SQL使用技巧
1、行列转换:
decode(条件,值1,返回值1,值2,返回值2,...值n,返回值n,缺省值);
select decode(sign(变量1-变量2),-1,变量1,变量2) from dual; --取较小值
sign()函数根据某个值是0、正数还是负数,分别返回0、1、-1
例如:
变量1=10,变量2=20
则sign(变量1-变量2)返回-1,decode解码结果为“变量1”,达到了取较小值的目的。
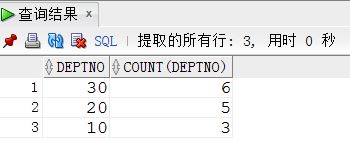
举例:查询emp表中的每个部门的人数?
SELECT sum(decode(deptno,10,1,0)) as 部门10,
sum(decode(deptno,20,1,0)) as 部门20,
sum(decode(deptno,30,1,0)) as 部门30 from emp复制

做个对比:select deptno,count(deptno) from emp group by deptno
2、递归查询的优化
lpad/rpad( string, padded_length, [ pad_string ] )
解释:字符不够的时候向左或者向右填充。
例如:
SQL> select lpad('abcde',10,'x') from dual;
LPAD('ABCDE',10,'X')
xxxxxabcde
SELECT ID, FATHER_ID, NAME, CONNECT_BY_ISLEAF LEAF
FROM T_TREE
START WITH FATHER_ID = 0
CONNECT BY PRIOR ID = FATHER_ID; 复制
解释:CONNECT_BY_ISLEAF 判断该行记录是否为叶子节点,如果是返回1,否则返回0
START WITH FATHER_ID = 0 规定哪一条记录为根节点
CONNECT BY PRIOR ID = FATHER_ID 判断此节点的父节点是哪一条记录
例子:
SELECT LPAD(MENU_NAME,
LENGTHB(MENU_NAME) + LEVEL,
DECODE(CONNECT_BY_ISLEAF, 1, ' | ', '+'))
FROM MENU
START WITH PID = '0'
CONNECT BY PRIOR ID = PID;复制
3、利用分析函数排序和去重
http://blog.csdn.net/haiross/article/details/15336313#comments
分析函数是什么? 分析函数是Oracle专门用于解决复杂报表统计需求的功能强大的函数,它可以在数据中进行分组然后计算基于组的某种统计值,并且每一组的每一行都可以返回一个统计值。
分析函数和聚合函数的不同之处是什么? 普通的聚合函数用group by分组,每个分组返回一个统计值,返回的字段名只能是分组名。而分析函数采用partition by分组,并且每组每行都可以返回一个统计值,返回的字段名可以是每个字段,因为是对应到记录的,所以没有关系。
分析函数的形式 分析函数带有一个开窗函数over(),包含三个分析子句:分组(partition by), 排序(order by), 窗口(rows) ,他们的使用形式如下:over(partition by xxx order by yyy rows between zzz)
开窗函数over()包含三个分析子句:分组子句(partition by), 排序子句(order by), 窗口子句(rows) 窗口就是分析函数分析时要处理的数据范围,就拿sum来说,它是sum窗口中的记录而不是整个分组中的记录,因此我们在想得到某个栏位的累计值时,我们需要把窗口指定到该分组中的第一行数据到当前行, 如果你指定该窗口从该分组中的第一行到最后一行,那么该组中的每一个sum值都会一样,即整个组的总和。
OVER(PARTITION BY DEPTNO ORDER BY ENAME ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW):当前组第一行到当前行的汇总
OVER(PARTITION BY DEPTNO ORDER BY ENAME ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING):当前行到最后一行的汇总
OVER(PARTITION BY DEPTNO ORDER BY ENAME ROWS BETWEEN 1 PRECEDING AND CURRENT ROW):当前行的上一行(rownum-1)到当前行的汇总
OVER(PARTITION BY DEPTNO ORDER BY ENAME ROWS BETWEEN 1 PRECEDING AND 2 FOLLOWING):当前行的上一行(rownum-1)到下两行(rownum+2)的汇总复制
而无论是否省略分组子句,如下结论都是成立的:
1、窗口子句不能单独出现,必须有order by子句时才能出现。
