干货!SpareNet:基于样式和对抗性渲染的点云补全
点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!
在本文中,我们提出了一种基于样式和对抗性可微分渲染的点云生成器(SpareNet) 用于点云补全。首先,我们提出了基于通道注意力的EdgeConv,以充分利用点云特征的局部结构和全局形状。其次,我们观察到基于折叠(Folding) 的点云生成方法中拼接(concatenation) 的操作限制了其生成复杂且真实形状的潜力。受到StyleGAN的启发,我们将形状特征视为样式码,在折叠过程中用其调节归一化层,这大大增强了生成器的表达能力。第三,我们意识到现有的点云监督,例如倒角距离(Chamfer Distance)或推土机距离(Earth Mover's Distance),不能如实地反映重建点云的视觉质量。为了解决这个问题,我们使用可微分渲染器将补全的点云投影到深度图,并应用对抗性训练来倡导不同视角下的视觉真实性。ShapeNet和KITTI上的大量实验证明了我们方法的有效性,该方法实现了最先进的量化性能,同时提供了卓越的视觉质量。
本期AI TIME PhD直播间,我们邀请到了伊利诺伊大学厄巴纳香槟分校计算机系博士生谢楚琳,为我们带来报告分享——《Style-based Point Generator with Adversarial Rendering for Point Cloud Completion》

谢楚琳:
伊利诺伊大学厄巴纳香槟分校计算机系一年级博士生,本科毕业于浙江大学,目前以第一作者在 ICML、CVPR、ICLR 等会议上发表论文,曾在阿里、微软亚洲研究院和字节跳动等公司实习。
个人主页:
https://alphapav.github.io/
01
背 景
(1)问题描述
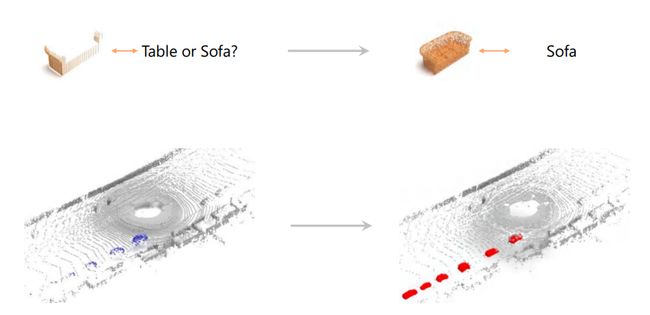
点云是计算机视觉领域非常热门的话题,在自动驾驶、三维重建、室内导航、增强现象(AR)、机器人等视觉任务场景中都有广泛的应用。直接从三维传感器获取的点云往往因为传感器分辨率的限制或者一些物体遮挡等因素导致生成的点云是稀疏的、不完整的。如下图直接得到的沙发点云缺失很多细节,导致无法区分该点云的类别是桌子还是沙发,当我们利用计算机技术进行点云补全,就获得了完整的点云,方便后面的分类、分割等下游任务。
由此我们得到了点云补全的概念,即补全一个物体的部分观测点云,为下游任务做准备。
本文总结了点云补全的3个特征:
1) 点云补全的输出应该保留输入点云部分观测的完整结构。
2) 点云补全网络需要具有很强的想象力,能够从点云部分观测中推断出物体完整的点云形状。
3) 补全后的点云局部结构应该具备清晰、准确、无噪声干扰的特点。
(2)相关工作
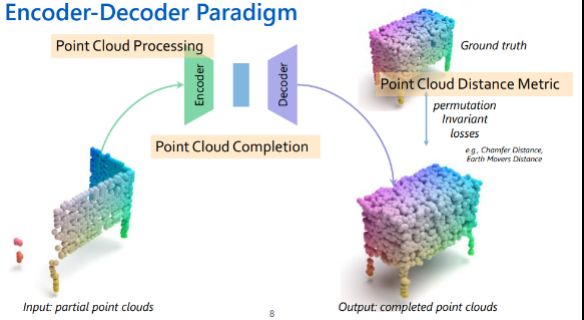
目前点云补全的方法大多是采用encoder-decoder的形式,如下图,首先输入部分点云到encoder获取点云的形状特征,然后由形状特征经过decoder得到完整的点云形状,将输出与Ground truth通过倒角距离(Chamfer Distance)或推土机距离(Earth Mover's Distance)进行求loss来进行网络监督。这其中有三个比较重要的环节:特征提取,点云补全,loss计算。
02
方 法
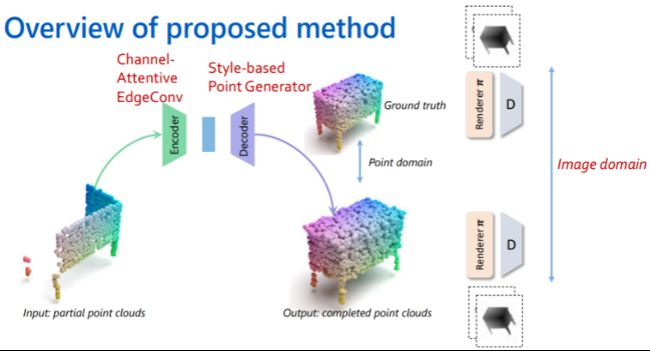
下图是本文点云补全方法的整体框架,分别对上面encoder-decoder方法中提到的三个环节进行改进。在encoder的特征提取时,本文提出了Channel-Attentive EdgeConv(CAE)对输入的部分点云进行全局和局部的特征提取;在decoder阶段,本文提出Style-based Point Generator生成更加具有细节的点云补全输出;在进行loss计算时,我们发现直接在point域计算效果不佳,因此我们将点云目标投射在depth map上,能够再二维图像域进行loss计算。
(1) encoder部分
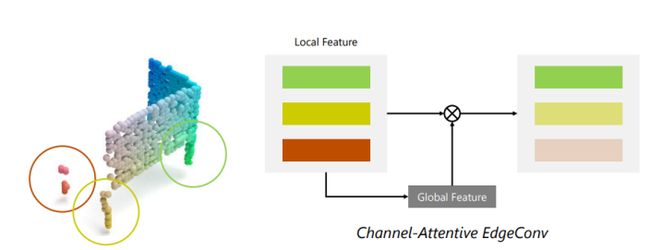
现有点云补全工作中采用的特征提取方法大体分为两种,一种是基于MLP(多层感知机)+最大池化然后生成全局点云特征;另一种是通过提取局部特征然后生成全局特征。下图是一个点云补全输入的部分结构,红色圆圈标出的点云区域是不完整的,因此如果对该区域生成局部特征对点云的影响是消极的。绿色圆圈标出的部分比较完整,那么生成的局部特征对最终完整点云形状生成会起到促进作用。

