Linux 配置系统白名单 gcc/g++
推荐书籍《程序员的自我修养》《深入理解计算机系统》
配置系统白名单
我们在使用普通用户的时候,有些时候需要使用 sudo 指令来对某一条指令直接进行权限提升,因为某一些指令可能因为使用的路径或者其他原因,普通用户没有权限使用这个命令,那么可以使用sudo来暂时对某一条命令进行权限的提升,从而使用root 的权限来使用某条命令。但是,不是所有的普通用户都有权限来使用 sudo 命令,他必须是 root 用户添加到系统白名单里面用户才能使用 sudo 命令。
如下所示,该用户没有 被系统添加到白名单当中:

当我们输入自己的(该用户)的密码之后,报错提示:该用户不在白名单用户当中,所以我们每一执行这一条通过 sudo 权限提升的命令。
这个 sudoers 这个白名单文件的路径如下所示:
/etc/sudoers该文件的属性:
![]()
我们发现这个文件的拥有者是root,而拥有者,所属组,的权限都是只读的,而其他人更是没有权限。我们知道,在Linux当中的普通用户是受权限约束的,而root 账户是不受权限约束的,所以这个文件理论上之后root 账户能修改。这也正是我们所希望的,这个白名单的权限已经上升到root了,root账户肯定不想让其他用户给自己的操作系统挖坑,然后这个坑还需要自己填上。
所以,当我们用普通用户的身份,不说改了,连查看这个文件的权限都没有:
我们使用vim 查看这个文件:

提示,没有权限。
![]()
使用root 账号来访问这个 文件:
![]()
打开文件,一般是在文件的100行左右,会出现如下所示的内容,这就是当前的白名单用户了:

此时在我的 sudoers文件当中只有 root 用户,我们可以 yy 复制一下 上述 root 这一行的内容,然后把 root 名改为我们想要添加的用户名,这样我们就可以添加一个普通用户带白名单了。

如上所示,我们就成功的添加了pzz这个白名单了。
然后我切换到pzz 这个用户使用sudo命令:
在输入密码之后,就成功的创建了这个文件:

但是我们一般不建议把普通用户添加到白名单当中,因为权限的约束可以帮助我们正确的使用Linux,方式误操作造成的一些不好后果,比如误删 操作系统文件等等。
gcc/g++ 编译器的使用
gcc 只能用户编译 c 的代码,而 g++ c/c++ 都可以编译。
在 Linux 当中,C/C++ 的头文件是在如下目录当中存储的:
/usr/include 路径文件如下所示:
首先我们先来了解一下C源代码生成的可执行程序的过程,在编译之前,编译器要先对源文件进行预处理,预处理就是把 注释去掉,把头文件引入(就是把引用头文件的地方替换为头文件当中的内容),替换宏,条件编译。这些操作,如下所示,生成 .i 文件:
![]()
text_pzz.c 源文件生成的 预处理文件:text_pzz.i :

我们在 windows / Linux 当中编写的C/C++ 代码是在 C/C++ 环境下编译的,也就是说,我们想要编写代码就需要有对应的环境,我们在Linux当中是直接可以使用 gcc 这个编译器来进行编译的,因为这是已经安装好的了环境,而且windows当中我们不能直接进行 C/C++代码的编写,像其中的头文件就需要我们手动去安装,而上述的替换就是把我们安装好的头文件,拷贝到引用头文件的位置。
其实我们在安装 vs2019 的时候,如果想要编写 C/C++ 代码,是需要安装对应的安装包的,而这个我们安装这个安装包就是在安装 C/C++ 的头文件和库文件等等的环境。
我们发现,text_pzz.i 文件在前面多了很多行代码,这些都是替换的头文件当中代码。

上述是去掉的注释。

上述是条件编译,意思是如果定义了 Debug 这个宏,那么就执行ifdef 当中语句,否则执行 else 当中语句,上述程序没有定义这个宏,所以替换的是 printf("not Debug"); 这条语句。
除了在源文件当中定义宏,我们也可以在 Linux 命令行(gcc当中)当中定义宏:
gcc -E text_pzz.c -o text_pzz.i -DDebug
上述使用 -DDebug 这样的方式定义了 Debug 这个宏,然后我们查看的生成的 预处理文件:

那么上述使用gcc来定义 一个宏,之前我们说过的 gcc 还可以拷贝头文件,去注释等等的操作,说明编译器具有直接修改代码的能力,具有文本修改的能力,所以我们可以在编译器编译代码之前给这个代码定义一个宏。
条件编译的作用远不在于判断宏的定义,举个例子:
我们在下载软件的过程当中,会遇到 家庭版,专业版等等的这个软件的不同选择方案,如果某个软件,这个公司的开发方案就是 一个家庭版一个专业版两种方案,那么是不是就意味着,这个公司将来在更新这个软件,或者是维护这个软件的时候,是不是就要维护/更新两份代码;如果某一个方案的代码更新了bug,那么另一份代码也需要更新bug,但是只要是做种方案的更新就意味着需要多一分测试开发的操作,就非常的麻烦。
所以,公司里面根本就不会维护两份代码,维护的其实就是一份代码,像上述的方案,公司只需要维护专业版就行了,然后根据不同的编译条件,裁剪掉家庭版不需要的功能就可以了。
在编译器预处理之后,这个代码还是C/C++的代码,只不过现在的代码是预处理之后,比较干净的C/C++的代码。然后用这个干净的C/C++的代码,进行编译生产汇编代码。
汇编的gcc 指令如下:
gcc -S text_pzz.c -o text_pzz.s
生成的汇编代码如下:
.file "text_pzz.c"
2 .section .rodata
3 .LC0:
4 .string "not Debug"
5 .LC1:
6 .string "hello Linux:aaa"
7 .text
8 .globl main
9 .type main, @function
10 main:
11 .LFB0:
12 .cfi_startproc
13 pushq %rbp
14 .cfi_def_cfa_offset 16
15 .cfi_offset 6, -16
16 movq %rsp, %rbp
17 .cfi_def_cfa_register 6
18 movl $.LC0, %edi
19 movl $0, %eax
20 call printf
21 movl $.LC1, %edi
22 movl $0, %eax
23 call printf
24 movl $0, %eax
25 popq %rbp
26 .cfi_def_cfa 7, 8
27 ret
28 .cfi_endproc
29 .LFE0:
30 .size main, .-main
31 .ident "GCC: (GNU) 4.8.5 20150623 (Red Hat 4.8.5-44)"
32 .section .note.GNU-stack,"",@progbits
汇编之后,就是汇编操作,把这个汇编文件汇编成计算机能认识的对应的二进制的文件,指令如下:
gcc -c text_pzz.c -o text_pzz.o
生成的文件是二进制的,所以我们用vim文本编译器打开是乱码,我们可以借助 od 这样的工具来查看:

最后通过连接,生成可执行文件或库文件:
gcc text_pzz.o -o text_pzz
其中的 text_pzz.o 是汇编生成的二进制文件gcc/g++ 命令的语法使用
gcc 和 g++ 两个编译器的命令使用和特性都差不多,可以一起理解使用。
一般我们在编译源文件生成可执行文件的时候,推荐使用如下目命令格式:
gcc 源文件名 -o 生成的可执行文件名我们还可以这样来编译出可执行文件:
gcc -o 生成的可执行文件 源文件意思就是,-o 选项后面跟的一定是 对应生成的可执行文件,至于源文件在哪,不在意。
-E:告诉编译器开始进行程序的翻译,将预处理工作做完就停下来,不再往后走;生成 源文件对应的 预处理文件,-E 选项后面一定跟的是 源文件。如下所示例子:
gcc -E 源文件 -o 生成的预处理文件名生成的预处理文件名,虽然后缀可以随意命名,但是我们一般建议命名为 .i 为文件后缀
-S:告诉编译器开始进行程序的翻译,将编译工作做完,就停止工作。
-c:告诉编译器开始进行程序的翻译,将汇编工作做完,就停止工作。
那么最后生成的二进制的文件,还是不能执行的,我们把生产的这个二进制文件称为,可重定位二进制目标文件,简称为目标文件 。在windows下,就是我们见到 的 后缀为 .obj 后缀的文件。这个文件不可以独立执行,需要通过链接之后,才可以执行。

