Linux 之八 完整嵌入式 Linux 环境及构建工具、(交叉)编译工具链、CPU 体系架构
最近,工作重心要从裸机开发转移到嵌入式 Linux 系统开发,由于之前对嵌入式 Linux 环境并不是很了解,因此,第一步就是需要了解如何搭建一个完整的嵌入式 Linux 环境。现在将学习心得记录为此文。
嵌入式 Linux 环境
嵌入式 Linux 环境与我们熟悉的 PC 环境还是有很大区别的,要搭建出一套完整的嵌入式 Linux 环境需要做的工作相当多。下图是我根据学习整理的一个嵌入式 Linux 环境示意图:

-
BootLoader:通常使用的是 U-Boot,就是一个复杂点的裸机程序。与我们通常编写的裸机程序(例如 ARM 架构)没有本质区别。BootLoader 需帮助内核实现重定位,BootLoader 还要给内核提供启动参数。
BootLoader 是无条件启动的,从零开始启动的。
-
Linux Kernel: 本身也是一个复杂的裸机程序。与裸机程序相比,内核运行起来后,在软件上分为内核层和应用层,分层后两层的权限不同,内存访问和设备操作的管理上更加精细(内核可以随便访问各种硬件,而应用程序只能被限制地访问硬件和内存地址)。
内核是不能开机自动完全从零开始启动的,需要 BootLoader 帮忙。
-
裸机程序编译工具链: 这个编译工具链(名字是我自己起的)编译出特定于架构的纯裸机程序以在指定架构上运行。一般由内核厂家提供,我们最为熟知的就是 ARM 提供的 GNU Arm Embedded Toolchain 中的 arm-none-eabi-*、Keil 中的 armcc、IAR。
通常采用交叉编译。
-
linux 程序编译工具链: 这个编译工具链(名字是我自己起的)用于编译出在我们的嵌入式 Linux 环境中运行的用户程序。通常这个编译工具链需要我们根据自己的嵌入式 Linux 环境自己编译。如果是直接买的 SoC 或者开发套件,SoC 或者开发套件厂家会自己编译好然后提供给客户。
- 通常采用交叉编译。
- 自己编译出来的 linux 程序编译工具链通常会被称为 SDK。嵌入式 linux 编译套件往往不是通用的!
- linux 程序编译工具链也可以编译裸机程序,例如编译裸机 U-Boot、Linux Kernel。 但是通常不会使用 linux 程序编译工具链来进行纯裸机开发。
-
文件系统: 其中主要就是根文件系统(RootFS),包括 Linux 启动时所必须的目录和关键性的文件,例如,Linux 启动时都需要有 init 目录下的相关文件。Linux 启动时,第一个必须挂载的是根文件系统,若系统不能从指定设备上挂载根文件系统,则系统会出错而退出启动。成功之后可以自动或手动挂载其他的文件系统。
根文件系统是第一个需要使用我们自己的编译套件来编译的程序。
-
用户 APP: 这个就是我们的嵌入式 Linux 中运行的应用程序了。肯定是需要使用我们自己制作的 linux 程序编译工具链来产生。
以上就是完整的嵌入式 Linux 环境各个部分的基本情况。从搭建嵌入式 Linux 环境的角度来说,我们需要自己编译 BootLoader、Linux Kernel、文件系统、linux 程序编译工具链 这四大部分;从使用者角度来说,通常会直接购买以上完整的嵌入式环境,然后在以上环境上开发用户 APP,基本不会涉及以上四大部分的修改(二次开发除外)。
其中,最麻烦的应该就是构建自己的 linux 程序编译工具链了。
构建过程
嵌入式 Linux 环境的搭建是从源代码开始的,可以手动构建每一部分,也可以选择使用自动化构建工具。如果选择纯手工搭建就要熟悉每一部分的源码的构建细节(好消息是,Linux 系统下的源码基本都是 configure + make 的处理流程),使用自动化构建工具则需要学习对应工具的使用方法。
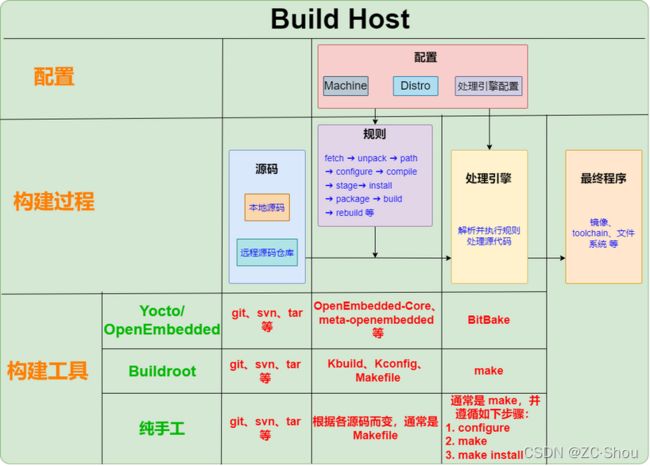
CPU 体系架构
当前全球公认为主流的 CPU 体系架构有 x86、PowerPC、ARM、RISC-V 和 MIPS 等。早年, x86 和 PowerPC 专注于桌面计算机、服务器等领域,ARM、RISC-V 和 MIPS 则在嵌入式领域发力。如今,x86、PowerPC 也布局了嵌入式领域,ARM、RISC-V 和 MIPS 也开始布局桌面计算机和服务器。
我之前主要使用的是 ARM 架构,最近转移到了 RISC-V 架构,因此,以下以 ARM 作为对比,重点介绍 RISC-V。
ARM
