TextDiffuser: Diffusion Models as Text Painters
TextDiffuser: Diffusion Models as Text Painters (Paper reading)
Jingye Chen, HKUST, HK, arXiv2023, Cited: 0, Code, Paper
1. 前言
扩散模型因其出色的生成能力而受到越来越多的关注,但目前在生成准确连贯的文本方面仍存在困难。为了解决这个问题,我们引入了TextDiffuser,重点是生成具有视觉吸引力的文本,并且与背景一致。TextDiffuser包括两个阶段:首先,一个Transformer模型根据文本提示生成关键词的布局,然后扩散模型根据文本提示和生成的布局生成图像。此外,我们还贡献了第一个带有OCR注释的大规模文本图像数据集MARIO-10M,其中包含1000万个图像-文本对,包括文本识别、检测和字符级分割注释。我们还收集了MARIO-Eval基准数据集,作为评估文本渲染质量的综合工具。通过实验证明和用户研究,我们展示了TextDiffuser的灵活性和可控性,能够仅使用文本提示或结合文本模板图像创建高质量的文本图像,并进行文本修复以重建带有文本的不完整图像。
2. 整体思想
我们想在图片上生成文本,或者直接生成带有具体文本的图片。对于这两类,我们可以先确定你想加入的文本的位置,会容易些。一般的生成带有文本图像的prompts:”一只猫举着张纸,上面写着Hello World“,只有Hello World是我们想生成的文字,那么我们可以把”Hello World“当作一个关键词,让模型学会生成关键词的文字和一只猫。
本文,第一步先生成boxes,表示每个关键字的位置。然后在boxes中写入文字,再对每个文字mask,得到每个字母H E L的具体masks。第二步,以masks等作为条件训练扩散模型。训练得到的扩散模型,可以直接生成带有文字的图片,比如我们用第一步生成文字的masks,直接用pre-trained的模型就可以生成了。
3. 方法
TextDiffuser,这是一个基于扩散模型的灵活可控的框架。该框架由两个阶段组成。在第一个阶段,我们使用布局Transformer来定位文本提示中每个关键词的坐标,并获得字符级分割掩码。在第二个阶段,我们利用生成的分割掩码作为扩散过程的条件,结合文本提示对潜在扩散模型进行微调。为了进一步提高生成文本区域的质量,我们在潜在空间中引入了一个字符感知的损失函数。图1展示了TextDiffuser在仅使用文本提示或结合文本模板图像生成准确连贯的文本图像方面的应用。此外,TextDiffuser还能够进行文本修复,以重建带有文本的不完整图像。为了训练我们的模型,我们使用OCR工具并设计过滤策略,获得了1000万个带有OCR注释的高质量图像-文本对(称为MARIO-10M),每个对都包含识别、检测和字符级分割注释。
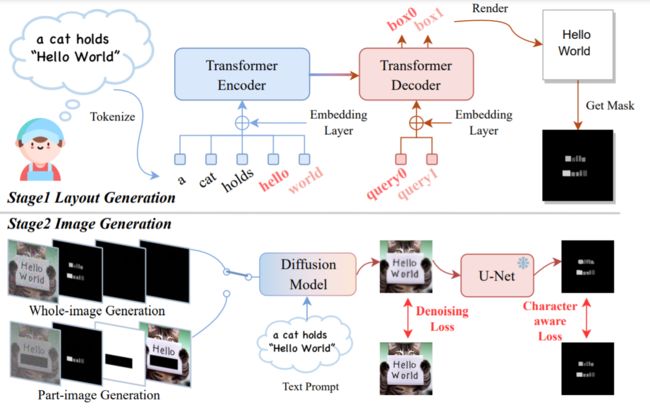
Stage 1 布局生成: 在这个阶段,我们的目标是利用边界框来确定关键词的布局(由用户提示中的引号括起来)。受到Layout Transformer的启发,我们利用Transformer架构来获取关键词的布局。形式上,我们将分词的提示(prompt)表示为 P = ( p 0 , p 1 , . . . , p L − 1 ) P = (p_0, p_1, ..., p_{L−1}) P=(p0,p1,...,pL−1),其中 L L L表示最大的标记长度。在LDM的基础上,我们使用CLIP和两个线性层来将序列编码为 C L I P ( P ) ∈ R L × d CLIP(P) ∈ R^{L×d} CLIP(P)∈RL×d,其中 d d d是潜在空间的维度。为了将关键词与其他内容区分开来,我们设计了一个关键词嵌入 K e y ( P ) ∈ R L × d Key(P) ∈ R^{L×d} Key(P)∈RL×d,其中包含两个条目(即关键词和非关键词)。此外,我们使用嵌入层 W i d t h ( P ) ∈ R L × d Width(P) ∈ R^{L×d} Width(P)∈RL×d来编码关键词的宽度。结合可学习位置嵌入 P o s ( P ) ∈ R L × d Pos(P) ∈R^{L×d} Pos(P)∈RL×d,我们构建整个嵌入如下所示:
