9个服务端提升debug效率的IDEA Debugger技巧

不可否认,未来的一到两年中,程序员的编码体验将会发生剧烈的变化。作为一名一线开发,要如何提前准备,来应对这种变化呢?

前言
在AIGC时代,虽然深度学习模型可以仅通过一段注释来生成我们想要的代码,但是,最终要让代码跑起来的还是程序员自己,因此,调试代码,解决问题的能力相较于编码能力会变得愈发重要。
对于服务端而言,IDEA的Debugger几乎成为了调试代码的银弹。但是,笔者发现很多人在使用Debugger时,只使用了其中很小一部分功能。
在本文中,笔者将简要介绍一些自己整理的IDEA Debugger中一些鲜为人知,却能够在特定场景提升Debug效率的功能。
注意:本文不会涉及IDEA Debugger的基础操作,例如:
基本的Debug操作,包括但不限于:Step Over, Step Into, Step Out, Run to Cursor, Drop Frame等
基本的断点类型:条件断点、方法断点、线程/全局断点、字段断点、计数断点等
以上操作在各大论坛中均有优秀文章介绍。

断点
▐ 不暂停断点
尽管很多文章已经提到过断点的非挂起功能,但是由于其太好用了,所以本文也单独列出,使用方法如下。
我们在创建断点时,进入断点配置界面后:
取消勾选Suspend,并填写Evaluate and log,此时,断点将会变为黄色。

当程序运行到断点时,代码不会中断执行,而是会直接在Debugger中打印出Evaluate and log中的信息:

▐ 异常断点
普通断点的不足
当代码产生异常时,我们可以通过log看到异常捕获信息,然而,异常的捕获位置很可能和异常真实发生的位置相距甚远。
例如以下代码,ExceptionPoint的process方法调用了innerProcess方法,并在innerProcess方法中会产生运行时异常:

而异常捕获在上层的Filter类的main方法中:

当异常产生后,产生的log为:
![]()
可以发现,log并没有打印出异常的堆栈信息,一旦发生这种情况,尽管我们可以定位到异常是哪里被捕获的,却很难定位到异常是在哪里呗抛出的。
配置异常断点
为了获取异常被抛出的位置,我们可以使用IDEA中的异常断点,配置位置在断点面板的上面:

选择好需要捕获的异常类型后,需要配置断点过滤:Catch class filters
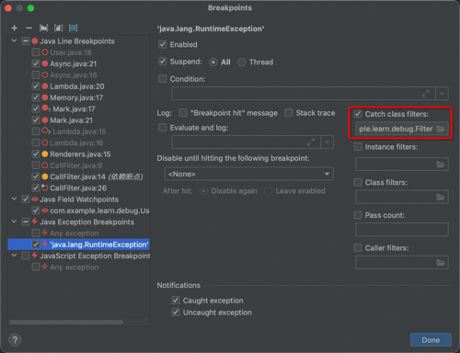
在断点过滤处,要输入捕获断点的类(本例为上层的Filter),配置完成后,重新Debug时,IDEA就会在异常将要抛出时进入断点:
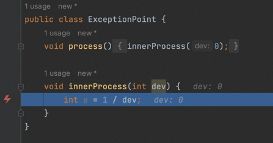
在异常抛出的位置,我们就可以很容易看出方法的入参出参,从而定位问题。
▐ 依赖断点
断点依赖的场景
有时,目标方法可能被多个方法调用,例如以下代码,work()方法同时被warmup和realWork方法调用。
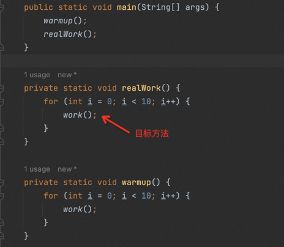
如果我们想让目标方法work()中的断点仅在被realWork()调用时才启用,要怎么办呢?
以下提供两种方法,这两种方法分别适用于不同的使用场景。
前置条件断点
在方法realWork()中创建非挂起断点:

在目标方法work()中如下位置增加断点依赖:仅当选中断点执行后再启用

完成上述配置后,Debug时,则仅当realWork()的断点被激活后,第二个断点才会被启用。
调用过滤器
另一种方法是直接创建调用过滤器,不过这种方法需要当前暂停的断点正在被目标方法调用。
使用方法为:
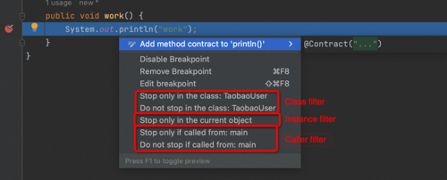
在work()的断点行,Alt+Enter,在弹出的界面中,选择当前断点的调用条件:

