分布式软件架构——RESTful服务
RESTful(Representational State Transfer)
RESTful是一种网络应用程序的设计风格和开发方式,基于HTTP,可以使用XML格式定义或JSON格式定义。RESTFUL适用于移动互联网厂商作为业务接口的场景,实现第三方OTT调用移动网络资源的功能,动作类型为新增、变更、删除所调用资源。它是一种主流的远程服务访问风格。
REST和RPC的对比
REST与RPC在思想上存在差异的核心,是抽象的目标不一样,也就是面向资源的编程思想与面向过程的编程思想之间的区别。
二者在概念上的不同,是指REST并不是一种远程服务调用协议,它是就不是一种协议。因为协议都带有一定的规范性和强制性,最起码也该有个规约文档,比如JSON-RPC,它哪怕再简单,也要有个《JSON-RPC Specification》(JSON-RPC 2.0 Specification
)来规定协议的格式细节、异常、响应码等信息。但是REST并没有定义这些内容,虽然它有一些指导原则,但实际上并不受任何强制的约束。
REST
REST 概念的提出来自于罗伊・菲尔丁(Roy Fielding)在 2000 年发表的博士论文: 《Architectural Styles and the Design of Network-based Software Architectures》 。中文版参见 架构风格与网络的软件架构设计
罗伊・菲尔丁(Roy Fielding)是一名很优秀的软件工程师,他的主要头衔如下:
1)Apache 服务器的核心开发者,后来成为了著名的 Apache 软件基金会的联合创始人
2)HTTP 1.0 协议(1996 年发布)的专家组成员
3)HTTP 1.1 协议(1999 年发布)的负责人
4)指导设计 HTTP 1.1 协议的理论和思想,最初是以备忘录的形式,在专家组成员之间交流,这个备忘录其实就是 REST 的雏形。
什么叫『表征状态转移』?即什么是REST(Representational State Transfer)。
超文本(Hypertext)
先去理解什么是 HTTP,再配合一些实际例子来进行类比,你就会发现 “REST” 实际上是 “HTT”(Hyper Text Transfer,超文本传输)的进一步抽象,它们就像是接口与实现类之间的关系。HTTP 中使用的 “超文本” 一词,是美国社会学家泰德・H・尼尔森(Theodor Holm Nelson)在 1967 年于《Brief Words on the Hypertext》一文里提出的,
Nelson在 1992 年修正后的定义:
By now the word “hypertext” has become generally accepted for branching and responding text,
but the corresponding word “hypermedia”, meaning complexes of
branching and responding graphics, movies and sound – as well as text – is much less used.
Instead they use the strange term “interactive multimedia”:
this is four syllables longer, and does not express the idea of extending hypertext.
—— Theodor Holm Nelson Literary Machines, 1992
“超文本(或超媒体)” 指的是一种 “能够对操作进行判断和响应的文本(或声音、图像等)”
资源(Resource)
内容本身(可以将其视作是某种信息、数据),我们称之为 “资源”
表征(Representation)
“表征” 这个概念是指信息与用户交互时的表示形式:
如: 同一资源:
- 服务端向浏览器返回的 HTML 格式的数据
- 服务端向浏览器返回的 PDF 格式的数据
- 服务端向浏览器返回的 Markdown 格式的数据
- 服务端向浏览器返回的 RSS 格式的数据
- … …
上面就是同一资源的多种表征
状态(State)
在特定语境中才能产生的上下文信息就被称为 “状态”,如:
读完了这篇文章,想再接着看下一篇文章的内容时,你向服务器发出请求 “给我下一篇文章”。
但是 “下一篇” 是个相对概念,必须依赖 “当前你正在阅读的文章是哪一篇”,这样服务器才能正确回应
有状态(Stateful)还是无状态(Stateless),都是只相对于服务端来说的:
- 服务器记住用户的状态,这是有状态
- 客户端来记住状态,在请求的时候明确告诉服务器,这是无状态
