Linux文件系统
文章目录
-
- 什么是文件系统
- 认识磁盘
-
- 磁盘盘面结构
- LBA寻址方式
- 扇区和磁盘I/O
- 文件系统的具体分析
-
- 文件系统的分治思想
- Linux文件系统结构图
- inode
- stat命令
- 文件名的作用
- 目录文件
- 创建/删除文件,内核做了什么
- 软硬链接
什么是文件系统
前面我们所讲的文件都是内存级别的。也就是这些和文件相关的组织和管理全部都是发生在内存级别的。相比于内存,磁盘的容量可是能以G,甚至是T级别来衡量。这就意味这,磁盘上存储着大量的文件! 而如此庞大的文件数量必然是需要组织和管理的。包括开机前的操作系统的代码也都在磁盘上,如果不加以组织和管理,操作系统连自己的代码在哪里可能都找不到。而管理磁盘文件就是文件系统的工作。
接下来,我们就会详细介绍文件系统的组成部分和工作原理。不过在正式介绍这个之前,我们要来先看一看我们既熟悉又陌生的东西—>磁盘
认识磁盘
为什么说磁盘既熟悉又陌生呢?是因为我们经常听说磁盘是存放文件的地方。但是我们却没有真实见过磁盘是什么模样。下面我们就来看一看磁盘具体是什么样的。

磁盘由很多机械部件组成。不过我们需要关注的是磁头和盘面,其他的部件不是我们研究的重点。那么一个磁盘是如何存储数据并且读取相关的数据呢?
首先,不可否认的是,计算机只能够识别二进制的数据。那么必然磁盘上存储的是01二进制数据。那么,由于磁盘是具有磁性的,那么磁极N/S级对应的就是0和1两种状态,而相对的只要改变磁盘上某个位置的极性就可以做到存储0和1。磁盘存储0和1数据就是这么做到的。
那么如何读取数据呢?这个动作就是交给磁头了。不过我们需要进一步观察磁盘盘面的结构才能更好体会这个磁盘如何读取数据。
磁盘盘面结构
首先,我们来进一步看一看磁盘盘面的结构
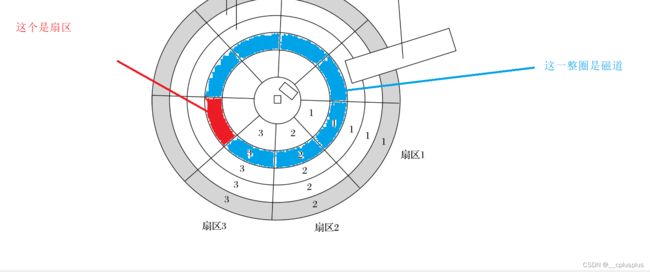
这里我们有必要介绍途中的磁道和扇区的概念
磁道:磁盘的盘面是由一个个的同心圆构成的,而这些同心圆之间的圆环就是磁道
扇区:由上图我们可以看出,每条磁道都被分成了好多段小圆弧,这些校园胡构成的就是扇区!
那么我们知道了磁盘的结构。接下来我们就知道如果要对磁盘进行读取和写入,那么就需要:
1.首先找到这个数据在哪一个盘面
2.找到盘面后,需要确定这个数据在哪一个磁道
3.找到对应的磁道以后,我们要确定需要读取/写入哪一个扇区
而由于整个磁盘是立体的,所以磁道我们从立体的观点来看这个是一个柱体,所以又叫做磁柱(Cylinder)
而每一个面都有一个磁头,所以我们还需要知道磁头(Head)
每个柱面上有一块块的扇区,所以我们还需要扇区(sector)
而对于这种寻址方式,我们取出对应的首字母大写,所以这种寻址方式叫做CHS寻址方式
对于在磁盘读取和写入数据我们就使用CHS寻址方式,但是内核中又是如何处理的呢?别急,接下来我们就来介绍内核对于文件的寻址方式—>LBA
LBA寻址方式
我们知道,对于内核而言,它可处理不了磁盘的环状结构,那么对它而言。它就只有一种处理方式,把对应的磁盘的环状结构抽象看成一条直线。也就是如下这样:

而这样的一条直线。就可以对应使用一个数组来表示。换句话说,对应磁盘上数据的增删改查,最后就变成了对于数组数据的增删改查!而这种抽象以后管理磁盘的方式,我们就叫做LBA—>逻辑块地址管理方式。
而对应的转换方式如下:
用c表示当前柱面号,h表示当前磁头号,s表示当前扇区号,cs表示起始柱面号,hs表示起始磁头号,ss表示起始扇区号,ps表示每磁道有多少个扇区,ph表示每柱面有多少个磁道,计算公式如下:
LBA=(c-ch)phps+(h-hs)*ps+(s-ss)
而对应LBA求出c,h,s的方式如下:
c=LBA/(ph*ps)+cs
h=(LBA/ps)%ph+hs
s=(LBA/ps)+ss
这样就可以通过对应的转换方式把数组和磁盘上的文件数据关联起来进行管理!
