Elasticsearch7.9集群部署,head插件,canal同步mysql数据到es,亲自测试,无坑
Elasticsearch集群部署
1、服务器规划
10.4.7.11 node1
10.4.7.12 node2
10.4.7.13 node3
1. 集群相关
一个运行中的 Elasticsearch 实例称为一个节点,而集群是由一个或者多个拥有相同 cluster.name 配置的
节点组成,它们共同承担数据和负载的压力。当有节点加入集群中或者从集群中移除节点时,集群将会重新平均
分布所有的数据。当一个节点被选举成为主节点时,它将负责管理集群范围内的所有变更,例如增加、删除索引,
或者增加、删除节点等。而主节点并不需要涉及到文档级别的变更和搜索等操作,所以当集群只拥有一个主节点
的情况下,即使流量的增加它不会成为瓶颈。 任何节点都可以成为主节点。我们的示例集群就只有一个节点,所
以它同时也成为了主节点。作为用户,我们可以将请求发送到 集群中的任何节点 ,包括主节点。 每个节点都知
道任意文档所处的位置,并且能够将我们的请求直接转发到存储我们所需文档的节点。 无论我们将请求发送到哪
个节点,它都能负责从各个包含我们所需文档的节点收集回数据,并将最终结果返回給客户端。 Elasticsearch
对这一切的管理都是透明的。
解释:
status 字段指示着当前集群在总体上是否工作正常。
它的三种颜色含义如下:
green:所有的主分片和副本分片都正常运行。
yellow:所有的主分片都正常运行,但不是所有的副本分片都正常运行。
red:有主分片没能正常运行
1. 分片:
一个分片是一个底层的工作单元 ,它仅保存了全部数据中的一部分。一个分片是一个 Lucene 的实例,它本身
就是一个完整的搜索引擎。我们的文档被存储和索引到分片内,但是应用程序是直接与索引而不是与分片进行交互。
Elasticsearch 是利用分片将数据分发到集群内各处的。分片是数据的容器,文档保存在分片内,分片又被分配到
集群内的各个节点里。 当你的集群规模扩大或者缩小时, Elasticsearch 会自动的在各节点中迁移分片,使得数据
仍然均匀分布在集群里。
一个分片可以是 主 分片或者 副本 分片。 索引内任意一个文档都归属于一个主分片,所以主分片的数目决定着
索引能够保存的最大数据量。一个索引必须创建主分片,副本分片可以没有。
分片和主流关系型数据库的表分区的概念有点类似。
2. 副本:
一个副本分片只是一个主分片的拷贝。副本分片作为硬件故障时保护数据不丢失的冗余备份,并为搜索和返回文档等读操作提供服务。
如果主分片有3个,那么一个副本replica就对应有1X3=3个replica shard副本分片。
副本分片数量计算公式 = 副本数量repilca num X 主分片数量primary shard num
在索引建立的时候就已经确定了主分片数,但是副本分片数可以随时修改。也就是说分片数量不允许修改,副本数量可以修改。
3. 分片与副本的关系:
每个主分片(primary shard)不会和副本分片(replica shard)存在于同一个节点中,有效的保证es的数据高可用性。
例如1:比如一个索引有3个分片和1副本,那么一共就有3*2=6个分片,3个是主分片,3个是副本分片,每个主分片都会对应一个副本分片。
例如2:只有2个节点,但是有3个分片和2个副本,这样的情况就会导致分片无法完全分配,因为主分片和副本分片不能存在于同一个节点中。
#三台都要执行初始化配置
[root@localhost ~]# vim /etc/sysctl.conf
vm.max_map_count=655360
net.ipv4.tcp_syncookies=1
net.ipv4.tcp_tw_reuse=1
net.ipv4.tcp_tw_recycle=1
net.ipv4.tcp_fin_timeout=30
net.ipv4.ip_forward=1
[root@localhost ~]# sysctl -p #修改完执行使其生效
[root@localhost ~]# vim /etc/security/limits.conf
#新增内容如下:
* soft nofile 655360
* hard nofile 655360
* soft memlock unlimited
* hard memlock unlimited
* soft nproc 65535
* hard nproc 65535
* - as unlimited
2.安装es
[root@localhost ~]# wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.9.3-linux-x86_64.tar.gz
[root@localhost ~]# mkdir -p /app /data/elasticsearch
[root@localhost ~]# tar -zxf elasticsearch-7.9.3-linux-x86_64.tar.gz -C /app
[root@localhost app]# ln -sv /app/elasticsearch-7.9.3 /app/elasticsearch
#修改配置文件
[root@localhost elasticsearch]# vi /app/elasticsearch/config/elasticsearch.yml
cluster.name: es-cluster #集群名称
node.name: node1
network.host: 10.4.7.11
http.port: 9200
transport.tcp.port: 9300
discovery.seed_hosts: ["10.4.7.11", "10.4.7.12", "10.4.7.21"]
cluster.initial_master_nodes: ["10.4.7.11", "10.4.7.12", "10.4.7.21"]
discovery.zen.minimum_master_nodes: 1
indices.query.bool.max_clause_count: 10240
cluster.max_shards_per_node: 10000
gateway.recover_after_nodes: 1
bootstrap.memory_lock: true
bootstrap.system_call_filter : false
#开启x-pack安全验证
xpack.security.enabled: true
xpack.security.audit.enabled: true
xpack.security.transport.ssl.enabled: true
xpack.security.transport.ssl.verification_mode: certificate
xpack.security.transport.ssl.keystore.path: elastic-certificates.p12
xpack.security.transport.ssl.truststore.path: elastic-certificates.p12
path.data: /data/elasticsearch
path.logs: /app/elasticsearch/logs
#调整内存大小
[root@localhost elasticsearch]# egrep -v "#|^$" /app/elasticsearch/config/jvm.options|head -2
-Xms2g
-Xmx2g
#修改elasticsearch自带jdk的路径变量,在文件最前面
[root@localhost app]# vi /app/elasticsearch/bin/elasticsearch
export JAVA_HOME=/app/elasticsearch/jdk