ARM 架构是由 ARM 公司推出的基于精简指令集计算机(RISC)指令集架构(ISA)。ARM 架构版本从 ARMv3 到 ARMv7 支持 32 位空间和 32 位算数运算,大部分架构的指令为定长 32 位(Thumb 指令集支持变长的指令集,提供对 32 位和 16 位指令集的支持),而 2011 年发布的 ARMv8-A 架构添加了对 64 位空间和 64 位算术运算的支持,同时也更新了 32 位定长指令集。
ARM 公司除了 ARM 指令集相关产品,也提供了一些列的开发软件,例如 Keil、DS-5 等。
指令集架构(Instruction Set Architecture,ISA)是计算机抽象模型的一部分。它定义了软件如何控制 CPU。Arm ISA 允许开发人员编写符合 Arm 规范的软件和固件,以此实现在任何基于 Arm 的处理器上都可以以同样的方式执行它们。ARM 指令集架构有三种:
-
A64: A64 指令集是在 Armv8-A 中引入的,以支持 64 位架构。A64 指令集有固定的 32 位指令长度。
对应的 CPU 通常使用 AArch64 来表示
-
A32: A32 指令集有固定的 32 位指令长度,并在 4 字节边界上对齐。A32 指令集就是在 Armv6 和 Armv7 架构中我们常说的 ARM 指令集,Armv8 及之后改名 A32 以与 A64 进行区分。
- A32 指令主要被用于 A-profile 和 R-profile。
- 对应的 CPU 通常使用 AArch32 来表示
-
T32: T32 指令集最初是作为 16 位指令的补充集引入的,用于改进的用户代码的代码密度。随着时间的推移,T32 演变成 16 位和 32 位混合长度的指令集。因此,编译器可以在单个指令集中平衡性能和代码大小。
T32 指令集就是在 Armv6 和 Armv7 架构中被我们所熟知的 Thumb 指令集,Armv8 及之后改名为 T32。 T32 支持所有架构的 Profile,并且是 M-Profile 架构所支持的唯一指令集。随着 Thumb-2 技术的引入,A32 的大部分功能都被纳入了 T32 中。目前 32 位的 ARM 指令集通常指的就是它。
以上这三种指令集被称为 ARM 基础指令集(ARM Base ISAs),除此之外,ARM 还提供指令集扩展:自定义指令、DSP、浮点等等。
此外还需要注意,自 ARM11(ARMv6 指令集) 之后,ARM 启用了全新的产品命名方式:Cortex-A、Cortex-R、Cortex-M,他们之间的指令集是独立的,且会有区别。

RISC-V
RISC-V 是一个基于精简指令集(RISC)原则的开源的指令集架构(ISA),其中的 V 表示第 5 代。RISC-V 于 2010 年诞生于美国加州大学伯克利分校并行计算实验室(Parallel Computing Laboratory) 的 David A. Patterson 教授指导的团队。目前,由 2015 年成立的 RISC-V 基金会(现在被称为 RISC-V International)拥有及维护和发布与 RISC-V 定义相关的知识产权。
- RISC-V 官方还提供了一系列的工具,具体见 https://riscv.org/exchanges/software/。
- 指令集手册,软件工具等基本都托管在 RISC-V Github 上。
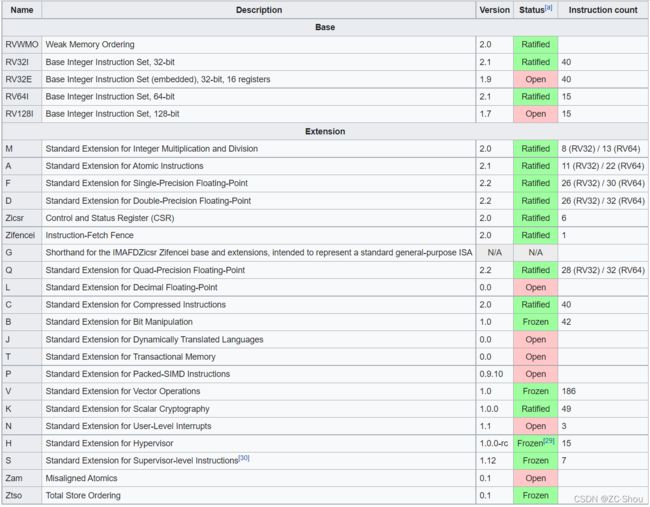
基础指令与扩展指令
RISC-V 指令使用模块化的设计, 包括几个可以互相替换的基本指令集以及额外可以选择的扩展指令集两大部分。在 ISA Specification 的第 27 章节专门描述了指令集的命名规则。下图是维基百科整理的表格:
寄存器
指令的操作对象通常只能是寄存器(内存访问指令可以操作内存)。RISC-V 有 32 个整数寄存器(在嵌入式版本则是 16 个),当采用了浮点扩展之后,还会额外有 32 个浮点寄存器。

其中,第一个整数寄存器被称为零寄存器,其余的被称为通用寄存器。往零寄存器中的写入操作不会有任何效果,读取则总是返回 0。使用零寄存器作为占位符可以简化指令集。
- RISC-V 有提供控制寄存器 及状态寄存器,但是 user-mode 程序只能使用用来量测性能及浮点管理的部分
- RISC-V 没有可以一次 保存或恢复多个寄存器的指令
- 内存访问指令只有
load和store
x86
x86 是一个复杂指令集计算机(CISC)指令集体系结构家族,最初是由 Intel 基于 Intel 8086 微处理器及其 8088 变体开发的。该名字就源自于 Intel 的 80x86 系列处理器。