E m b e d d i n g ( P ) = C L I P ( P ) + P o s ( P ) + K e y ( P ) + W i d t h ( P ) Embedding(P)=CLIP(P)+Pos(P)+Key(P)+Width(P) Embedding(P)=CLIP(P)+Pos(P)+Key(P)+Width(P)
进一步,使用基于Transformer的 l l l层编码器 Φ E Φ_E ΦE和解码器 Φ D Φ_D ΦD对嵌入进行处理,以自回归的方式获得 K K K个关键词的边界框 B ∈ R K × 4 B ∈ R^{K×4} B∈RK×4,这里的4是box的坐标。具体而言,我们使用位置嵌入作为Transformer解码器 Φ D Φ_D ΦD的查询,确保第 n n n个查询对应于提示中的第 n n n个关键词。模型通过 l 1 l_1 l1损失进行优化,也表示为 ∣ B G T − B ∣ |B_{GT} − B| ∣BGT−B∣,其中 B G T B_{GT} BGT是真实值。此外,我们可以利用一些Python包(如Pillow)来渲染文本,并同时获得具有 ∣ A ∣ |A| ∣A∣个通道的字符级分割掩码 C C C,其中 ∣ A ∣ |A| ∣A∣表示字母表 A A A的大小。这里的意思是,我们获得了 K K K个boxes,然后我们在boxes中用Pillow写入文字,比如Hello,然后对每一个字母都生成Mask如图中最后生成的一样,但是这里里的A是95,包括了大小写字符什么的,会根据你的关键词,生成对应字母的box,其他为空。因此,我们获得了关键词的布局,下面介绍图像生成过程。

Stage 1 图像生成: 在这个阶段,我们旨在根据第一阶段生成的分割掩码 C C C来生成图像。我们使用VAE将形状为 H × W H×W H×W的原始图像编码为4维潜在空间特征 F ∈ R 4 × H ′ × W ′ F ∈ R^{4×H′×W′} F∈R4×H′×W′。然后,我们从均匀分布(0, T m a x T_{max} Tmax)中采样一个时间步长 T T T,并从高斯噪声 ϵ ∈ R 4 × H ′ × W ′ ϵ ∈ R^{4×H′×W′} ϵ∈R4×H′×W′中采样,以破坏原始特征,得到 F ^ = α ˉ T F + 1 − α ˉ T ϵ \hat F =\sqrt{\bar α_T} F +\sqrt{1 − \bar α_T} ϵ F^=αˉTF+1−αˉTϵ,其中 α ˉ T \bar α_T αˉT是扩散过程的系数。此外,我们使用三个卷积层对字符级分割掩码 C C C进行下采样,得到8维 C ^ ∈ R 8 × H ′ × W ′ \hat C ∈ R^{8×H′×W′} C^∈R8×H′×W′。我们还引入了两个额外的特征,称为1维特征掩码 M ^ ∈ R 1 × H ′ × W ′ \hat M ∈ R^{1×H′×W′} M^∈R1×H′×W′和4维掩码特征 F ^ M ∈ R 4 × H ′ × W ′ \hat F_M ∈ R^{4×H′×W′} F^M∈R4×H′×W′。在整个图像生成过程中, M ^ \hat M M^被设置为覆盖特征的所有区域,而 F ^ M \hat F_M F^M是完全掩蔽图像的特征。在部分图像生成过程中(也称为文本修复),特征掩码 M ^ \hat M M^表示用户想要生成的区域,而掩蔽特征 F ^ M \hat F_M F^M表示用户希望保留的区域,如结构图下图所示的两个分支。为了同时训练两个分支,我们使用一种掩蔽策略,其中样本以概率 σ σ σ完全被掩蔽,以概率 1 − σ 1−σ 1−σ部分被掩蔽。我们将 F ^ , C ^ , M ^ , F ^ M \hat F, \hat C, \hat M, \hat F_M F^,C^,M^,F^M在特征通道中连接为一个17维的输入,并使用采样的噪声 ϵ ϵ ϵ与预测噪声 ϵ θ ϵ_θ ϵθ之间的去噪损失进行训练。
