mysql开窗函数
mysql开窗函数
-
- 1.定义
- 2.语法
- 3.开窗函数的分类
-
- 3.1聚合开窗函数
-
- 总结
- 3.2排序开窗函数
- 3.3其他
1.定义
- 窗口函数为了解决想要即显示聚集前的数据,又要显示聚集后的数据。
- 开窗函数对一组值进行操作,不需要group by 子句对数据进行分组,能够在同一行中同时返回基础行的列和聚合列
注意:开窗函数在mysql8.0后才有
2.语法
函数名(列) over(选项【选项可以为 partition by 列 order by 列】)
over(partition by xxx) 按照xxx所有行进行分组
over(partition by xxx order by aaa) 按照xxx分组,按照aaa排序
3.开窗函数的分类
3.1聚合开窗函数
- 函数名如果是聚合函数,则成为聚合开窗函数
- 语法:聚合函数(列) over(partition by 列 order by 行)
- 常见的聚合函数:sum(),count(),max(),min()…
计算每个学生的及格数
-- 使用聚合函数
select student_id,count(sid) from score where num>=60 group by student_id;
-- 使用开窗函数
select sid,student_id,count(sid) over(partition by student_id order by student_id) 及格数
from score where num>=60;


总结
开窗函数不会修改源数据表的结构,会在表的最后一列添加想要的结果,如果分组存在多行数据,则重复显示
3.2排序开窗函数
- row_number(行号)
- 生成连续的序号,不考虑分数相同
- rank(排名)
- 相同分数的排名一样,后面排名为真正的序号,排名存在跳跃性
- 例如:12225,排名为2的有3个,下一个排名为5,因为前面有4个成绩
- dense_rank(密集排序)
- 相同分数的排名一样,是连续的排名
- 例如:12223,排名为2的有3个,下一个排名为3
- ntile(分组排名)
- ntile有桶的概念
- ntile(6),将总记录划分为6桶,如果是12条记录,就是一桶2条记录
- 排名就是:112233445566
- 排序的结果数字大小只能用于桶与桶之间,桶内部虽然序号相同,但是num不一定相同
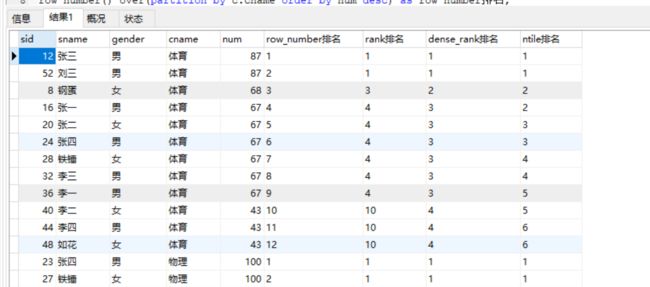
-- 看代码区分关系
select s.sid,s1.sname,s1.gender,c.cname,s.num,
row_number() over(partition by c.cname order by num desc) as row_number排名,
rank() over(partition by c.cname order by num desc) as rank排名,
dense_rank() over(partition by c.cname order by num desc) as dense_rank排名,
ntile(6) over(partition by c.cname order by num desc) as ntile排名
from score as s
join student s1 on s.student_id=s1.sid
left join course c on s.course_id=c.cid;
案例:
-- 查询各科成绩前三名的学生成绩信息
select * from(
select s.sid,s1.sname,s1.gender,c.cname,s.num,
dense_rank() over(partition by c.cname order by num desc) as dense_rank排名
from score as s
join student s1 on s.student_id=s1.sid
left join course c on s.course_id=c.cid) as e
where dense_rank排名<=3;
3.3其他
-
lag(col,n)
统计窗口内向上第n行值
-
lead(col,n)
统计窗口内往下第n行值