export PATH=$JAVA_HOME/bin:$PATH
#修改配置文件中node.name并且授权es用户目录权限
[root@localhost app]# useradd es && chown -R es.es /app/elasticsearch* && chown -R es.es /data/elasticsearch
# 开启x-pack安全验证
#生成证书
[root@localhost ~]# /app/elasticsearch/bin/elasticsearch-certutil cert -out /app/elasticsearch/config/elastic-certificates.p12 -pass ""
#以es用户启动服务
su -c '/app/elasticsearch/bin/elasticsearch -d' es
3.node2,node3安装
[root@localhost ~]# mkdir -p /app /data/elasticsearch
[root@localhost ~]# scp -rp 10.4.7.11:/app/elasticsearch-7.9.3/ /app/
[root@localhost ~]# ln -sv /app/elasticsearch-7.9.3 /app/elasticsearch
[root@localhost ~]# useradd es && chown -R es.es /app/elasticsearch* && chown -R es.es /data/elasticsearch
#node2,node3启动es
[root@localhost ~]# su -c '/app/elasticsearch-7.9.3/bin/elasticsearch -d' es
4.三台都起来了,设置密码,这里是手动设置指定的密码,如果三台都没起来,设置密码会报错,
下面都是一些用户设置密码,统一设置密码为:Elastic123
[root@k8s-node1 config]# /app/elasticsearch/bin/elasticsearch-setup-passwords interactive
设置集群分片最大数
[root@localhost ~]curl -XPUT -u elastic:Elastic123 -H "Content-Type: application/json" http://10.4.7.11:9200/_cluster/settings -d '{"transient": {"cluster": {"max_shards_per_node":10000}}}'
5.安装head插件,只需要再集群之间任何一台安装就可以了
[root@localhost ~]# curl -sL -o /etc/yum.repos.d/khara-nodejs.repo https://copr.fedoraproject.org/coprs/khara/nodejs/repo/epel-7/khara-nodejs-epel-7.repo
[root@localhost ~]# yum install -y nodejs nodejs-npm
[root@localhost ~]# npm --version
[root@localhost ~]# node --version
6. 安装grunt ,grunt是一个很方便的构建工具,可以进行打包压缩,测试,执行,5.0里的
head插件就是通过grunt启动的,
下载地址:https://github.com/mobz/elasticsearch-head
下载zip包
# 进入 elasticsearch-head 文件夹,执行命令
[root@localhost ~]# unzip elasticsearch-head-master.zip
[root@localhost ~]# cd elasticsearch-head-master/
#设置淘宝源,安装会快点
[root@localhost elasticsearch-head-master]# npm config set registry http://registry.npm.taobao.org
[root@localhost elasticsearch-head-master]# npm install -g grunt-cli
[root@localhost elasticsearch-head-master]# npm install
7. Gruntfile.js 文件
修改 elasticsearch-head 目录下的 Gruntfile.js 文件,在 options 属性内增加 hostname,设置为 0.0.0.0
connect: {
server: {
options: {
hostname: '0.0.0.0', #添加这行,注意逗号。
port: 9100,
base: '.',
keepalive: true
}
}
}
#修改head服务器连接es地址,添加es集群的任何节点。
[root@localhost elasticsearch-head-master]# vi _site/app.js
原来
this.base_uri = this.config.base_uri || this.prefs.get("app-base_uri") || "http://localhost:9200";
修改localhost为:
this.base_uri = this.config.base_uri || this.prefs.get("app-base_uri") || "http://10.4.7.21:9200";
8.运行head启动node.js,必须在elasticsearch-head-master目录下
[root@localhost elasticsearch-head-master]# nohup grunt server > grunt.log 2>&1 &
9.es各个节点在elasticsearch.yml添加下面内容。
[root@localhost app]# vi /app/elasticsearch/config/elasticsearch.yml
#添加es-head可以跨域连接
http.cors.enabled: true
http.cors.allow-origin: "*"
#配置es-head验证Authorization
http.cors.allow-methods: OPTIONS, HEAD, GET, POST, PUT, DELETE
http.cors.allow-headers: Authorization,X-Requested-With,X-Auth-Token,Content-Type, Content-Length
10,重启es集群各个节点
#配置es启动服务脚本
[root@localhost ~]# ps aux|grep elasticsearch | grep -v grep |awk '{print $2}'|xargs kill -9 2>/dev/null
[root@localhost ~]# su -c '/app/elasticsearch-7.9.3/bin/elasticsearch -d' es
11.浏览器登录es-head,配置es什么节点就访问什么ip,使用用户密码验证
http://10.4.7.21:9100/?auth_user=elastic&auth_password=Elastic123
12.如果记不得之前的账号,可以创建新的账号,具有超级用户内置角色。
#创建用户
[root@localhost opt]# /app/elasticsearch/bin/elasticsearch-users useradd admin -p Admin123 -r superuser