下图是本文提出的CAE特征提取方法的示意图,CAE通过全局特征调制局部特征,达到促进完整的局部特征,抑制不好的局部特征的目的。
下图是CAE的详细实现逻辑结构图,输入是M个点的部分点云,encoder部分包含了4个这样的CAE结构。
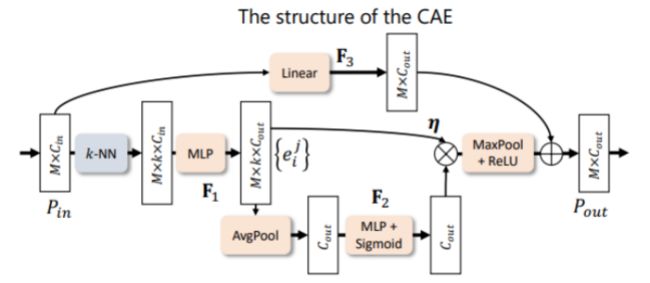
(2) decoder部分
在decoder部分现有工作通常是基于folding的方法,将encoder部分提取的特征作为形状编码(shape code)与2D网格中采样点的坐标直接拼接在一起,通过MLP学习生成3D表面上的一个点,即点云补全输出的三维结构上的一个点。本文认为直接将shape code与2D采样点拼接的方式较为低效,并且受到Style-GAN网络的启发,我们将shape code作为style,将2D网格作为content,我们使用一个网络对shape code学习一些参数然后输入到MLP中对2D网格的采样点进行一个指导,从而有一个更充分的信息融合。我们把这个结构称为style-based folding layer,如下图所示。

Decoder部分使用k个style-based folding layer对k个表面进行同时的学习,将这k个表面拼接起来,得到最终的点云补全预测输出。其中,每个MLP学习中都有之前encoder部分学习的shape code进行指导。在并行生成k个3D表面时,加入一个expansion loss,控制不同表面之间的点不重叠,更好地生成比较复杂的表面。

