numpy(一):numpy的创建数组+基本属性+numpy随机数组+数组的访问+数组的变换
文章目录
- 一、了解nump
- 二、numpy的基本属性
- 三、numpy中数组的多种创建方法
-
- 1.array()
- 2.arang(),等差数列
- 3.linspace(),等差数列
- 4.logspace(),等比数列
- 5.zeros()和ones(),占位数组
- 6.empty()
- 7.eye(),单位矩阵
- 8.diag(),对角矩阵
- 四、常见的4个numpy的随机生成数组方法
- 五、数组的变换
-
- 1.shape和reshape()
- 2.展平数组:ravel()和flatten()
- 3.ravel 和 flatten 区别(面试题)
- 4.组合数组:hstack和vstack
- 5.组合函数:concatenate()函数和轴
- 六、数组的访问---通过索引
-
- 1.访问一维数组
- 2.访问二维数组
- 3.遮罩mask
- 七、numpy中的数据类型和自定义数据类型
一、了解nump
1.特点
- numpy的主要对象是同种元素的多维数组
- numpy底层是用C实现
- python执行效率低,编程效率高
2.面试题:数组和列表的区别
数组和列表结构相似,用法有些区别,比如数组存储的是相同类型的数据,执行速度较快。但是列表可以存储其他类型的数据,甚至可以嵌套字典列表等,因此处理的时候较慢,再加上python语言本身执行效率比编译型语言运行慢,所以列表比字典执行效率低。
二、numpy的基本属性
| 属性 | 作用 |
|---|---|
| arr1.shape | 数组的维度 |
| arr1.ndim | 数组的秩,也是求出的维度的长度 |
| arr1.size | 数组元素的总个数 |
| arr1.dtype | 数组的类型(int32,int64,float32等) |
| arr3.itemsize | 每个元素的字节大小(字节byte--------位bit(8byte=1bit)) |
| arr1.data | 缓冲区data |
举例:
import numpy as np
# ------------------------------------一维数组
a1 = np.array([1, 2, 3, 4, 5])
print('a1的维度:', a1.shape) # a1的维度: (5,)
print('a1的秩求法1:', a1.ndim) # a1的秩求法1: 1
print('a1的秩求法2:', len(a1.shape)) # a1的秩求法2: 1
print('a1的数组元素个数:', a1.size) # a1的数组元素个数: 5
print('a1的缓存区:', a1.data) # a1的缓存区: 注意:numpy中的一维数组的shape理解
- 上述一维数组维度(5,),意思是一维数组,数组中有五个元素
- 上述二维数组维度(3,3),意思是二维数组,每个维度中三个元素
三、numpy中数组的多种创建方法
| 创建数组的函数 | 作用 |
|---|---|
| np.array() | 内部填充列表或元组,可一维数组可二维数组 |
| np.arange() | 左闭右开,类似range函数,可以设置范围和步长 |
| np.linspace() | 左闭右闭,等差数列数组,可以指定范围和个数 |
| np.logspace() | 等比数列,指定范围和个数和公比 |
| np.zeros() | 占位数组,用0占位,可以设置形状 |
| np.ones() | 占位数组,用1占位,可以设置形状(2,3) ,一维数组直接写长度 |
| np.empty() | 随机数组,可以设置形状(直接写行和列) ,一维数组直接写长度 |
| np.eye() | 单位矩阵 |
| np.diag() | 对角矩阵 |
1.array()
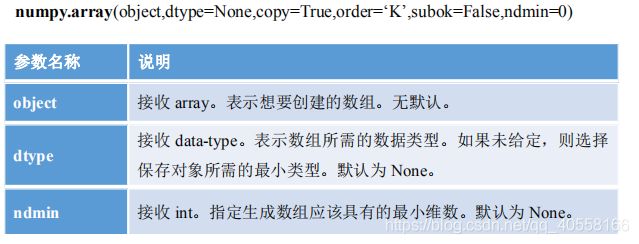
注意:
- ①在创建多维数组的时候,[ ]和( )均可以
- ②切记数组中的类型是相同的
# 不指定数组类型
print(np.array([1, 2, 3]))
print(np.array([[1, 2, 3], [4, 5, 6]]))
print(np.array([(1, 2, 3), (4, 5, 6)]))
'''
结果:
[1 2 3]
[[1 2 3]
[4 5 6]]
[[1 2 3]
[4 5 6]]
'''
#指定数据类型
print(np.array([1,2,3],dtype=np.float64)) # [ 1. 2. 3.]
2.arang(),等差数列