[root@localhost opt]# /app/elasticsearch/bin/elasticsearch-users list
admin : superuser
[root@localhost opt]# curl -u admin:Admin123 http://10.4.7.11:9200/_nodes/process?pretty
#基本操作
查看集群状态
[root@localhost ~]# curl -u elastic:Elastic123 -XGET http://10.4.7.11:9200/_cat/health?v
#查看节点状态
[root@localhost ~]# curl -u elastic:Elastic123 -XGET http://10.4.7.11:9200/_cat/nodes?v
#查看索引状态
[root@localhost ~]# curl -u elastic:Elastic123 -XGET http://10.4.7.11:9200/_cat/indices?v
#查看es集群
[root@localhost ~]# curl -u elastic:Elastic123 -XGET http://10.4.7.11:9200/_cluster/health?pretty
{
"cluster_name" : "es-cluster",
"status" : "green", #状态为green
"timed_out" : false,
"number_of_nodes" : 3,
"number_of_data_nodes" : 3,
"active_primary_shards" : 4, #4个主分片
"active_shards" : 10, #10个分片
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 0,
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 100.0
}
#查看分片
[root@localhost ~]# curl -u elastic:Elastic123 -XGET http://10.4.7.11:9200/_cat/shards
13.备份security索引,担心删除,无法登录使用。
#查看以前的security的索引
[root@localhost nodes]# curl -u admin:Admin123 -XGET http://10.4.7.11:9200/.security-*
#删除security索引
[root@localhost nodes]# curl -u admin:Admin123 -X DELETE http://10.4.7.11:9200/.security-*
#创建备份目录,每个es集群节点都要添加。
[root@localhost ~]# mkdir -p /data/es-backups/
[root@localhost ~]# chown -R es.es /data/es-backups/
#添加内容到配置文件里
[root@localhost ~]# vi /app/elasticsearch/config/elasticsearch.yml
#备份配置目录
path.repo: ["/data/es-backups/"]
#重启es各个节点
[root@localhost ~]# ps aux|grep elasticsearch | grep -v grep |awk '{print $2}'|xargs kill -9 2>/dev/null
[root@localhost ~]# su -c '/app/elasticsearch-7.9.3/bin/elasticsearch -d' es
14.安装es的分词器
安装包地址:https://github.com/medcl/elasticsearch-analysis-ik/releases,
需要注意
要下载与自己版本一致的,版本不一致的可能会有问题。
在es的安装地址下,plugins文件夹中创建目录ik
解压安装包到ik文件夹中
https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.9.3/elasticsearch-analysis-ik-7.9.3.zip
#安装ik分词器插件,先在10.4.7.11上操作,然后拷贝es集群其他节点。
[root@localhost ~]# wget https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.9.3/elasticsearch-analysis-ik-7.9.3.zip
[root@localhost ~]# mkdir /app/elasticsearch/plugins/analysis-ik/
[root@localhost ~]# cp /root/elasticsearch-analysis-ik-7.9.3.zip /app/elasticsearch/plugins/analysis-ik
[root@localhost ~]# cd /app/elasticsearch/plugins/analysis-ik
[root@localhost analysis-ik]# unzip elasticsearch-analysis-ik-7.9.3.zip
[root@localhost analysis-ik]# chown -R es.es /app/elasticsearch*
#拷贝
[root@localhost plugins]# scp -rp /app/elasticsearch/plugins/analysis-ik 10.4.7.12:/app/elasticsearch/plugins/
[root@localhost plugins]# scp -rp /app/elasticsearch/plugins/analysis-ik 10.4.7.21:/app/elasticsearch/plugins/
#重启es各个节点
[root@localhost ~]# chown -R es.es /app/elasticsearch*
[root@localhost ~]# ps aux|grep elasticsearch | grep -v grep |awk '{print $2}'|xargs kill -9 2>/dev/null
[root@localhost ~]# su -c '/app/elasticsearch/bin/elasticsearch -d' es
#查看日志,会有下面信息输出
[root@localhost ~]# tailf -200 /app/elasticsearch/logs/es-cluster.log
[2022-01-21T03:59:00,462][INFO ][o.e.p.PluginsService ] [node1] loaded module [x-pack-security]
[2022-01-21T03:59:00,462][INFO ][o.e.p.PluginsService ] [node1] loaded module [x-pack-sql]
[2022-01-21T03:59:00,464][INFO ][o.e.p.PluginsService ] [node1] loaded module [x-pack-stack]
[2022-01-21T03:59:00,464][INFO ][o.e.p.PluginsService ] [node1] loaded module [x-pack-voting-only-node]
[2022-01-21T03:59:00,466][INFO ][o.e.p.PluginsService ] [node1] loaded module [x-pack-watcher]
