多业务聚合查询设计思路与实践
文章目录
-
- @[toc]
- 1.需求
- 2.方案
-
- 2.1 方案架构图
- 2.2 选用flink-cdc的原因
- 3.实践
-
- 3.1 环境准备
- 3.3 es集群搭建
- 3.4 flink1.14.0环境搭建
- 3.5 准备sql和jar包
-
- 3.5.1[创建mysql的flink用户并授权](https://ververica.github.io/flink-cdc-connectors/master/content/connectors/mysql-cdc.html)
- 3.5.2 准备sql
- 3.5.3准备jar包
- 3.5.4 mysql数据库中需要准备products、orders两张表
- 3.5.5 执行sql同步数据
- 4.总结
文章目录
-
- @[toc]
- 1.需求
- 2.方案
-
- 2.1 方案架构图
- 2.2 选用flink-cdc的原因
- 3.实践
-
- 3.1 环境准备
- 3.3 es集群搭建
- 3.4 flink1.14.0环境搭建
- 3.5 准备sql和jar包
-
- 3.5.1[创建mysql的flink用户并授权](https://ververica.github.io/flink-cdc-connectors/master/content/connectors/mysql-cdc.html)
- 3.5.2 准备sql
- 3.5.3准备jar包
- 3.5.4 mysql数据库中需要准备products、orders两张表
- 3.5.5 执行sql同步数据
- 4.总结
1.需求
最近接到一个需求,需要给客服部做一个把多个业务系统的的数据聚合到es里面做统一的搜索,一期需要把各个业务侧的订单数据同步到es中做聚合搜索,这个需求如果用传统的思维会在各个业务侧写一个xxl-job的定时任务,然后向es的各个业务索引中全量、增量的同步数据,这种传统的方案来说,不断需要各个业务侧写大量的业务代码,并且数据的时效性不高,做不到业务测试的业务侧的订单表的数据修改后,es的业务索引中的数据能立马也同步成最新的数据,如果有数据思维的话,这种需求能不写业务代码搞定就不要写业务代码,但是在传统的开发中采用的传统思维就会去写大量的业务代码,各个业务侧一套代码,由于各个业务侧的开发的水平参差不齐,维护成本高,代码质量层次不齐,时效性不高,还容易写出一些奇奇怪怪的坑,所以该设计一个什么样的方案呢?
2.方案
方案灵感来源于如下两篇文章:
基于 Flink CDC 构建 MySQL 和 Postgres 的 Streaming ETL
基于 Flink CDC 实现海量数据的实时同步和转换
2.1 方案架构图
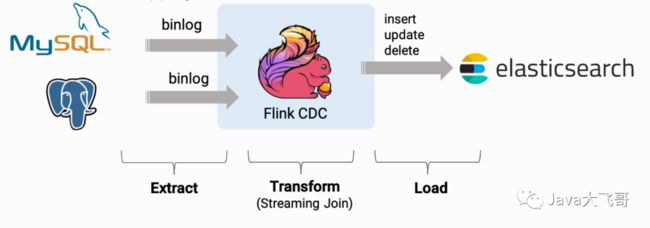
该方案使用flink-cdc对mysql的log-bin做监听做全量、增量和实时的数据同步,那来看下常见的cdc的方案的对比:
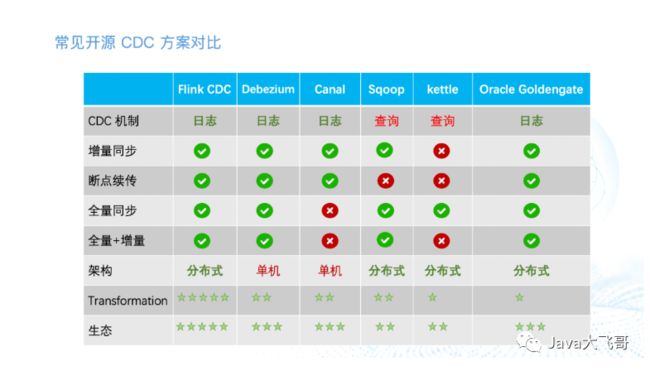
2.2 选用flink-cdc的原因
1)架构是分布式的,避免了单点故障,提升了计算数据处理的效率。
2)支持全量、增量和实时的数据同步,避免了业务侧写各种各样的同步数据的业务代码。
3)生态丰富、易用、功能强大,社区活跃。
4)数据采集、计算、统计、打宽、转换等强大的功能,可以使用编程式的方式跑jar任务,也可以使用flink-sql强大的sql功能做数据提取统计分析这种实时的事情,同时可以和大数据生态结合使用,也可以单独使用解决业务开发的痛点问题。
5)flink-cdc2.x版本以上做了重大的更新,支持无锁化(不像1.x是有锁的,一个不小心就会锁数据库的表)、并发性能更高,所以2.x以上的版本就不用担心这个锁表的问题了。
3.实践
3.1 环境准备
首先需要准备一个mysql的数据库,flink集群或者是单机和一个es集群或者es单机,本文都是采用Docker-Desktop来搭建的。
版本如下:
mysql5.7.16
es7.14.0
flink1.14.0
3.2 开启mysql的log-bin
Mysql5.7.x镜像开启log-bin失效及解决
3.3 es集群搭建
Docker部署ES集群、kibana、RabbitMq和chrome安装elasticsearch-head插件
3.4 flink1.14.0环境搭建
flink1.14.0官网
flink-playgrounds1.14.0官方git
本文使用flink1.14.0搭建的环境,所以你也可以使用官方最新的稳定版本,可以使用flink1.17.0,flink的每个版本的差异还是有点大的,每个版本的写法都会有点不太一样,这个还有的注意下的。
使用官方提供的docker-compose的部署文件做了修改:

部署文件docker-compose.yaml:
version: "2.1"
services:
jobmanager:
image: apache/flink:1.14.4-scala_2.12-java8
command: "jobmanager.sh start-foreground"
ports:
- 8081:8081
volumes:
- ./conf:/opt/flink/conf
- /tmp/flink-checkpoints-directory:/tmp/flink-checkpoints-directory
- /tmp/flink-savepoints-directory:/tmp/flink-savepoints-directory
environment:
- JOB_MANAGER_RPC_ADDRESS=jobmanager
taskmanager:
image: apache/flink:1.14.4-scala_2.12-java8
depends_on:
- jobmanager
command: "taskmanager.sh start-foreground"
volumes:
- ./conf:/opt/flink/conf
- /tmp/flink-checkpoints-directory:/tmp/flink-checkpoints-directory
- /tmp/flink-savepoints-directory:/tmp/flink-savepoints-directory
environment:
- JOB_MANAGER_RPC_ADDRESS=jobmanager
这里只部署了jobmanager、taskmanager没有要zookeeper和kafka
修改配置文件:
flink-conf.yaml
在该配置文件中加入如下配置:
classloader.resolve-order: parent-first
如果不加这个配置会到导致在flink的节点上执行sql-client.sh的窗口执行sql任务的时候会报错:

这里也是一个大坑,这里也是请教的大佬才搞定的。
部署命令:
git clone https://github.com/apache/flink-playgrounds.git
cd flink-playgrounds/operations-playground
docker-compose builddocker-compose up -d
# 强制全部重新创建会重新拉取镜像会很慢
docker-compose up --force-recreate -d
# 指定docker-compose文件后重新部署,只会重新部署新增的容器,不会全部删除后创建
docker-compose -f docker-compose.yaml up -d
3.5 准备sql和jar包
3.5.1创建mysql的flink用户并授权
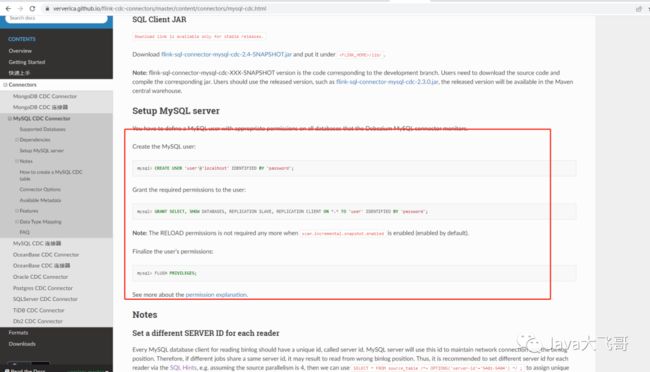
3.5.2 准备sql
cdc任务的sql:
Flink SQL> SET execution.checkpointing.interval = 3s; # 首先,开启 checkpoint,每隔3秒做一次 checkpoint,在执行如下sql前先执行该sql,设置保存点,每3s执行一次同步
-- Flink SQL
Flink SQL> CREATE TABLE products (
id INT,
name STRING,
description STRING,
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'connector' = 'mysql-cdc',
'hostname' = 'xxxx',
'port' = '3306',
'username' = 'flink',
'password' = '123456',
'database-name' = 'mydb',
'table-name' = 'products'
);
Flink SQL> CREATE TABLE orders (
order_id INT,
order_date TIMESTAMP(0),
customer_name STRING,
price DECIMAL(10, 5),
product_id INT,
order_status BOOLEAN,
PRIMARY KEY (order_id) NOT ENFORCED
) WITH (
'connector' = 'mysql-cdc',
'hostname' = 'ip',
'port' = '3306',
'username' = 'flink',
'password' = '123456',
'database-name' = 'mydb',
'table-name' = 'orders'
);
# 最后,创建 enriched_orders 表, 用来将关联后的订单数据写入 Elasticsearch 中
-- Flink SQL
Flink SQL> CREATE TABLE enriched_orders (
order_id INT,
order_date TIMESTAMP(0),
customer_name STRING,
price DECIMAL(10, 5),
product_id INT,
order_status BOOLEAN,
product_name STRING,
product_description STRING,
PRIMARY KEY (order_id) NOT ENFORCED
) WITH (
'connector' = 'elasticsearch-7',
'hosts' = 'http://ip:port',
'index' = 'enriched_orders'
);
#关联订单数据并且将其写入 Elasticsearch 中使用 Flink SQL 将订单表 order 与 商品表 products,物流信息表 shipments 关联,并将关联后的订单信息写入 Elasticsearch 中
-- Flink SQL
Flink SQL> INSERT INTO enriched_orders
SELECT o.*, p.name, p.description
FROM orders AS o
LEFT JOIN products AS p ON o.product_id = p.id;
jdbc任务sql:
# JDBC跑批
-- Flink SQL
Flink SQL> SET execution.checkpointing.interval = 3s; # 首先,开启 checkpoint,每隔3秒做一次 checkpoint
-- Flink SQL
Flink SQL> CREATE TABLE products (
id INT,
name STRING,
description STRING,
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://ip:3306/mydb',
'table-name' = 'products',
'username' = 'flink',
'password' = '123456'
);
Flink SQL> CREATE TABLE orders (
order_id INT,
order_date TIMESTAMP(0),
customer_name STRING,
price DECIMAL(10, 5),
product_id INT,
order_status BOOLEAN,
PRIMARY KEY (order_id) NOT ENFORCED
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://ip:3306/mydb',
'table-name' = 'orders',
'username' = 'flink',
'password' = '123456'
);
-- Flink SQL
Flink SQL> CREATE TABLE enriched_orders (
order_id INT,
order_date TIMESTAMP(0),
customer_name STRING,
price DECIMAL(10, 5),
product_id INT,
order_status BOOLEAN,
product_name STRING,
product_description STRING,
PRIMARY KEY (order_id) NOT ENFORCED
) WITH (
'connector' = 'elasticsearch-7',
'hosts' = 'http://ip:port',
'index' = 'enriched_orders'
);
# 关联订单数据并且将其写入 Elasticsearch 中使用 Flink SQL 将订单表 order 与 商品表 products,物流信息表 shipments 关联,并将关联后的订单信息写入 Elasticsearch 中
-- Flink SQL
Flink SQL> INSERT INTO enriched_orders
SELECT o.*, p.name, p.description
FROM orders AS o
LEFT JOIN products AS p ON o.product_id = p.id;
这里需要注意的是jdbc的sql任务和cdc-sql的任务最大的区别是:jdbc的sql任务执行一次就完结掉了,而cdc-sql的任务是一直在running,之前由于这里搞成jdbc的sql的方式了,然后去修改数据里面的数据,新增、修改和删除发现不会增量和实时同步,只会全量同步,最后是请教了一个大佬才茅塞顿开的,然后换成了cdc的方式就可以了。
3.5.3准备jar包
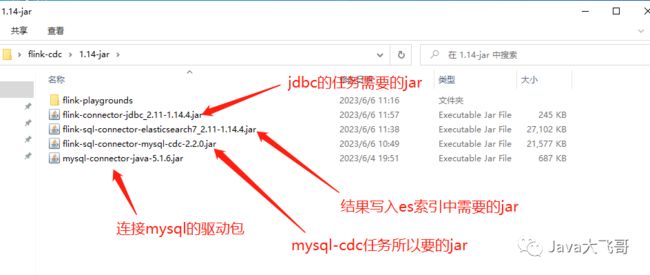
jar包需要拷贝的执行的节点上的如下目录里面:

上传jar包然后重启集群的容器。
3.5.4 mysql数据库中需要准备products、orders两张表
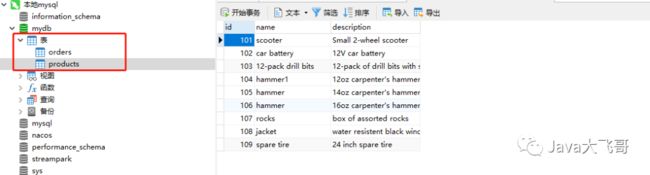
sql如下:
-- MySQL
CREATE DATABASE mydb;
USE mydb;
CREATE TABLE products (
id INTEGER NOT NULL AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(255) NOT NULL,
description VARCHAR(512)
);
ALTER TABLE products AUTO_INCREMENT = 101;
INSERT INTO products
VALUES (default,"scooter","Small 2-wheel scooter"),
(default,"car battery","12V car battery"),
(default,"12-pack drill bits","12-pack of drill bits with sizes ranging from #40 to #3"),
(default,"hammer","12oz carpenter's hammer"),
(default,"hammer","14oz carpenter's hammer"),
(default,"hammer","16oz carpenter's hammer"),
(default,"rocks","box of assorted rocks"),
(default,"jacket","water resistent black wind breaker"),
(default,"spare tire","24 inch spare tire");
CREATE TABLE orders (
order_id INTEGER NOT NULL AUTO_INCREMENT PRIMARY KEY,
order_date DATETIME NOT NULL,
customer_name VARCHAR(255) NOT NULL,
price DECIMAL(10, 5) NOT NULL,
product_id INTEGER NOT NULL,
order_status BOOLEAN NOT NULL -- Whether order has been placed
) AUTO_INCREMENT = 10001;
INSERT INTO orders
VALUES (default, '2020-07-30 10:08:22', 'Jark', 50.50, 102, false),
(default, '2020-07-30 10:11:09', 'Sally', 15.00, 105, false),
(default, '2020-07-30 12:00:30', 'Edward', 25.25, 106, false);
3.5.5 执行sql同步数据

进入到/opt/flink/bin路径下,执行如下命令进入sql管理后台:
./sql-client.sh

然后在这个界面顺序执行上面准备的cdc任务的sql,首先执行:
Flink SQL> SET execution.checkpointing.interval = 3s;
开启checkpoint,然后在去顺序执行建表sql和关联insert的sql将数据同步到es的索引中,
mysql-cdc的insert的任务一直在执行中的:

es中同步的数据如下:

在mysql的mydb的数据中执行新增、修改和删除的操作,数据都可以实时更新到es的索引中。
4.总结
到此实践分享已经完成,生产的话在设计下高可用啥的,设计下各个业务的数据模型,然后就可以用flink-cdc把各个业务的mysql数据库表中的数据全量、增量和实时的数据同步到es中做聚合检索了,es的操作使用开源的easy-es框架,让操作es更简单和高效,希望我的分享能帮助到你,文章虽然是开源,但是创作不易,请不要侵权抄袭,否则直接举报,最起码的版权意识还是要有的,你可以转载,但是请把原文地址放上去,最可恶的那种就是直接复制过去然后就变成他自己的原创了,这种行为真的是很可耻,非常让人讨厌、反感和紫火,请一键三连,么么哒!