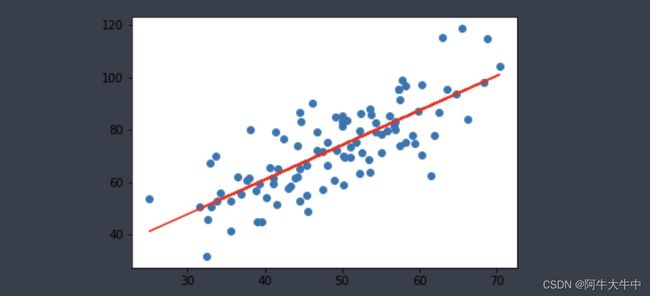
机器学习模型——回归模型
文章目录
- 监督学习——回归模型
- 线性回归模型
-
- 最小二乘法
- 求解线性回归
- 代码实现
-
-
- 引入依赖:
- 导入数据:
- 定义损失函数:
- 定义核心算法拟合函数:
- 测试:
- 画出拟合曲线:
-
- 多元线性回归
-
- 梯度下降求线性回归
- 梯度下降和最小二乘法
- 代码实现
-
-
- 定义模型的超参数:
- 定义核心梯度下降算法函数:
- 测试:
- 画出拟合曲线:
-
- 调用sklearn库代码实现
-
-
- 调用库:
- 获取数值:
- 画出拟合曲线:
-
这里来学习一下机器学习的一些模型,包括:
- 监督学习:
- 回归模型:
- 线性回归
- 分类模型:
- k近邻(kNN)
- 决策树
- 逻辑斯谛回归
- 回归模型:
- 无监督学习:
- 聚类:
- k均值(k-means)
- 降维
- 聚类:
监督学习——回归模型
线性回归模型
- 线性回归(linear regression)是一种线性模型,它假设输入变量x和单个输出变量y之间存在线性关系。
- 具体来说,利用线性回归模型,可以从一组输入变量x的线性组合中,计算输出变量y
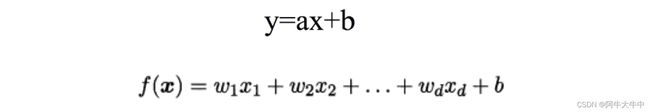

- 线性回归模型:
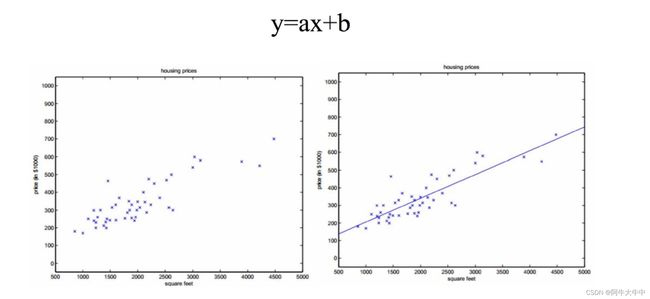
定义:

最小二乘法
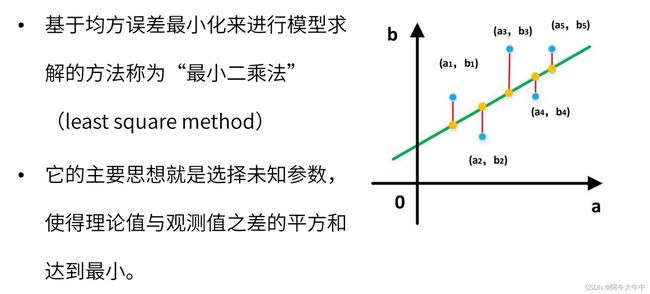

求解线性回归

代码实现
引入依赖:
import numpy as np
import matplotlib.pyplot as plt
导入数据:
points = np.genfromtxt('data.csv', delimiter=',')
# points[0,0] 第一行第一列的元素
# 提取points中的两列数据,分别作为x,y
x = points[:, 0] # 所有行的第一列元素
y = points[:, 1] # 所有行的第二列元素
# 用plt画出散点图
plt.scatter(x, y)
plt.show()
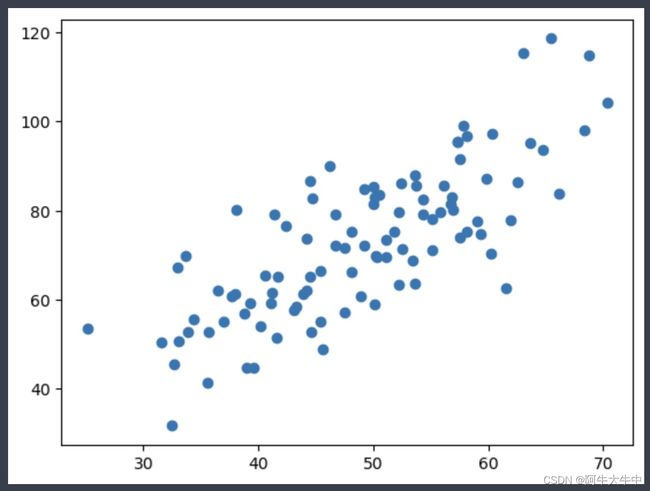
其中数据data.csv:
32.502345269453031,31.70700584656992
53.426804033275019,68.77759598163891
61.530358025636438,62.562382297945803
47.475639634786098,71.546632233567777
59.813207869512318,87.230925133687393
55.142188413943821,78.211518270799232
52.211796692214001,79.64197304980874
39.299566694317065,59.171489321869508
48.10504169176825,75.331242297063056
52.550014442733818,71.300879886850353
45.419730144973755,55.165677145959123
54.351634881228918,82.478846757497919
44.164049496773352,62.008923245725825
58.16847071685779,75.392870425994957
56.727208057096611,81.43619215887864
48.955888566093719,60.723602440673965
44.687196231480904,82.892503731453715
60.297326851333466,97.379896862166078
45.618643772955828,48.847153317355072
38.816817537445637,56.877213186268506
66.189816606752601,83.878564664602763
65.41605174513407,118.59121730252249
47.48120860786787,57.251819462268969
41.57564261748702,51.391744079832307
51.84518690563943,75.380651665312357
59.370822011089523,74.765564032151374