英特尔 8086 微处理器中的 x86 是16 位的,1985 年,英特尔发布了 32 位 80386。现在,我们通常使用 i386 表示 32 位 x86 架构(有时候也直接使用 x86 表示)。 在 1999 年至 2003 年,AMD 将这种 32 位架构扩展到 64 位,并在早期文档中将其称为 x86-64,后来称为 AMD64。英特尔很快以 IA-32e 的名义采用了 AMD 的架构扩展,后来使用 EM64T 的名称,最后使用 Intel64。现在,我们仍然使用 x86-64 或 AMD64 来表示 64 位的 x86 架构(有时候也直接使用 x64 表示)。
PowerPC
PowerPC(Performance Optimization With Enhanced RISC – Performance Computing,有时简称称 PPC)是 1991 年 Apple-IBM-Motorola联盟( AIM)基于早期的 IBM POWER 架构创建的精简指令集计算机(RISC)指令集架构(ISA)。从 2006 年开始被命名为 Power ISA(PowerPC ISA + PowerPC Book E),而 PowerPC 则作为某些 PowerPC 架构的处理器的商标而存在。基本发展过程:POWER ➔ PowerPC ➔ Power ISA。
MIPS
MIPS(Microprocessor without Interlocked Pipeline Stages)是由美国 MIPS 计算机系统公司开发的一种采取精简指令集(RISC)的指令集架构(ISA)。早期的 MIPS 架构只有 32 位的版本,随后才开发 64 位的版本。在 MIPS V 之后分为了 MIPS32 和 MIPS64。
2021 年 3 月,MIPS 宣布 MIPS 架构的开发已经结束,因为该公司正在向 RISC-V 过渡。
(交叉)编译工具链
软件程序的编译过程由一系列的步骤完成,每一个步骤都有一个对应的工具。这些工具紧密地工作在一起,前一个工具的输出是后一个工具的输入,像一根链条一样,我们称这些工具为编译工具链。
在当前平台(例如 x86 架构的 PC)下,直接编译出来程序(或者库文件),其可以直接在当前的平台运行(或使用)。这个过程就叫做本地编译,使用的编译工具叫做本地编译工具链(简称编译工具链)。例如 PC 上的 VC、GCC、LLVM、TCC 等。
在当前平台下(例如 x86 架构的 PC)下,直接编译出来程序(或者库文件),其不可以直接在当前的平台运行(或使用),必须放到目标平台上(例如 ARM)才可以运行(或使用),这个过程就叫做交叉编译,使用的编译工具叫做交叉编译工具链。例如PC 中的 armcc、iar、特定架构的 GNU、特定架构的 LLVM 等。
这里的平台指的是 CPU 架构或者操作系统
交叉编译工具链又可以根据是否支持 Linux 系统分为 裸机程序交叉编译工具链 和 Linux 程序交叉编译工具链 这两大类。我们上面的举例中,armcc、iar 都属于裸机交叉编译工具链;而特定架构的 GNU、特定架构的 LLVM 则根据需要可以支持 Linux 系统,也可以不支持 Linux 系统,因此它既有裸机程序交叉编译工具链,也有 Linux 程序交叉编译工具链。
- 这里说的裸机是相对于 Linux 系统来说的。裸机程序交叉编译工具链可以用于编译一些嵌入式实时操作系统,例如 FreeRTOS、RT-Thread 等。
- 由于 ARM 的绝对市场地位,导致了在网上搜索交叉编译工具链,基本都和 ARM 有关系。其中一个明显的例子就是交叉编译器的命名。
GNU 交叉编译工具链
我们接触最多交叉编译工具链就是特定架构的 GNU,例如 Arm GNU Toolchain 就分为仅支持裸机的 arm-none-eabi 和 支持 linux 系统的 arm-none-linux 这两大类。特定架构的 GNU 交采编译工具链也是目前我们使用最多的交叉编译工具链,网上所说的交叉编译工具链基本就是指的 GCC。
- 随着开源运动的兴起,自由软件基金会开发了自己的开源免费的 C 语言编译器 GNU C Compiler,简称 GCC。GCC 中提供了 C Preprocessor 这个 C 语言的预处理器,简称 CPP。后来 GCC 又加入了对 C++ 等其它语言的支持,所以他的名字也改为 GNU Compiler Collection。G++ 则是专门用来处理 C++ 语言的。