通过指定开始值、终值和步长创建表示等差数列的一维数组,注意得到的结果数组不包含终值。
# 创建一个start开始,stop结尾,步长为step的数组
arange(start=None, stop=None, step=None, dtype=None)
参数说明:
- start 起始数字,stop 终止数字。
- 左闭右开。
- step 步长,dtype类型
import numpy as np
print(np.arange(3, 9)) # 默认步长为1 [3 4 5 6 7 8]
print(np.arange(1.1, 1.9, 0.1)) # [ 1.1 1.2 1.3 1.4 1.5 1.6 1.7 1.8]
3.linspace(),等差数列
通过指定开始值、终值和元素个数创建表示等差数列的一维数组,可以通过endpoint参数指定是否包含终值,默认值为True,即包含终值。
linspace(start, stop, num=50, endpoint=True, retstep=False, dtype=None)
参数介绍:
- start 起始数字,stop 终止数字。
- num 在范围内生成的数组的个数
- 左闭右闭。
import numpy as np
print(np.linspace(1, 10, 10))
# [ 1. 2. 3. 4. 5. 6. 7. 8. 9. 10.]
#默认是小数
4.logspace(),等比数列
返回在对数刻度上均匀间隔的数字;即可以通过np.logspace方法创建等比数列数组。
logspace(start, stop, num=50, endpoint=True, base=10.0, dtype=None)
参数介绍:
- start 起始数字,stop 终止数字,num数量
- 左闭右闭
arr6 = np.logspace(1, 3, 3) # 从1次开始到3次结束,数量3个,以十开始的等比数列
print(arr6) # [ 10. 100. 1000.]
arr7 = np.logspace(1, 3, 3, base=2)
print(arr7) # [ 2. 4. 8.]
5.zeros()和ones(),占位数组
zeros(shape, dtype=None, order='C')
ones(shape, dtype=None, order='C')
参数介绍:
- 几位几列,通常传入一个数组,例如两行三列(2,3)
# zeros()使用0进行占位的数组,ones用法相同
np.zeros((2, 3))
'''
[[ 0. 0. 0.]
[ 0. 0. 0.]]
'''
np.zeros(5)
'''
[ 0. 0. 0. 0. 0.]
'''
6.empty()
创建一个内容随机且依赖于内存状态的数组,根据给定的维度和数值类型返回一个新的数组,其元素不进行初始化。
empty(shape, dtype=None, order='C')
参数介绍:
- 几位几列,通常传入一个数组,例如两行三列(2,3)
np.empty((2, 3))
'''
结果:
[[ 2.47032823e-322 0.00000000e+000 0.00000000e+000]
[ 0.00000000e+000 0.00000000e+000 0.00000000e+000]]
'''
7.eye(),单位矩阵
np.eye(3) # 生成3阶单位矩阵
'''
[[ 1. 0. 0.]
[ 0. 1. 0.]
[ 0. 0. 1.]]
'''
8.diag(),对角矩阵
np.diag([1,2,3,4])
'''
结果:
[[1 0 0 0]
[0 2 0 0]
[0 0 3 0]
[0 0 0 4]]
'''
四、常见的4个numpy的随机生成数组方法
| 随机生成数组的函数 | 作用 |
|---|---|
| np.random.random(n) | 生成0,1范围的数组,n为元素个数,左闭右开 |
| np.random.rand(m,n) | 生成0,1范围的数组,形状为m*n,左闭右开 |
| np.random.randn(n) | 生成正太形式的随机数组,n为元素个数 |
| np.random.randint(m,n,size) | 生成m,n范围的数组,形状为size(传入元组形式的shape) |
1.random.random(n)#[0,1),n为元素个数
import numpy as np
arr1 = np.random.random(3)
print(arr1)
arr2 = np.random.random(15).reshape((3, 5)) # 三行五列
print(arr2)