扇区和磁盘I/O
那么接下来我们谈一谈扇区。首先我们要知道磁盘的基本单位就是扇区!大多数磁盘的扇区设计都是以512B作为基本单位,但是操作系统一次进行磁盘I/O的基本单位是4MB,为什么不是和磁盘基本单位一样呢?
有如下的两个方面的考量:
1.磁盘I/O实在是太慢了,为了提高效率,所以一次I/O输入输出的量大一点,能减少I/O次数就减少I/O次数
2.如果操作系统的磁盘I/O基本单位和磁盘基本单位相同,则具有极强的耦合性!
这个耦合性应该如何理解呢?今天我们使用的是扇区大小为512MB的磁盘,假设我们的操作系统也以512B为基本单位输出。 那么一旦后续磁盘的扇区改变了,操作系统的源代码也要跟着变化。这就违背了软件设计的高内聚,松耦合的原则。而我今天以4kb作为基本的I/O基本单位,那么和磁盘交互的事情就交给了驱动层负责帮我做转换。而不是操作系统去修改源码适应磁盘。屏蔽底层硬件的差异,使得内核以统一的视角看待磁盘IO
文件系统的具体分析
兜兜转转走了一圈,终于开始正式讲我们的文件系统了!首先声明一点,本文针对的是Linux操作系统的文件系统的组织方式进行讲解。读者不要以这套规则对比windows和macos系统
首先,Linux系统采用的是文件内容和文件属性分开存储的方案!原因很简单:文件内容是经常变化,但是文件的属性几乎不怎么变。如果混合在一起,一旦变就都要跟着变。所以Linux选择把两者分开存储。
文件系统的分治思想
首先我们知道,磁盘能够装在的文件大小是大多是500G甚至是1T。面对如此庞大数量的文件。直接一股脑全部扔给操作系统是不可能的!就如同国家主席管理一整个国家,国家那么大不可能所有事都由国家主席管。那么对应的,如果把国家划分成一个个省。管好其中的一个省,然后借鉴优秀经验管好其他的省就能管好整个国家。如果省还是太大,就继续划分成市。管好每一个城市就能管好省。依次类推。 管理国家还要视情况而定,但是磁盘上全都是01二进制没有任何的区别,完全就可以用上面分治的方法去管理。
500G—>5个100G—>管好其中一个100G,其他4个100G复制前面的管理经验就好了
100G还是太大,在分成5个20G —>管好一个20G ---->剩下4个20G复制前面的管理经验就好了
20G还是太大,---->分成5个4G—>管好一个4G---->剩下的复制前面的管理经验就好了
依次类推
而Linux采取的就是这样的管理方式进行磁盘的管理。
Linux文件系统结构图
整个的Linux系统的文件系统结构图如下
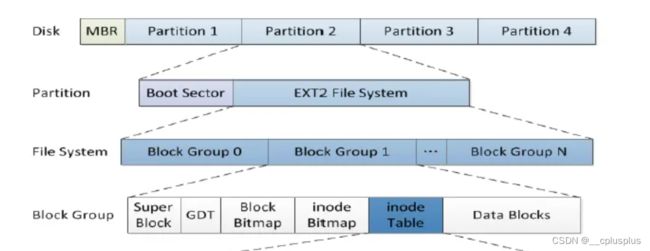
接下来我们来看这个block group的每个组成部分
Boot Block: 存放操作系统相关的启动项说明
Data Blocks:存储实际的文件的内容,也就是数据块
Block Bitmap:记录数据块的使用情况,每一个比特位记录块是否被使用
inode Bitmap:记录inode块是否被使用
innode Table:以128B为单位,进行inode属性保存
inode有一个inode编号,一个文件一个inode号
GDT:记录共有多少块inode,起始的inode号,多少inode被使用,多少block被使用,还剩多少inode和block,总的group大小是多少
superblock:文件系统的顶层数据结构,记录总的分区情况
值得一提的是:在一个组中可能会存在多个superblock,它的目的仅仅只是做一个备份而已。
inode
可能你也注意到了前面的系统结构图里面,这个inode反复出现。那么这个inode究竟是什么?如何理解这个inode?下面我们就来研究一下这个inode。
我们前面知道,Linux不以后缀名区分文件,那么系统底层区分文件靠的就是这个inode! 我们可以通过如下的一条命令查看inode
ls -i #查看对应的文件inode编号
这个inode内部负责存放的就是各种各样文件的属性,我们看看内核中的inode的定义
struct inode {
struct hlist_node i_hash;
struct list_head i_list;
struct list_head i_sb_list;
struct list_head i_dentry;
unsigned long i_ino;
atomic_t i_count;//文件引用计数
umode_t i_mode;
unsigned int i_nlink; //文件硬链接数
