融合动态反向学习的阿奎拉鹰与哈里斯鹰混合优化算法(DAHHO)-附代码
融合动态反向学习的阿奎拉鹰与哈里斯鹰混合优化算法(DAHHO)
文章目录
- 融合动态反向学习的阿奎拉鹰与哈里斯鹰混合优化算法(DAHHO)
-
- 1.哈里斯鹰优化算法
- 2.改进哈里斯鹰优化算法
-
- 2.1 动态反向学习策略
- 2.2 改进混合算法理论分析
- 3.实验结果
- 4.参考文献
- 5.Matlab代码
- 6.python代码
摘要: 阿奎拉鹰优化算法(Aquila optimizer, AO)和哈里斯鹰优化算法(Harris hawks optimization, HHO)是近年提出的优化算法。AO算法全局寻优能力强,但收敛精度低,容易陷入局部最优,而HHO算法具有较强的局部开发能力,但存在全局探索能力弱,收敛速度慢的缺陷。针对原始算法存在的局限性,本文将两种算法混合并引入动态反向学习策略,提出一种融合动态反向学习的阿奎拉鹰与哈里斯鹰混合优化算法。首先,在初始化阶段引入动态反向学习策略提升混合算法初始化性能与收敛速度。此外,混合算法分别保留了AO的探索机制与HHO的开发机制,提高算法的寻优能力
1.哈里斯鹰优化算法
基础哈里斯鹰优化算法的具体原理参考,我的博客:https://blog.csdn.net/u011835903/article/details/108528147
2.改进哈里斯鹰优化算法
2.1 动态反向学习策略
本文引人动态反向学 习策略, 提高初始化解的质量, 计算方法如下为
X DOBL = X init + r 18 × ( r 19 × ( L B + U B − X init ) − X init ) \boldsymbol{X}_{\text {DOBL }}=\boldsymbol{X}_{\text {init }}+r_{18} \times\left(r_{19} \times\left(\mathrm{LB}+\mathrm{UB}-\boldsymbol{X}_{\text {init }}\right)-\boldsymbol{X}_{\text {init }}\right) XDOBL =Xinit +r18×(r19×(LB+UB−Xinit )−Xinit )
式中: X i n i t X_{\mathrm{init}} Xinit 代表通过随机生成的初始化种群; r 18 r_{18} r18 与 r 19 r_{19} r19 均为分布在 0 ∼ 1 0 \sim 1 0∼1 的随机数。首先, 算法分别 生成原始初始化种群 X i n i t \boldsymbol{X}_{\mathrm{init}} Xinit 与反向初始种群 X D O B L \boldsymbol{X}_{\mathrm{DOBL}} XDOBL, 然后将两个种群合并为新种群 X n e w = { X D O B L ∪ \boldsymbol{X}_{\mathrm{new}}=\left\{\boldsymbol{X}_{\mathrm{DOBL}} \cup\right. Xnew={XDOBL∪ X init } \left.X_{\text {init }}\right\} Xinit } 。计算新种群的适应度值, 并利用贪婪策略 使种群内部充分竞争, 选取最佳的 N N N 个个体作为 初始化种群。通过此方法能够让种群更快地靠近 最优解, 从而提升算法的收敛速度。
2.2 改进混合算法理论分析
