scrapy对接selenium原理超详细解读!!!!
详解
-
-
-
- 下载器中间件常见方法解读
-
- 1、from_crawler(cls, crawler)
- 2、process_request(request, spider)
- 3、process_response(request, response, spider)
- 4、process_exception(request, exception, spider)
- scrapy于selenium衔接原理
- 实例
-
-
下载器中间件常见方法解读
下载器中间件有什么作用:
1:在scheduler(调度器)中调取一个request(请求),发送给Downloader(下载器)之前,我们可以对request(请求)进行修改.
2:在Downloader(下载器)返回response(响应)给spider之前,我们可以对response(响应)进行修改.
下载器中间件的功能十分强大,修改User-Agent,处理重定向,设置代理,失败重试,设置cookie等都需要它来操作.
首先,我们要先理解下载器中间件的常见的方法
1、from_crawler(cls, crawler)
此方法是下载器中间件的主要入口,接受一个crawler实例
@classmethod
def from_crawler(cls, crawler):
settings = crawler.settings
return cls()
通过类方法 from_crawler 将它传递给扩展(extensions)。 该对象提供对所有Scrapy核心组件的访问, 也是扩展访问Scrapy核心组件和挂载功能到Scrapy的唯一途径。
Crawler必须使用 scrapy.spiders.Spider 子类及 scrapy.settings.Settings 的对象进行实例化
中间件中大部分类方法都是为了获取设置setting中的自定义的信息。
@classmethod将此方法变为类方法,
详情讲解请移步:python 类方法 实例方法 静态方法 作用及区别
2、process_request(request, spider)
为通过下载中间件的每个请求调用此方法。
def process_request(self, request, spider):
# request
# spider指的是当前是哪个爬虫发送过来的request对象
# Called for each request that goes through the downloader
# middleware.
# Must either:
# - return None: continue processing this request
# - or return a Response object
# - or return a Request object
# - or raise IgnoreRequest: process_exception() methods of
# installed downloader middleware will be called
return None
process_request()应该是: return None,返回一个 Response对象,返回一个Request 对象,或 raise IgnoreRequest。
如果它返回None,Scrapy 将继续处理这个请求,执行所有其他中间件,直到最终调用适当的下载器处理程序执行请求(并下载其响应)。
如果它返回一个Response对象,Scrapy 就不会调用任何其他方法process_request()或process_exception()方法,或者适当的下载函数;它会返回那个响应process_response() 安装的中间件的方法总是在每次响应时调用。
如果它返回一个Request对象,Scrapy 将停止调用 process_request 方法并重新安排返回的请求。执行新返回的请求后,将在下载的响应上调用适当的中间件链。
如果引发IgnoreRequest异常,将process_exception()调用已安装的下载器中间件的方法。如果它们都没有处理异常,Request.errback则调用请求 ( )的 errback函数。如果没有代码处理引发的异常,它将被忽略并且不记录(与其他异常不同)。
参数 request ( Requestobject) – 正在处理的请求
spider ( Spiderobject) – 此请求针对的蜘蛛
3、process_response(request, response, spider)
处理响应:当下载器完成http请求,传递响应给引擎的时候该方法被调用
def process_response(self, request, response, spider):
# request-我们发送了哪个请求得到了当前的响应
# spider- 我们使用了哪个爬虫发送了请求为了得到当前的响应
# Called with the response returned from the downloader.
# Must either;
# - return a Response object
# - return a Request object
# - or raise IgnoreRequest
return response
process_response()应该:返回一个Response 对象,返回一个Request对象或引发IgnoreRequest异常。
如果它返回一个Response(它可能是相同的给定响应,也可能是一个全新的响应),则该响应将继续使用process_response()链中的下一个中间件的进行处理。
如果它返回一个Request对象,中间件链就会停止,并且返回的请求被重新安排在将来下载。这与从 返回请求的行为相同process_request()。
如果它引发IgnoreRequest异常,Request.errback则调用请求 ( )的 errback
函数。如果没有代码处理引发的异常,它将被忽略并且不记录(与其他异常不同)。
参数 request (is a Requestobject) – 发起响应的请求
response ( Responseobject) – 正在处理的响应
spider ( Spiderobject) – 此响应针对的蜘蛛
4、process_exception(request, exception, spider)
Scrapyprocess_exception()在下载处理程序或process_request()(来自下载器中间件)引发异常(包括IgnoreRequest异常)时调用
def process_exception(self, request, exception, spider):
# Called when a download handler or a process_request()
# (from other downloader middleware) raises an exception.
# Must either:
# - return None: continue processing this exception
# - return a Response object: stops process_exception() chain
# - return a Request object: stops process_exception() chain
pass
process_exception()应该返回:要么None,一个Response对象,要么一个Request对象。
如果它返回None,Scrapy将继续处理这个异常,执行process_exception()已安装的中间件的任何其他方法,直到没有中间件并且默认的异常处理开始。
如果它返回一个Response对象,process_response() 则启动已安装中间件的方法链,并且 Scrapy 不会打扰调用任何其他process_exception()中间件方法。
如果它返回一个Request对象,则返回的请求将被重新安排为将来下载。这将停止执行 process_exception()中间件的方法,就像返回响应一样。
参数 request (is a Requestobject) – 产生异常的请求
异常(一个Exception对象)——引发的异常
spider ( Spiderobject) – 此请求针对的蜘蛛
scrapy于selenium衔接原理
在知道了下载器中间件的个方法原理后,在弄清楚他的作用位置
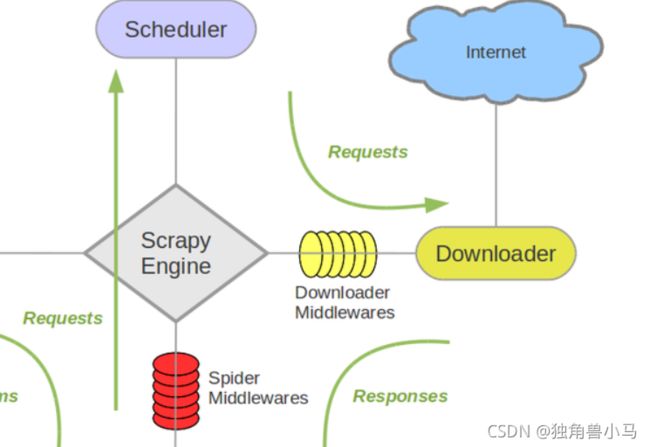
图中可以看到,下载器中间件的位置位于引擎和下载器之间,也就是说:
下载器中间件在下载器和Scrapy引擎之间,每一个request和response都会通过中间件进行处理。
在中间件中,对request进行处理的函数是process_request(request, spider)
所以我们可以根据这个特性,当需要使用selenium时,将请求提交,在通过下载器中间件的时候进行对接,因此不难想到,selenium的真正运用的地方是在下载器中间件中进行
在上述的中间件方法作用中**process_request(request, spider)**的返回值有一条
如果其返回 Response 对象,Scrapy将不会调用 任何 其他的 process_request() 或process_exception() 方法,或相应地下载函数; 其将返回该response。
因此我们就可以借助下载器中间件中的process_request(request, spider)方法来实现selenium操作
实例
Scrapy+Selenium+PhantomJS详解及入门案例(附完整代码)