2、当省略窗口子句时: a) 如果存在order by则默认的窗口是unbounded preceding and current row --当前组的第一行到当前行,即在当前组中,第一行到当前行,这里强调一下,如果partition by字段和order by 字段一样的话,这个order by不生效,相当于省略了order by
b) 如果同时省略order by则默认的窗口是unbounded preceding and unbounded following --整个组
两个order by的执行时机
分析函数(以及与其配合的开窗函数over())是在整个sql查询结束后(sql语句中的order by的执行比较特殊)再进行的操作, 也就是说sql语句中的order by也会影响分析函数的执行结果:
a) 两者一致:如果sql语句中的order by满足与分析函数配合的开窗函数over()分析时要求的排序,即sql语句中的order by子句里的内容和开窗函数over()中的order by子句里的内容一样,那么sql语句中的排序将先执行,分析函数在分析时就不必再排序; b) 两者不一致:如果sql语句中的order by不满足与分析函数配合的开窗函数over()分析时要求的排序,即sql语句中的order by子句里的内容和开窗函数over()中的order by子句里的内容不一样,那么sql语句中的排序将最后在分析函数分析结束后执行排序。
常用的分析函数:
1、row_number() over(partition by ... order by ...) 为每一条记录返回一个唯一的值。当碰到相同数据时,排名按照记录集中记录的顺序依次递增,现实情景为:个人在分组内的排名 2、rank() over(partition by ... order by ...) 得到每条记录在数据中的排名,排名不跳跃 3、dense_rank() over(partition by ... order by ...) 得到每条记录在数据中的排名,排名跳跃 4、count() over(partition by ... order by ...) 每个分组中,某个字段的统计 5、max() over(partition by ... order by ...) 6、min() over(partition by ... order by ...) 7、sum() over(partition by ... order by ...) 8、avg() over(partition by ... order by ...) 9、first_value() over(partition by ... order by ...) 得到第一个记录值 10、last_value() over(partition by ... order by ...) 得到最后一个记录值 11、lag() over(partition by ... order by ...) lag函数可以在一次查询中取出同一字段的前n行的数据
12、lead() over(partition by ... order by ...) lead函数可以在一次查询中取出同一字段的后n行的值
lag(arg1,arg2,arg3) 第一个参数是列名, 第二个参数是偏移的offset, 第三个参数是超出记录窗口时的默认值。
select id,name,lag(name,1,0) over(order by id) from kkk;
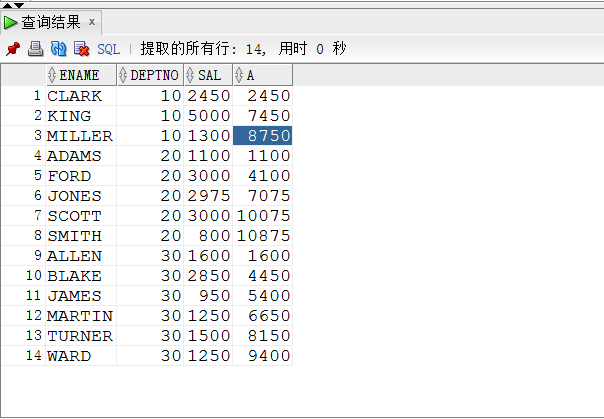
例子:select ename,deptno,sal,sum(sal) over(partition by deptno order by ename) as A from emp
去重:
1、利用rowid的唯一性查询或删除重复数据
select ROWNUM,ROWID,d1.* from dept2 d1 where d1.rowid=(select min(d2.rowid) from dept2 d2 where d2.deptno=d1.deptno);复制
2、给定重复行序号并去重
SELECT FWZL
FROM (SELECT FWZL,
ROW_NUMBER() OVER(PARTITION BY FWZL ORDER BY ID DESC) RN
FROM T_FWXX) F
WHERE F.RN = 1复制
4、求占比、小计和总计
分析函数RATIO_TO_REPORT 用来计算当前记录的指标expr占开窗函数over中包含记录的所有同一指标的百分比. 这里如果开窗函数的统计结果为null或者为0,就是说占用比率的被除数为0或者为null, 则得到的结果也为0. 开窗条件query_partition_clause决定被除数的值, 如果用户忽略了这个条件, 则计算查询结果中所有记录的汇总值. 用户不能使用其他分析函数或者ratio_to_report作为分析函数ratio_to_report的参数expr, 也就是说这个函数
百分比(求这个字段值占整组的百分比):select deptno,ename,empno,round(RATIO_TO_REPORT(sal) OVER(PARTITION BY deptno)*100,1) 百分比 from emp

