分布式一致Hash&分布式ID
文章目录
-
- 分布式集群一致Hash算法
-
- Hash算法
- 常见的Hash算法
- 冲突解决的策略
- Hash算法应用场景
- 普通Hash算法存在的问题
- 一致Hash算法
-
- Nginx配置一致性Hash负载均衡策略
- 分布式ID解决方案
-
-
- UUID(可以用)
- 独立数据库的自增ID(不推荐)
- SnowFlake 雪花算法(推荐)
- 借助Redis的Incr命令获取全局唯一ID(推荐)
-
分布式集群一致Hash算法
首先来了解一下分布式集群。分布式和集群是两个不同的概念,分布式是指将一个系统拆分后的多个实例,集群是指多个实例一起工作。分布式一定是集群,而集群不一定是分布式,因为复制型的集群不是拆分而是复制。
Hash算法
散列函数也叫Hash算法,主要思想是根据结点的关键码值来确定其存储地址:以关键码值K为自变量,通过一定的函数关系h(K)(称为散列函数),计算出对应的函数值来,把这个值解释为结点的存储地址,将结点存入到此存储单元中。检索时,用同样的方法计算地址,然后到相应的单元里去取要找的结点。通过散列方法可以对结点进行快速检索。散列(hash,也称“哈希”)是一种重要的存储方式,也是一种常见的检索方法。
常见的Hash算法
-
除余法
顾名思义,除余法就是用关键码x除以M(往往取散列表长度),并取余数作为散列地址。除余法几乎是最简单的散列方法,散列函数为: h(x) = x mod M
-
乘余取整法
使用此方法时,先让关键码key乘上一个常数A (0< A < 1),提取乘积的小数部分。然后,再用整数n乘以这个值,对结果向下取整,把它做为散列的地址。散列函数为: hash ( key ) = _LOW( n × ( A × key % 1 ) )。 其中,“A × key % 1”表示取 A × key 小数部分,即: A × key % 1 = A × key - _LOW(A × key), 而_LOW(X)是表示对X取下整。
冲突解决的策略
尽管散列函数的目标是使得冲突最少,但实际上冲突是无法避免的。因此,我们必须研究冲突解决策略。冲突解决技术可以分为两类:开散列方法( open hashing,也称为拉链法,separate chaining )和闭散列方法( closed hashing,也称为开地址方法,open addressing )。这两种方法的不同之处在于:开散列法把发生冲突的关键码存储在散列表主表之外,而闭散列法把发生冲突的关键码存储在表中另一个槽内.
参考链接:https://www.jianshu.com/p/f9239c9377c5
Hash算法应用场景
hash算法在很多分布式集群产品中都有应用,比如分布式集群框架Redis、Hadoop、ElasticSearch、Mysql分库分表、Nginx负载均衡等。
主要的应用场景归纳起来两个:
-
请求的负载均衡(比如nginx的ip_hash策略)
Nginx的ip_hash策略可以在客户端IP不变的情况下,将其发出的请求始终路由到同一个服务器上,实现会话粘滞,避免session共享问题
如果没有ip_hash策略,可以维护一张映射表,存储客户端IP或者sessionid与具体服务器的映射关系
缺点:
1)在客户端很对的情况下,映射表非常大,浪费内存空间
2)客户端上下线、服务器上下线,都会导致重新维护映射表,映射表维护成本很大
如果使⽤哈希算法,事情就简单很多,我们可以对ip地址或者sessionid进⾏计算哈希值,哈希值与服务器数量进⾏取模运算,得到的值就是当前请求应该被路由到的服务器编号,如此,同⼀个客户端ip发送过来的请求就可以路由到同⼀个⽬标服务器,实现会话粘滞。
-
分布式存储
以分布式内存数据库Redis为例,集群中有redis1, redis2, redis3 三台Redis服务器那么,在进⾏数据存储时,
普通Hash算法存在的问题
普通Hash算法存在⼀个问题,以ip_hash为例,假定下载⽤户ip固定没有发⽣改变,现在tomcat3出现了问题, down机了,服务器数量由3个变为了2个,之前所有的求模都需要重新计算。
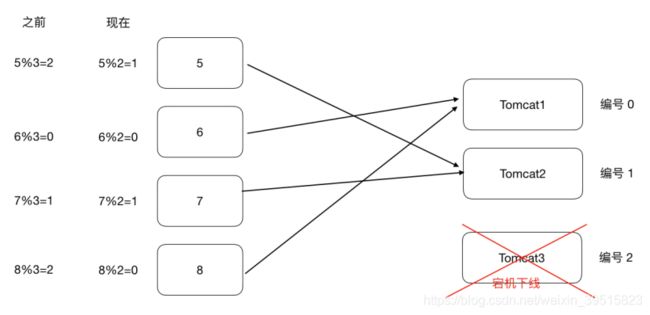
如果在真实生产情况下,后台服务器很多太,客户端也有很多,那么影响是很大的,缩容和扩容都会存在这样的问题,大量用户的请求会被路由到其他服务器处理,用户在原来服务器中的会话都会丢失。
一致Hash算法
一致hash算法的思路首先有一条线,在线上从0开始标记2的32次方的点,每个点代表一个IP地址,然后把线首尾相连构成一个圆环,这个圆环被称为hash环。针对客户端IP和服务端IP进行hash求值,对应在圆环上,客户端按照顺时针方向找到最近的服务节点。