l d e n o i s i n g = ∣ ∣ ϵ − ϵ θ ( F ^ , C ^ , M ^ , F ^ M , P , T ) ∣ ∣ 2 2 l_{denoising}=||ϵ-ϵ_θ(\hat F, \hat C, \hat M, \hat F_M, P, T)||^2_2 ldenoising=∣∣ϵ−ϵθ(F^,C^,M^,F^M,P,T)∣∣22
此外,我们提出了一个字符感知损失来帮助模型更加关注文本区域。具体而言,我们预训练了一个U-Net,可以将潜在特征映射到字符级分割掩码,见3.1小节。在训练过程中,我们固定其参数,并仅使用它通过交叉熵损失函数 l c h a r l_{char} lchar提供指导,其中权重为 λ c h a r λ_{char} λchar。总体而言,模型通过以下方式进行优化:
l = l d e n o s i n g + l c h a r l = l_{denosing}+l_{char} l=ldenosing+lchar
最好,输出特征被送到VAE解码器得到图像。
3.1 设计字符感知损失
U-Net包含四个下采样操作和四个上采样操作。输入将被下采样至最大的1/16。为了提供字符感知损失,输入特征F是4维的,空间尺寸为64×64,而输出特征是96维的(字符表A的长度加上一个表示非字符像素的空值符号),同样具有64×64的空间尺寸。随后,计算输出特征(需要将预测的噪声转换为预测特征)与调整大小为64×64的字符级分割掩码 C ′ C' C′之间的交叉熵损失。U-Net使用MARIO-10M的训练集进行一次预训练。我们使用Adadelta优化器,并将学习率设置为1。在训练扩散模型时,U-Net被冻结,仅用于提供字符感知的指导。
3.2 推理
TextDiffuser在推理过程中提供了高度的可控性和灵活性,具体体现在以下几个方面:(1)根据用户的提示生成图像。特别地,用户可以修改生成的布局或编辑文本,以满足个性化需求;(2)用户可以直接从第二阶段开始,提供一个模板图像(例如场景图像、手写图像或打印图像),并预训练一个分割模型以获得字符级分割掩码;(3)用户可以使用文本修复来修改给定图像的文本区域。此外,该操作可以进行多次。
3.2 字符级分割模型
我们使用基于U-Net的字符级分割模型进行训练,其架构与3.1节所示的架构类似。我们将输入大小设置为256×256,以确保在这个分辨率下大多数字符都可读取。我们使用合成的场景文本图像、印刷文本图像和手写文本图像等约4百万个样本来训练分割模型。我们采用数据增强策略(如模糊、旋转和颜色增强)使分割模型更加鲁棒。使用Adadelta优化器,学习率为1,对分割模型进行了10个epochs的训练。图8展示了训练数据集中的一些样本。

3.3 数据集
由于目前没有专门用于文本渲染的大规模数据集,为了解决这个问题,我们收集了1000万个带有OCR注释的图像-文本对,构建了MARIO-10M数据集。我们还从MARIO-10M测试集的子集和其他现有来源中收集了MARIO-Eval评估基准,以作为评估文本渲染质量的综合工具。由于TMDB电影/电视剧海报和Open Library图书封面没有现成的字幕,因此我们根据它们的标题使用以下模板构建字幕。我们使用{XXX}作为标题的占位符。
TMDB:
• Logo {XXX}
• A movie poster named {XXX}
• A film poster of {XXX}