57.31000343834809,95.455052922574737
63.615561251453308,95.229366017555307
46.737619407976972,79.052406169565586
50.556760148547767,83.432071421323712
52.223996085553047,63.358790317497878
35.567830047746632,41.412885303700563
42.436476944055642,76.617341280074044
58.16454011019286,96.769566426108199
57.504447615341789,74.084130116602523
45.440530725319981,66.588144414228594
61.89622268029126,77.768482417793024
33.093831736163963,50.719588912312084
36.436009511386871,62.124570818071781
37.675654860850742,60.810246649902211
44.555608383275356,52.682983366387781
43.318282631865721,58.569824717692867
50.073145632289034,82.905981485070512
43.870612645218372,61.424709804339123
62.997480747553091,115.24415280079529
32.669043763467187,45.570588823376085
40.166899008703702,54.084054796223612
53.575077531673656,87.994452758110413
33.864214971778239,52.725494375900425
64.707138666121296,93.576118692658241
38.119824026822805,80.166275447370964
44.502538064645101,65.101711570560326
40.599538384552318,65.562301260400375
41.720676356341293,65.280886920822823
51.088634678336796,73.434641546324301
55.078095904923202,71.13972785861894
41.377726534895203,79.102829683549857
62.494697427269791,86.520538440347153
49.203887540826003,84.742697807826218
41.102685187349664,59.358850248624933
41.182016105169822,61.684037524833627
50.186389494880601,69.847604158249183
52.378446219236217,86.098291205774103
50.135485486286122,59.108839267699643
33.644706006191782,69.89968164362763
39.557901222906828,44.862490711164398
56.130388816875467,85.498067778840223
57.362052133238237,95.536686846467219
60.269214393997906,70.251934419771587
35.678093889410732,52.721734964774988
31.588116998132829,50.392670135079896
53.66093226167304,63.642398775657753
46.682228649471917,72.247251068662365
43.107820219102464,57.812512976181402
70.34607561504933,104.25710158543822
44.492855880854073,86.642020318822006
57.50453330326841,91.486778000110135
36.930076609191808,55.231660886212836
55.805733357942742,79.550436678507609
38.954769073377065,44.847124242467601