- 由于 ARM 的绝对市场地位,导致了在网上搜索交叉编译工具链,基本都和 ARM 有关系。其他架构,例如 MIPS、RISC-V 也有 GCC 交叉编译工具链,但是由于市场占有率低我们接触较少,网上资料也非常少。
在我们构建自己的 GCC (交叉)编译工具链的时候,编译(交叉)编译工具链使用的平台、编译出的(交叉)编译工具链运行的平台、使用编译出的(交叉)编译工具链编译出的程序运行的平台三者可以完全不同。其中关键的一步是设置 configure 的参数,该命令有三个参数 --build、--host、--target 非常重要,下图是 Windows 上的 MinGW 编译器配置信息:
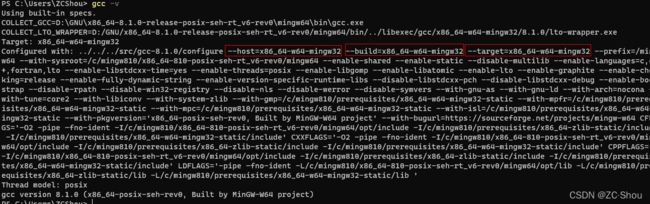
--build:这个参数指出了编译(交叉)编译工具链使用的平台。如果我们不显示指定这个参数的值,那么这个参数的值就会由 config.guess 自动识别。--host:这个参数指出了编译出的(交叉)编译工具链运行的平台。这个参数的值一般就等于--build的值。--target:这个参数指出了使用编译出的(交叉)编译工具链编译出的程序运行的平台。这个选项只有在建立交叉编译环境的时候用到,正常编译和交叉编译都不会用到。
本地编译工具链一般就是指的 --build = --host = --target 的情况,交叉编译工具链一般是--build = --host ≠ --target 的情况。基本很少出现--build ≠ --host 的情况。
命名规则
一般来说,交叉编译工具链的命名规则是:arch [-vendor] [-os] [-(gnu)abi]-*。但是,关于这个规则,我并没有找到在哪份官方资料上有介绍,实际有些交叉编译工具链也确实不符合上面的命名规则。如果有谁在官方资料上见到过此规则的详细描述,一定要私信告诉我。
- arch: 体系架构,如 ARM、MIPS、RISC-V
- vendor: 工具链提供商,没有 vendor 时,用 none 代替。
- os: 目标操作系统,没有 os 支持时,也用 none 代替,表示裸机。如果同时没有 vendor 和 os 支持,则只用一个 none 代替。例如 arm-none-eabi 中的 none 表示既没有 vendor 也没有 os 支持。
- none
- C 库通常是 newlib
- 提供不需要操作系统的 C 库服务
- 允许为特定硬件目标提供基本系统调用
- 可以用来构建 Bootloader 或 Linux Kernel,不能构建 Linux 用户空间代码
- linux
- 用于 Linux 操作系统的开发
- linux 特有的 C 库的选择:glibc、uClibc-ng、musl
- 支持 Linux 系统调用
- 可以用来构建 Linux 用户空间代码,但也可以构建裸机代码,如 Bootloader 或 Linux Kernel
- none
- abi: 应用二进制接口(Application Binary Interface)
- gnu: 这个其实是早期 AArch32 架构使用的名字,后来该名字为 gnueabi
- gnueabi: 其实就是嵌入式应用二进制接口(Embedded Application Binary Interface,EABI)
- elf: 这个通常用在 64 位裸机架构的编译工具链中
由于 ARM 的绝对市场地位,导致了在网上搜索交叉编译工具链,基本都和 ARM 有关系。因此,这里的命名规则更多的是指 Arm GNU Toolchain 的命名。
组成部分
GUN 交叉编译工具链中有三个核心组件:Binutils、GCC、C library,如果需要支持 Linux,则还有个 Linux kernel headers。在源代码组织上他们是相互独立的,需要单独进行交叉编译。
- Binutils:包括一些二进文件相关的工具
- 主要工具
ld链接器as汇编器
- 调试/分析工具和其他工具
- addr2line、ar、c++filt、gold、gprof、nm、objcopy、objdump、ranlib、readelf、size、strings、strip
- 需要针对每种 CPU 架构进行配置
- 交叉编译非常简单,不需要特殊的依赖项。
- 主要工具
- gcc:GNU Compiler Collection
- C、C++、Fortran、Go 等编译器前端
- 各种 CPU 架构的编译器后端
- Provides:
-
编译器本身。例如 cc1 for C、cc1plus for C++
