Bert-二分类(包括py3.8版本情况下tensorflow降为1.X的情况,包括安装虚拟环境)
Bert-二分类
-
- 前话
- 数据预处理
- 代码微调
- 设置参数
- 设置虚拟环境
- Run-train
- 注意
前话
1.作为一名小白最近在做中文文本二分类的实战,用到Google的Bert模型。
2.中途卡了很多次,记录下来,如果有朋友也遇到了类似问题,很高兴能帮到你们。
数据预处理
1.BERT输入的最大长度限制为512,bert自带截断,长文本截取前 510 个字符,另外两个为[cls]。不过也可以学学bert对超长文本的数据处理方式,但是虽然文章篇幅长,不一定就是要读取到最大长度,后面对比发现,读取100比读取512准确率更高。
2.对于篇章级的分了段的句子,要合并,代码如下:
import openpyxl
# .xlsx文件中只留下每一行需要合并处理的段落句子
def write_excel_xlsx(path_w, path_r, sheet_name):
workbook_r = openpyxl.load_workbook(path_r)
sheet_r = workbook_r[sheet_name]
workbook_w = openpyxl.Workbook()
sheet_w = workbook_w.active
sheet_w.title = sheet_name
for row_r, i in zip(sheet_r.rows, range(621)): # 被读取文件的行数
for cell in row_r:
sheet_w.cell(row=i + 1,
column=1,
value=''.join(list(cell.value.split('\n')))) #
workbook_w.save(path_w)
print("xlsx格式表格写入数据成功!")
book_name_xlsx = "C:/Users/hua'wei/Desktop/官方增加数据.xlsx" # 需要处理的读文件
book_name_xlsx1 = "C:/Users/hua'wei/Desktop/官方增加数据2.xlsx" # 需要处理的写文件
sheet_name_xlsx = '数据' # 文件下方的小框框要写的标题,记得要改
write_excel_xlsx(book_name_xlsx1, book_name_xlsx, sheet_name_xlsx)
3.去除不必要的内容,比如英文,各种符号,数字等等(一般用原始的数据不要去除更好,如果 去除方法不对,数据会有问题,模型输入就会跑不通)(不用去除停用词不用自己分词(模型已经写好了分词)不用自己词向量化)。由于Bert为监督模型(确实监督效果更好),将数据集人工分类标注为“0”“1”后再分为训练集(70%)、验证集(20%)、测试集(10%)(最好新建一个文件夹专门放数据集,此文件夹放在bert-master下)。结果如下:

3.从github上下载好中文预训练模型(用人家已经预训练好的,普通machine跑不了)以及bert-master,导入到PyCharm,准备工作就完毕了。
代码微调
1.bert-master文件夹下的“run_classifier.py”用来做文本分类任务。
2.仿照例类,写自己数据读取的类,我将之命名为MyDataProcessor,代码如下:
class MyDataProcessor(DataProcessor):
"""Base class for data converters for sequence classification data sets."""
def get_train_examples(self, data_dir): # 读取训练数据集
"""Gets a collection of `InputExample`s for the train set."""
return self._create_examples(
self._read_tsv(os.path.join(data_dir, "train.txt")), "train")
def get_dev_examples(self, data_dir): # 读取验证数据集
"""Gets a collection of `InputExample`s for the dev set."""
return self._create_examples(
self._read_tsv(os.path.join(data_dir, "dev.txt")), "dev")
def get_test_examples(self, data_dir): # 读取测试数据集
"""Gets a collection of `InputExample`s for prediction."""
return self._create_examples(
self._read_tsv(os.path.join(data_dir, "test.txt")), "test")
def _read_tsv(cls, input_file, quotechar=None): # 我改为了读取.txt文件的方式(虽然名字没有改哈哈)
"""Reads a tab separated value file."""
with open(input_file,'r',encoding='utf-8') as f:
lines = []
for line in f.readlines():
lines.append(line)
return lines
# 如果数据格式并不是一个label,一个tab,一段文本;则需要更改“_create_examples()”的实现。
def _create_examples(self, lines, set_type): # 照猫画虎创造自己的实例
"""Creates examples for the training and dev sets."""
examples = []
for (i, line) in enumerate(lines):
guid = "%s-%s" % (set_type, i)
text_a = tokenization.convert_to_unicode(line[1]) # 文本
label = tokenization.convert_to_unicode(line[0]) # 标签
examples.append(
InputExample(guid=guid, text_a=text_a, text_b=None, label=label)) # 没有第二条文本text_b=None
return examples
def get_labels(self):
"""Gets the list of labels for this data set."""
return ['0','1']
3.在main(_)函数中将processors的内容增加为:
processors = {
"cola": ColaProcessor,
"mnli": MnliProcessor,
"mrpc": MrpcProcessor,
"xnli": XnliProcessor,
"mydata": MyDataProcessor, # 自己创建的类,想个名字
}
设置参数
1.一开始建立了一个新的run.sh脚本文件(不熟练),打算运行此脚本,但总是报错,告知找不到data。
2.后来就直接在PyCharm里面设置参数了,如图所示:
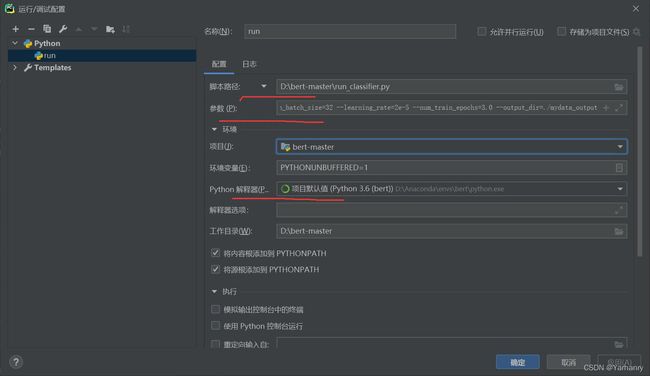
如果是用的他人的修改过的模型,不是官方原始的,就要修改脚本路径,第一条红线处

其中data_dir是你的要训练的文本的数据所在的文件夹,vocab_file,bert_config_file,init_checkpoint是你的bert预训练模型文件夹里面的,填写预训练模型位置即可,我放在bert-master同级目录下。task_name要求和你的DataProcessor类中的名称一致。下面的几个参数,do_train代表是否进行fine tune,do_eval代表是否进行evaluation,还有未出现的参数do_predict代表是否进行预测。max_seq_length代表了句子的最长长度,当显存不足时,可以适当降低max_seq_length。batch-size是1次迭代所使用的样本量,epoch:1个epoch表示过了1遍训练集中的所有样本,output_dir就是将你训练好的结果存放之地。
3.注意参数末尾不可以加\,开头的文件路径为./或…/ 不能是/不然后面会报错“Failed to create a directory ”
4.超参部分,官方表示如下设定在所有任务上都表现很好:
'''
Batch size: 16, 32
Learning rate (Adam): 5e-5, 3e-5, 2e-5
•Number of epochs: 3, 4
'''
设置虚拟环境
1.一开始遇到一个非常头疼的问题,总是显示UnicodeDecodeError: ‘utf-8’ codec can’t decode byte 0xd5 in position 93: invalid continuation byte的报错,去Stack Overflow看,有说可能是数据集保存的时候不是UTF-8的编码格式(或许你们是这个问题),在编译器里改一下,可是仍然没有用(不是数据集的问题,还没有调用读取数据集的函数)。偶然看到一个answer
“It appears the string self.__name in the last line contains non uft-8 encoded characters”,一下子醍醐灌顶,可能是我的路径名称里有中文。找预训练好的文件时无法decode路径,接下来我就更改路径名称,最终就解决了这个问题。
2.由于TensorFlow版本的问题(我目前是2.x),需要不断的修改api,改到后面有个不兼容问题实在改不了(后面又会出现不同问题)
![]()
最后决定降版本,python安装tensorflow的版本要严格对应,安装的时候应注意版本问题(cp对应严格!!),由于我的python是3.8版本,我又在Anaconda里安装了虚拟环境,在cmd里面输入如下命令:
![]()
可自己选择路径,检查现有虚拟环境(我的虚拟环境的名字为bert):