[2022-01-21T03:59:00,467][INFO ][o.e.p.PluginsService ] [node1] loaded plugin [analysis-ik] #这里插件
ik分词器提供3种分词模式
1: default : 把需要分词的文本一个词一个词来拆分。
2:ik_smart :将需要分词的文本做最大颗粒的拆分。
3:ik_max_word:将需要分词的文本最小颗粒的拆分,尽量分更多的词。
#测试分词器的,
[root@localhost opt]# curl -u elastic:Elastic123 -H "Content-Type: application/json" -XGET http://10.4.7.12:9200/_analyze?pretty -d '
{
"text": "美国留给?", # 对这个text类型文本进行分词
"analyzer": "ik_max_word" #指定ik分词模式
}'
{
"tokens" : [
{
"token" : "美国",
"start_offset" : 0,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "留给",
"start_offset" : 2,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 1
}
]
}
#对于ik分词器是:索引时使用ik_max_word将搜索内容进行最细颗粒度分词,搜索时使用ik_smart最粗颗粒分词,提高搜索精确度。
#下面创建一个xc_course索引库,定义映射关系。相当于mysql的表结构
[root@localhost ~]# curl -u elastic:Elastic123 -H "Content-Type: application/json" -XPOST http://10.4.7.11:9200/xc_course/doc/ -d '
{
"properties": {
"name": {
"type": "text", #name字段类型为文本
"analyzer": "ik_max_word", #指定name的字段索引分词器
"search_analyzer": "ik_smart" #指定name的字段搜索分词器
},
"description": {
"type": "text"
},
"studymodel": {
"type": "keyword" #精确匹配,不进行分词。
},
"pic": {
"type": "text",
"index": false #指定pic字段关闭索引。
}
}
}'
#对xc_source索引添加文档
[root@localhost ~]# curl -u elastic:Elastic123 -H "Content-Type: application/json" -XPOST http://10.4.7.11:9200/xc_course/doc/ -d '
{
"name":"Bootstrap开发框架",
"description":"Bootstrap是由Twitter推出的一个前台页面开发框架,在行业之中使用较为广泛。此开发框架包含了大量的CSS、JS程序代码,可以帮助开发者(尤其是不擅长页面开发的程序人员)轻松的实现一个不受浏览器限制的精美界面效果。",
"studymodel":"201001",
"pic": "haha"
}'
15.安装canal,同步mysql数据到es,mysql必须开启binlog日志,canal-deployer服务相当于slave节点,canal-deployer会通过io线程去读取mysql的binlog日志。
#先安装mysql
[root@localhost ~]# cat mysql_install.sh
#!/bin/bash
id mysql 2>&1 >/dev/null
if [ $? -eq 0 ];then
echo "mysql user is exists"
else
useradd -s /sbin/nologin -M mysql
fi
rm -rf /home/mysql_data
rm -rf /usr/local/mysql
cd /usr/local/src
wget http://dev.mysql.com/get/Downloads/MySQL-5.7/mysql-5.7.17-linux-glibc2.5-x86_64.tar.gz
tar -zxf mysql-5.7.17-linux-glibc2.5-x86_64.tar.gz
mv mysql-5.7.17-linux-glibc2.5-x86_64 /usr/local/mysql
mkdir -pv /home/mysql_data/{data,logs,tmp,mysql-bin}
chown -R mysql.mysql /usr/local/mysql
chown -R mysql.mysql /home/mysql_data/
cat >/etc/my.cnf <
port = 3306
socket = /usr/local/mysql/mysql.sock
default_character_set=utf8
[mysql]
prompt="\u@\h [\d]>"
no-auto-rehash
default_character_set=utf8
[mysqld]
character_set_server = utf8
user = mysql
basedir = /usr/local/mysql
datadir = /home/mysql_data/data
tmpdir = /home/mysql_data/tmp
port = 3306
server-id = 26
socket = /usr/local/mysql/mysql.sock
event_scheduler = 0
open_files_limit = 65535
log_error = /home/mysql_data/logs/error.log
binlog_format = row
log-bin = /home/mysql_data/mysql-bin/mysqlbin-log
max_binlog_size = 1024M
sync_binlog = 1
expire_logs_days = 7
EOF
/usr/local/mysql/bin/mysqld --defaults-file=/etc/my.cnf --initialize
\cp -rf /usr/local/mysql/support-files/mysql.server /etc/init.d/mysqld
/etc/init.d/mysqld start
chkconfig --add mysqld
chkconfig mysqld on
#执行脚本
[root@localhost ~]# chmod +x mysql_install.sh
[root@localhost ~]# ./mysql_install.sh
[root@localhost ~]# echo "export PATH=$PATH:/usr/local/mysql/bin" >> /etc/profile
[root@localhost ~]# source /etc/profile
.修改初始密码
查看初始密码:
[root@localhost ~]# grep "password" /home/mysql_data/logs/error.log
2017-05-08T07:49:40.620503Z 1 [Note] A temporary password is generated for root@localhost: q=8jh*JpNar)
初始密码为: q=8jh*JpNar) 每次初始化密码都不会相同;
