Linux——IP协议1
目录
协议头格式
如何封装和解包
如何交付(分用)
报头每一个字段
分片是怎么做到的
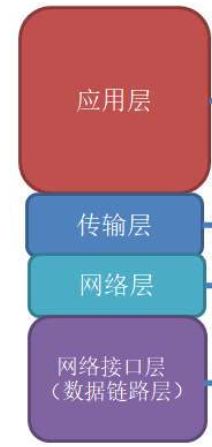
应用层解决的是数据使用的问题。
在传输层,网络层,数据链路层:解决的是网络通信的细节,将数据可靠的从A主机跨网络发送到B主机。
可靠性由传输层决定,从主机A送到主机B由网络层决定。
IP协议主要是提供一种能力,将数据从A主机送到B主机的能力。有这种能力,一定能把数据送给对方吗?不能,有能力是指有很大概率能做成,而不是一定能做成。
 主机: 配有IP地址, 但是不进行路由控制的设备;
主机: 配有IP地址, 但是不进行路由控制的设备;
路由器: 即配有IP地址, 又能进行路由控制;
节点: 主机和路由器的统称;
协议头格式
 数据部分有TCP数据段
数据部分有TCP数据段

如何封装和解包
IP协议也是固定长度的报文,前20个字节就是固定的,也可携带选项。读取前20个字节,就能读取到报头的相关属性了,先读取前20字节,再读取4位首部长度,用首部长度减去20字节,得到的就是选项。如果没有选项,4位首部长度就是5(0101).
IP采用的是定长报头和子描述字段。
如何交付(分用)
8位协议表示有效载荷部分表示是UDP还是TCP,根据8位协议决定交给TCP还是UDP。
报头每一个字段
4位版本:就是IPV4,指定IP协议的版本, 对于IPv4来说, 就是4
IPV6和IPV4差别:IPV4是4字节,32个比特位来表示IP地址,IPV6用128位比特位表示IP地址。但IPV6和IPV4是不兼容的。现在所有的计算机用的都是IPV4。
4位首部长度:IP地址表示报头长度用4个比特位表示,即十进制下0-15,4位首部长度有自己的单位,基本单位是4字节,即整个报文的宽度0-32比特位,假设4位首部长度是4,整个报文长度就是4*x,即最终能表示0-60的数字。
8位服务类型:3位优先权字段(已经弃用), 4位TOS字段, 和1位保留字段(必须置为0). 4位
TOS分别表示: 最小延时, 最大吞吐量, 最高可靠性, 最小成本. 这四者相互冲突, 只能选择一个. 对于ssh/telnet这样的应用程序, 最小延时比较重要; 对于ftp这样的程序, 最大吞吐量比较重要.
16位总长度:IP数据报整体占多少个字节,有效载荷=16位总长度-4位首部长度*4
生存时间:当一个报文进行转发的时候,可能会由于路由器问题,导致报文在路由器里长时间转发,经过了大量路由器,为了防止出现环路转发的情况,给每个报文设置了生存时间。 生存时间本质是一个计数器,每转发一次,计数器--,当生存时间为0时,便不在路由器中转发,直接丢弃。
16位首部校验和:如果首部校验失败,报文就被直接丢弃,我们不用担心报文被丢弃,发送方主机会重传。
32位源IP:数据包从哪来
32位目的IP:数据包到哪去。
IP报文的形式和TCP报文非常类似,因此称为TCP/IP协议。
链路层由于物理特征的原因,一般无法转发太大的数据,链路层有一次可以转发到网络的报文大小的限制。一般是1500字节,一般称为MTU(最大传输单元),若网络层要向下交付2500字节数据,网络层就需要做一件事情:“数据分片。”
分片之后,又由谁来组装? 谁分片,谁组装(对端网络层),谁污染,谁治理。
分片是将一个较大的IP报文,分割成多个较小的 ,满足条件的报文,分片的行为是网络层大的,同样组装的行为也必须由对方的网络层做。
对方为什么要组装?因为对方给自己的网络层是一个完整的TCP报文,接收方在网络层向上交付也必须是一个完整的报文。IP分片和组装的行为,TCP是不知道,不关心的。
分片是怎么做到的