Open Library:
• A book of {XXX}
• A book with text {XXX} on it
• A book cover with logo {XXX} on it
3.4 OCR
由于我们依赖OCR工具来注释MARIO-10M,因此有必要评估这些工具的性能。具体来说,我们手动对100个样本进行了文本识别、检测和字符级分割掩模的注释,然后将它们与OCR工具给出的注释进行比较。我们注意到现有方法的性能低于它们在文本检测和定位基准上的结果。以DB为例,它可以在ICDAR 2015数据集上实现91.8%的文本检测精度,而在MARIO-10M上只能达到76%。这是因为MARIO-10M中存在许多具有挑战性的情况,例如模糊和小字体。此外,可能存在领域差距,因为DB是在场景文本检测数据集上训练的,而MARIO-10M包含了各种场景中的文本图像。未来的工作可以探索更先进的识别、检测和分割模型,以减少OCR注释中的噪声。我们在图10中展示了一些OCR结果。
![]()


4. 实验

对于第一阶段,我们利用预训练的CLIP来获取给定提示的嵌入。Transformer层数 l l l设置为2,潜在空间的维度 d d d设置为512。根据CLIP,最大标记长度L设置为77。我们使用常用字体“Arial.ttf”,字体大小设置为24以获取宽度嵌入,并且在渲染过程中也使用此字体。字母表A包括95个字符,包括26个大写字母、26个小写字母、10个数字、32个标点符号和一个空格字符。在标记化过程中,当一个词有多个子标记时,只有第一个子标记被标记为关键词。
对于第二阶段,我们使用Hugging Face Diffusers实现了扩散过程,并加载了检查点“runwayml/stable-diffusion-v1-5”。需要注意的是,我们只需要修改输入卷积层的输入维度(从4改为17),使得我们的模型具有与原始模型类似的参数规模和计算时间。具体而言,输入和输出图像的高度 H H H和宽度 W W W为512。对于扩散过程,输入的空间尺寸设置为 H ′ = 64 H' = 64 H′=64和 W ′ = 64 W' = 64 W′=64。我们将批量大小设置为 768 768 768,并训练模型两个时期,使用8块具有32GB内存的Tesla V100 GPU,共计四天的时间。我们使用AdamW优化器,学习率设置为1e-5。此外,我们利用梯度检查点和xformers进行计算效率的优化。在训练过程中,将最大时间步长Tmax设置为1,000,并以10%的概率丢弃标题,以进行无分类器的引导。在训练部分图像生成分支时,以50%的概率对检测到的文本框进行遮罩。在推理过程中,我们使用50个采样步骤,并使用尺度为7.5的无分类器引导。
4.1 消融实验
对于Transformer层数和是否使用宽度嵌入进行了割舍研究:所有的割舍模型都是在MARIO-10M的训练集上进行训练,并在MARIO-10M的测试集上进行评估。结果显示,添加宽度嵌入可以提高性能,当Transformer层数 l l l分别设置为1、2和4时,IoU分别提高了2.1%、2.9%和0.3%。最佳IoU是在使用2个Transformer层和包括宽度嵌入的情况下实现的。
字符级分割掩码为生成字符提供了明确的引导:字符级分割掩码在TextDiffuser的生成过程中对字符的位置和内容提供了明确的引导。为了验证使用字符级分割掩码的有效性,我们训练了没有使用掩码的割舍模型。与使用TextDiffuser生成的文本相比,生成的文本不准确且与背景不协调,突显了明确引导的重要性。
字符感知损失的权重:我们对 λ c h a r λ_char λchar进行了实验,范围为[0, 0.001, 0.01, 0.1, 1]。我们使用DrawBenchText进行评估,并使用Microsoft Read API来检测和识别生成图像中的文本。我们使用准确率(Acc)作为指标,以验证检测到的单词是否与关键词完全匹配。我们观察到,当 λ c h a r λ_{char} λchar设置为0.01时,性能最佳,得分比基准( λ c h a r = 0 λ_{char} = 0 λchar=0)提高了9.8%。