-
编译器调用程序。gcc、g++ 不但调用编译器本身,也调用 binutils 中的 汇编器、连接器
不要被 gcc 这个名字误导,它其实是个 wrapper,会根据输入文件调用一系列其他程序。国外资料中被称为 compiler driver,国内有些资料称为 引导器。
-
目标库:libgcc(gcc 运行时)、libstdc ++(c ++ 库)、libgfortran(fortran运行时)
-
标准 c++ 库的头文件
-
- 构建 gcc 比构建 binutils 要复杂的多
- Linux Kernel headers:构建需要支持 Linux 系统时必须提供。这些头文件定义了用户空间与内核之间的接口(系统调用、数据结构等)。
- 为了构建一个 C 库,需要 Linux 内核头文件中系统调用号的定义、各种结构类型和定义。
- 在内核中,头文件被分开:
- 用户空间可见的头文件,存储在
uapi目录中:include/uapi/、arch//include/uapi/asm - 内部的内核头文件
- 用户空间可见的头文件,存储在
- 在安装过程中需要使用
- 安装包括一个清理过程,用于从头文件中删除特定于内核的结构体
- 从 Linux 4.8 开始,安装 756 个头文件
- 内核到用户空间 ABI 通常是向后兼容的。Kernel headers 的版本必须等于或者小于目标 Linux 的版本
- C library:
-
提供 POSIX 标准函数的实现,以及其他几个标准和扩展
-
基于 Linux 系统调用
-
几个可用的实现
-
glibc:The GNU C Library 是 Linux C 库的事实标准,我们常见的 Linux 发行版中都使用它。支持众多的架构和操作系统,但是不支持没有 MMU 的平台,不支持静态链接。早些年由于硬件限制及 glibc 本身太大基本不能直接用于嵌入式,如今貌似也可以了。
-
uClibc-ng:以前叫 uClibc,始于 2000 年,支持非常灵活的配置。支持架构很多(包括一些 glibc 不支持的),但是仅支持 Linux 操作系统。支持多种没有 MMU 的架构,如 ARM noMMU、Blackfin 等,支持静态链接。
STM32F MCU 没有 MMU,其嵌入式 Linux 环境中编译工具链就是用的它。
-
musl:始于 2011 年,开发非常积极,最近添加了对于 noMMU 的支持。它非常小,尤其是在静态链接时。兼容性好,并且严格遵循 C 标准。
-
bionic:安卓系统使用
-
其他一些特殊用途的:newlib(用于裸机)、dietlibc、klibc
musl 的作者对于 Linux 常用的这几个库做了一个对比,以下是对比情况图:

-
-
在编译和安装之后,提供了:
- 动态链接器
ld.so - C 库本身
libc.so,及其配套库:libm、librt、libpthread、libutil、libnsl、libresolv、libcrypt - C 库的头文件:
stdio.h、string.h等等。
- 动态链接器
-
GUN 将编译器和 C 库分开放在两个软件包里,好处是比较灵活,方便在工具链中可以选择不同的 C 库。但是,也带来了编译器和 C 库的循环依赖问题:编译 C 库需要 C 编译器,但是 C 编译器又依赖 C 库。理论上编译器是不应该依赖 C 库的,它应该只负责将源代码翻译为汇编代码即可,但实际上并非如此。
C99 标准定义了两种实现:一种称为 hosted 实现,一种称为 freestanding 实现。其中,hosted 实现支持完整的 C 标准,包括语言标准和库标准,它用于编译在有宿主系统的环境下运行的程序。freestanding 实现仅支持完整的语言标准,对于库标准它只要求支持部分库标准。
构建(交叉)编译工具链分为好多步,而且单是编译 gcc 就要多次。
LLVM
传统编译器的工作原理基本上都是三段式的,可以分为前端(Frontend)、优化器(Optimizer)、后端(Backend)。前端负责解析源代码,检查语法错误,并将其翻译为抽象的语法树(Abstract Syntax Tree)。优化器对这一中间代码进行优化,试图使代码更高效。后端则负责将优化器优化后的中间代码转换为目标机器的代码,这一过程后端会最大化的利用目标机器的特殊指令,以提高代码的性能。
- 虽然这种三段式的编译器有很多有点,并且被写到了教科书上,但是在实际中这一结构却从来没有被完美实现过。