rollup()与cube():排列组合分组
1)、group by rollup(a, b, c): 首先会对(a、b、c)进行group by, 然后再对(a、b)进行group by, 其后再对(a)进行group by, 最后对全表进行汇总操作。
2)、group by cube(a, b, c): 则首先会对(a、b、c)进行group by, 然后依次是(a、b),(a、c),(a),(b、c),(b),(c), 最后对全表进行汇总操作。
ROLLUP,是GROUP BY子句的一种扩展,可以为每个分组返回小计记录以及为所有分组返回总计记录。
CUBE,也是GROUP BY子句的一种扩展,可以返回每一个列组合的小计记录,同时在末尾加上总计记录。
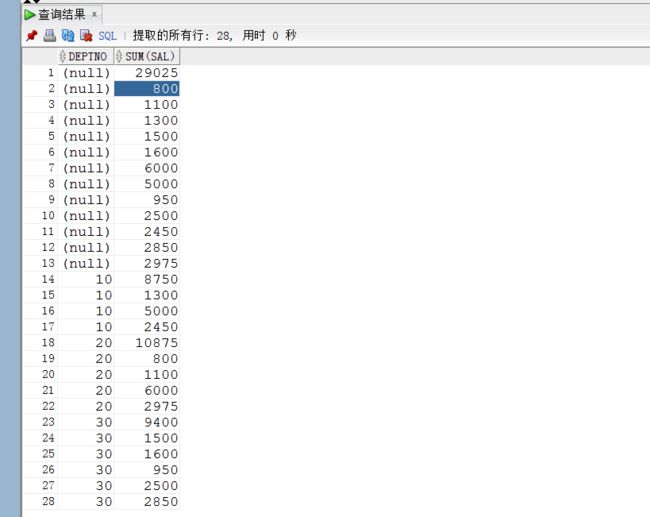
求每个分组的小计和总计:select deptno,sal,sum(sal) from emp group by rollup(deptno,sal)

求每一个列的组合的小计记录:select deptno,sum(sal) from emp group by cube(deptno,sal)
聚合函数(within group语法):
select rank(1500) within group (order by sal desc) "rank of 1500" from emp;
解释:如果存在一条记录,这条记录的salary字段值为1500。那么将该条记录插入emp表中后,按照sal字段降序排列后,该条记录的序号为多少?
可以使用within group关键字的函数有rank,dense_rank,PERCENT_RANK,PERCENTILE_CONT,PERCENTILE_DISC等

5、单条记录插入多表
原理:利用一个insert all 语法:insert all when .. then
INSERT ALL WHEN LOCALE = 1 THEN INTO EMPLOYEE1(ID, LOCALE, NAME, AGE, GENDER, CODE) VALUES (ID, LOCALE, NAME, AGE, GENDER, CODE)
WHEN LOCALE = 32 THEN INTO EMPLOYEE2(ID, LOCALE, NAME, AGE, GENDER, CODE) VALUES(ID, LOCALE, NAME, AGE, GENDER, CODE)
insert all into table values()
into table values()
6、Merge的使用
解释:DML语句,适用于批量处理
MERGE INTO table_name alias1 USING (table|view|sub_query) alias2 ON (join condition) WHEN MATCHED THEN UPDATE table_name SET col1 = col_val1, col2 = col2_val where 条件 WHEN NOT MATCHED THEN INSERT (column_list) VALUES (column_values) where 条件;
MERGE INTO EMPLOYEE E
USING (SELECT * FROM EMPLOYEE1) E1
ON (E.NAME = E1.NAME)
WHEN MATCHED THEN
UPDATE SET E.CODE = E1.CODE, E.AGE = E1.AGE
WHEN NOT MATCHED THEN
INSERT (E.ID, E.LOCALE, E.NAME, E.AGE, E.GENDER, E.CODE) VALUES(E1.ID, E1.LOCALE, E1.NAME, E1.AGE, E1.GENDER, E1.CODE);
备注:对两张表的两个字段相匹配,如果匹配上了就做更新操作,否则就做插入操作。
7、KEEP的使用
keep是Oracle下的另一个分析函数,他的用法不同于通过over关键字指定的分析函数,可以用于这样一种场合下:取同一个分组下以某个字段排序后,对指定字段取最小或最大的那个值。
一般写法是 MIN [ MAX ] (A) KEEP(DENSE_RANK FIRST [ LAST ] ORDER BY B),这里引用别人说的明的解释一下:
DENSE_RANK
功能描述:根据ORDER BY子句中表达式的值,从查询返回的每一行,计算它们与其它行的相对位置。组内的数据按ORDER BY子句排序,然后给每一行赋一个号,从而形成一个序列,该序列从1开始,往后累加。每次ORDER BY表达式的值发生变化时,该序列也随之增加。有同样值的行得到同样的数字序号(认为null时相等的)。密集的序列返回的时没有间隔的数。
FIRST
功能描述:从DENSE_RANK返回的集合中取出排在最前面的一个值的行(可能多行,因为值可能相等),因此完整的语法需要在开始处加上一个集合函数以从中取出记录。
LAST