整体图像生成分支和部分图像生成分支的训练比例: 我们探索了训练比例σ的范围为[0, 0.25, 0.5, 0.75, 1],并在表3中展示了结果。当σ设置为1时,表示仅训练整体图像分支,反之亦然。我们使用DrawBenchText对整体图像生成分支进行评估。对于部分图像生成分支,我们从MARIO-10M测试集中随机选择了1,000个样本,并随机遮挡了一些检测到的文本框。我们利用Microsoft Read API来检测和识别生成图像中重建的文本框,同时使用文本检测结果和定位结果的F-measure作为度量指标(分别表示为Det-F和Spot-F)。结果显示,当训练比例设置为50%时,模型平均表现更好(0.716)。
4.2 实验结果
定量结果: 对于整体图像生成任务,我们在定量实验中与Stable Diffusion (SD) 、ControlNet 和DeepFloyd进行比较。DeepFloyd使用了两个超分辨率模块来生成分辨率更高的1024×1024图像,而其他方法生成的图像分辨率为512×512。我们使用使用第一阶段模型生成的印刷文本图像的Canny图作为ControlNet的条件。请注意,由于缺乏开源代码、检查点或API,我们无法与Imagen、eDiff-i和GlyphDraw 进行比较。根据表4,我们展示了与现有方法相比的文本到图像任务的定量结果。我们的TextDiffuser在CLIPScore方面表现最好,同时在FID方面也取得了可比较的性能。此外,TextDiffuser在四个与OCR相关的指标方面表现最佳。有趣的是,TextDiffuser在没有明确文本相关指导的情况下显著优于那些方法(例如,相对于F-measure,相对于Stable Diffusion和DeepFloyd分别提高了76.10%和60.62%),凸显了明确指导的重要性。至于部分图像生成任务,我们无法评估我们的方法,因为据我们所知,没有针对这个任务专门设计的方法。

定性结果: 对于整体图像生成任务,我们进一步通过展示使用官方演示页面或API服务生成的定性示例,与闭源DALL·E 、Stable Diffusion XL (SD-XL)和Midjourney进行比较。下图展示了不同方法生成的一些来自提示或印刷文本图像的图像。值得注意的是,我们的方法生成的文本更易读,并且与生成的背景相一致。相反,虽然SD-XL和Midjourney生成的图像在视觉上具有吸引力,但其中一些生成的文本不包含所需的文本,或包含具有错误笔画的难以辨认的字符。结果还显示,尽管ControlNet提供了强有力的监督信号,但它仍然难以生成与背景一致的准确文本的图像。对于部分图像生成任务,我们在图5中展示了一些结果。与文本编辑任务 [86] 相反,我们给予模型足够的灵活性,以生成具有合理样式的文本。例如,第二行第一列的图像中包含绿色的单词“country”,而模型生成了黄色的单词“country”。这是合理的,因为它遵循最近单词“range”的样式。此外,我们的方法可以生成与背景一致的逼真文本,即使在复杂情况下,如服装。
4.3 关键词和mask的作用
如图13所示,我们尝试在没有明确指导的情况下进行生成。例如,根据第一行,我们将字符像素的值设置为1,非字符像素的值设置为0(即去除内容,只提供位置指导),以这种方式训练。我们观察到模型可以生成一些与关键词类似的单词,但包含一些语法错误(例如,“Hello”中缺少了一个“l”)。此外,根据第二行,我们在没有分割掩模的情况下训练TextDiffuser(即去除位置和内容指导)。在这种情况下,实验等效于直接在MARIO-10M数据集上对预训练的潜在扩散模型进行微调。结果显示,文本渲染质量变差,这证明了明确指导的重要性。