day02_python快速入门
day02_快速入门
-
- 1. 编码
- 2. 编程初体验
- 3. 类型转换
- 4. 变量
-
- 4.1 变量名的规范
- 4.2 变量内存指向关系
- 5. 今日练习
1. 编码
当我们在电脑上输入一段话,并保存到电脑中,在计算机中则会将中文内存转换为01010100100101...这样的形式,最终存储到硬盘上。
在计算机中有这么一个编码的概念(密码本)。
王 -> 01010100101 010
敏 -> 010010110 10101
...
在计算机中有很多种编码
每种编码都有自己的一套密码本,都维护着自己的一套规则,如:
utf-8编码:
王 -> 101010001(乱写的)
桂 -> 110101010(乱写的)
gbk编码:
王 -> 010101010(乱写的)
桂 -> 010100010(乱写的)
所以,使用不同的编码保存文件时,硬盘的文件中存储的0/1也是不同的
注意事项:以某个编码的形式进行保存文件,以后就要以这种编码去打开这个文件,否则就会出现乱码。
2. 编程初体验
编码必须要保持一致:保存和打开一致,否则会出现乱码- 默认Pyhton解释器是以UTF-8的形式打开文件的,如果想要修改Python的默认解释器编码,可以下面这样干:
# -*- coding:utf-8 -*-
print("我是你二大爷")
- 在
Pycharm中写完代码,如果不规范的话,可以点击上面的code->Reformat Code, 则软件会帮你自动规范化代码
3. 类型转换
int() str() bool()
三句话搞懂类型转换
- 其他所有类型转换为布尔类型时,除了
空字符串,0 以外,其他所有都为True。 - 字符串转整形时,只有那种’
988’格式(全为数字)的字符串才可以转换为整形,其他都报错 - 想要转化为某种类型,就用这种
类型的英文包裹一下就行。
sr(...)
int(...)
bool(...)
4. 变量
变量,其实就是我们生活中起的别名和外号,让变量名指向某个值,格式为:【变量名=值】,以后可以通过变量名来操作其对应的值。
name = '王不易'
print(name) # 王不易
flag = 1>18 # 意思是将,右边的'1>18'返回的结果赋值给flag,所以flag=False
address = '浙江省'+'宁波市' # 意思是先将右边的字符串进行拼接,然后返回给address 所以address = '浙江省宁波市'
number = 1 == 2 # 先看右边再看左边。number = False
4.1 变量名的规范
三个规范(只要有一条,就会报错)
- 变量名只能由
字母、数字、下划线组成。 - 不能以
数字为开头 - 不能使用
Python内置的关键词作为变量名- 如果不知道是否为内置关键词,也没有关系,当你在用内置关键词作为变量名的时候,Pycharm会给你报错

- 如果不知道是否为内置关键词,也没有关系,当你在用内置关键词作为变量名的时候,Pycharm会给你报错
三个建议:
- 下划线连接命名(小写)
# 很长的变量名,中间用_连接
farther_name = 'wangbuyi'
class_name = '计算机2101'
- 见名知意
# 让别人看见变量名就知道这是什么意思
age = 19
color = 'red'
name = 'wby'
- 驼峰
# 顾名思义,就是变量名中首字母大写
# 在程序中,要么选择下划线连接命名,要么驼峰命名,建议不要一起使用,容易混乱
StudentName = 'wby'
StudentAge = 18
4.2 变量内存指向关系
通过学习上述变量知识让我们对变量了有了初步认识,接下来我们就要从稍稍高级一些的角度来学习变量,即:内存指向(在电脑的内存中是怎么存储的)。
情景一
name = "wupeiqi"
在计算机的内存中创建一块区域保存字符串”wupeiqi”,name变量名则指向这块区域。
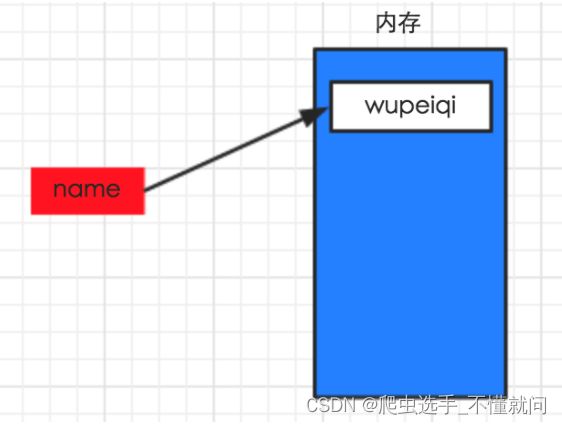
情景二
name = "wupeiqi"
name = "alex"
在计算机的内存中创建一块区域保存字符串”wupeiqi”,name变量名则指向这块区域。然后又再内存中创建了一块域保存字符串”alex”,name变量名则指向”alex”所在的区域,不再指向”wupeiqi”所在区域(无人指向的数据会被标记为垃圾,由解释器自动化回收)