转移(Transfer)
服务器通过某种方式,把 “用户当前阅读的文章” 转变成 “下一篇文章”,这就被称为 “表征状态转移”
- 统一接口(Uniform Interface):
“统一接口”,包括:GET、HEAD、POST、PUT、DELETE、TRACE、OPTIONS 七种基本操作
任何一个支持 HTTP 协议的服务器都会遵守这套规定,对特定的 URI 采取这些操作,服务器就会触发相应的表征状态转移。
- 超文本驱动(Hypertext Driven):
浏览器作为通用的客户端,任何网站的导航(状态转移)行为都不可能是预置于浏览器代码之中,
而是由服务器发出的请求响应信息(超文本)来驱动的。
这点与其他带有客户端的软件有十分本质的区别,
在那些软件中,业务逻辑往往是预置于程序代码之中的,
有专门的页面控制器(无论在服务端还是在客户端中)来驱动页面的状态转移。
- 自描述消息(Self-Descriptive Messages):
一种被广泛采用的自描述方法,是在名为 “Content-Type” 的 HTTP Header 中标识出互联网媒体类型(MIME type)
比如 “Content-Type : application/json; charset=utf-8”
互联网媒体类型(MIME type):
https://zh.wikipedia.org/wiki/%E4%BA%92%E8%81%94%E7%BD%91%E5%AA%92%E4%BD%93%E7%B1%BB%E5%9E%
RESTful风格的系统特征
Fielding认为,一套理想的、完全满足REST的系统应满足以下六个特征:
- 服务端与客户端分离(Client-Server)
- 无状态(Stateless)
- 可缓存(Cacheability)
- 分层系统(Layered System)
- 统一接口(Uniform Interface)
- 按需代码(Code-On-Demand)
REST与RPC在思想上的差异是,REST的基本细想是面向资源来抽象问题,它与此前流行的面向过程的编程思想,在抽象主体上有本质的区别。
RPC是将本地的方法调用思路迁移到远程方法调用上,开发者是围绕着“远程方法”去设计两个系统间的交互的,比如CORBA、RMI、DCOM等等。这样做的坏处,不仅是“如何在异构系统间表示一个方法”,“如何获得接口能够提供的方法清单”,都成了需要专门协议去解决的问题(RPC的三大基本问题之一),更在于服务的每个方法都是不同的,服务使用者必须逐个学习才能正确地使用它们。Google在 《Goole API Design Guide》 中曾经写下这样一段话:
Traditionally, people design RPC APIs in terms of API interfaces and methods, such as CORBA and Windows COM. As time goes by, more and more interfaces and methods are introduced. The end result can be an overwhelming number of interfaces and methods, each of them different from the others. Developers have to learn each one carefully in order to use it correctly, which can be both time consuming and error prone.
以前,人们面向方法去设计 RPC API,譬如 CORBA 和 DCOM,随着时间推移,接口与方法越来越多却又各不相同,开发人员必须了解每一个方法才能正确使用它们,这样既耗时又容易出错。
—— Google API Design Guide, 2017
REST 提出以资源为主体进行服务设计的风格,就为它带来了不少好处。
- 降低了服务接口的学习成本
统一接口(Uniform Interface)是 REST 的重要标志,将对资源的标准操作都映射到了标准的 HTTP 方法上去,这些方法对于每个资源的用法都是一致的,语义都是类似的,不需要刻意去学习,更不需要有什么 Interface Description Language 之类的协议存在。 - 资源天然具有集合与层次结构
以方法为中心抽象的接口,由于方法是动词,逻辑上决定了每个接口都是互相独立的;但以资源为中心抽象的接口,由于资源是名词,天然就可以产生集合与层次结构。举个具体例子,你想像一个商城用户中心的接口设计:用户资源会拥有多个不同的下级的资源,譬如若干条短消息资源、一份用户资料资源、一部购物车资源,购物车中又会有自己的下级资源,譬如多本书籍资源。很容易在程序接口中构造出这些资源的集合关系与层次关系,而且是符合人们长期在单机或网络环境中管理数据的直觉的。相信你不需要专门阅读接口说明书,也能轻易推断出获取用户icyfenix的购物车中的第2本书的 REST 接口应该表示为:
GET /users/icyfenix/cart/2
- REST绑定于HTTP协议
面向资源编程不是必须构筑在 HTTP 之上,但 REST 是,这是缺点,也是优点。因为 HTTP 本来就是面向资源而设计的网络协议,纯粹只用 HTTP(而不是 SOAP over HTTP 那样在再构筑协议)带来的好处是 RPC 中的 Wire Protocol 问题就无需再多考虑了,REST 将复用 HTTP 协议中已经定义的概念和相关基础支持来解决问题。HTTP 协议已经有效运作了三十年,其相关的技术基础设施已是千锤百炼,无比成熟。而坏处自然是,当你想去考虑那些 HTTP 不提供的特性时,便会彻底地束手无策。
Richardson成熟度
《RESTful Web APIs》和《RESTful Web Services》的作者 Leonard Richardson 曾提出过一个衡量“服务有多么 REST”的 Richardson 成熟度模型(Richardson Maturity Model),便于那些原本不使用 REST 的系统,能够逐步地导入 REST。Richardson 将服务接口“REST 的程度”从低到高,分为 0 至 3 级:
- 0.The Swamp of Plain Old XML:完全不 REST。另外,关于 Plain Old XML 这说法,SOAP 表示感觉有被冒犯到。
- 1.Resources:开始引入资源的概念。
- 2.HTTP Verbs:引入统一接口,映射到 HTTP 协议的方法上。
- 3.Hypermedia Controls:超媒体控制在本文里面的说法是“超文本驱动”,在 Fielding 论文里的说法是“Hypertext As The Engine Of Application State,HATEOAS”,其实都是指同一件事情。
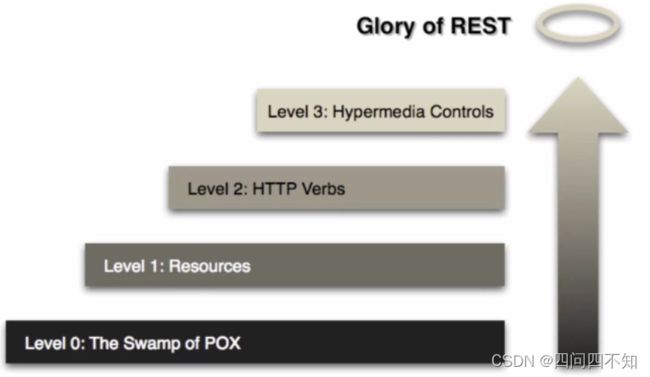
通过马丁 福勒(Martin Fowler)撰写的关于 RMM 成熟度模型的文章中的实际例子(原文是 XML 写的,这里简化为 JSON 表示),来具体展示一下四种不同程度的 REST 反应到实际接口中会是怎样的。假设你是一名软件工程师,接到需求(原文中的需求复杂一些,这里简化了)的 UserStory 描述是这样的——开发一个医生预约系统(病人通过系统,可以得知指定日期内指定的医生是否具有空闲时间,以便预约就诊)。
第 0 级成熟度:The Swamp of Plain Old XML
医院开放了一个/appointmentService的 Web API,传入日期、医生姓名作为参数,可以得到该时间段该名医生的空闲时间,该 API 的一次 HTTP 调用如下所示:
POST /appointmentService?action=query HTTP/1.1
{
"date": "2020-03-04",
"doctor": "mjones"
}
服务器回传结果:
HTTP/1.1 200 OK
[
{
"start": "14:00",
"end": "14:50",
"doctor": "mjones"
},
{
"start": "16:00",
"end": "16:50",
"doctor": "mjones"
}
]
得到了医生空闲的结果后,我觉得 14:00 的时间比较合适,于是进行预约确认,并提交了我的基本信息:
POST /appointmentService?action=confirm HTTP/1.1
{
"appointment": {
"date": "2020-03-04",
"start": "14:00",
"doctor": "mjones"
},
"patient": {
"name": "icyfenix",
"age": 30
}
}
如果预约成功,那我能够收到一个预约成功的响应:
HTTP/1.1 200 OK
{
"code": 0,
"message": "Successful confirmation of appointment"
}
如果发生了问题,譬如有人在我前面抢先预约了,那么我会在响应中收到某种错误信息:
HTTP/1.1 200 OK
{
"code": 1,
"message": "doctor not available"
}
到此,整个预约服务宣告完成,直接明了,我们采用的是非常直观的基于 RPC 风格的服务设计,看似很容易就解决了所有问题,但真的是如此么?
