选择一个传给 proxies 参数。
import requests
import random
from bs4 import BeautifulSoup
def get_douban_books(url, proxies):
headers = {
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36'
}
# 使用代理爬取数据
res = requests.get(url, proxies=proxies, headers=headers)
soup = BeautifulSoup(res.text, 'html.parser')
items = soup.find_all('div', class_='pl2')
for i in items:
tag = i.find('a')
name = tag['title']
link = tag['href']
print(name, link)
url = 'https://book.douban.com/top250?start={}'
urls = [url.format(num * 25) for num in range(10)]
# IP 代理池(瞎写的并没有用)
proxies_list = [
{
"http": "http://10.10.1.10:3128",
"https": "http://10.10.1.10:1080",
},
{
"http": "http://10.10.1.11:3128",
"https": "http://10.10.1.11:1080",
},
{
"http": "http://10.10.1.12:3128",
"https": "http://10.10.1.12:1080",
}
]
for i in urls:
# 从 IP 代理池中随机选择一个
proxies = random.choice(proxies_list)
get_douban_books(i, proxies)
robots.txt
robots.txt 是一种存放于网站根目录下的文本文件,用于告诉爬虫此网站中的哪些内容是不应被爬取的,哪些是可以被爬取的。
我们只要在网站域名后加上 /robots.txt 即可查看,比如豆瓣读书的 robots.txt 地址是:https://book.douban.com/robots.txt。打开它后的内容如下:

- User-agent: * 表示针对所有爬虫(* 是通配符),接下来是符合该 user-agent 的爬虫要遵守的规则。比如Disallow: /search 表示禁止爬取 /search 这个页面,其他同理。
- robots.txt 也能针对某一个爬虫限制,比如最后的 User-agent: Wandoujia Spider 表示针对Wandoujia Spider 这个爬虫,Disallow: / 表示禁止整个网站的爬取。
- 但是robots.txt只是一个君子协议,网站只是告诉大家哪些页面禁止爬取数据,并不能阻止你去爬取。即便如此,我们还是应该遵守规则,下次在爬取网站时,记得先打开该网站的robots.txt 查看哪些页面可以爬取数据,哪些页面禁止爬取数据。
转载自网络部黄铮同学