[root@localhost ~]# mysql -uroot -p -S /usr/local/mysql/mysql.sock 初始密码
mysql > alter user 'root'@'localhost' identified by '123456'; #修改密码为:123456
mysql > flush privileges;
#接下来需要创建一个拥有从库权限的账号,用于订阅binlog
# 这里创建的账号为canal,并且设置密码
root@localhost [(none)]>GRANT all privileges ON *.* TO 'canal'@'%' identified by 'canal123';
Query OK, 0 rows affected, 1 warning (0.01 sec)
root@localhost [statement]>GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'root'@'127.0.0.1' identified by 'root123';
Query OK, 0 rows affected, 1 warning (0.02 sec)
root@localhost [(none)]>FLUSH PRIVILEGES;
Query OK, 0 rows affected (0.04 sec)
#创建好测试用的数据库statement,之后创建一张表track
建表语句如下:
root@localhost [(none)]>create database statement;
Query OK, 1 row affected (0.01 sec)
root@localhost [(none)]>use statement
root@localhost [statement]>CREATE TABLE `user` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`name` varchar(256) COLLATE utf8mb4_unicode_ci NOT NULL,
`detail` text COLLATE utf8mb4_unicode_ci NOT NULL,
`age` int(3) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;
#插入一些数据,用于后面测试
root@localhost [statement]>insert into user values(1,"xixi","货在哪过",33);
Query OK, 1 row affected (0.01 sec)
root@localhost [statement]>insert into user values(2,"gege","你是谁",34);
Query OK, 1 row affected (0.01 sec)
root@localhost [statement]>insert into user values(3,"haha","万岁啊",35);
Query OK, 1 row affected (0.02 sec)
#安装kibana
[root@localhost opt]# wget https://artifacts.elastic.co/downloads/kibana/kibana-7.9.2-linux-x86_64.tar.gz
[root@localhost opt]# tar -zxf kibana-7.9.2-linux-x86_64.tar.gz
[root@localhost opt]# ln -sv kibana-7.9.2-linux-x86_64 kibana
[root@localhost opt]# cd kibana/config/
[root@localhost config]# cat kibana.yml |egrep -v '^#|^$'
server.port: 5601
server.host: "10.4.7.22"
server.name: "es-kibana"
elasticsearch.hosts: ["http://10.4.7.11:9200","http://10.4.7.12:9200","http://10.4.7.21:9200"]
elasticsearch.username: "elastic"
elasticsearch.password: "Elastic123"
#启动kibana
[root@localhost opt]# nohup ./kibana/bin/kibana --allow-root >/dev/null &
访问 kibana 页面,输入es账号:"elastic" ,密码: "Elastic123" 登入
http://10.4.7.22:5601/
复制代码
效果如下,这里点击 Explore on my own,或者选择最左侧上方的三个横杠,下面选择"Management"的Dev Tools
#创建user索引,为了同步mysql的user表数据到es,在kibana的web界面操作
PUT user
{
"settings": {
"index": {
"number_of_shards": "1",
"number_of_replicas": "1"
}
},
"mappings": {
"properties": {
"age": {
"type": "integer"
},
"id": {
"type": "long"
},
"name": {
"type": "text",
"analyzer": "ik_smart"
},
"detail": {
"type": "text",
"analyzer": "ik_max_word"
}
}
}
}
#部署canal
需要下载 canal 的各个组件 canal-deployer、canal-adapter、canal-admin,、
下载地址:
https://github.com/alibaba/canal/releases
各组件简单介绍
canal-server(canal-deploy):
可以直接监听MySQL的binlog,把自己伪装成MySQL的从库,只负责接收数据,并不做处理。
canal-adapter:
相当于canal的客户端,会从canal-server中获取数据,然后对数据进行同步,可以同步到MySQL、Elasticsearch和HBase等存储中去。
canal-admin:
为canal提供整体配置管理、节点运维等面向运维的功能,提供相对友好的 WebUI 操作界面,方便更多用户快速和安全的操作。
#安装 canal-server,首先配置jdk
[root@localhost opt]# tar -zxf openjdk-11.0.1_linux-x64_bin.tar.gz
[root@localhost opt]# ln -sv jdk-11.0.1/ jdk
#文件最后添加两行内容
[root@localhost opt]# vi /etc/profile
export JAVA_HOME=/opt/jdk
export PATH=$JAVA_HOME/bin:$PATH
[root@localhost opt]# source /etc/profile
[root@localhost opt]# wget https://github.com/alibaba/canal/releases/download/canal-1.1.5-alpha-1/canal.deployer-1.1.5-SNAPSHOT.tar.gz
[root@localhost opt]# mkdir -p canal-deployer
[root@localhost opt]# tar -zxf canal.deployer-1.1.5-SNAPSHOT.tar.gz -C canal-deployer/
