MySQL存储引擎概述
前言:MySQL语句执行流程为:SQL语句→查询缓存→解析器→优化器→执行器(执行器会调用执行引擎API);人们把“连接管理、查询缓存、语法解析、查询优化”这些并不涉及真实数据存储的功能划分为MySQL server的功能,把真实存取数据的功能划分为存储引擎的功能。索引MySQL server完成了查询优化后,只需要安装生成的执行计划调用底层存储引擎提供的API,获取到数据后返回给客户端就好了。
1、什么是存储引擎
MySQL中提到了存储引擎的概念。简而言之,存储引擎就是至表的类型。其实存储引擎以前叫做表处理器,后来改名为存储引擎,它的功能就是接收上层传下来的指令,然后对表中的数据进行提取或写入操作。
查看存储引擎:
以MySQL8为例:
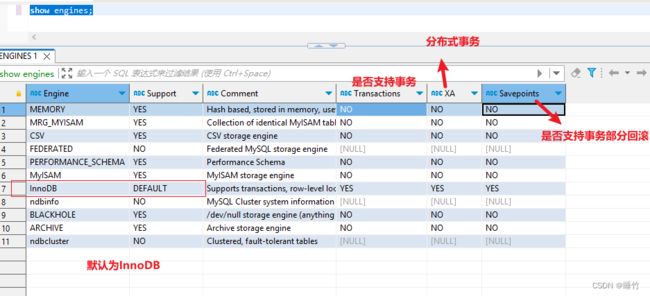
<1>引擎表
show engines;如:
<2>查看默认存储引擎
show variables like '%storage_engine%';
--或者
SELECT @@default_storage_engine;如:
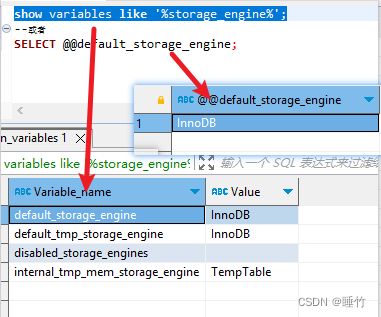
注意:在MySQL5.5之前,默认使用的是MRG_MYISAM
<3>修改存储引擎
- 临时修改
SET DEFAULT_STORAGE_ENGINE=MyISAM;- 修改my.conf文件:
default-storage-engine=MyISAM;重启下MySQL服务即可(systemctl restart mysqld.service)
- 创建表时,也可以显式地指明存储引擎
CREATE TABLE USER_TEST(ID INT) ENGINE = InnodB;2、引擎介绍
2.1、InnoDB引擎:具备外键支持功能的事务存储引擎
- MySQL从3.23.34a开始就包含InnoDB存储引擎。>=5.5之后,默认采用该引擎
- InnoDB是MySQL的默认事务型引擎,它被涉及用来处理大量的短期(short-lived)事务。可以确保事务的完整提交(commit)和回滚(Rollback)。
- 除了增加和查询外,还需要更新、删除操作,应优先选择InnoDB存储引擎。
- 除非有非常特别的原因需要使用其他的存储引擎,否则应该优先考虑InnoDB引擎。
- 数据文件结构:(在《第02章_MySQL数据目录》章节已讲)
- 表名.frm 存储表结构(MySQL8.0时,合并在表名.ibd中)
- 表名.ibd 存储数据和索引
- InnoDB是为处理巨大数据量的最大性能设计。
- 在以前的版本中,字典数据以元数据文件、非事务表等来存储。现在这些元数据文件被删除了。比如:.frm,.par,.trn,.isl,.db.opt等在MySQL8.0中不存在了。
- 对比MyISAM的存储引擎,InnoDB写的处理效率差一些(InnoDB的缺点),并且会占有更多的磁盘空间以保存数据和索引。
- MyISAM只缓存索引,不缓存真实数据;InnoDB不仅缓存索引还要缓存真实数据,对内存要求较高(InnoDB的缺点),而且内存大小对性能有决定性的影响。
InnoDB表的优势
