增强复制状态机的两阶段提交协议
Enhancing Two Phase-Commit Protocol for Replicated State Machines
Halit Uyanık and Tolga Ovatman
Department of Computer Engineering
Istanbul Technical University
34469 Istanbul, Turkey
Email
目录
- 1 介绍
- 2 设计和实现
- 2.1 事件类型
- 2.2 在状态机上执行事件
- 2.3 具有优先级的基本两阶段提交算法
- 2.4 利用SM优先级增强两阶段提交算法
- 2.5 强大的一致性保证
- 3 实验
- 致谢
- 参考
摘要:两阶段提交 (2PC) 是一种分布式算法,其中希望对服务进行提交的进程首先需要确保参与的对等方已准备好进行提交操作。在我们的研究中,我们通过提前中止状态机的状态执行来增强复制状态机环境的 2PC,以防更高优先级的状态机检查提交要写入的值。通过应用我们的方法,当副本数量超过 3 时,与经典 2PC 相比,我们的方法浪费的状态执行次数要少得多。
关键字:两阶段提交协议、复制状态机、一致性管理
1 介绍
两阶段提交 (2PC) 协议广泛用于在分布式系统中提供原子事务的对等点之间的一致性。在典型的 2PC 会话中,需要对公共资源进行更改的进程需要广播其意图。此操作会触发其他进程为提交更改做准备。但是,可能有多个进程试图同时对同一资源进行更改。当使用 2PC 协议时,可以利用进程优先级来解决此类冲突,其中每个进程在进程运行之前分配了一个预定值。使用这个值,不同的机器可以决定接下来要执行哪个提交消息。较高的优先级值表示较高的重要性,并且总是比编号低的优先级值优先。
随着云系统中的无服务器架构最近引起了极大的兴趣,复制状态机(RSM)作为一种在自动化流程开发中提供容错能力的模型出现了 [1]。 RSM 用于最新的分布式系统,例如 Chubby 和 Spanner,因为它在提供 CAP(Consistency Availability-Partition tolerance)很重要的服务方面很有用。我们的研究提出了对 2PC 协议的增强,该协议利用早期预先确定 RSM 之间可能的写入冲突来避免低优先级状态机 (SM) 执行的额外状态执行。作为额外的改进,我们在我们的实现中也不使用任何全局锁定机制。或者,我们在 SM 中使用本地锁来促进增强型 2PC (e2PC) 运行期间所需的原子操作。
使用 RSM 方法,我们将 2PC 协议的步骤分配到不同的转换步骤中,并进行了实验:当 RSM 中发生写冲突时,它对浪费多少进程的影响。我们已经实现了一个应用程序,其中客户端不断执行尝试更改共享变量的 RSM。该应用程序被部署到分布式云环境中,以试验和了解不同数量的客户端和服务器。我们的实验表明,当使用所提出的 2PC 增强时,随着复制机器数量的增加,失败的 SM 周期数和浪费状态执行的数量都会减少。
承诺协议中使用了基于优先级的研究,例如 Sha 等人的研究,其中观察到了优先级集成系统面临秩序混乱的问题[2]。 Rodrigues 等人的研究提出了一种针对 LAN 的机制,其中现代云系统下的行为在研究时不存在 [3]。另一项类似的研究 [4] 使用优先级作为排序机制,而在我们的研究中,我们使用优先级作为解决写入冲突的手段。
我们没有使用类似于 Paxos [5]、RAFT [6] 的领导方法,而是使用本地锁定机制,因为我们所有的服务器都充当领导者,并且可以根据共识做出决策。还有一些研究以使用不同类型的锁为代价来涵盖 2PC 优化 [7],还有一些 [8] 提到了为什么经典的 2PC 方法是不够的,并在不使用锁的情况下实现了一种新方法。我们还为它的高可用性消息队列系统使用了一个名为 RabbitMQ 的著名消息代理。
本文组织如下:第 2 节详细介绍了我们的实验性 SM 设计和算法。实验结果在第 3 节讨论,最后进一步的想法和我们研究的局限性在第 4 节讨论。
2 设计和实现
在我们的实验中,每个客户机产生一组事件流,以便处理驻留在服务器中的SMs。客户端还负责生成优先级值,范围为1到100,000。还假设没有客户机在同一时间产生具有相同优先级值的消息。