这两种函数可以用于同列中相邻行的数据相减操作
案例
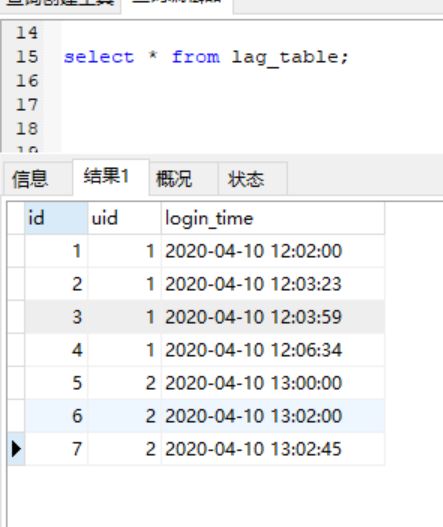
-- 对于下面的数据,对于同一用户(uid)如果在2分钟之内重新登录,则判断为作弊,统计哪些用户有作弊行为,并计算作弊次数
-- 去时间差
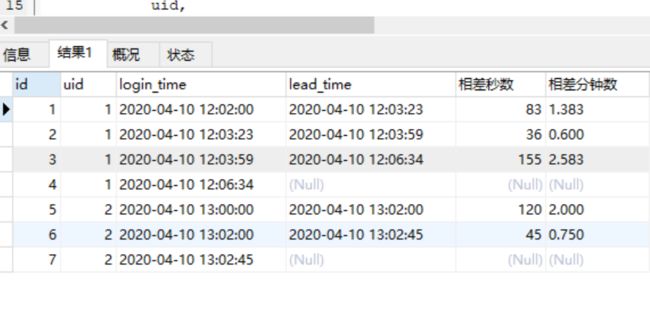
SELECT *,
format(相差秒数 / 60, 3) 相差分钟数
FROM
( SELECT id,
uid,
login_time,
-- 加一列时间
lead (login_time, 1) over ( PARTITION BY uid ORDER BY login_time ) lead_time,
-- 求2列时间的差值
timestampdiff(
SECOND,
login_time,
( lead (login_time, 1) over ( PARTITION BY uid ORDER BY login_time ))
) 相差秒数
FROM lag_table ) as e;
-- 求作弊次数
SELECT uid,count(1) 作弊次数
FROM
( SELECT id,
uid,
login_time,
-- 加一列时间
lead (login_time, 1) over ( PARTITION BY uid ORDER BY login_time ) lead_time,
-- 求2列时间的差值
timestampdiff(
SECOND,
login_time,
( lead (login_time, 1) over ( PARTITION BY uid ORDER BY login_time ))
) 相差秒数
FROM lag_table ) as e
where format(相差秒数 / 60, 3)<=2 group by uid;

-
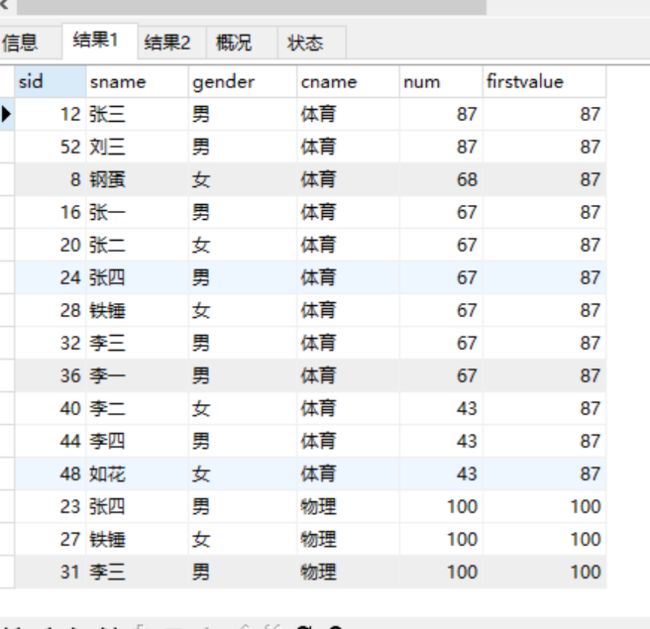
first_value(column)
取分组内排序后,截止当前行,第一个值
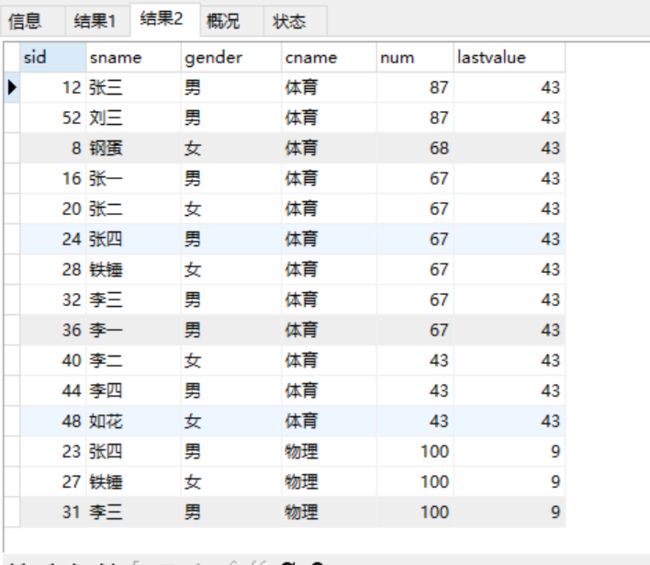
-- 取科目成绩最大值 -- 根据降序,第一个值是最大值 select s.sid,s1.sname,s1.gender,c.cname,s.num, first_value(num) over(partition by c.cname order by num desc) as firstvalue from score s join student s1 on s.student_id=s1.sid left join course c on s.course_id=c.cid;
-
last_value(column)
- 取分组内排序后,截止到当前行,最后一个值
- last_value()默认统计范围是rows between unbounded preceding and current row,就是取当前行数据与当前行之前的数据比较
修改范围: 在order by 后面加上rows between unbounded preceding and unbounded following 即:order by rows between unbounded preceding and unbounded following 就变为:当前分组数据与数据进行比较,取最后一个值 unbounded 无限制的 preceding 分区的当前记录向前的偏移量 current 当前 following 分区的当前记录向后偏移量-- 取科目成绩最小值 -- 根据降序,最后一个值是最小值,要修改范围 select s.sid,s1.sname,s1.gender,c.cname,s.num, last_value(num) over(partition by c.cname order by num desc rows between unbounded preceding and unbounded following) as lastvalue from score s join student s1 on s.student_id=s1.sid left join course c on s.course_id=c.cid;