2.random.rand(m,n)-------生成m*n的数组,前闭后开[0,1)
print(np.random.rand(2,3))

3.random.randn(n)-------生成正太的随机数,n为数量
arr4 = np.random.randn(20000)
# 画图模块查看正太分布
import matplotlib.pyplot as plt
plt.hist(arr4)
plt.show()

4.random.randint()#左闭右闭
print(np.random.randint(2, 33, size=(2, 5)))# 从2,33,随机生成一个两行五列

五、数组的变换
| 函数 | 作用 | 区别 |
|---|---|---|
| array.shape=(2,3) | 将数组形状改为(2,3) | |
| array.reshape((2,3)) | 将数组形状改为(2,3) | |
| ravel(array) | 将多维数组改为一维数组 | 视图view:侧重的是数据的展现,而不是数据的本身–使用ravel返回的是一份视图,类似浅拷贝 |
| flatten(array) | 将多维数组改为一维数组 | 拷贝copy:强调的是数据–使用flatten返回的是一份拷贝,类似深拷贝 |
| hstack(arr1,arr2) | 将两个数组按行横向拼接 | |
| vstack(arr1,arr2) | 将两个数组按列纵向拼接 | |
| concatenate((arr1, arr2), axis=1) | 和hstack效果相同,将两个数组按行横向拼接 | |
| concatenate((arr1, arr2), axis=0) | 和vstack效果相同,将两个数组按列纵向拼接 |
1.shape和reshape()
- shape属性可以求出几维数组,返回的是一个元组(行,列),也可以单独设置shape,这样会将shape的值重新规划
- reshape可以重新规划数组
a1 = np.array([1, 2, 3, 4, 5, 6])
print(a1.shape)
a1.shape = (2, 3)
print(a1)
a2 = np.array([1, 2, 3, 4, 5, 6]).reshape((2, 3))
print(a2)

2.展平数组:ravel()和flatten()
①ravel()
arr1 = np.arange(10000)
arr2 = arr1.reshape((100, 100))
arr3 = arr2.ravel()
print(arr1)
print(arr2)
print(arr3)
# 当numpy数据太大的时候,中间会用...省略,但是我们非要看中间的,需要设置
np.set_printoptions(threshold=np.NAN)
print(arr1)

②flatten()
arr1 = np.arange(10).reshape((2, 5))
arr2 = arr1.flatten()
arr3 = arr1.ravel()
print(arr1)
print(arr2)
print(arr3)

3.ravel 和 flatten 区别(面试题)
- 共同点: 都可将多维数组降为一维数组
- 区别:
①拷贝copy:强调的是数据–使用flatten返回的是一份拷贝,类似深拷贝
②视图view:侧重的是数据的展现,而不是数据的本身–使用ravel返回的是一份视图,类似浅拷贝
a1 = np.array([[1, 2], [3, 4]])
f_a = a1.flatten() #
r_a = a1.ravel()
print(a1)
print(f_a) # [1 2 3 4]
print(r_a) # [1 2 3 4]
a1[1][1] = 1111
print('--------------------类似深拷贝,自己或者原数组改变,不会影响对方----------')
f_a[2] = 100
print(f_a) # [ 1 2 100 4]
print(a1) # 不变
print('---------------------类似浅拷贝,自己或者原数组改变,会互相改变--------')
r_a[2] = 100
print(r_a) # [ 1 2 100 1111]
print(a1) # 变化

4.组合数组:hstack和vstack
一维数组: hstack和vstack
arr1 = np.arange(1, 6, 2) # [1 3 5]
arr2 = np.arange(7, 12, 2) # [ 7 9 11]
arr3 = np.hstack((arr1, arr2)) # 横行拼接
arr4 = np.vstack((arr1, arr2)) # 纵向拼接
print(arr3)
print(arr4)

二维数组: hstack和vstack
# 二维数组
arr1 = np.array([[1, 2, 3], [4, 5, 6]])
arr2 = np.array([[7, 8, 9], [10, 11, 12]])
arr3 = np.hstack((arr1, arr2)) # 横行拼接
arr4 = np.vstack((arr1, arr2)) # 纵向拼接
print(arr3)
print(arr4)