服务器主要由服务和代理组成,前者负责管理事件的走向,后者负责将事件的执行和SM与服务分离。这个结构使我们能够只关注我们的算法,并防止来自服务的直接事件执行的任何不可预见的影响。客户端在任何时候只能与单个服务器通信。
我们在工作中使用线性状态机设计。为了比较检查和提交步骤之间的距离,我们在READ、check和WRITE操作之间引入了额外的M个步骤,这些操作的定义将在事件类型一节中讨论。没有分支案件。此外,我们的SM是完全确定的。因此,我们可以确定执行事件之后的下一步是什么。
2.1 事件类型
本小节标识用于在普通SM上执行转换的每个事件类型。这些事件由客户机发送,由服务读取,并由代理处理。
1)TRIVIAL 事件:琐碎事件被标识为其他重要进程之间的填充事件。然而,这并不意味着它们都是独立的。在READ和WRITE事件之间还存在一些琐碎事件,这使得这些琐碎事件依赖于SM的进程。因此,在任何时候执行TRIVIAL事件时,agent也会检查失败的条件。
2)READ 事件:Read事件基本上是从本地存储中获取数据,并将其缓存起来以备即将进行的WRITE操作。在SM的整个生命周期中,这个缓存值将与本地存储中的值进行比较,以查看是否有其他机器对本地存储进行了更改。任何注意到的更改都将导致此SM失败。客户端发送的READ事件可能并不总是被执行,这将在算法部分进行解释。
3)CHECK 事件:当一台机器需要检查其他机器的优先级时,它使用CHECK操作广播一条消息。在接收到此请求后,其他每台机器都将发送响应OK或FAIL。响应取决于它们的当前优先级值,以及与CHECK消息一起发送的优先级值。
4)WRITE 事件:在成功执行之前需要的事件后发送WRITE事件。这意味着机器已经成功地获得了自己的写锁,因此阻止了其他机器继续执行CHECK操作。因此,当一台机器进入写状态时,就意味着没有其他机器可以使它失败。在广播WRITE事件之后,所有机器将提交与消息一起发送的值。因此更改它们的本地值,并在必要时重置它们自己的本地机器。
5)FAIL 事件:当机器在执行客户端发送的事件时发生故障时触发失败事件。它也可以在另一台机器执行提交操作时被触发。由于代理每次可以执行一个事件,如果另一个提交在当前机器上触发了一个失败事件,机器将在下一个事件执行时意识到它,因此会尽快通知客户机。
6)FINISH 事件:FINISH事件基本上是另一个TRIVIAL事件,它有一个异常,表示从开始到结束完成了一个完整的状态机事件循环。
2.2 在状态机上执行事件
正如在设计部分所提到的,事件的执行是从使用代理的算法中抽象出来的。因此,事件执行和一些条件检查在这两种算法中是相同的,将在这里讨论。
当算法服务触发代理时,代理检查SM和缓存变量的当前状态,以确定是否可以继续进行。这里需要指出的是,代理一次只能处理一个触发器。使用这种本地锁定机制,我们将防止来自另一台机器的触发器和同时激活的本地触发器。
根据触发器是来自另一台机器(例如提交更改)还是来自机器本身,条件会发生变化。它确保提交操作一定会被执行,因此它只检查当前SM是否处于READ和WRITE步骤之间。如果这个条件为真,那么在更改本地变量值之后,本地SM副本将重置为初始状态,因此来自客户机的任何挂起的循环将重新启动。否则,只修改局部变量。
如果一个触发器来自本地服务,那么我们检查两个不同的条件。第一个代理需要确保传入的事件实际上可以在SM上执行,因为如果机器由于来自另一台机器的触发器而执行了FAIL事件,那么它就不能执行除第一个事件之外的任何事件。
其次,如果缓存值和数据库值不相等,这意味着在本地SM读取值后发生了更改,因此它不能继续进行任何操作。这将导致重新设置SM,客户端需要从头开始重新启动。
2.3 具有优先级的基本两阶段提交算法
在基本的2PC算法中,副本收到具有优先级值的事件后,首先检查事件的类型。如果是READ类型的事件,服务将检查另一台具有更高优先级值的机器是否通知它正在执行WRITE操作。如果是,则返回FAIL给客户端,以便客户端重新开始。我们不将这些类型的失败计算在统计数据中,因为失败的原因不是冲突,而是服务器无法继续前进。如果事件类型是TRIVIAL或FINISH,它命令代理直接执行事件。在此之后,代理检查执行条件,如果没有任何错误,则执行SM。