16位标识是IP报文的序号,可根据这个序号区分报文,唯一的标识主机发送的报文. 如果IP报文在数据链路层被分片了, 那么每一个片里面的这个id都是相同的
3位标志:第一位保留(保留的意思是现在不用, 但是还没想好说不定以后要用到). 第二位置为1表示禁止分片, 这时候如果报文长度超过MTU, IP模块就会丢弃报文. 第三位表示"更多分片", 如果分片了的话,最后一个分片置为0, 其他是1. 类似于一个结束标记,一般情况下如果没有被分片,更多分片标志位的最后一位是0。
13位分片偏移:是分片相对于原始IP报文开始处的偏移. 其实就是在表示当前分片在原报文中处在哪个位置. 实际偏移的字节数是这个值 * 8 得到的. 因此, 除了最后一个报文之外, 其他报文的长度必须是8的整数倍(否则报文就不连续了)。
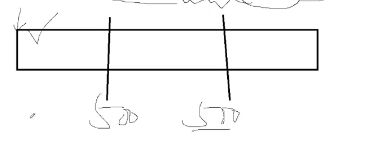
报文长度是1500字节,分成三份,第一个片偏移量0,第二个500,第三个1000.
更多分片是1代表该分片后面还有分片:如下面这张图里更多分片是1,1,0。
虽然有分片,但分片行为不是主流,能一次交付就尽量一次交付。
接收方若要组装,就要识别出报文和报文的不同(通过16位标识区分,不同报文标识不同,相同报文的分片,标识是相同的。)
还要能识别该报文是否被分片了。如果3位标志的第三位“更多分片”标志位是1,就代表它被分片。
如果“我”就是最后一个分片,那么我的“更多分片”标志位就是0。13位片偏移一定不为0,因为“我”前面一定有报文。
即一个报文没被分片,更多分片标志位是0,而且13位片偏移也是0。
判断是否被分片的伪代码

当我们收到一批报文时,先尽可能的讲报文的分片,区分出来,并放在一起。
又识别出哪些分片是开始,哪些分片是中间,哪些分片是结尾呢?
区分开始:只要是分片的,更多分片是1,片偏移是0。
区分结尾:更多分片为0,片偏移不是0,中间报文可能会有多个。
区分中间:更多分片是1,片偏移不是0.
我们如何保证把分片收全了呢?如果在组装过程中,任何一个分片丢失,也要识别出来,那如何识别呢?
ID:1234
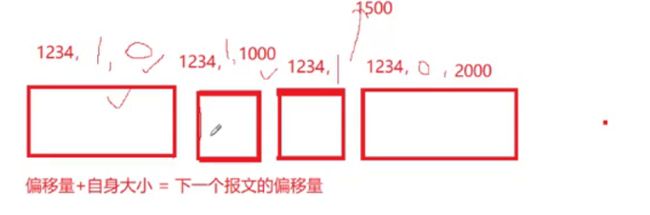
根据偏移量来进行升序排序,结合偏移量+自身大小=下一个报文的偏移量大小,来扫描整个报文,如果不匹配,中间一定会有丢失的,如果成功计算到结尾,就一定收取完整了。
根据3位标志和13位片偏移,可以进行组装。
在组装过程中,如果某报文丢了,偏移量就会对不上,这样就能找到丢失的片段。
分片之前,一定是一个独立的IP报文。分片之后,是每一个分片都要有IP报头,还是直接进行分片而且报头跟着第一个分片就行。
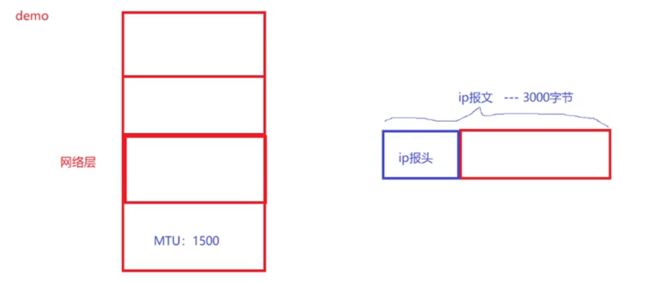
答案是每一个分片都要有IP报头,这样才能进行之后的组装,因为如果没有IP报头,接收方无法接收。
而上图中的3000字节,,MTU是1500,如何分呢?报文标识是1234
第一个报文

由于进行了分片,新报文的报头也要变,如16为总长度会变小,由3000变为1500.
对于剩下的1500字节的报文,又该如何发送?
若直接加报头,则整个报文会变为1520字节
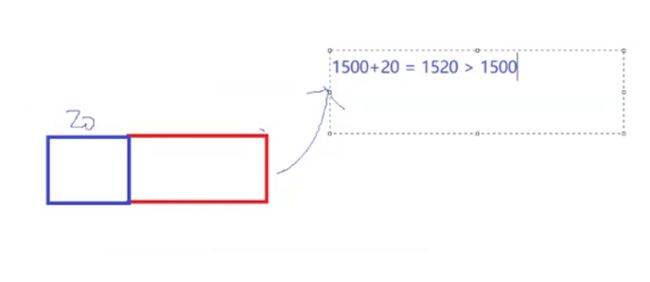
因此我们要继续拆分,拆个1480出来,再添加20字节的IP报头。

之后再对剩余的20字节做同样处理。该偏移量是原始报文的偏移量1500+1480

分片我们严重不推荐,分片坏处是什么?
在网络层分片和组装的过程中,上层(网络层和应用层)是不知道的,它们只知道这是一个完整的报文,网络通信的时候丢包是有概率的,分片增加了丢包概率。
上面的问题不是网络层说了算,要彻底解决问题,要在上层的传输层找答案。