阿奎拉鹰根据不同猎物 会采取 4 种不同的捕食行为。在前期迭代中, 根 据随机数 r 1 r_1 r1 选择高空飞行搜索或环绕猎物飞行, 这两种探索方式主要针对快速移动的猎物。因此 位置更新中分别考虑了阿奎拉鹰种群的最佳位 置、平均位置和随机位置, 式 (1) 利用种群最佳位 置和平均位置实现整体种群在搜索空间内的大范 围搜索, 式 (3) 利用莱维飞行配合最佳位置实现 搜索空间的大范围随机扰动,体现算法较强的全 局探索能力。当迭代次数 t > ( 2 3 × T ) t>\left(\frac{2}{3} \times T\right) t>(32×T) 时, 根据随机 数 r 4 r_4 r4 选择低空飞行攻击或地面近距离攻击策略, 这两种攻击方式主要针对移动速度较慢的猎物, 体现算法的局部搜索能力。然而,根据生物特性 来看, 阿奎拉鹰倾向于单独狩猎, 且地面移动能力较弱, 无法对地面上猎物实行有效攻击。从数 学描述来看, 局部开发过程并没有对选定的搜索 空间进行充分搜索, 其中莱维飞行的作用也很 弱, 根据适应度进行位置更新加剧了局部最优停 滞。此外, AO 算法仅是根据迭代次数进行阶段 划分, 无法有效平衡算法全局阶段与局部阶段。 因此, A O \mathrm{AO} AO 算法全局探索阶段随机性较强, 种群在 搜索空间覆盖面广, 不易错失关键的搜索信息, 而局部开发阶段容易陷人局部最优。HHO 则根据猎物的能量衰减实现全局到局部搜索的过 渡。探索过程主要依靠最优个体信息, 没有与其 他个体交流, 引发种群多样性下降, 导致收玫速 度较慢。随着迭代次数的增加, 猎物的能量下 降, 进人局部开发阶段, 根据猎物能量和逃逸概 率采取 4 种不同的捕食策略。当逃逸概率 r 16 ⩾ 0.5 r_{16} \geqslant 0.5 r16⩾0.5 时, 通过猎物能量选择软包围或硬包围, 分别根 据自身与猎物的距离和猎物的位置进行位置更 新。否则, 通过猎物能量选择渐进式快速俯冲的 软包围或硬包围, 两种方式均加人了莱维飞行 项, 并根据适应度判断使用莱维游走还是快速俯 冲攻击, 使算法能够有效跳出局部最优。总的来 说, A O \mathrm{AO} AO 的全局搜索和 H H O \mathrm{HHO} HHO 的局部搜索分别是该 两种算法的核心特点, 本文将 A O \mathrm{AO} AO 的全局探索阶 段和 HHO 的局部探索阶段相结合, 充分发挥两 种算法的优势,保留算法的全局探索能力、较快 的收玫速度和跳出局部最优的能力。此外, 在初 始化阶段引人动态反向学习策略, 进一步提升算 法初始化种群质量, 使混合算法的收敛速度和精度都得到提高,增强了算法的整体寻优性能。
DAHHO 算法步骤如下:
- 初始化种群, 计算动态反向学习种群, 根据贪婪策略保留较优个体进人主程序迭代。
2)计算种群适应度值,记录较优个体。
3 ) 如果 ∣ E ∣ ⩾ 1 |E| \geqslant 1 ∣E∣⩾1, 个体随机选择式 (1) 或式 (3) 开始探索行为。 - 如果 ∣ E ∣ < 1 |E|<1 ∣E∣<1, 种群根据逃逸猎物能量值与 适应度值选择开发策略:
策略 1 软包围。当 r 16 ⩾ 0.5 r_{16} \geqslant 0.5 r16⩾0.5 且 ∣ E ∣ ⩾ 0.5 |E| \geqslant 0.5 ∣E∣⩾0.5, 子 群个体采用式 (11) 更新位置。
策略 2 硬包围。当 r 16 ⩾ 0.5 r_{16} \geqslant 0.5 r16⩾0.5 且 ∣ E ∣ < 0.5 |E|<0.5 ∣E∣<0.5, 子 群个体采用式 (4) 更新位置。
策略 3 渐近式快速俯冲软包围。当 r 16 < 0.5 r_{16}<0.5 r16<0.5 且 ∣ E ∣ ⩾ 0.5 |E| \geqslant 0.5 ∣E∣⩾0.5, 子群个体采用式 (5)、(6)、(7) 更新 位置。
策略 4 渐近式快速俯冲硬包围。当 r 16 < 0.5 r_{16}<0.5 r16<0.5 且 ∣ E ∣ < 0.5 |E|<0.5 ∣E∣<0.5, 子群个体采用式 (6)、(7)、(8) 更新位置。 - 判断程序是否满足终止条件, 满足则跳出 循环, 否则返回步骤 2 。
- 输出最佳位置及适应度值。
3.实验结果
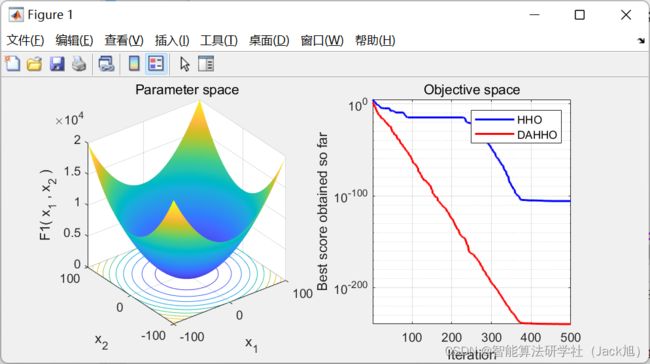
4.参考文献
[1]贾鹤鸣,刘庆鑫,刘宇翔等.融合动态反向学习的阿奎拉鹰与哈里斯鹰混合优化算法[J].智能系统学报,2023,18(01):104-116.