如果事件是WRITE,那么它将进入两阶段提交过程。首先,它检查所有其他机器的优先级和写入状态。由于我们确保了如果一台机器正在提交,那么其他机器就不能在WRITE事件上取得进展,因此来自另一台机器的这种应答将导致SM本身失败。
如果机器在第一个检查优先级进程中没有遇到任何问题,它将尝试进入提交状态。在这一点上有一个最后的条件检查,在检查其他机器的操作过程中,有可能另一个状态已经被检查的机器接收一个具有更高优先级的WRITE事件,因此检查当前机器的状态,并以失败告终。因此,在将状态更改为提交之前,机器会尝试获得其本地锁,如果已经失败,则将失败返回给客户端,否则更改状态并将更改提交给其他机器。在收到来自所有机器的提交响应后,它还更改自己的本地变量并重置其提交状态。然后将完成的响应发送给客户端,并等待下一个事件触发器。
2.4 利用SM优先级增强两阶段提交算法
算法1描述了e2PC算法。如果到达的事件是READ、TRIVIAL或FINISH,服务命令代理直接执行事件。如前所述,代理仍然检查默认条件。如果没有任何错误发生,服务将成功返回给客户端并等待下一个触发器。
第二个选项是CHECK事件。当CHECK事件到达时,服务向所有其他机器广播一条消息,请求它们根据其优先级值进行响应。如果不存在具有更高优先级值的其他机器服务,那么它将继续在订购代理上执行事件,然后向客户机发送成功响应。否则,服务将失败返回给客户端,以便客户端重新启动。
第三个选项是WRITE事件。为了让服务执行写事件,它需要在其本地锁上赢得竞速条件。竞争条件发生在另一台机器的CHECK请求和本地原子锁变量上的本地WRITE请求之间。如果任何其他具有CHECK请求且优先级高于当前本地WRITE请求的机器来到并在本地请求之前获得锁,则本地机器将失败。由于局部变量是原子的,并且它对每个副本都是惟一的,因此不存在死锁情况。在成功地将本地锁变量设置为true之后,机器就可以向所有其他机器发送提交请求,然后在收到它们的成功响应之后,它就可以提交本地更改。
2.5 强大的一致性保证
正如在设计部分中提到的,我们的系统只使用局部锁,并且在这些锁的上下文中定义的原子操作确保是无锁的。因此,任何使用这些锁的进程最终都会释放它们。此属性使所有机器能够相互交互而不陷入任何死锁,而且由于只有一台机器可以作为优先级竞赛的胜利者获得写锁,因此我们的设计提供了很强的一致性。
e2PC服务算法流程

3 实验
前一节中讨论的两种算法在不同的环境中进行了实验。我们使用AWS(Amazon Web Services) EC2免费层服务器来创建分布式环境。实验包括2-10个副本。平均消息吞吐量使用RabbitMQ管理接口API计算,为每秒2000条消息。每个客户端完成的提交数是1000,在所有操作完成后,每个客户机将执行9000个事件。我们重复了20次实验来收集平均值。
用两种不同的方法来比较算法。第一个是失败的状态机周期(FSMC),第二个是所有SMs执行的浪费事件执行(WEC)的总数。FSMC的计算方法是将所有机器执行的FAIL事件总数相加。WEC的计算方法是取执行的事件总数与在无故障情况下应执行的事件数之差。尽管FSMC和WEC在一定程度上相互依赖,但FSMC只显示失败周期的数量,这使得WEC检查有意义,可以查看进展损失了多少。因此,第一个度量定义了客户机必须进行多少次尝试才能处理其所有事件循环,而第二个度量定义了服务器必须多执行多少个事件才能完成所有传入请求。
图1为FSMC实验结果,图2为WEC计数。对于这两种结果,随着副本数量的增加,同步更新的数量也会增加尝试也会增加,导致rsm浪费更多进程。检查6个副本及以上的测量结果,e2PC算法的浪费比基本的2PC实现要少得多。其原因是e2PC执行的写冲突的早期检测。
图1所示。失败的状态机周期为每个客户机1000个提交请求
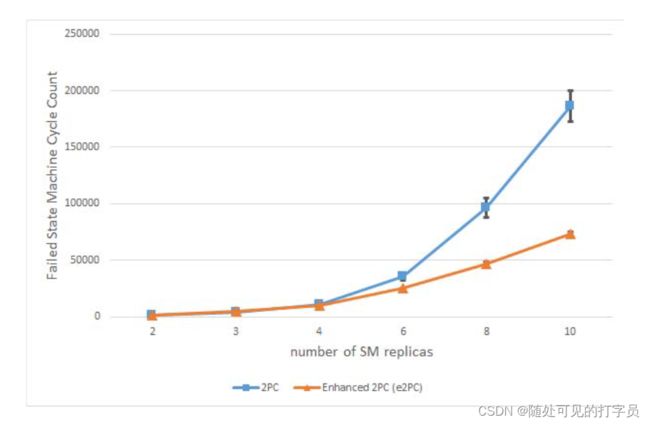
图2所示。每个客户端提交1000次会浪费事件执行
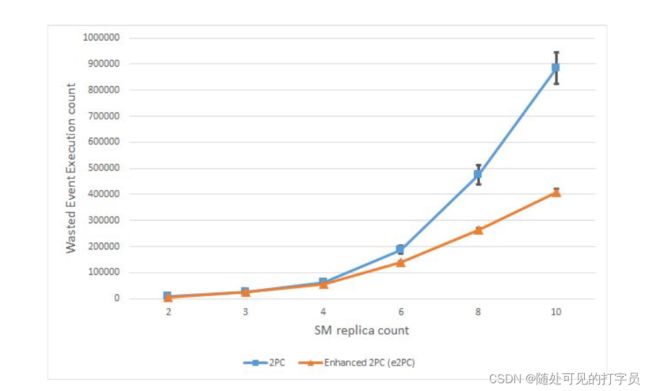