选择后,IDEA会自动填充到以下位置:
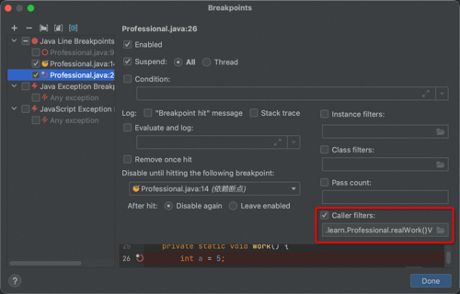
同时,对于非静态方法,还可以选择Instance filters和Class filters,原理相同。
▐ 断点后悔药
如果我们好不容易按照上述方法设置了一些复杂的断点,却因为手滑点了一下,一不小心给删了,要怎么恢复呢?
以下提供三种方法,也分别适用于不同场景。
标准的撤回操作
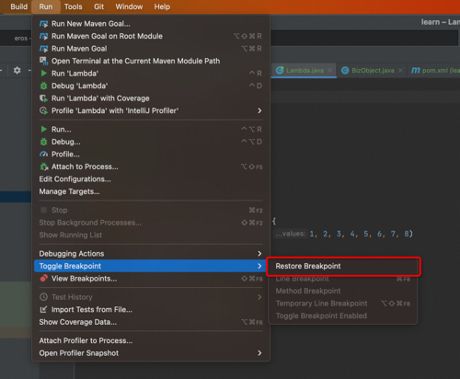
在如上位置,通过点击Restore Breakpoint,即可撤销删除最近删除的断点
原地复活
如果我们已经进行了多个断点的删除操作,以至于上述撤回按钮已经失效了,要怎么办呢?
我们还可以在不小心删掉断点的位置再次创建一个普通断点,可以注意到,此时,IDEA会多出一个选项:

点击Restore previous breakpoint,即可恢复原来的断点。
一劳永逸的方法
既然我们经常一不小心删除断点,干脆修改左键为不删除断点不就好了?
IDEA也提供这一功能,位置在
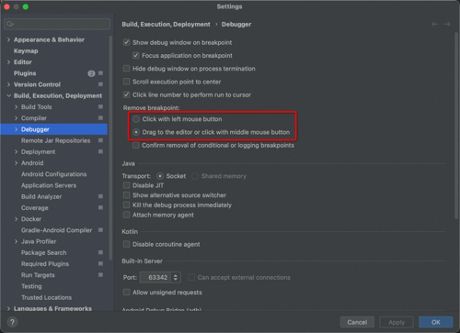
IDEA默认选择第一个,我们可以将其修改为第二个,修改后,左键点击断点,则禁用断点,按鼠标中键才会删除断点,彻底避免了手滑操作。

渲染
▐ 修改对象渲染器
使用场景
有时,IDEA自带的变量渲染器并不能满足我们的需要。例如,我们创建一个继承JSONObject的类:

由于JSONObject继承了Map,所以IDEA默认是以Map的方式渲染的,因此,当我们运行以下代码时:

可以看到Debugger将bizObject渲染为了:
![]()
可以看到,bizObject中的msg字段直接不见了,这当然不是我们想要的,为了获得真实的变量结果,我们可以手动修改IDEA的渲染方式,以下提供三种方法。
简单修改
直接将Map渲染器修改为toString渲染器即可

修改后,Debugger的界面就会变为:
![]()
该方法在一般情况下已经能够满足我们的需求。
创建Class Level Watch
如果我们只想看BizObject中的msg字段,又不想修改渲染器的话,可以通过创建Class Level Watch来达到这一目的。
右键变量,点击New Class Level Watch
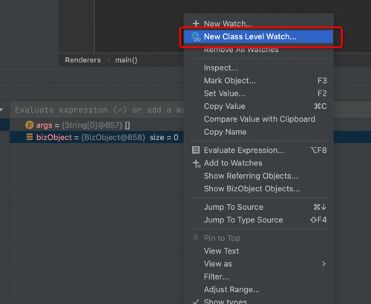
在弹出的输入框中输入想要查看的内容:
![]()
接下来,项目中所有类型为BizObject的类都会单独渲染一个msg字段。
![]()
创建自定义渲染器
如果上述方案都不能满足我们花哨的需求,也可以自定义渲染器:在指定的对象上,选择Create Renderer