uid_t i_uid;//用户pid
gid_t i_gid;//组id
dev_t i_rdev;
loff_t i_size;//文件大小
struct timespec i_atime;
struct timespec i_mtime;
struct timespec i_ctime;
//...很多属性
};
stat命令
而实际上我们还可以通过stat命令具体查看inode的情况
stat filnanme
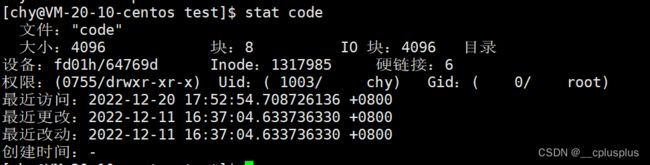
我们知道datablock就是存放文件内容的地方,而datablock存储文件的情况有如下的两种:
1.部分的datablock会保存对应文件的编号
2.有的datablock则会直接保存这个文件所使用别的文件的编号,通常是文件较大的情况会使用这种策略,相当于一个指针数组指向了其他文件。
文件名的作用
前面我们讲了,Linux不以文件名作为区分文件的标识,而是用inode的。那么文件名是否也是文件的属性?当然是!只不过Linux并没有直接把文件名存入到struct inode内部。 况且我们使用rm等一些列命令使用的依旧是文件名!那么Linux是如何把文件名和inode联系在一起的呢?---->通过一种键值映射的方式!,也就是类似于c++中的map容器的
目录文件
Linux下一切皆文件,那么对应的目录也是一个文件。但是目录这个文件比较特殊。它的datablock专门存放的就是这个目录文件里面有的文件名和inode映射,也就是说要想找到这个文件,必须找到文件的inode,而我知道文件名,所以我只能退回寻找对应的文件所在的父目录的datablock找映射,但是我要找父目录的datablock,我就要有父目录的inode,因此我又要回退到父目录的父目录的datablock去寻找,依次回退一直到根目录!也就是任何文件最终都是要从根目录开始向下寻找! 而目录也有权限,对应的权限能够允许你的操作如下
1.r 权限:---->决定了你是否可以查看一个目录里面的内容
2.w 权限---->决定了你是否在目录里面
3.x 权限---->决定你能否进入这个目录
创建/删除文件,内核做了什么
当我们创建文件的时候,内核一般做了如下的事情
1.在inodebitmap中寻找一个尚未使用的比特位,将其由0变1,然后分配给对应的文件使用
2.创建相关的内核数据结构,分配对应的inode编号和block。
3.使用文件的inode找到block,把数据写入对应的block中
而Linux中删除文件的方式也比较简单,就是把对应的位图由1改成0就达到删除的效果了。也就是说所谓的删除,仅仅是伪删除,通过一定的技术手段依旧能找到!但是如果一旦在删除的位置进行重复写入,那么就可能找不回来了!
软硬链接
Linux下存在两种链接的方式---->硬链接和软链接,而创建链接的方式就是使用ln命令。
#使用ln默认就是硬链接,-s选项指明是软链接
ln [source] dest
ln -s [source] [dest]
在正式介绍这二者的区别之前,我们先来使用ls的-i选项来观察一些东西
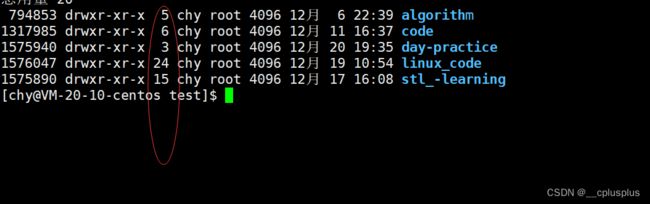
这里的第三个数字先前我们从来没关心过。那么今天我们就来正式介绍一下这三个数字。这三个数字代表的就是当前这个文件的硬链接数。 那么接下来,我们就针对一个文件分别创建硬链接和软链接来观察对应二者的区别
#创建名为Myfile的硬链接
ln myfile.c MyfileC
#创建名为MyfileC.sort的软链接
ln -s myfile.c MfileC.soft

仔细观察,你就会发现硬链接的两个文件的inode是一样的!而软链接的inode是不同于源文件的!也就是说明:软链接本质是建立一个新的文件,而硬链接的本质只是重新建立了一个文件名和inode的映射!也就是说,删除硬链接仅仅只是减少了一个文件名和inode之间的映射!只要还存在>=1的一个映射,那么这个文件依旧有效 而软链接存储的仅仅只是一个被链接文件的路径,为了方便能够找到这个文件,一旦原文件被删除,那么这个保存的路径自然也就没有任何意义了!而删除链接的命令就是unlink
#删除对应的链接
unlink MyfileC
而对于任何一个空目录,对应的硬链接数都是2,原因是除了自身以外还有一个 ‘.’在引用自己,所以硬链接数是2。
以上就是本文主要内容,如果有不足的地方还望指出,希望能够和大家一起进步。