- 回顾 GCC 的历史,虽然它取得了巨大的成功,但开发 GCC 的初衷是提供一款免费的开源的编译器,仅此而已。可后来随着GCC支持了越来越多的语言,GCC 架构的问题也逐渐暴露出来。
LLVM 作为后起之秀,从开始就是按照前端(Frontend)、优化器(Optimizer)、后端(Backend)的三段式进行设计,整个编译器框架非常符合人们对于编译器的设计以及非常容易理解和学习。
- LLVM 的命名最早源自于底层虚拟机(Low Level Virtual Machine)的首字母缩写,但这个项目并不局限于创建一个虚拟机,开发者因而决定放弃这个缩写的意涵。现在 LLVM 是一个专用名词,表示编译器框架整个项目。
- 目前,很多平台都开始转投 LLVM 了,例如苹果、安卓、ARM等等
ABI、EABI、OABI、GNU EABI
应用二进制接口(Application Binary Interface,ABI)定义了一个系统中函数的参数如何传送、如何接受函数返回值、数据类型的大小、布局和对齐、应用程序应如何对操作系统进行系统调用、对象文件,程序库等的二进制格式等细节。ABI 允许编译好的目标代码在使用兼容 ABI 的系统中无需改动就能运行。
嵌入式应用程序二进制接口 (Embedded Application Binary Interface,EABI) 指定嵌入式软件程序的文件格式、数据类型、寄存器用法、堆栈帧组织和函数参数传递的标准约定,以便与嵌入式操作系统一起使用。广泛使用的 EABI 有 PowerPC、Arm EABI、MIPS EABI。
在很多地方有 GNU EABI 的这样的叫法,例如,在 ARM 提供的 GNU 工具链中有 arm-none-linux-gnueabi 的命名。这里的 GNU EABI 其实就是 EABI。之所以叫这个名字是因为 GNU 一贯作风是要求带有 GNU 字样。例如 GNU 要求把 Linux 称为 GNU/Linux,但是实际情况大家都直接叫 Linux。
OABI (其中的 O,理解为 Old 或 Obsolete)是 ARM 系列的最开始使用的应用程序二进制接口。OABI 假设 CPU 拥有一个浮点单元处理器(实际很多没有),导致编译器生成的程序总是尝试与浮点单元通信以进行浮点运算,由于没有浮点运算单元,内核出现异常,异常机制会自动再使用软件模拟浮点进行计算,这导致了一些额外开销。
EABI 被创造出来以解决 OABI 的这个问题。但是,EABI 没有简单的方法来让二进制发行版同时支持软浮点和硬浮点,因此,ARM 的交叉编译器分为 ARMEL 和 ARMHF 这两种。因此,有个 arm-none-linux-gnueabihf 表示支持硬浮点。
嵌入式系统启动
宏观上来看,系统的启动分为 Boot 执行阶段和系统执行阶段,Boot 阶段为系统运行准备必要条件,然后将 CPU 的控制权交给系统,系统接管 CPU ,然后做相应初始化后开始运行;从微观来看,系统启动从上电开始,经过了很多阶段。
芯片一上电就会根据设定的启动方式,从固定的位置开始读取代码并执行。这个固定的位置根据芯片而定,例如,STM32 的 MCU 支持 RAM、Flash、BootLoader 三个位置启动。下图是一个典型的嵌入式 Linux 系统启动流程:

注意:不含安全启动。在安全启动下,参见 ARM 的 Platform Security Architecture 中的 Trusted Firmware
嵌入式系统构建工具
构建一整套嵌入式 Linux 环境是一件很庞大的事情,我们可以选择自己动手,根据上面嵌入式 Linux 环境,一点一点来构建其中的各个部分。实际情况是,为了简化搭建工作量,诞生了一些嵌入式系统构建工具。这些工具通过各种自动化手段,只需要我们输入基本命令,就可以自动构建出以上说的完整嵌入式环境。
Buildroot
Buildroot 是 Linux 平台上的一个用于构建嵌入式 Linux 系统的框架。整个 Buildroot 是由 Makefile 脚本和 Kconfig 配置文件构成的。使用它可以和编译 Linux 内核一样,通过使用 Kbuild/Kconfig 系统编译出一个完整的可以直接烧写到机器上运行的 Linux 系统软件(包含boot、kernel、rootfs 以及 rootfs 中的各种库和应用程序、交叉编译工具链)。
Buildroot 支持的架构有 ARC、ARM、AArch64、Blackfin、csky、m68k,Microblaze、MIPS(64)、NIOS II、OpenRisc、PowerPC(64)、SuperH、SPARC、x86、x86 64、Xtensa.