在渲染器创建页面中,我们可以自定义渲染方式:
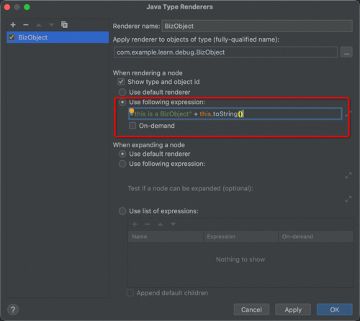
当保存后,就可以看到IDEA按照我们想要的方式渲染对应类型变量了:
![]()
如果渲染比较耗费资源,也可以勾选下面的On-demand开关,打开后,只有点一下对应变量才会执行渲染。
此外,如果想要将渲染配置同步给别人,也可以将配置抽取为注解放在对应类名上:
import org.jetbrains.annotations.Debug.Renderer;@Renderer(text = "name",childrenArray = "courses.toArray()",hasChildren = "courses.isEmpty()")public class Student {private String name;private ArrayList courses;Student(String name, ArrayList courses){this.name=name;this.courses=courses;}}由于这一功能不是很常用,因此本文不再赘述,这里是注解说明https://www.jetbrains.com/help/idea/customizing-views.html#renderers。
▐ 修改列表渲染器
当我们创建如下的列表时:
![]()
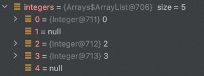
在Debug界面,IDEA会将integers列表渲染为:

可以看到,IDEA并没有渲染为null的元素,如果我们没有注意,并在接下来遍历这个list,很可能会产生NPE。
如何让IDEA显示为null的元素呢?方法如下:

取消勾选后,IDEA就会将列表重新渲染为以下内容了。

定位
▐ 标记
在一次请求链路中,有些对象在构造好后是不会轻易改变的,他们可能辗转穿梭于多个上下文中(例如User对象)。如果我们想要持续跟踪这个对象,则可以使用IDEA中的对象标记功能。
例如,我们创建两个上下文,分别为InputContext和OutputContext,其中都包含user字段。

在一次处理中,代码从inputContex中获取user放到outputContext中

在我们进入断点后,可以在user对象上选择Mark Object:
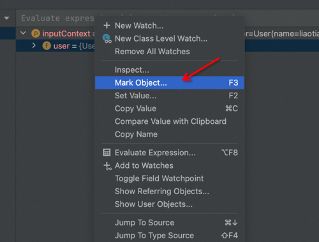
选择后,可以输入对于这个对象的标记(下例中将user用“mark”标记):

一旦一个对象被标记,这个对象在被销毁前就有了以下功能:
在任何debug页面,只要有引用指向这个对象,则会额外标记:

在任何线程,任何上下文中,我们都可以引用这个对象。
以下是一个在条件断点中引用user对象的实例:
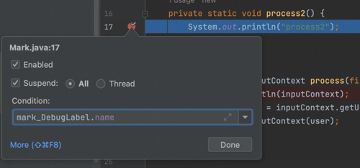
在上图中,可以看到,process2方法的上下文中并没有被标记的user对象,然而,如果我们使用标记名_DebugLabel,就可以访问之前标记user的对象,并且能够取出其name字段。
注意:变量标记在当前Debug结束后就会失效。
▐ 引用
在多线程环境下,如果一个对象同时被两个线程执行写操作,很可能会出现线程并发问题,如果我们定位到一个对象可能出现了多线程问题,要如何知道这个对象被哪些线程引用呢?
方法也很简单,只需要找到对应变量,点击Show referring Objects,就可以找到所有线程中引用当前对象的对象。

▐ 异步栈信息
当我们在同步代码中使用线程池来执行异步任务时,这个异步任务的栈和主线程是隔离的,此时,IDEA还可以看到主线程的栈信息么?
例如以下代码:main方法中创建了一个异步任务,调用了task方法;在task方法中,又启用了一个异步任务,调用了innerTask方法。

通过实践可以发现,虽然是有两层的异步调用,但是IDEA还是打印出了包括主线程在内的所有堆栈信息:

只是每个Stack Frame之间增加了Async stack trace的提示,这是由于IDEA默认开启了Async stack trace,如果不想要看到除当前栈外的信息,可以在此处关掉这一功能:

关掉后,所有异步任务就只会显示当前的栈信息了。
¤ 拓展阅读 ¤
3DXR技术 | 终端技术 | 音视频技术
服务端技术 | 技术质量 | 数据算法