56.901214702247074,80.207523139682763
56.868900661384046,83.14274979204346
34.33312470421609,55.723489260543914
59.04974121466681,77.634182511677864
57.788223993230673,99.051414841748269
54.282328705967409,79.120646274680027
51.088719898979143,69.588897851118475
50.282836348230731,69.510503311494389
44.211741752090113,73.687564318317285
38.005488008060688,61.366904537240131
32.940479942618296,67.170655768995118
53.691639571070056,85.668203145001542
68.76573426962166,114.85387123391394
46.230966498310252,90.123572069967423
68.319360818255362,97.919821035242848
50.030174340312143,81.536990783015028
49.239765342753763,72.111832469615663
50.039575939875988,85.232007342325673
48.149858891028863,66.224957888054632
25.128484647772304,53.454394214850524
定义损失函数:
# 损失函数是系数的函数,另外还要传入数据的x,y
def compute_cost(w, b, points):
total_cost = 0
M = len(points)
# 逐点计算平方损失误差,然后求平均数
for i in range(M):
x = points[i, 0]
y = points[i, 1]
total_cost += ( y - w * x - b ) ** 2 # **2 代表平方
return total_cost / M
定义核心算法拟合函数:
# 先定义一个求均值的函数
def average(data):
sum = 0
num = len(data)
for i in range(num):
sum += data[i]
return sum/num
# 定义核心拟合函数
def fit(points):
M = len(points)
x_bar = average(points[:, 0])
sum_yx = 0
sum_x2 = 0
sum_delta = 0
for i in range(M):
x = points[i, 0]
y = points[i, 1]
sum_yx += y * ( x - x_bar )
sum_x2 += x ** 2
# 根据公式计算w
w = sum_yx / ( sum_x2 - M * (x_bar**2) )
for i in range(M):
x = points[i, 0]
y = points[i, 1]
sum_delta += ( y - w * x )
b = sum_delta / M
return w, b
测试:
w, b = fit(points)
print("w is: ", w) # 斜率
print("b is: ", b)
cost = compute_cost(w, b, points)
print("cost is: ", cost)
w is: 1.3224310227553846
b is: 7.991020982269173
cost is: 110.25738346621313
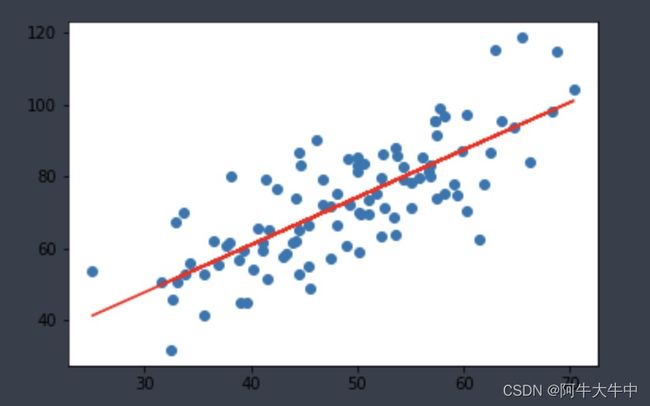
画出拟合曲线:
plt.scatter(x, y)
# 针对每一个x,计算出预测的y值
pred_y = w * x + b
plt.plot(x, pred_y, c='r')
plt.show()
多元线性回归

梯度下降求线性回归
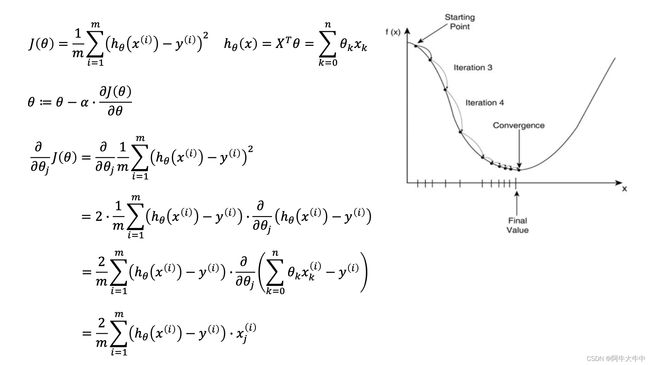
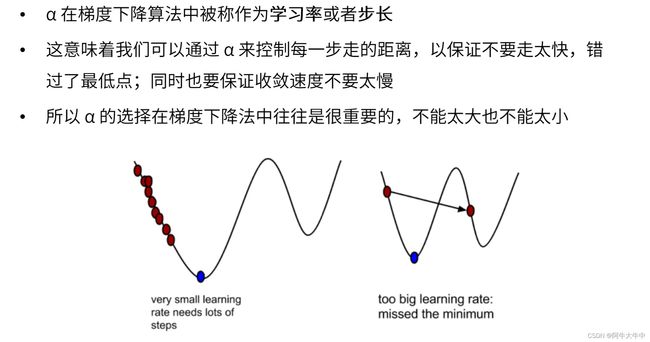
梯度下降和最小二乘法
- 相同点:
- 本质和目标相同:两种方法都是经典的学习算法,在给定已知数据的前提下利用求导算出一个模型(函数),使得损失函数最小,然后对给定的新数据进行估算预测
