MPP架构
什么是MPP架构
MPP (Massively Parallel Processing),即大规模并行处理。
并行处理:
在数据库集群中,首先每个节点都有独立的磁盘存储系统和内存系统,其次业务数据根据数据库模型和应用特点划分到各个节点上,MPP是将任务并行的分散到多个服务器和节点上,在每个节点上计算完成后,将各自部分的结果汇总在一起得到最终的结果。
大规模:
每台数据节点通过专用网络或者商业通用网络互相连接,彼此协同计算,作为整体提供数据库服务。整个集群称为非共享数据库集群,非共享数据库集群有完全的可伸缩性、高可用、高性能、优秀的性价比、资源共享等优势。
以上和Doris的设计架构一致所以我们称Doris是一个分布式的、面向查询的分布式数据库。主要部分是SQL,它在内部使用MPP技术。如下图
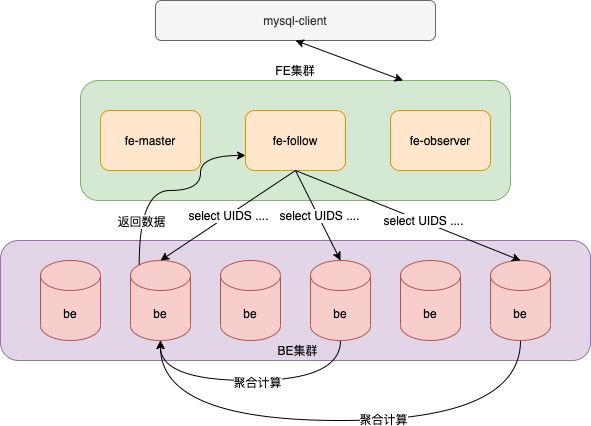
2、架构特性
MPP 具备以下技术特征:
1) 相对低的硬件成本:完全使用 x86 架构的 PC Server,不需要昂贵的 Unix 服务器和磁盘阵列;
2) 集群架构与部署:完全并行的 MPP + Shared Nothing 的分布式架构,采用 Non-Master 部署,节点对等的扁平结构;
3) 海量数据分布压缩存储:可处理 PB 级别以上的结构化数据,采用 hash分布、random 存储策略进行数据存储;同时采用先进的压缩算法,减少存储数据所需的空间,可以将所用空间减少 1~20 倍,并相应地提高 I/O 性能;
4) 数据加载高效性:基于策略的数据加载模式,集群整体加载速度可达2TB/h;
5) 高扩展、高可靠:支持集群节点的扩容和缩容,支持全量、增量的备份/恢复;
6) 高可用、易维护:数据通过副本提供冗余保护,自动故障探测和管理,自动同步元数据和业务数据。提供图形化工具,以简化管理员对数据库的管理工作;
7) 高并发:读写不互斥,支持数据的边加载边查询,单个节点并发能力大于 300 用户;
8) 行列混合存储:提供行列混合存储方案,从而提高了列存数据库特殊查询场景的查询响应耗时;
9) 标准化:支持SQL92 标准,支持 C API、ODBC、JDBC、ADO.NET 等接口规范。
3、例子
Greenplum是一种基于PostgreSQL的分布式数据库。其采用shared nothing架构(MPP),主机,操作系统,内存,存储都是自我控制的,不存在共享。也就是每个节点都是一个单独的数据库。节点之间的信息交互是通过节点互联网络实现。通过将数据分布到多个节点上来实现规模数据的存储,通过并行查询处理来提高查询性能。这个就像是把小数据库组织起来,联合成一个大型数据库。将数据分片,存储在每个节点上。每个节点仅查询自己的数据。所得到的结果再经过主节点处理得到最终结果。通过增加节点数目达到系统线性扩展。
elasticsearch也是一种MPP架构的数据库,Presto、Impala等都是MPP engine,各节点不共享资源,每个executor可以独自完成数据的读取和计算,缺点在于怕stragglers,遇到后整个engine的性能下降到该straggler的能力,所谓木桶的短板,这也是为什么MPP架构不适合异构的机器,要求各节点配置一样。
Spark SQL应该还是算做Batching Processing, 中间计算结果需要落地到磁盘,所以查询效率没有MPP架构的引擎(如Impala)高。
4、MPP架构与Hadoop
其实MPP架构的关系型数据库与Hadoop的理论基础是极其相似的,都是将运算分布到节点中独立运算后进行结果合并。个人觉得区别仅仅在于前者跑的是SQL,后者底层处理则是MapReduce程序。
但是我们会经常听到对于MPP而言,虽说是宣称也可以横向扩展Scale OUT,但是这种扩展一般是扩到100左右,而Hadoop一般可以扩展1000+,这也是经常被大家拿来区分这两种技术的一个说词。
这是为什么呢?其实可以从CAP理论上来找到一些理由。因为MPP始终还是DB,一定要考虑C(Consistency),其次考虑 A(Availability),最后才在可能的情况下尽量做好P(Partition-tolerance)。而Hadoop就是为了并行处理和存储设计的,所有数据都是以文件存储,所以优先考虑的是P,然后是A,最后再考虑C。所以后者的可扩展性当然好于前者。
以下几个方面制约了MPP数据库的扩展
1、高可用:MPP DB是通过Hash计算来确定数据行所在的物理机器(而Hadoop无需此操作),对存储位置的不透明导致MPP的高可用很难办。
2、并行任务:数据是按照Hash来切分了,但是任务没有。每个任务,无论大小都要到每个节点去走一圈。
3、文件系统:数据切分了,但是文件数没有变少,每个表在每个节点上一定有一到多个文件。同样节点数越多,存储的表就越多,导致每个文件系统上有上万甚至十万多个文件。
4、网络瓶颈:MPP强调对等的网络,点对点的连接也消耗了大量的网络带宽,限制了网络上的线性扩展(想象一台机器可能要给1000台机器发送信息)。更多的节点并没有提供更高的网络带宽,反而导致每个组节点间平均带宽降低。
5、其他关系数据库的枷锁:比如锁、日志、权限、管理节点瓶颈等均限制了MPP规模的扩大。
但是MPP数据库有对SQL的完整兼容和一些事务处理功能,对于用户来说,在实际的使用场景中,如果数据扩展需求不是特别大,需要的处理节点不多,数据都是结构化数据,习惯使用传统RDBMS的很多特性的场景,可以考虑MPP如Greenplum/Gbase等。
但是如果有很多非结构化数据,或者数据量巨大,有需要扩展到成百上千个数据节点需求的,这个时候Hadoop是更好的选择。