第 1 级成熟度:Resources
第 0 级是 RPC 的风格,如果需求永远不会变化,也不会增加,那它完全可以良好地工作下去。但是,如果你不想为预约医生之外的其他操作、为获取空闲时间之外的其他信息去编写额外的方法,或者改动现有方法的接口,那还是应该考虑一下如何使用 REST 来抽象资源。
通往 REST 的第一步是引入资源的概念,在 API 中基本的体现是围绕着资源而不是过程来设计服务,说的直白一点,可以理解为服务的 Endpoint 应该是一个名词而不是动词。此外,每次请求中都应包含资源的 ID,所有操作均通过资源 ID 来进行,譬如,获取医生指定时间的空闲档期:
POST /doctors/mjones HTTP/1.1
{
"date": "2020-03-04"
}
然后服务器传回一组包含了 ID 信息的档期清单,注意,ID 是资源的唯一编号,有 ID 即代表“医生的档期”被视为一种资源:
HTTP/1.1 200 OK
[
{
"id": 1234,
"start": "14:00",
"end": "14:50",
"doctor": "mjones"
},
{
"id": 5678,
"start": "16:00",
"end": "16:50",
"doctor": "mjones"
}
]
我还是觉得 14:00 的时间比较合适,于是又进行预约确认,并提交了我的基本信息:
POST /schedules/1234 HTTP/1.1
{
"name": "icyfenix",
"age": 30,
"reservation": 1234
}
后面预约成功或者失败的响应消息在这个级别里面与之前一致,就不重复了。比起第 0 级,第 1 级的特征是引入了资源,通过资源 ID 作为主要线索与服务交互,但第 1 级至少还有三个问题并没有解决:一是只处理了查询和预约,如果我临时想换个时间,要调整预约,或者我的病忽然好了,想删除预约,这都需要提供新的服务接口。二是处理结果响应时,只能靠着结果中的code、message这些字段做分支判断,每一套服务都要设计可能发生错误的 code,这很难考虑全面,而且也不利于对某些通用的错误做统一处理;三是并没有考虑认证授权等安全方面的内容,譬如要求只有登陆用户才允许查询医生档期时间,某些医生可能只对 VIP 开放,需要特定级别的病人才能预约,等等。
第 2 级成熟度:HTTP Verbs
第 1 级遗留三个问题都可以靠引入统一接口来解决。HTTP 协议的七个标准方法是经过精心设计的,只要架构师的抽象能力够用,它们几乎能涵盖资源可能遇到的所有操作场景。REST 的做法是把不同业务需求抽象为对资源的增加、修改、删除等操作来解决第一个问题;使用 HTTP 协议的 Status Code,可以涵盖大多数资源操作可能出现的异常,而且 Status Code 可以自定义扩展,以此解决第二个问题;依靠 HTTP Header 中携带的额外认证、授权信息来解决第三个问题,这个在实战中并没有体现,请参考安全架构中的“凭证”相关内容。
按这个思路,获取医生档期,应采用具有查询语义的 GET 操作进行:
GET /doctors/mjones/schedule?date=2020-03-04&status=open HTTP/1.1
然后服务器会传回一个包含了所需信息的回应:
HTTP/1.1 200 OK
[
{
"id": 1234,
"start": "14:00",
"end": "14:50",
"doctor": "mjones"
},
{
"id": 5678,
"start": "16:00",
"end": "16:50",
"doctor": "mjones"
}
]
我仍然觉得 14:00 的时间比较合适,于是又进行预约确认,并提交了我的基本信息,用以创建预约,这是符合 POST 的语义的:
POST /schedules/1234 HTTP/1.1
{
"name": "icyfenix",
"age": 30,
"reservation": 1234
}
如果预约成功,那我能够收到一个预约成功的响应:
HTTP/1.1 201 Created
Successful confirmation of appointment
如果发生了问题,譬如有人在我前面抢先预约了,那么我会在响应中收到某种错误信息:
HTTP/1.1 409 Conflict
doctor not available
第 3 级成熟度:Hypermedia Controls
第 2 级是目前绝大多数系统所到达的 REST 级别,但仍不是完美的,至少还存在一个问题:你是如何知道预约 mjones 医生的档期是需要访问/schedules/1234这个服务 Endpoint 的?也许你甚至第一时间无法理解为何我会有这样的疑问,这当然是程序代码写的呀!但 REST 并不认同这种已烙在程序员脑海中许久的想法。RMM 中的 Hypermedia Controls、Fielding 论文中的 HATEOAS 和现在提的比较多的“超文本驱动”,所希望的是除了第一个请求是有你在浏览器地址栏输入所驱动之外,其他的请求都应该能够自己描述清楚后续可能发生的状态转移,由超文本自身来驱动。所以,当你输入了查询的指令之后:
GET /doctors/mjones/schedule?date=2020-03-04&status=open HTTP/1.1
服务器传回的响应信息应该包括诸如如何预约档期、如何了解医生信息等可能的后续操作:
HTTP/1.1 200 OK
{
"schedules": [
{
"id": 1234,
"start": "14:00",
"end": "14:50",
"doctor": "mjones",
"links": [
{
"rel": "comfirm schedule",
"href": "/schedules/1234"
}
]
},
{
"id": 5678,
"start": "16:00",
"end": "16:50",
"doctor": "mjones",
"links": [
{
"rel": "comfirm schedule",
"href": "/schedules/5678"
}
]
}
],
"links": [
{
"rel": "doctor info",
"href": "/doctors/mjones/info"
}
]
}
如果做到了第 3 级 REST,那服务端的 API 和客户端也是完全解耦的,你要调整服务数量,或者同一个服务做 API 升级将会变得非常简单。
不足与争议
面向资源的编程思想只适合做 CRUD,面向过程、面向对象编程才能处理真正复杂的业务逻辑
这是遇到最多的一个问题。HTTP 的四个最基础的命令 POST、GET、PUT 和 DELETE 很容易让人直接联想到 CRUD 操作,以至于在脑海中自然产生了直接的对应。REST 所能涵盖的范围当然远不止于此,不过要说 POST、GET、PUT 和 DELETE 对应于 CRUD 其实也没什么不对,只是这个 CRUD 必须泛化去理解,它们涵盖了信息在客户端与服务端之间如何流动的几种主要方式,所有基于网络的操作逻辑,都可以对应到信息在服务端与客户端之间如何流动来理解,有的场景里比较直观,而另一些场景中可能比较抽象。
针对那些比较抽象的场景,如果真不好把 HTTP 方法映射为资源的所需操作,REST 也并非刻板的教条,用户是可以使用自定义方法的,按 Google 推荐的 REST API 风格,自定义方法应该放在资源路径末尾,嵌入冒号加自定义动词的后缀。譬如,我可以把删除操作映射到标准 DELETE 方法上,如果此外还要提供一个恢复删除的 API,那它可能会被设计为:
POST /user/user_id/cart/book_id:undelete
如果你不想使用自定义方法,那就设计一个回收站的资源,在那里保留着还能被恢复的商品,将恢复删除视为对该资源某个状态值的修改,映射到 PUT 或者 PATCH 方法上,这也是一种完全可行的设计。
面向资源的编程思想与另外两种主流编程思想只是抽象问题时所处的立场不同,只有选择问题,没有高下之分:
- 面向过程编程时,为什么要以算法和处理过程为中心,输入数据,输出结果?当然是为了符合计算机世界中主流的交互方式。
- 面向对象编程时,为什么要将数据和行为统一起来、封装成对象?当然是为了符合现实世界的主流的交互方式。
- 面向资源编程时,为什么要将数据(资源)作为抽象的主体,把行为看作是统一的接口?当然是为了符合网络世界的主流的交互方式。
REST 与 HTTP 完全绑定,不适合应用于要求高性能传输的场景中
笔者个人很大程度上赞同此观点,但并不认为这是 REST 的缺陷,锤子不能当扳手用并不是锤子的质量有问题。面向资源编程与协议无关,但是 REST(特指 Fielding 论文中所定义的 REST,而不是泛指面向资源的思想)的确依赖着 HTTP 协议的标准方法、状态码、协议头等各个方面。HTTP 并不是传输层协议,它是应用层协议,如果仅将 HTTP 当作传输是不恰当的(SOAP:再次感觉有被冒犯到)。对于需要直接控制传输,如二进制细节、编码形式、报文格式、连接方式等细节的场景中,REST 确实不合适,这些场景往往存在于服务集群的内部节点之间,这也是之前曾提及的,REST 和 RPC 尽管应用场景的确有所重合,但重合的范围有多大就是见仁见智的事情。
REST 不利于事务支持