如上所示,这个文件他是没有执行的权限的,就算我们给这个文件加上执行的权限,这个文件也是不能执行的:

执行时候报错:
![]()
所以,最后我们还需要有一个链接的过程,命令如下:
gcc text_pzz.o -o text_pzz
这时候生成的文件才是我们最后的可执行文件:

关于连接:将可重定位二进制文件,和库 进行链接形成可执行文件。
关于上述选项的顺序的记忆,可以按照 esc 这个按键来记忆,他的顺序和 esc 的顺序是一样的,只是除了 c 是小写的,其余两个是大写的。而对应生成文件的下标,就是 .i .s .o ,简写就是 iso 这个顺序,没错和 摄影当中的 感光度(iso) 是一个顺序。
了解链接
我们在调用函数的时候,使用的函数的调用这个一步,而函数主要有三部,声明,定义(实现),调用。
库,给我们提供函数的实现。而所谓的连接就是把库和生成的二进制文件链接。
那么 C的标准库在Linux 当中在如下这个目录当中:
/usr/lib64/libc.so那么我们从中也发现了,这个库的本质就是一个文件,有路径。那么库在不同的环境当中有不同的格式,在 Linux当中的格式一般是 以 .so() 结尾的动态库 , .a() 结尾的静态库。在windows当中有 .dll() 动态库; .lib() 静态库。
而库也是有命名规则的,一般是 如下这种形式的:
libname.so.xxx一般是以 lib 开头的,so是库的类型,xxx可能是版本。name就是这个库的名字。如上述当中的 libc.so C语言标准库,除去 lib前缀, .so 后缀就只有c了。
而一般安装的是动态库,静态库是不会默认安装的。
所以,对于编译性语言,在安装开发包的时候必定是下载安装对应的头文件 + 库文件。
安装了之后,才有了我们最后的链接二进制文件和库文件的操作。
而库文件的实现就是,把实现好的源文件(.c),经过一定的翻译,然后打包。这就使得最后,只用给你提供一个文件即可,不用给你提供太多的源文件。用打包的方式,还可以达到隐藏源文件的目的。
基于以上的实现,我们在调用函数之前,头文件提供函数的声明,库文件提供函数的实现,库的实现就使得,我们不用再重复工作,站在一定的高度来实现我们想要实现的效果。
而链接分为两种,一种是动态链接,一种是静态链接。
动态链接:

如上图所示,就是动态链接的实现,当在源代码当中执行到库当中实现某一块内容的时候,就跳转到库中去执行这个代码块,执行完之后再返回源代码执行处。
那么,如何找到这个动态库的位置,是通过编译器来找到动态库 位置的,他告诉了程序在哪可以找到这个库,然后跳过去执行就可以了。
向上述的库,可以就之后一个,那么不管是哪一个写了什么代码,只要用到了这个库当中的内容,那么在编译的时候,执行到库中实现的内容的时候就会动态链接这个库,这个库是共享的,不是一个人所有的。所以,动态库也被称为共享库。
既然是共享的,每个人都可以用这个动态库,而且使用的时间不同,所以这个动态库是不能缺失的。一旦这个动态库缺失,影响的不是一个程序,很多程序可能都无法正常那个运行。
比如在Linux操作系统当中有很多的命令是用到了 C 的标准库的,如果此时我们把 C的标注库删掉了,那么 Linux 当中的很多命令都用不了。
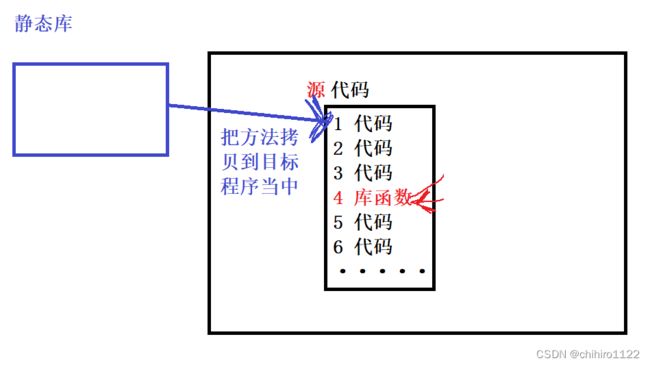
静态链接
编译器将库当中方法拷贝到目标程序当中,我们把这个这样的过程称之为 静态链接,而对应的库就是静态库。
那么,这就意味着,静态链接的程序,将不再依赖于库,即使这个库被销毁了,这个程序依然可以运行。
Linux 当中 链接方式
我们可以使用 ldd 命令 来查看某一个可执行文件的链接的库是什么。