InnoDB存储引擎在实际应用中拥有诸多优势,比如操作便利、提高了数据库的性能、维护成本低等。如果由于硬件或软件的原因导致服务器崩溃,那么在重启服务器之后不需要进行额外的操作。InnoDB崩溃恢复功能自动将之前提交的内容定型,然后撤销没有提交的进程,重启之后继续从崩溃点开始执行。
InnoDB存储引擎在主内存中维护缓冲池,高频率使用的数据将在内存中直接被处理。这种缓存方式应用于多种信息,加速了处理进程。
在专用服务器上,物理内存中高达80%的部分被应用于缓冲池。如果需要将数据插入不同的表中,可以设置外键加强数据的完整性。更新或者删除数据,关联数据将会被自动更新或删除。如果试图将数据插入从表,但在主表中没有对应的数据,插入的数据将被自动移除。如果磁盘或内存中的数据出现崩溃,在使用脏数据之前,校验和机制会发出警告。当海个表的主键都设置合理时,与这些列有关的操作会被自动优化。插入、更新和删除操作通过做改变缓冲自动机制进行优化。InnoDB不仅支持当前读写,也会缓冲改变的数据到数据流磁盘。
2.2、MyISAM引擎:主要的非事务处理存储引擎
- MyISAM提供了大量的特性,包括全文索引、压缩、空间函数(GIS)等,但MyISAM不支持事务、行级锁、外键,有一个很大的缺陷:崩溃后无法安全恢复。
- 5.5之前默认的存储引擎
- 优势是访问的速度快,在事务完整性没有要求或者以SELECT、INSERT为主的应用
- 针对数据统计有额外的常数存储。故而count(*)的查询效率很高(原本:MyISAM引擎会有一个专门的变量,记录count数量(这里的count是指表中的所有数据,查询count时不能附带任何的where条件),因此查询效率极快)
- 数据文件结构:(在《第02章_MySQL数据目录》章节已讲)
- 表名.frm 存储表结构
- 表名.MYD 存储数据(MYData)
- 表名.MYI 存储索引(MYIndex)
- 应用场景:只读应用或者以读为主的业务
2.3、InnoDB与MyISAM的选择问题
很多人对InnoDB和MyISAM的取舍存在疑问,到底选择哪个比较好呢?
MySQL5.5之前的默认存储引擎是MyISAM,5.5之后改为了InnoDB。
首先对于InnoDB存储引擎,提供了良好的事务管理、崩溃修复能力和并发控制。因为InnoDB存储引擎支持事务,所以对于要求事务完整性的场合需要选择InnoDB,比如数据操作除了插入和查询以外还包含有很多更新、删除操作,像财务系统等对数据准确性要求较高的系统。缺点是其读写效率稍差,占用的数据空间相对比较大。
其次对于MyISAM存储引擎,如果是小型应用,系统以读操作和插入操作为主,只有很少的更新、删除操作,并且对事务的要求没有那么高,则可以选择这个存储引擎。MyISAM存储引擎的优势在于占用空间小,处理速度快;缺点是不支持事务的完整性和并发性。
这两种引擎各有特点,当然你也可以在MySQL中,针对不同的数据表,可以选择不同的存储引擎。

2.4、Archive引擎:用于数据存档
- archive是“归档”的意思(主要功能),仅仅支持插入和查询两种功能(行被插入后不能再修改,可以理解为历史不容修改)。
- 在MySQL5.5以后支持索引功能。
- 拥有很好的压缩机制,使用zlib压缩库,在记录请求的时候实时的进行压缩,经常被用来作为仓库使用。