当服务器进行扩容或缩容时,它只会影响它与上一服务节点之间的客户端(请求的迁移达到最小,对分布式集群非常合适,避免了大量请求的迁移)。
但是,当一致哈希算法在服务节点太少时,很容易因节点分部不均匀而造成数据倾斜问题,例如系统中有两台服务器,其环分布如下图所示,节点2只能负责很小的一段,大量的客户端请求落在了节点1上,这就是数据(请求)倾斜问题。
为了解决这种数据倾斜问题,一致性哈希算法引入了虚拟节点机制,即对每个服务节点计算多个哈希,每个计算结果位置都放置一个服务节点,称为虚拟节点。

Nginx配置一致性Hash负载均衡策略
ngx_http_upstrean_consistent_hash模块是一个负载均衡器,使用内部一致性hash算法选择合适的后端节点。
该模块可以根据配置参数采用不同的方式将请求均匀映射到后端服务器:
consistent_hash $remote_addr : 可以根据客户端IP映射
consistent_hash $request_uri : 根据客户端请求的uri映射
consistent_hash $args :根据客户端携带的参数进行映射
ngx_http_upstrean_consistent_hash模块是一个第三方模块,需要下载安装。
1)github下载nginx一致性hash负载均衡模块https://github.com/replay/ngx_http_consistent_hash

- 下载的压缩包上传到nginx服务器,并解压
3)进入nginx的源码目录,执行命令:
./configure --add-module=/root/ngx_http_consistent_hash-master
make
make install
- Nginx配置
upstream consistenServer {
consistent_hash $request_uri;
server 127.0.0.1:8080;
server 127.0.0.1:8090;
}
分布式ID解决方案
-
UUID(可以用)
UUID是指Universally Unique Identifier ——通用唯一识别码
产生重复UUID并造成错误的概率非常低。
Java中可以使用java.util.UUID类。
-
独立数据库的自增ID(不推荐)
单独创建一个Mysql数据库,在数据库中创建一张表,表的ID设置为自增,其他需要全局唯一ID的时候,就模拟向该表中插入一条记录,此时ID自增,然后通过Mysql的
select last_insert_id()获取刚刚这张表中自增生成的ID。例如:
表结构如下:
create table 'distribute_id' ( `id` bigint(32) not null AUTO_INCREMENT comment '主键', ·create_time' datetime default null, primary key ('id') ) engine=InnoDB default charset=urf8;当分布式集群中那个应用需要全局唯一的分布式Id时,可以使用代码链接这个数据库,执行如下sql语句即可:
insert into distribute_id(create_time) values(NOW()); select LAST_INSERT_ID();注意:
1)这里create_time字段无意义,是为了能够插入一条数据。
2)使用独立的Mysql实例生成分布式ID,虽然可行,但是性能和可靠性不够好,因为需要代码链接数据库,另外MySQL数据库实例挂掉,那么就无法获取分部式id
3)过于麻烦
SnowFlake 雪花算法(推荐)
雪花算法是Twitter推出的一个用于生成分布式ID的策略。
雪花算法是一个算法,基于这个算法可以生成ID,生成的ID是一个long型,那么在Java中一个long型是8个字节,算下来是64bit,如下是使用雪花算法生成的一个ID的二进制形式示意:

另外,一些互联网公司也基于上述方案封装了一些分布式ID的生成器,比如滴滴的tinyid(基于数据库实现)、百度的uidgenerator(基于SnowFlake)和美团的leaf(基于数据库和SnowFlake)等。
借助Redis的Incr命令获取全局唯一ID(推荐)
Redis Incr命令将key中储存的数字值赠一,如果key不存在,那么key的值会初始化为0,然后在执行Incr操作。
Java代码中使用Jedis客户端调用Redis的incr命令获得全局唯一的ID
-
引入jedis客户端jar
<dependency> <groupId>redis.clientsgroupId> <artifactId>jedisartifactId> <version>2.9.0version> dependency> -
java代码(此次是连接单点,也不使用连接池)
Jedis jedis = new Jedis("127.0.0.1", 6379); try { long id = jedis.incr("id"); System.out.println("从redis中获取的分布式id为:" + id); } finally { if (jedis != null) { jedis.close(); } }