图3。早期和晚期优先级检查的失败状态机周期比较
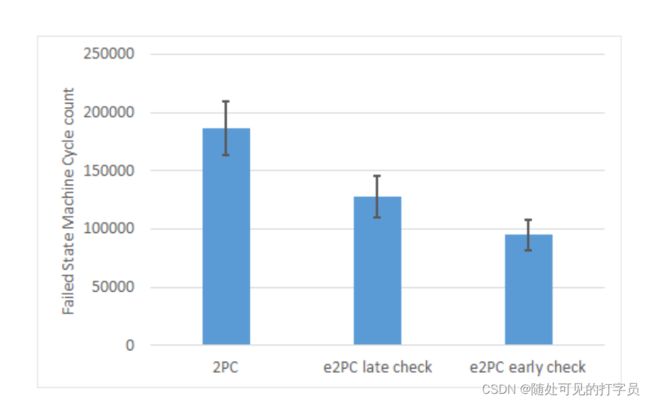
图4。早期和后期优先级检查的浪费事件执行比较
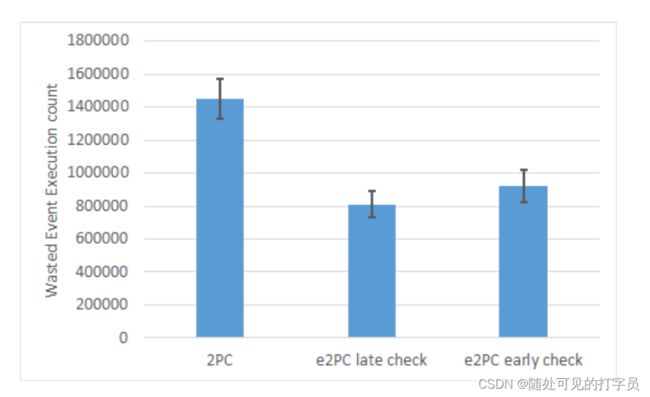
我们提出的方法还可以进行微调,以平衡在读取值后尽早检查优先级和延迟检查优先级之间的权衡。为了更好地演示这种效果,我们对一个状态机重复了我们的实验,该状态机在读写操作之间发生了10个状态转换(是前面实验中转换数量的两倍)。我们使用了8个副本,并在读操作之后或写操作之前执行了优先级检查。图3和图4显示了这个实验的结果。自然,如图中所示,较早执行检查将减少浪费的执行,但是,如果高优先级SMs与低优先级SMs频繁冲突,这也可能降低总体吞吐量,因为在这种情况下,较早的检查是不必要的。
我们的实验表明,增强2PC协议与写冲突的早期控制机制,降低了不必要的状态执行的成本在不同机器上同时更新同一对象的频率很高。该机制是通过将基本两阶段提交协议的步骤分离到RSM上的不同事件来实现的。
致谢
本研究得到土耳其科学和技术研究委员会(TUBITAK)的支持,项目编号为118E887。
参考
[1] Fred B Schneider. The state machine approach: A tutorial. In Faulttolerant distributed computing, pages 18–41. Springer, 1990.
[2] Lui Sha, Ragunathan Rajkumar, Sang Hyuk Son, and C-H Chang. A realtime locking protocol. IEEE Transactions on computers, 40(7):793–800, 1991.
[3] Luıs Rodrigues, Paulo Ver ́ıssimo, and Antonio Casimiro. Priority-based totally ordered multicast. IFAC Proceedings Volumes, 28(5):351–359, 1995.
[4] Nuno Santos and Andr ́e Schiper. Achieving high-throughput state machine replication in multi-core systems. Technical report, 2011.
[5] Leslie Lamport et al. Paxos made simple. ACM Sigact News, 32(4):18–25, 2001.
[6] Diego Ongaro and John Ousterhout. In search of an understandable consensus algorithm. In 2014 {USENIX} Annual Technical Conference ({USENIX}{ATC} 14), pages 305–319, 2014.
[7] George Samaras, Kathryn Britton, Andrew Citron, and C Mohan. Twophase commit optimizations in a commercial distributed environment.Distributed and Parallel Databases, 3(4):325–360, 1995.
[8] Mohammed Khaja Nizamuddin and Syed Abdul Sattar. Algorithm for priority based concurrency control without locking in mobile environments. In 2011 3rd International Conference on Electronics Computer Technology, volume 3, pages 108–112. IEEE, 2011.