- 不同点:
- 损失函数:梯度下降可以选取其他损失函数,而最小二乘一定是平方损失函数。
- 实现方法:最小二乘法是直接求导出全局最小;而梯度下降是一种迭代法。
- 效果:最小二乘找到的一定是全局最小,但计算繁琐,且复杂情况下未必有解;梯度下降迭代计算简单,但找到的一般是局部最小,只有目标函数式凸函数时才是全局最小;到最小点附近时收敛速度会变慢,且对初始点的选择极为敏感。
代码实现
引入依赖、导入数据、定义损失函数同上。
定义模型的超参数:
alpha = 0.0001 # 步长
initial_w = 0
initial_b = 0
num_iter = 10 # 迭代次数
定义核心梯度下降算法函数:
def grad_desc(points, initial_w, initial_b, alpha, num_iter):
w = initial_w
b = initial_b
# 定义一个list保存所有的损失函数值,用来显示下降的过程
cost_list = []
for i in range(num_iter):
cost_list.append( compute_cost(w, b, points) )
w, b = step_grad_desc( w, b, alpha, points )
return [w, b, cost_list]
# 迭代
def step_grad_desc( current_w, current_b, alpha, points ):
sum_grad_w = 0
sum_grad_b = 0
M = len(points)
# 对每个点,代入公式求和
for i in range(M):
x = points[i, 0]
y = points[i, 1]
sum_grad_w += ( current_w * x + current_b - y ) * x
sum_grad_b += current_w * x + current_b - y
# 用公式求当前梯度
grad_w = 2/M * sum_grad_w
grad_b = 2/M * sum_grad_b
# 梯度下降,更新当前的w和b
updated_w = current_w - alpha * grad_w
updated_b = current_b - alpha * grad_b
return updated_w, updated_b
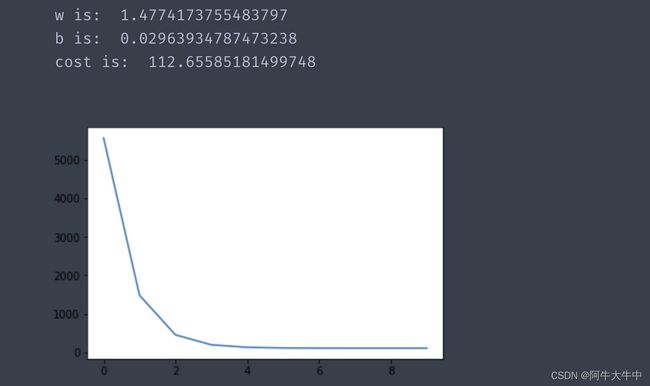
测试:
w, b, cost_list = grad_desc( points, initial_w, initial_b, alpha, num_iter )
print("w is: ", w)
print("b is: ", b)
cost = compute_cost(w, b, points)
print("cost is: ", cost)
plt.plot(cost_list)
plt.show()
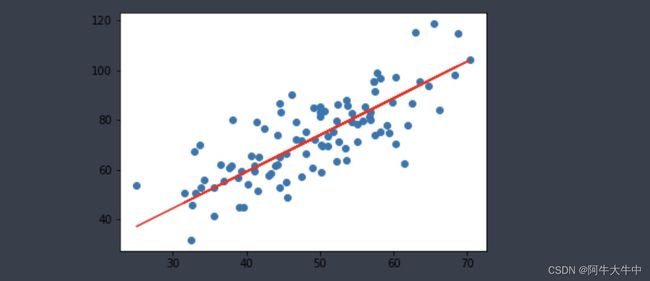
画出拟合曲线:
plt.scatter(x, y)
# 针对每一个x,计算出预测的y值
pred_y = w * x + b
plt.plot(x, pred_y, c='r')
plt.show()
调用sklearn库代码实现
引入依赖、导入数据、定义损失函数同上。
调用库:
from sklearn.linear_model import LinearRegression
lr = LinearRegression()
x_new = x.reshape(-1, 1) # reshape(-1, 1) -1表示行数不限,1表示列数为1,即变为n行1列矩阵
y_new = y.reshape(-1, 1)
lr.fit(x_new, y_new)
获取数值:
# 从训练好的模型中提取系数和截距
w = lr.coef_[0][0] # 系数
b = lr.intercept_[0] # 截距
print("w is: ", w)
print("b is: ", b)
cost = compute_cost(w, b, points)
print("cost is: ", cost)
w is: 1.3224310227553597
b is: 7.991020982270399
cost is: 110.25738346621318
画出拟合曲线:
plt.scatter(x, y)
# 针对每一个x,计算出预测的y值
pred_y = w * x + b
plt.plot(x, pred_y, c='r')
plt.show()