[root@localhost opt]# cd canal-deployer/
#canal.properties配置文件定义了canal相关参数
[root@localhost opt]# cat /opt/canal-deployer/conf/canal.properties
。。。。。。。。。。。。。。。。。。。。。。。
######### destinations #############
#################################################
canal.destinations = example #这里的example,表示使用example这个实例。可以配置多个实例,用逗号隔开。
# conf root dir
canal.conf.dir = ../conf
# auto scan instance dir add/remove and start/stop instance
canal.auto.scan = true
canal.auto.scan.interval = 5
# set this value to 'true' means that when binlog pos not found, skip to latest.
# WARN: pls keep 'false' in production env, or if you know what you want.
canal.auto.reset.latest.pos.mode = false
canal.instance.tsdb.spring.xml = classpath:spring/tsdb/h2-tsdb.xml
#canal.instance.tsdb.spring.xml = classpath:spring/tsdb/mysql-tsdb.xml
canal.instance.global.mode = spring
canal.instance.global.lazy = false
canal.instance.global.manager.address = ${canal.admin.manager}
#canal.instance.global.spring.xml = classpath:spring/memory-instance.xml
canal.instance.global.spring.xml = classpath:spring/file-instance.xml
#canal.instance.global.spring.xml = classpath:spring/default-instance.xml
。。。。。。。。。。。。。。。。。。。。。。
#配置example实例配置文件,如果配置其他的,就创建实例名称跟配置文件。
[root@localhost canal-deployer]# cat conf/example/instance.properties
#################################################
canal.instance.mysql.slaveId=22 #跟mysql的serverid不一样就可以
# position info
canal.instance.master.address=10.4.7.22:3306 #指定连接mysql地址
# username/password
canal.instance.dbUsername=canal #canal连接mysql的用户
canal.instance.dbPassword=canal123 #canal连接mysql的密码
canal.instance.connectionCharset = UTF-8
# table regex
#canal.instance.filter.regex=.*\\..* #匹配mysql的所有库下的所有表
canal.instance.filter.regex=statement\\..* #匹配statement库下的所有表
#启动canal-server服务,
在连接canal时,发现连接失败,去查canal日志canal_stdout.log发现有:
Unrecognized VM option ‘UseCMSCompactAtFullCollection’
据说是jdk版本在8以上就不可以,后来又参照了链接
发现可以删除startup.sh中的参数解决:
[root@localhost canal-server]# ./bin/startup.sh
#查看日志,会有下面信息输出
[root@localhost canal-server]# tailf -200 logs/canal/canal.log
#安装adapter
#配置文件修改
[root@localhost opt]# wget https://github.com/alibaba/canal/releases/download/canal-1.1.5-alpha-1/canal.adapter-1.1.5-SNAPSHOT.tar.gz
[root@localhost opt]# mkdir -p canal-adapter
[root@localhost opt]# tar -zxf canal.adapter-1.1.5-SNAPSHOT.tar.gz -C canal-adapter
[root@localhost opt]# cd canal-adapter
[root@localhost canal-adapter]# cat conf/application.yml
[root@localhost canal-adapter]# cat conf/application.yml
server:
port: 8081 #adapter服务端口为8081
spring:
jackson:
date-format: yyyy-MM-dd HH:mm:ss
time-zone: GMT+8
default-property-inclusion: non_null
canal.conf:
mode: tcp # kafka rocketMQ
canalServerHost: 10.4.7.22:11111 #canal-deployer服务地址
# zookeeperHosts: slave1:2181
# mqServers: 127.0.0.1:9092 #or rocketmq
# flatMessage: true
batchSize: 500
syncBatchSize: 1000
retries: 0
timeout:
accessKey:
secretKey:
username:
password:
vhost:
srcDataSources:
defaultDS:
url: jdbc:mysql://10.4.7.22:3306/statement?useUnicode=true #连接mysql的statement库
username: canal #在mysql上授权的用户访问statement数据库
password: canal123 #用户密码
canalAdapters:
- instance: example # canal instance Name or mq topic name
groups:
- groupId: g1
outerAdapters:
- name: es7
key: es71 #这个很重要,必须设置,下面配置要调用。
hosts: 10.4.7.11:9200,10.4.7.12:9200,10.4.7.21:9200 # es集群地址,逗号分隔。
properties:
mode: rest #设置rest模式
security.auth: elastic:Elastic123 # 登录es的账号密码,如果没有设置就注释
cluster.name: es-cluster #es集群名称
#到conf/es7目录下新建user.yml文件,定义mysql数据到es数据的映射字段
[root@localhost es7]# cat conf/es7/user.yml
dataSourceKey: defaultDS #这里defaultDS就是conf/application.yml里定义连接mysql的那个字段。
outerAdapterKey: es71 #这个很重要,必须设置跟conf/application.yml的里key一样
destination: example # # canal instance Name or mq topic name
groupId: g1
esMapping:
_index: user #这里的索引对应前面statement库下面的表user,在es必须提前创建好,索引类似等于mysql的表,懂的
_type: _doc
_id: _id
upsert: true
# pk: id
sql: "select id as _id,name,detail,age from user" #这里track表相关的字段的sql语句。
# etlCondition: "where id>={}" ##etl的条件参数,可以将之前没能同步的数据同步,数据量大的话可以用logstash,
commitBatch: 3000
#启动adapter,如果启动不起来,需要修改startup.sh的下面内容,有些参数错误。
if [ -n "$str" ]; then
JAVA_OPTS="-server -Xms256m -Xmx256m -Xmn256m -XX:SurvivorRatio=2 -XX:PermSize=96m -XX:MaxPermSize=256m -Xss256k -XX:-UseAdaptiveSizePolicy -XX:MaxTenuringThreshold=15 -XX:+DisableExplicitGC -XX:+UseConcMarkSweepGC -XX:+CMSParallelRemarkEnabled -XX:+UseCMSInitiatingOccupancyOnly -XX:+HeapDumpOnOutOfMemoryError"
else
#启动adapter
[root@localhost canal-adapter]# ./bin/startup.sh
#查看日志
[root@localhost canal-adapter]# tailf logs/adapter/adapter.log
... 43 common frames omitted
2022-01-24 17:52:41.593 [main] INFO c.a.o.canal.adapter.launcher.loader.CanalAdapterLoader - Start adapter for canal instance: example succeed
2022-01-24 17:52:41.594 [main] INFO c.a.o.canal.adapter.launcher.loader.CanalAdapterService - ## the canal client adapters are running now ......