接下来执行这两条命令,进入创造的虚拟环境,安装你所需要TF版本(我安装的是1.6.0版本,或许可以直接安装1.1.0版本应该不用改api)

tips:如果安装别的包,例如pandas,直接在此环境下敲命令:pip install pandas
显示如此则安装成功:

接下来前往PyCharm为你的项目修改python解释器:

右下角选择解释器设置
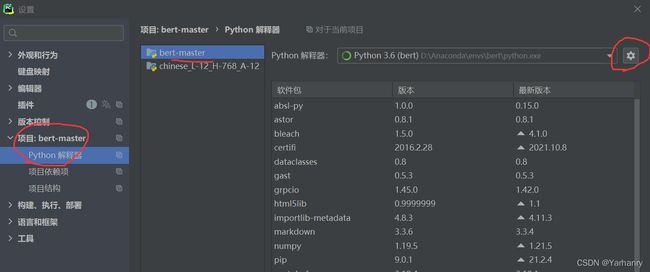
点击添加
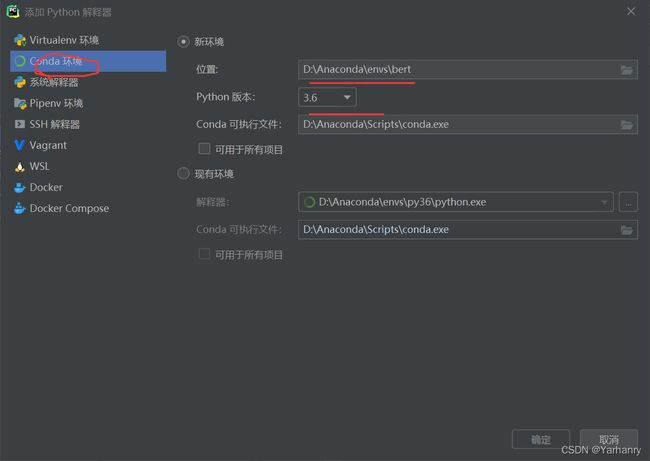
注意一一对应,位置为你刚刚安装的虚拟环境的文件夹位置,最后按确定选择对应的解释器就好了。

Run-train
接下来就要一步步填在2.X版本下改的坑了,把它改回来(大部分是tf.compat.v1改回tf),或者可以去github上重新导入run_classifier.py源码,我选择的是后者,在过程中,出现了TF1.6.0版本不兼容的api接下来我们一一改一下,如下图(报错以及相应更改):





将两处drop_remainder参数给注释掉
bert中文微调tensorflow降版本过程以上三处关于api的修改,感谢这位博主。
后续自己又遇到了一些报错,好在也改过来了:

![]()
把False和name两个参数去掉即可(后来又加回来了,也可以跑通,我也不知道为什么)

最后一个出现的报错困扰了我一天,就看卡在了"Running evaluation"处,猜是不是eval数据有问题,之后我把eval参数设置为fasle,结果train是没问题的,果然问题出在eval处。输入形式也没问题,后来我在eval数据集处加了几十条数据(原来对于eval数据的条数也有说法吗?不是很明白),终于跑通了!!!
出现如下结果说明训练完毕,可以看到输出评估结果如下:

验证集loss上升,acc也上升,原因是过拟合或者训练验证数据分布不一致导致,在训练后期,预测的结果趋向于极端,使少数预测错的样本主导了loss,但同时少数样本不影响整体的验证acc情况。
注意
1.所有路径最好不要包含中文
2.大量改动api,还不如直接在虚拟环境里调Tensorflow(也可能是因为我菜哈哈哈)
3.如果在import处有红下划线显示“未解析的引用…”是因为没有下载该库