Yocto
Yocto 全称是 Yocto Project(官方简称 YP) 是 Linux 基金会在 2010 年推出的一个开源的协作项目。提供模板、工具和方法以创建定制的 Linux 系统和嵌入式产品,而无需关心硬件体系。从历史上看,该项目是从 OpenEmbedded 项目发展而来的。
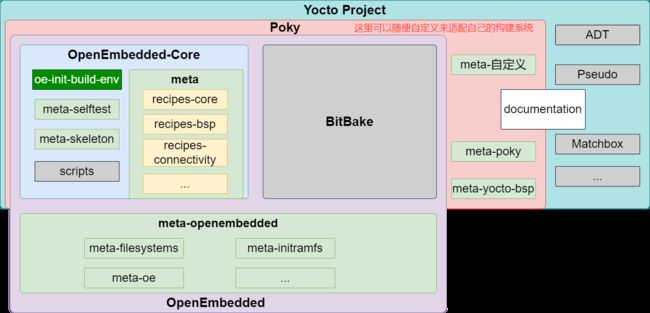
Yocto Project 这个名字(或者我们常简称的 Yocto)是指的这个项目本身或者一个组织,Poky 官方定义为 Yocto Project 的参考发行版,它才是我们真正使用的构建系统工具(更确切的说这就是一个可以构建出嵌入式 Linux 的 DEMO)。实际情况中,我们一般会对 Poky 进行自定义(删除 meta-poky 等,添加自己的 meta-xxx)来实现自己的嵌入式 Linux 系统构建工具包。如下是我们在用的一个目录结构:

这里还有个问题,Yocto Project 对于 OpenEmbedded 的引用是打散重新组合的(OpenEmbedded 本身就是有多个部分组成),并不是完整的把 OpenEmbedded 拿过来。从 Yocto Project 的角度来看,Yocto Project 的结构就是如下所示:
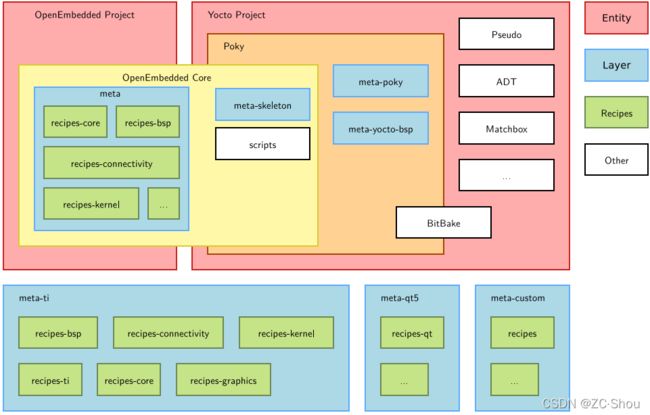
OpenEmbedded
OpenEmbedded (简称 OE)是一个构建自动化框架和交叉编译环境,用于为嵌入式设备创建 Linux 发行版。OpenEmbedded 由成立于 2003 年的 OpenEmbedded 社区开发,其诞生远早于 Yocto Project。2011 年 3 月,它与 Yocto Project 合作(实际就是合并了),并开始以 OpenEmbedded-Core 项目作为项目发展的名称(简称 OE-Core),之前的称为 OpenEmbedded-Classic(简称 OE-Classic 或 oe-dev),OpenEmbedded 这个名字就用来代指整个 OpenEmbedded 项目。
注意,在一些老文档中,OpenEmbedded 这个名字有可能还是指的旧的 OpenEmbedded 。例如,OpenEmbedded 的原始代码仓库并没有改名为 OpenEmbedded-Classic。OpenEmbedded 项目的代码仓库见 https://git.openembedded.org/。
之所以更名是因为与 Yocto Project 合并之后的开发团队对 OpenEmbedded 的整个结构进行了比价大改进。 OpenEmbedded-Classic 的所有自动构建的处方(Recipes)都放在一起,随着发展越来越难以维护;而在新的 OpenEmbedded-Core,其结构由许多 layers 组成(OpenEmbedded 维护了一个可以与 OE-Core 一起使用的层列表),让用户可以更容易加入定制的自动构建处方(Recipes)。OE-Classic 不再维护,也基本没有使用了!现在的 OpenEmbedded 也可以理解为基于 OE-Core 的一个实现(BitBake + OpenEmbedded-Core)+ 一组元数据)。

OpenEmbedded-Core 可以独立使用,也被集成在 Angstrom、SHR、Yocto Project 等系统中来使用。实际情况是,很少见单独使用 OE-Core 的情况,OpenEmbedded 基本就成了 Yocto Project 中的一部分(其他基本死的差不多了),其文档等全部都引用 Yocto Project 中对应文档。
PTXdist
PTXdist 是一个固件镜像构建工具,是 Pengutronix 在 2001 年开发的一个构建系统。采用了 Linux 内核中的配置系统 Kconfig 来选择和配置每个包,规则集合则基于 GNU Make 和 Bash。
OpenWRT
OpenWRT 是一个针对嵌入式设备的 Linux 操作系统。OpenWrt 不是一个单一且不可更改的固件,而是提供了具有软件包管理功能的完全可写的文件系统。