这个问题首先要看你怎么看待“事务(Transaction)”这个概念。如果“事务”指的是数据库那种的狭义的刚性 ACID 事务,那除非完全不持有状态,否则分布式系统本身与此就是有矛盾的(CAP 不可兼得),这是分布式的问题而不是 REST 的问题。如果“事务”是指通过服务协议或架构,在分布式服务中,获得对多个数据同时提交的统一协调能力(2PC/3PC),譬如WS-AtomicTransaction、WS-Coordination这样的功能性协议,这 REST 确实不支持,假如你已经理解了这样做的代价,仍决定要这样做的话,Web Service 是比较好的选择。如果“事务”只是指希望保障数据的最终一致性,说明你已经放弃刚性事务了,这才是分布式系统中的正常交互方式,使用 REST 肯定不会有什么阻碍,谈不上“不利于”。当然,对此 REST 也并没有什么帮助,这完全取决于你系统的事务设计,我们会在事务处理中再详细讨论。
REST 没有传输可靠性支持
是的,并没有。在 HTTP 中你发送出去一个请求,通常会收到一个与之相对的响应,譬如 HTTP/1.1 200 OK 或者 HTTP/1.1 404 Not Found 诸如此类的。但如果你没有收到任何响应,那就无法确定消息到底是没有发送出去,抑或是没有从服务端返回回来,这其中的关键差别是服务端到底是否被触发了某些处理?应对传输可靠性最简单粗暴的做法是把消息再重发一遍。这种简单处理能够成立的前提是服务应具有幂等性(Idempotency),即服务被重复执行多次的效果与执行一次是相等的。HTTP 协议要求 GET、PUT 和 DELETE 应具有幂等性,我们把 REST 服务映射到这些方法时,也应当保证幂等性。对于 POST 方法,曾经有过一些专门的提案(如POE,POST Once Exactly),但并未得到 IETF 的通过。对于 POST 的重复提交,浏览器会出现相应警告,如 Chrome 中“确认重新提交表单”的提示,对于服务端,就应该做预校验,如果发现可能重复,返回 HTTP/1.1 425 Too Early。另,Web Service 中有WS-ReliableMessaging功能协议用于支持消息可靠投递。类似的,由于 REST 没有采用额外的 Wire Protocol,所以除了事务、可靠传输这些功能以外,一定还可以在 WS-*协议中找到很多 REST 不支持的特性。
REST 缺乏对资源进行“部分”和“批量”的处理能力
这个观点笔者是认同的,这很可能是未来面向资源的思想和 API 设计风格的发展方向。REST 开创了面向资源的服务风格,却肯定仍并不完美。以 HTTP 协议为基础给 REST 带来了极大的便捷(不需要额外协议,不需要重复解决一堆基础网络问题,等等),但也是 HTTP 本身成了束缚 REST 的无形牢笼。这里仍通过具体例子来解释 REST 这方面的局限性:譬如你仅仅想获得某个用户的姓名,RPC 风格中可以设计一个“getUsernameById”的服务,返回一个字符串,尽管这种服务的通用性实在称不上“设计”二字,但确实可以工作;而 REST 风格中你将向服务端请求整个用户对象,然后丢弃掉返回的结果中该用户除用户名外的其他属性,这便是一种“过度获取”(Overfetching)。REST 的应对手段是通过位于中间节点或客户端的缓存来缓解这种问题,但此缺陷的本质是由于 HTTP 协议完全没有对请求资源的结构化描述能力(但有非结构化的部分内容获取能力,即今天多用于断点续传的Range Header),所以返回资源的哪些内容、以什么数据类型返回等等,都不可能得到协议层面的支持,要做你就只能自己在 GET 方法的 Endpoint 上设计各种参数来实现。而另外一方面,与此相对的缺陷是对资源的批量操作的支持,有时候我们不得不为此而专门设计一些抽象的资源才能应对。譬如你准备把某个用户的名字增加一个“VIP”前缀,提交一个 PUT 请求修改这个用户的名称即可,而你要给 1000 个用户加 VIP 时,如果真的去调用 1000 次 PUT,浏览器会回应你 HTTP/1.1 429 Too Many Requests,老板则会揍你一顿。此时,你就不得不先创建一个(如名为“VIP-Modify-Task”)任务资源,把 1000 个用户的 ID 交给这个任务,最后驱动任务进入执行状态。又譬如你去网店买东西,下单、冻结库存、支付、加积分、扣减库存这一系列步骤会涉及到多个资源的变化,你可能面临不得不创建一种“事务”的抽象资源,或者用某种具体的资源(譬如“结算单”)贯穿这个过程的始终,每次操作其他资源时都带着事务或者结算单的 ID。HTTP 协议由于本身的无状态性,会相对不适应(并非不能够)处理这类业务场景。
目前,一种理论上较优秀的可以解决以上这几类问题的方案是GraphQL,这是由 Facebook 提出并开源的一种面向资源 API 的数据查询语言,如同 SQL 一样,挂了个“查询语言”的名字,但其实 CRUD 都有涉猎。比起依赖 HTTP 无协议的 REST,GraphQL 可以说是另一种“有协议”的、更彻底地面向资源的服务方式。然而凡事都有两面,离开了 HTTP,它又面临着几乎所有 RPC 框架所遇到的那个如何推广交互接口的问题。
参考链接
1、REST概念