情景三
name = "wupeiqi"
new_name = name
在计算机的内存中创建一块区域保存字符串”wupeiqi”,name变量名则指向这块区域。new_name变量名指向name变量,因为被指向的是变量名,所以自动会转指向到name变量代表的内存区域。

情景四
name = "wupeiqi"
new_name = name
name = "alex"
在计算机的内存中创建一块区域保存字符串”wupeiqi”,name变量名则指向这块区域(灰色线), 然后new_name指向name所指向的内存区域,最后又创建了一块区域存放”alex”,让name变量指向”alex”所在区域.

情景五
num = 18
age = str(num)
在计算机的内存中创建一块区域保存整型18,name变量名则指向这块区域。通过类型转换依据整型18再在内存中创建一个字符串”18”, age变量指向保存这个字符串的内存区域。

至此,关于变量的内存相关的说明已讲完,由于大家都是初学者,关于变量的内存管理目前只需了解以上知识点即可,更多关于内存管理、垃圾回收、驻留机制等问题在后面的课程中会讲解。
5. 今日练习
-
谈谈你了解的编码以及为什么会出现乱码的现象?
答:当编码形式不一样的时候就会出现乱码的情况编码相当于是一个`密码本`,其中存储着文字和01010的对应关系。 乱码的出现时因为文件的存储方式和打开方式不一致导致。另外,如何数据丢失也可能会造成乱码。 假如: 武,对应存储的是:100100001000000111。如果文件中的内容丢失只剩下100100001000000,则读取时候就可能出现乱码。 -
Python解释器默认编码是什么?如何修改?
# Python解释器默认编码是UTF-8 # -*- coding:gbk -*-Python解释器默认编码:utf-8 在文件的顶部通过设置: # -*- coding:编码 -*- 实现修改。 -
用print打印出下面内容:
⽂能提笔安天下, 武能上⻢定乾坤. ⼼存谋略何⼈胜, 古今英雄唯是君。text = """ ⽂能提笔安天下, 武能上⻢定乾坤. ⼼存谋略何⼈胜, 古今英雄唯是君。 """ print(text) -
变量名的命名规范和建议?
答: 命名规范: 1. 不能以数字为开头;2. 只能是数字,字母,下划线组成;3. 不能以Python默认的关键字为变量名 建议: 1. 使用下划线来分割很长的变量名 2. 必须让人一眼就知道这个变量是什么意思三条规范(必须遵循,否则定义变量会报错) - 变量名只能由 字母、数字、下划线 组成。 - 变量名不能以数字开头。 - 变量名不能是Python内置关键字 二条建议(遵循可以显得更加专业,不遵循也可以正常运行不报错) - 下划线命名法,多个单词表示的变量名用下划线连接(均小写) - 见名知意,通过阅读变量名就能知道此变量的含义。 -
如下那个变量名是正确的?
name = '武沛齐' _ = 'alex' _9 = "老男孩" 9name = "宝浪" oldboy(edu = 666T T T F F -
设定一个理想数字比如:66,让用户输入数字,如果比66大,则显示猜测的结果大了;如果比66小,则显示猜测的结果小了;只有等于66,显示猜测结果正确。
n = input('请输入数字:') if int(n) < 66: print('猜小了') elif int(n) > 66: print('猜大了') else: print('猜对了') -
提示⽤户输入 “爸爸” ,判断⽤户输入的对不对。如果对, 提示真聪明, 如果不对, 提示你是傻逼么。
n = input('请输入 "爸爸" :') if n != '爸爸': print('你是傻逼么?') else: print('真聪明') -
写程序,成绩有ABCDE5个等级,与分数的对应关系如下.
A 90-100 B 80-89 C 60-79 D 40-59 E 0-39要求用户输入0-100的数字后,你能正确打印他的对应成绩等级.
score = input("请输入分数") data = int(score) if data >= 90 and data <= 100: print("A") elif data >= 80 and data <90: print("B") elif data >= 60 and data <80: print("C") elif data >= 40 and data <60: print("D") elif data >= 0 and data <40: print("E") else: print("输入错误")score = input("请输入分数") data = int(score) if 90 <= data <= 100: print("A") elif 80 <= data < 90: print("B") elif 60 <= data < 80: print("C") elif 40 <= data < 60: print("D") elif 0 <= data < 40: print("E") else: print("输入错误")
n = input('请输入0-100的数字: ')
if int(n) >= 90:
print('A')
elif int(n) >= 80 and int(n) < 90:
print('B')
elif int(n) >= 60 and int(n) < 80:
print('C')
elif int(n) >= 40 and int(n) < 60:
print('D')
else:
print('E')