OpenWRT 是一个高度模块化、高度自动化的嵌入式Linux系统,拥有强大的网络组件和扩展性,常常被用于工控设备、电话、小型机器人、智能家居、路由器以及 VOIP 设备中。
测试环境
正好手里有一块前几年的 STM32F769I-EVAL 的评估板,后续,我就以手里的 STM32F769I-EVAL 的评估板为载体,尽量不使用已有的嵌入式构建工具,来一步一步搭建这个嵌入式 Linux 环境。如下图所示的这个:

这块评估板的功能应该是非常全了,价格也是不便宜。ST 官网对于这块评估板的介绍参见 Evaluation board with STM32F769NI MCU。
熟悉 ST 的开发板的都知道,ST 的开发板主要有 ST 官方的 Nucleo 系列、Discovery Kits 系列、Evaluation 系列以及第三方开发板这些组成。其中,ST 自家开发板中 Evaluation 系列是功能最全的,也是价格最高的。第三方开发板差异就比加大了。

嵌入式环境与我们熟悉的 PC 环境还是有很大区别的。尤其是对于部分芯片,它没有 MMU,也就不能使用虚拟内存相关的所有技术。也就意味着,嵌入式中的地址都是实际的物理地址。
其次,嵌入式环境的另一个大特点就是资源非常紧张,这就导致了我们可能需要将最终的多部分的可执行程序放到不同的地方。举个例子,STM32 的 MCU 中,往往不能存放 Linux Kernel,我们需要将 Linux Kernel 放到一些外部存储器中。
对于 ARM 平台,ARM 给出了两个概念:加载域 和 执行域,加载域对应加载地址,执行域对应了一个执行地址。关于 ARM 的分散加载机制,可以参见博文 ARM 之十三 armlink(Keil) 分散加载机制详解 及 分散加载文件的编写 即可。
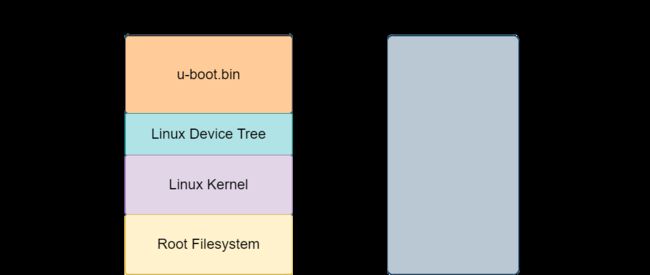
进一步具体到 STM32 芯片,我们的程序是放到内部的 FLASH 上的,FLASH 就是加载域,FLASH 上的具体地址就是加载域地址。同时,ST 芯片的设计可以从 FLASH 上执行代码(速度相对较慢),此时的加载域与执行域是同一个;还有一种更高效的方式是将代码放到 RAM 中执行(存放还是在 FLASH),此时 RAM 就是执行域,程序在 RAM 中的地址就是执行域地址。
参考
- https://codeantenna.com/a/wf8KVWOhym
- https://www.its404.com/article/qq_44034198/110872972
- https://sourcery.sw.siemens.com/GNUToolchain/kbentry32
- https://sourcery.sw.siemens.com/GNUToolchain/kbentry38
- https://www.jianshu.com/p/a7c8d99162c5
- https://blog.csdn.net/flagyan/article/details/6166107
- https://elinux.org/images/1/15/Anatomy_of_Cross-Compilation_Toolchains.pdf
- https://zhuanlan.zhihu.com/p/110402378
- https://wiki-archive.linaro.org/WorkingGroups/ToolChain/FAQ#What_is_the_differences_between_.2BIBw-arm-none-eabi-.2BIB0_and_.2BIBw-arm-linux-gnueabihf.2BIB0.3F_Can_I_use_.2BIBw-arm-linux-gnueabihf.2BIB0_tool_chain_in_bare-metal_environment.3F_How_do_you_know_which_toolchain_binary_to_use_where.3F
- https://docs.embeddedts.com/EABI_vs_OABI
- http://www.etalabs.net/compare_libcs.html