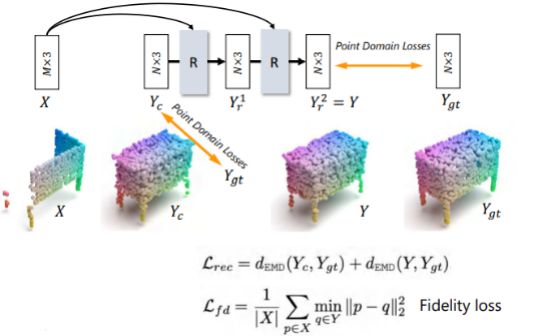
(3) refinement
在refine的时候,由于输入的部分点云也具有局部完整正确的结构,本文将输入的部分点云与点云补全的输出进行一个拼接。如果直接将输入与输出拼接,得到点的数量会大于我们需要的点,因此采用一个mininum density sampling将点的数量采样到我们需要的个数。
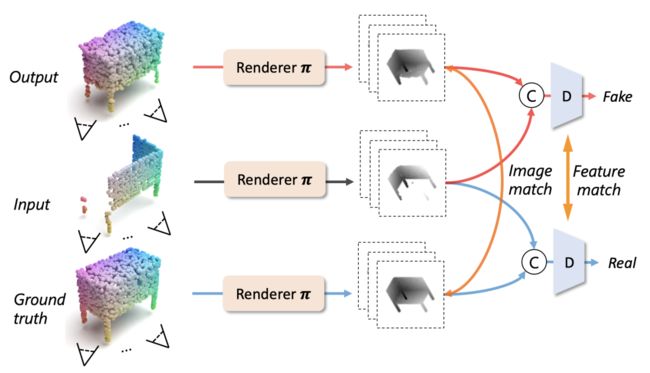
(4) adversarial point rendering
生成补全的点云后,我们发现如果只在point域用CD或者EMD算与ground-truth点云之间距离作为loss进行监督的话, 生成的补全的点云十分嘈杂,视觉效果不佳。因此我们将点云目标投射在depth map上,能够再二维图像域进行loss计算。除了直接和ground truth depth maps算matching loss,我们还在depth map上训练了一个判别器,用adversarial loss来促进前面的网络(encoder, decoder, refiner)生成视觉真实的点云。
(5) 损失函数设计
最终本文的损失函数包含四个部分,如下图,包括point domain的三个损失,image domain的groud truth和预测点云的depth map loss,点云补全对抗的均方误差和判别器特征匹配误差,decoder部分的expansion loss。

03
实 验
数据集:
ShapeNet、KITTI
实验结果:
(1) 可视化结果
点云补全的可视化结果:
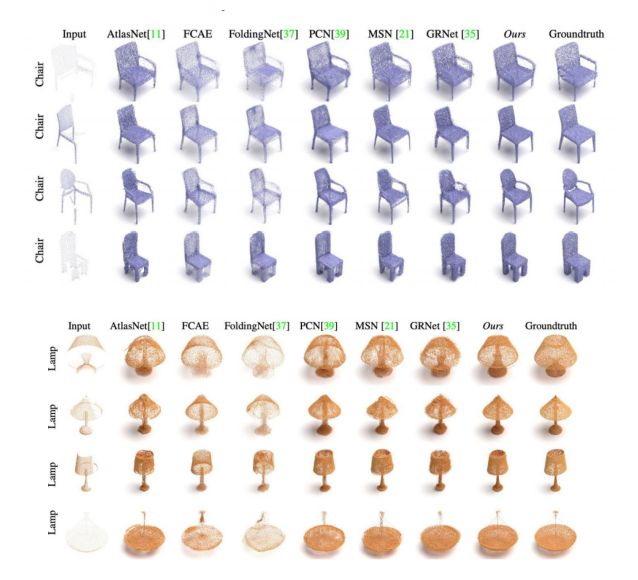
Depth Map的可视化:

(2) 与其他方法对比
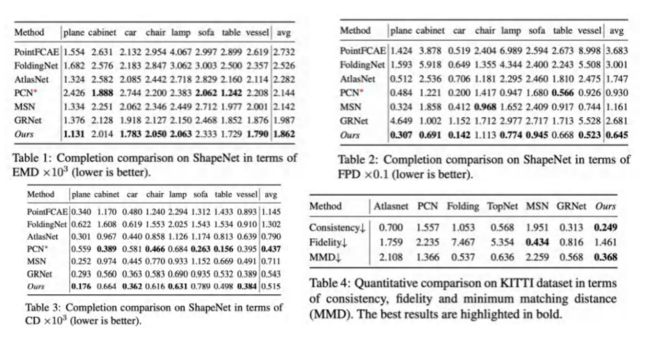
在点云分类任务的表现:本文方法对分类任务起到了更好的促进效果。

提
醒
论文:
《Style-based Point Generator with Adversarial Rendering for Point Cloud Completion》
点击阅读原文
即可观看分享回放哦!
整理:爱 国
审核:谢楚琳
AI TIME欢迎AI领域学者投稿,期待大家剖析学科历史发展和前沿技术。针对热门话题,我们将邀请专家一起论道。同时,我们也长期招募优质的撰稿人,顶级的平台需要顶级的你!
请将简历等信息发至[email protected]!
微信联系:AITIME_HY
AI TIME是清华大学计算机系一群关注人工智能发展,并有思想情怀的青年学者们创办的圈子,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法、场景、应用的本质问题进行探索,加强思想碰撞,打造一个知识分享的聚集地。

更多资讯请扫码关注

我知道你在看哟

点击“阅读原文”查看精彩回放