2022-01-24 17:52:41.612 [main] INFO org.apache.coyote.http11.Http11NioProtocol - Starting ProtocolHandler ["http-nio-8081"]
2022-01-24 17:52:41.613 [Thread-2] INFO c.a.o.canal.adapter.launcher.loader.CanalAdapterWorker - =============> Start to connect destination: example <=============
2022-01-24 17:52:41.670 [main] INFO org.apache.tomcat.util.net.NioSelectorPool - Using a shared selector for servlet write/read
2022-01-24 17:52:41.716 [main] INFO o.s.boot.web.embedded.tomcat.TomcatWebServer - Tomcat started on port(s): 8081 (http) with context path ''
2022-01-24 17:52:41.830 [main] INFO c.a.otter.canal.adapter.launcher.CanalAdapterApplication - Started CanalAdapterApplication in 20.873 seconds (JVM running for 22.881)
2022-01-24 17:52:41.888 [Thread-2] INFO c.a.o.canal.adapter.launcher.loader.CanalAdapterWorker - =============> Start to subscribe destination: example <=============
2022-01-24 17:52:41.930 [Thread-2] INFO c.a.o.canal.adapter.launcher.loader.CanalAdapterWorker - =============> Subscribe destination: example succeed <=============
# adapter管理REST接口
#查询所有订阅同步的canal instance或MQ topic,
[root@localhost canal-adapter]# curl http://10.4.7.22:8081/destinations
[{"destination":"example","status":"on"}] #当前只有example实例开启
#查询数据同步开关状态,指定的实例example
[root@localhost canal-adapter]# curl http://10.4.7.22:8081/syncSwitch/example
{"stauts":"on"}
#如果是单机模式则使用本地锁来控制开关,控制开启或者关闭
[root@localhost ~]# curl -XPUT http://10.4.7.22:8081/syncSwitch/example/on
{"code":20000,"message":"实例: example 开启同步成功"}
#关闭
[root@localhost canal-adapter]# curl -XPUT http://10.4.7.22:8081/syncSwitch/example/off
{"code":20000,"message":"实例: example 关闭同步成功"}
#手动ETL来测试mysql数据通过canal同步到es集群里。
第一步:登录mysql,插入数据
[root@localhost data]# mysql -uroot -p123456 -S /usr/local/mysql/mysql.sock
root@localhost [(none)]>use statement;
Database changed
root@localhost [statement]>insert into user values(39,"haha","万岁啊",39);
Query OK, 1 row affected (0.04 sec)
root@localhost [statement]>insert into user values(40,"haha","万岁啊",40);
Query OK, 1 row affected (0.01 sec)
#同时查看adapter的log,
[root@localhost canal-adapter]# tailf logs/adapter/adapter.log

#这个时候查看es集群是否有数据,通过kibana的查看
GET /user/_search

#重新测试下,
先删除user表所有数据,先添加三行数据,canal服务当前是启动的,因此会实时同步到es集群上
root@localhost [statement]>delete from user;
Query OK, 18 rows affected (0.10 sec)
root@localhost [statement]>insert into user values(1,"haha","万岁啊",1);
Query OK, 1 row affected (0.04 sec)
root@localhost [statement]>insert into user values(2,"haha","万岁啊",2);
Query OK, 1 row affected (0.03 sec)
root@localhost [statement]>insert into user values(3,"haha","万岁啊",3);
#kibana查看es是否有数据同步过来
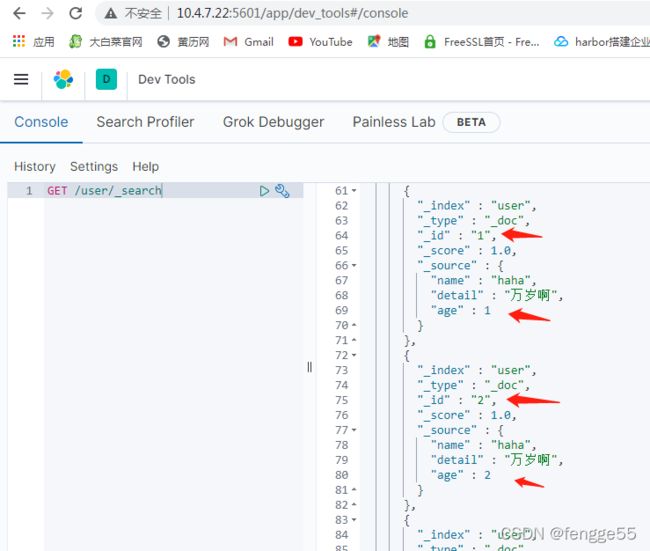
#配置canal全量同步mysql的数据,就是说,mysql一直在写数据,而canal意外停止服务了,默认是会导致新增的mysql数据是不同步到es集群上
所以当canal服务重启后,会同步之前新增的mysql数据到es集群里。
#先停止canal-adapter服务
[root@localhost canal-adapter]# ./bin/stop.sh
#mysql新增数据
[root@localhost data]# mysql -uroot -p123456 -S /usr/local/mysql/mysql.sock
root@localhost [(none)]>use statement;
Database changed
root@localhost [statement]>insert into user values(4,"haha","万岁啊",4);
Query OK, 1 row affected (0.06 sec)
root@localhost [statement]>insert into user values(5,"haha","万岁啊",5);
Query OK, 1 row affected (0.07 sec)
root@localhost [statement]>insert into user values(6,"haha","万岁啊",6);