- 创建ARCHIVE表时,存储引擎会创建名称以表名开头的文件。数据文件的扩展名为 .ARZ。
- 根据英文的测试结论来看,同样数据量下,Archive表比MyISAM表要小大约75%,比支持事务处理的InnoDB表小大约83%。
- ARCHIVE存储引擎采用了行级锁。该ARCHIVE引擎支持 AUTO_INCREMENT列属性。AUTO_INCREMENT列可以 具有唯一索引或非唯一索引。尝试在任何其他列上创建索引会导致错误。
- archive表适合日志和数据采集(档案)类应用;适合存储大量的独立的作为历史记录的数据。拥有很高的插入速度,但是对查询的支持较差。
- 下表展示了ARCHIVE 存储引擎功能
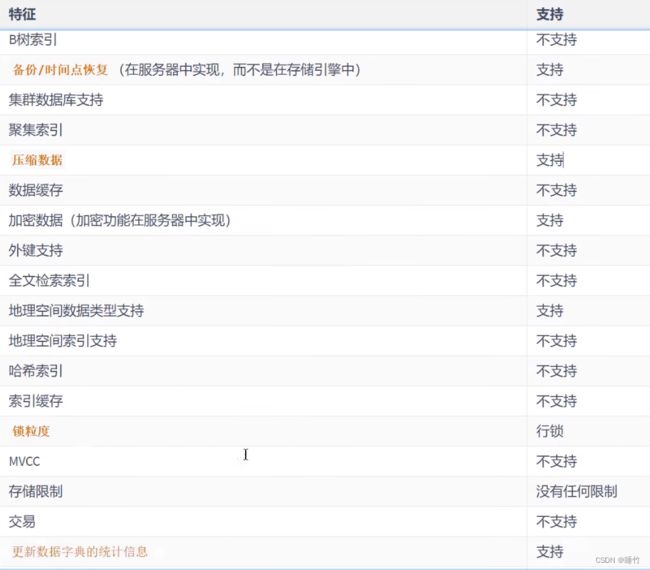
2.5、Blackhole引擎:丢弃写操作,读操作会返回空内容
- Blackhole引擎没有实现任何存储机制,它会丢弃所有插入的数据,不做任何保存。
- 但服务器会记录Blacklole表的日志,所以可以用于复制数据到备库,或者简单地记录到日志。但这种应用方式会碰到很多问题,因此并不推荐。
2.6、CSV引擎:存储数据时,以逗号分隔各个数据项
- CSV引擎可以将 普通的CSV文件作为MySQL的表来处理,但不支持索引。
- CSV引擎可以作为一种数据交换的机制,非常有用(类似于JSON)。
- CSV存储的数据直接可以在操作系统里,用文本编辑器,或者excel读取。
- 对于数据的快速导入、导出是有明显优势的。
2.7、Memory引擎:置于内存的表
概述:
Memory采用的逻辑介质是内存,响应速度很快,但是当mysqld守护进程崩溃的时候数据会丢失。另外,要求存储的数据是数据长度不变的格式,比如,Blob和Text类型的数据不可用(长度不固定的)。
主要特征:
- Memory同时支持哈希(HASH)索引和B+树索引。
- 哈希索引相等的比较快,但是对于范围的比较慢很多。
- 默认使用哈希(HASH)素引,其速度要比使用B型树(BTREE)索引快
- 如果希望使用B树索引,可以在创建索引时选择使用。
- Memory表至少比MyISAM表要快一个数量级。
- MEMORY表的大小是受到限制的。表的大小主要取决于两个参数,分别是max_rows和max_heap_table_size。其中,max_rows可以在创建表时指定;max_heap_table_size的大小默认为16MB, 可以按需要进行扩大。
- 数据是存储在内存中的,但是表结构还是存储在磁盘中
- 缺点:其数据易丢失,生命周期短。基于这个缺陷,选择Memory存储引擎时需要特别小心、
使用场景:
临时表,其他的都优先使用Redis
2.8、Federated引擎:访问远程表
- Federated引擎是访问其他MySQL服务器的一个代理,尽管该引擎看起来提供了一种很好的跨服务器的灵活性,但也经常带来问题,因此默认是禁言的
2.9、Merge引擎:管理多个MyISAM表构成的表集合
2.10、NDB引擎:MySQL集群专用存储引擎
也叫做NDB Cluster存储引擎,主要用于MySQL Cluster 分布式集群环境,类似于oracle的RAC集群。