功能描述:从DENSE_RANK返回的集合中取出排在最后面的一个值的行(可能多行,因为值可能相等),因此完整的语法需要在开始处加上一个集合函数以从中取出记录。
所以默认排序下,FIRST可以理解是取小值,LAST取大值。而前面的MIN或者MAX则是在KEEP的结果集中取某一字段的最大值或最小值。
keep和普通分析函数的区别:普通的分析函数只是列出分组后的记录,而对每一个组的记录进行统计分析。
keep对分组内的函数通过order by和max(),min()选取某个字段的值。可以理解成这里的keep就是sum() groud by deptno 前的sum()那样
实例:取出各个部门薪资最高的员工编号
1、select deptno,empno,sal,max(empno) keep(dense_rank first order by sal desc) over(partition by deptno) from emp2
2、select deptno,max(empno) keep(dense_rank first order by sal desc) from emp2 group by deptno
解释:按deptno分组,再对分组中的sal降序,取出第一个sal的员工号

8、SQL查询正则表达式的使用
ORACLE中的支持正则表达式的函数主要有下面四个: 1,REGEXP_LIKE :与LIKE的功能相似
select * from emp where regexp_like(empno,'7[0-9]{2}9') 2,REGEXP_INSTR :与INSTR的功能相似
REGEXP_INSTR
6个参数
第一个是输入的字符串
第二个是正则表达式
第三个是标识从第几个字符开始正则表达式匹配。(默认为1)
第四个是标识第几个匹配组。(默认为1)
第五个是指定返回值的类型,如果该参数为0,则返回值为匹配位置的第一个字符,如果该值为非0则返回匹配值的最后一个位置。
第六个是是取值范围:
i:大小写不敏感;
c:大小写敏感;
n:点号 . 不匹配换行符号;
m:多行模式;
x:扩展模式,忽略正则表达式中的空白字符。
SELECT REGEXP_INSTR(a,'[0-9]+') AS A FROM test_reg_substr;
3,REGEXP_SUBSTR :与SUBSTR的功能相似
REGEXP_SUBSTR函数格式如下:
function REGEXP_SUBSTR(String, pattern, position, occurrence, modifier) __srcstr :需要进行正则处理的字符串 __pattern :进行匹配的正则表达式 __position :起始位置,从第几个字符开始正则表达式匹配(默认为1) __occurrence :标识第几个匹配组,默认为1 __modifier :模式('i'不区分大小写进行检索;'c'区分大小写进行检索。默认为'c'。)
- --1、查询使用正则分割后的第一个值,也就是34
- SELECT REGEXP_SUBSTR('34,56,-23','[^,]+',1,1,'i') AS STR FROM DUAL;
- --结果是:34
- --2、查询使用正则分割后的最后一个值,也就是-23
- SELECT REGEXP_SUBSTR('34,56,-23','[^,]+',1,3,'i') AS STR FROM DUAL;
- --结果是:-23
4,REGEXP_REPLACE :与REPLACE的功能相似
9、常见函数
TRUNC:截取函数
EXTRACT:用于从一个date或者interval类型中截取到特定的部分
NVL
DECODE
length:字符长度
lengthb:字节长度
ASCII
INITCAP:首字母大写
SOUNDEX:返回由四个字符组成的代码 (SOUNDEX) 以评估两个字符串的相似性
MONTHS_BETWEEN
ADD_MONTHS
NEXT_DAY
LAST_DAY
ROUND:函数用于把数值字段舍入为指定的小数位数
10、分页函数
--普通写法
SELECT AA.FWZL, AA.FWTYBH
FROM (SELECT A.FWZL, A.FWTYBH, ROWNUM RN
FROM (SELECT F.FWZL, F.FWTYBH FROM FW F ORDER BY F.FWTYBH DESC) A
WHERE ROWNUM <= 120020) AA
WHERE AA.RN > 120000;复制
--rowid写法
SELECT /*+ ROWID(FW) */ FW.FWZL, FW.FWTYBH
FROM FW FW,
(SELECT AA.RID, AA.RN
FROM (SELECT A.RID, ROWNUM RN
FROM (SELECT /*+ index(F IDX_FW_FWTYBH) */
ROWID RID
FROM FW F
ORDER BY F.FWTYBH DESC) A
WHERE ROWNUM <= 120020) AA
WHERE AA.RN > 120000) B
WHERE FW.ROWID = B.RID;复制