上述的 text_pzz 这个可执行文件就是用 gcc 编译出来的,那么我们发现这个文件的 库是以 .so 结尾的,说明gcc 默认是 动态链接。
其实 在 Linux 当中默认提供的是 动态链接。
我们不能把上述使用的动态库 用 静态链接的方式去链接,因为动态库只能做动态链接,静态库只能做静态链接。
静态链接形式编译
上述我们直接使用 gcc 来进行编译的,所以默认使用的是 动态链接,如果我们想实现静态链接,可以使用 -static 这个选项:
gcc 源代码文件 -o 静态链接生辰的可执行文件 -static
图上图, mytest 是 动态链接生成的可执行文件,而 mytest-static 是 静态链接生成的,我们明显感觉到,静态链接的可执行文件的大小要比动态链接的可执行文件要大上不少。
体积变大也就是静态链接的缺点。
使用 ldd 来查看静态可执行文件的库,提示如下;
![]()
但是,上述的静态链接是需要系统提供静态库的,如果系统当中没有,那么就会报错;

如果现在只有静态库,没有动态库,那么我们直接进行 gcc 是可以编译成功的,因为 Linux 只是默认是动态链接的,如果没有动态链接,那么就看静态链接能不能执行。
而且不一定都是动态链接,或者都是静态链接,因为我们可能需要的库不同,可能这个库的链接方式和其他的有所不同,所以在现实当中,可以是混合的。
但是如果我们加了 -static 这个选项之后,那么就会把所有的库的链接都用静态链接的方式来链接。
我们还可以使用 file 命令来查看这个可执行文件的连接方式:

手动安装C/C++静态库
一般Linux 操作系统可能不会安装 C/C++的静态库,所以我们需要手动安装,下面提供一种 centos7 当中使用 yum 安装的方式:
// 安装C的静态标准库
sudo yum install -y glibc-static
// 安装C++的静态标准库
sudo yum install -y libstdc++-static
动/静态链接的优缺点
动态链接
优点:
因为是共享的,所以可以有效的节约资源(磁盘空间,内存空间,网络空间等)。因为这个可执行文件是要存储的,节省磁盘空间;而当我们运行可执行文件,这个文件是要加载到内存当中的,所以还可以节省内存空间;将来,这个可执行文件可能是要上传到网上供其他人进行下载的,所以也可以节省网络空间;
缺点:
动态库一旦某个库缺失,会导致各个程序无法运行。
静态链接
优点:
不依赖库,程序可以独立运行。
缺点:
体积大,比较消耗资源。
Debug && release
Debug版本的可执行程序可以被追踪调试,因为在Debug版本的可执行程序当中添加了对应的Debug信息。
而 gcc 默认是 生产 release 版本的可执行文件,如果想要生成 Debug 版本的可执行文件就要使用 -g 选项:
gcc text.c -o text_Debug -g
如上图,我们发现Debug版本的可执行文件要比 release版本的要大一点,而多出的这一点就是生成的 Debug 信息。
我们可以借助 readelf -S 这个命令来查看 Debug信息:

我们可以使用 grep 来帮我找到其中的 Debug信息:

可执行程序形成的时候,不是无序的二进制构成的,它是由自己的顺序的。(ELF格式)