Query OK, 1 row affected (0.00 sec)
root@localhost [statement]>insert into user values(7,"haha","万岁啊",7);
Query OK, 1 row affected (0.00 sec)
##到conf/es7目录下新建user.yml文件,定义mysql数据到es数据的映射字段
[root@localhost canal-adapter]# vi conf/es7/user.yml
dataSourceKey: defaultDS
outerAdapterKey: es71
destination: example
groupId: g1
esMapping:
_index: user
_type: _doc
_id: _id
upsert: true
# pk: id
sql: "select id as _id,name,detail,age from user"
etlCondition: "where id>={}" #新增这行
commitBatch: 3000
#启动canal-adapter服务
[root@localhost canal-adapter]# ./bin/startup.sh
#同时查看adapter的log,最后面会看到同步canal服务停止后,mysql新增的数据
[root@localhost canal-adapter]# tailf logs/adapter/adapter.log

#用kibana查看user的索引,mysql的user表所有数据都再es上面
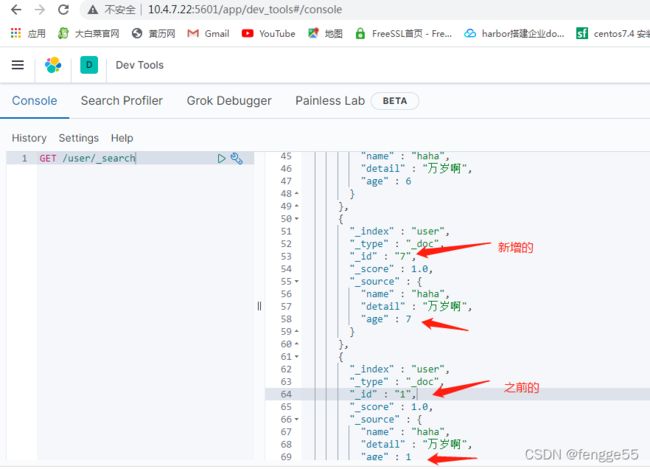
#如果只想同步statement数据库的user表的id为2之后的数据同步到es里,params等于后面的值,就是定义的 {}的值,表示条件: id >= 2
[root@localhost ~]# curl http://10.4.7.22:8081/etl/es7/es71/user.yml -X POST -d "params=2"
{"succeeded":true,"resultMessage":"导入ES 数据:6 条"}
16.安装canal-admin
[root@localhost opt]# tar -zxf canal.admin-1.1.5-SNAPSHOT.tar.gz -C canal-admin/
[root@localhost opt]# cd canal-admin/conf/
#导入文件,创建数据库canal_manager
[root@localhost conf]# mysql -uroot -p123456 -S /usr/local/mysql/mysql.sock < canal_manager.sql
[root@localhost conf]# mysql -uroot -p123456 -S /usr/local/mysql/mysql.sock
#配置canal-admin服务
[root@localhost conf]# cat application.yml
server:
port: 8089 #canal-admin服务端口
spring:
jackson:
date-format: yyyy-MM-dd HH:mm:ss
time-zone: GMT+8
spring.datasource:
address: 10.4.7.22:3306 #mysql地址
database: canal_manager #canal-admin的服务数据库,管理es的集群
username: canal #mysql上授权用户对canal_manager数据库
password: canal123 #mysql上用户密码
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://${spring.datasource.address}/${spring.datasource.database}?useUnicode=true&characterEncoding=UTF-8&useSSL=false
hikari:
maximum-pool-size: 30
minimum-idle: 1
canal:
adminUser: admin
adminPasswd: admin
#启动canal-admin服务,如果启动不起来,需要修改startup.sh 文件,参数有问题
str=`file -L $JAVA | grep 64-bit`
if [ -n "$str" ]; then
JAVA_OPTS="-server -Xms256m -Xmx256m" #修改下
else
JAVA_OPTS="-server -Xms256m -Xmx256m" #修改下
fi
JAVA_OPTS="$JAVA_OPTS -XX:+UseG1GC -XX:MaxGCPauseMillis=250" #修改下
JAVA_OPTS=" $JAVA_OPTS -Djava.awt.headless=true -Djava.net.preferIPv4Stack=true -Dfile.encoding=UTF-8"
CANAL_OPTS="-DappName=canal-admin"
for i in $base/lib/*;
do CLASSPATH=$i:"$CLASSPATH";
done
#启动canal-admin
[root@localhost canal-admin]# ./bin/startup.sh
#查看端口
[root@localhost canal-admin]# ss -lnt|grep 8089
#添加canal-deployer服务,配置地址跟端口就在canal_local.properties定义好的服务。
[root@localhost canal-deployer]# cat conf/canal_local.properties
# register ip
canal.register.ip =
# canal admin config
canal.admin.manager = 127.0.0.1:8089
canal.admin.port = 11110
canal.admin.user = admin
canal.admin.passwd = 4ACFE3202A5FF5CF467898FC58AAB1D615029441
# admin auto register
canal.admin.register.auto = true
canal.admin.register.cluster = canal-server #修改这行,设置名字。
#重启canal-deployer服务
[root@localhost canal-deployer]# ./bin/stop.sh
[root@localhost canal-deployer]# ./bin/startup.sh
#浏览器登录canal-admin,默认账号:admin ,密码为:123456,点击新建server
http://10.4.7.22:8089/
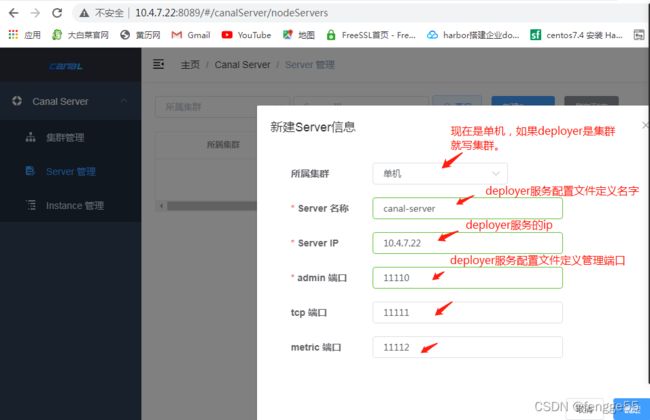
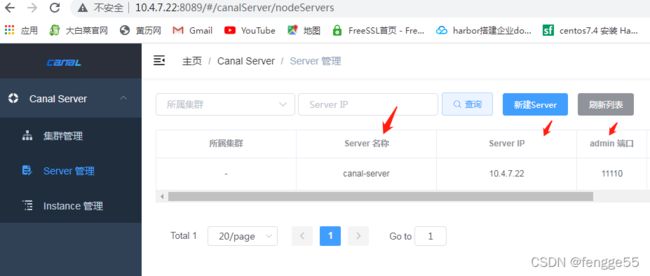
#基于fs来备份还原
1.注册共享仓库,10.4.7.22作为fs备份存储
#安装nfs服务,下一篇文件会更新,