注意:
- 长度不相同的两个数组,无法纵向拼接会报错
- 在stack中,参数为列表或者数组
5.组合函数:concatenate()函数和轴
arr1 = np.array([[1, 1], [2, 2]])
arr2 = np.array([[3, 3], [4, 4]])
print(np.concatenate((arr1, arr2), axis=0)) # 和vstack效果相同
print(np.concatenate((arr1, arr2), axis=1)) # 和hstack效果相同
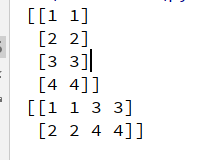
六、数组的访问—通过索引
1.访问一维数组
arr1 = np.arange(10)
print(arr1[3]) # 3
print(arr1[2:6]) # [2 3 4 5]
print(arr1[:2]) # [0 1]
print(arr1[::-1]) # [9 8 7 6 5 4 3 2 1 0]
arr1[2:4] = 111, 111
print(arr1)#[ 0 1 111 111 4 5 6 7 8 9]
2.访问二维数组
arr2 = np.array([[1, 1, 1, 1], [2, 2, 2, 2], [3, 3, 3, 3]])
print(arr2)
# 拿出第一行的第三个和第四个数据
print(arr2[0][2:])
print(arr2[0, 2:])
arr3 = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
# 取出1,3行的所有数据
print(arr3[(0, 2), :])
# 对于自定义类型的多维数组,可以采取键名拿数据
df = np.dtype([('name', np.str_, 40), ('numitems', np.int64), ('price', np.float64)])
print('df数据结构为:', df) # [('name', '
table1 = np.array([('apple', 12, 1.32), ('banana', 22, 3.26)], dtype=df)
print(table1['name'])

3.遮罩mask
arr3 = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
mask = np.array([True, False, True])
print(arr3[mask, 2])
#true为显示,false不显示,1,3行显示,然后列为2的,所以结果为:[3,9]
七、numpy中的数据类型和自定义数据类型
| 类型 | 描述 |
|---|---|
| bool_ | 布尔型数据类型(True 或者 False) |
| int_ | 默认的整数类型(类似于 C 语言中的 long,int32 或 int64) |
| intc | 与 C 的 int 类型一样,一般是 int32 或 int 64 |
| intp | 用于索引的整数类型(类似于 C 的 ssize_t,一般情况下仍然是 int32 或 int64) |
| int8 | 字节(-128 to 127) |
| int16 | 整数(-32768 to 32767) |
| int32 | 整数(-2147483648 to 2147483647) |
| int64 | 整数(-9223372036854775808 to 9223372036854775807) |
| uint8 | 无符号整数(0 to 255) |
| uint16 | 无符号整数(0 to 65535) |
| uint32 | 无符号整数(0 to 4294967295) |
| uint64 | 无符号整数(0 to 18446744073709551615) |
| float_ | float64 类型的简写 |
| float16 | 半精度浮点数,包括:1 个符号位,5 个指数位,10 个尾数位 |
| float32 | 单精度浮点数,包括:1 个符号位,8 个指数位,23 个尾数位 |
| float64 | 双精度浮点数,包括:1 个符号位,11 个指数位,52 个尾数位 |
| complex_ | complex128 类型的简写,即 128 位复数 |
| complex64 | 复数,表示双 32 位浮点数(实数部分和虚数部分) |
| complex128 | 复数,表示双 64 位浮点数(实数部分和虚数部分) |
自定义数据类型:
# 创建一个存储餐饮企业库存信息的数据类型
# (1)用一个长度为40的字符串来记录商品的名称
# (2)用一个长度64的整数来记录商品库存
# (3)用一个64为单精度浮点数来记录商品的价格
df = np.dtype([('name', np.str_, 40), ('numitems', np.int64), ('price', np.float64)])
print('df数据结构为:', df)
table1 = np.array([('apple', 12, 1.32), ('banana', 22, 3.26)], dtype=df)
print(table1)
print(table1['name'])
